 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSLR: A Semi-Supervised Learning Method for Isolated Sign Language Recognition
Apr 23, 2025Sign language is the primary communication language for people with disabling hearing loss. Sign language recognition (SLR) systems aim to recognize sign gestures and translate them into spoken language. One of the main challenges in SLR is the scarcity of annotated datasets. To address this issue, we propose a semi-supervised learning (SSL) approach for SLR (SSLR), employing a pseudo-label method to annotate unlabeled samples. The sign gestures are represented using pose information that encodes the signer's skeletal joint points. This information is used as input for the Transformer backbone model utilized in the proposed approach. To demonstrate the learning capabilities of SSL across various labeled data sizes, several experiments were conducted using different percentages of labeled data with varying numbers of classes. The performance of the SSL approach was compared with a fully supervised learning-based model on the WLASL-100 dataset. The obtained results of the SSL model outperformed the supervised learning-based model with less labeled data in many cases.
CLIP-SLA: Parameter-Efficient CLIP Adaptation for Continuous Sign Language Recognition
Apr 02, 2025



Continuous sign language recognition (CSLR) focuses on interpreting and transcribing sequences of sign language gestures in videos. In this work, we propose CLIP sign language adaptation (CLIP-SLA), a novel CSLR framework that leverages the powerful pre-trained visual encoder from the CLIP model to sign language tasks through parameter-efficient fine-tuning (PEFT). We introduce two variants, SLA-Adapter and SLA-LoRA, which integrate PEFT modules into the CLIP visual encoder, enabling fine-tuning with minimal trainable parameters. The effectiveness of the proposed frameworks is validated on four datasets: Phoenix2014, Phoenix2014-T, CSL-Daily, and Isharah-500, where both CLIP-SLA variants outperformed several SOTA models with fewer trainable parameters. Extensive ablation studies emphasize the effectiveness and flexibility of the proposed methods with different vision-language models for CSLR. These findings showcase the potential of adapting large-scale pre-trained models for scalable and efficient CSLR, which pave the way for future advancements in sign language understanding.
A Comparative Study of Continuous Sign Language Recognition Techniques
Jun 18, 2024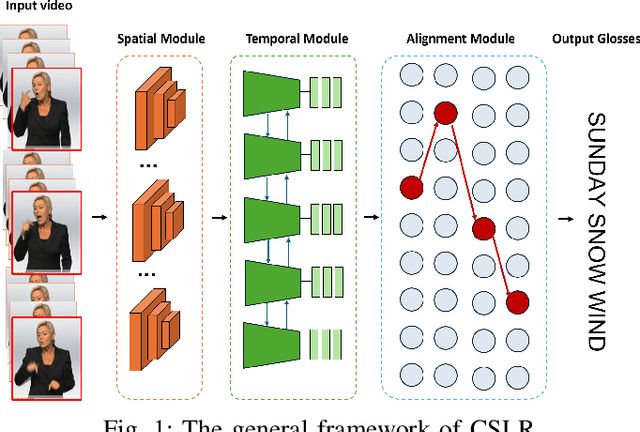

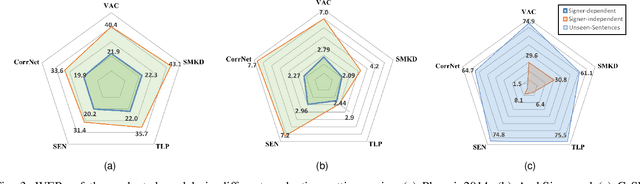

Continuous Sign Language Recognition (CSLR) focuses on the interpretation of a sequence of sign language gestures performed continually without pauses. In this study, we conduct an empirical evaluation of recent deep learning CSLR techniques and assess their performance across various datasets and sign languages. The models selected for analysis implement a range of approaches for extracting meaningful features and employ distinct training strategies. To determine their efficacy in modeling different sign languages, these models were evaluated using multiple datasets, specifically RWTH-PHOENIX-Weather-2014, ArabSign, and GrSL, each representing a unique sign language. The performance of the models was further tested with unseen signers and sentences. The conducted experiments establish new benchmarks on the selected datasets and provide valuable insights into the robustness and generalization of the evaluated techniques under challenging scenarios.