 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Oxford Radar RobotCar Dataset: A Radar Extension to the Oxford RobotCar Dataset
Sep 12, 2019
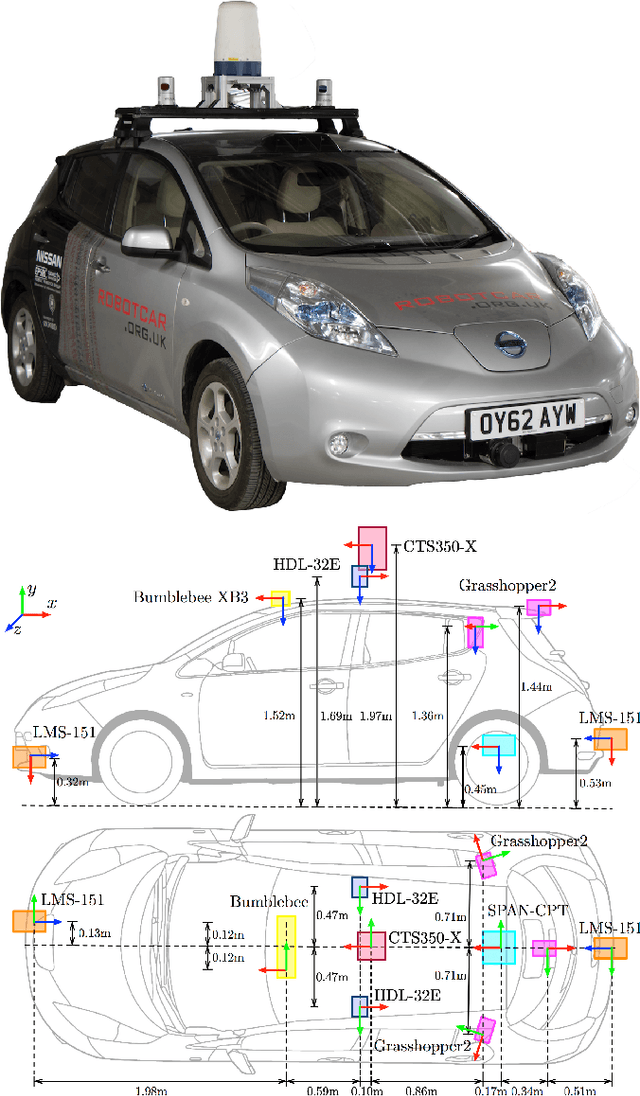


In this paper we present The Oxford Radar RobotCar Dataset, a new dataset for researching scene understanding using Millimetre-Wave FMCW scanning radar data. The target application is autonomous vehicles where this modality remains unencumbered by environmental conditions such as fog, rain, snow, or lens flare, which typically challenge other sensor modalities such as vision and LIDAR. The data were gathered in January 2019 over thirty-two traversals of a central Oxford route spanning a total of 280 km of urban driving. It encompasses a variety of weather, traffic, and lighting conditions. This 4.7 TB dataset consists of over 240,000 scans from a Navtech CTS350-X radar and 2.4 million scans from two Velodyne HDL-32E 3D LIDARs; along with six cameras, two 2D LIDARs, and a GPS/INS receiver. In addition we release ground truth optimised radar odometry to provide an additional impetus to research in this domain. The full dataset is available for download at: ori.ox.ac.uk/datasets/radar-robotcar-dataset
Masking by Moving: Learning Distraction-Free Radar Odometry from Pose Information
Sep 12, 2019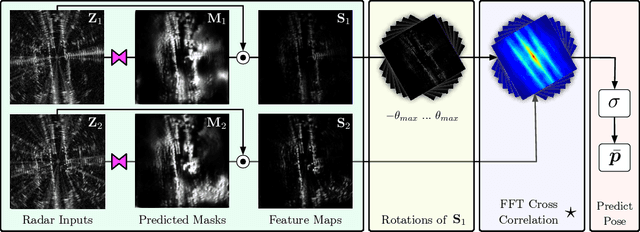
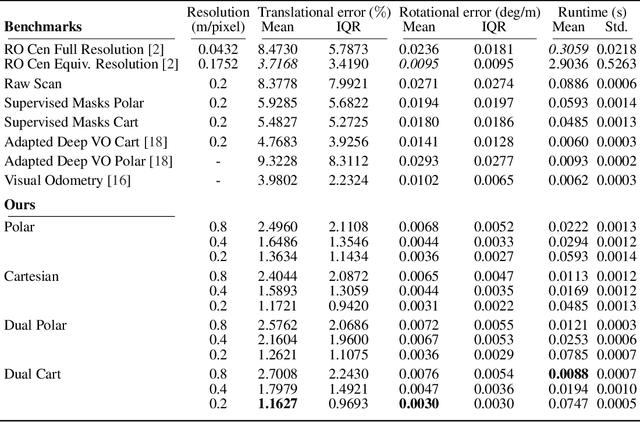
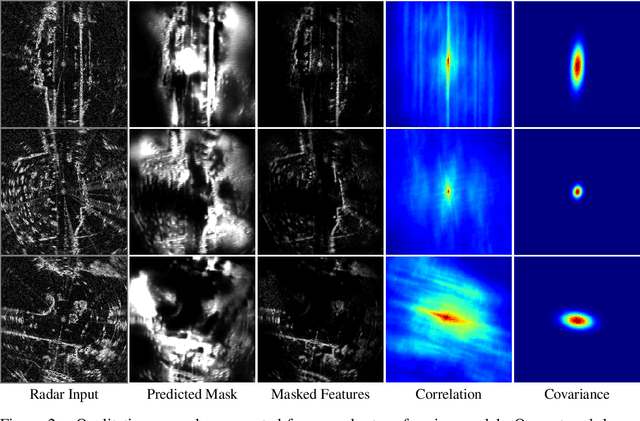
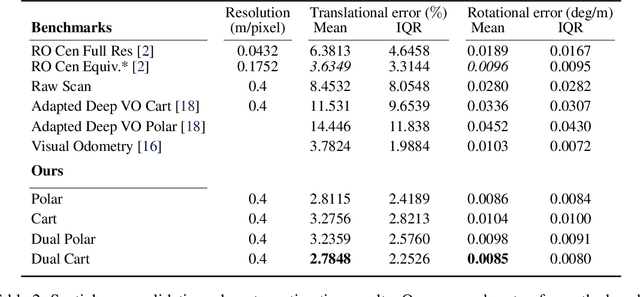
This paper presents an end-to-end radar odometry system which delivers robust, real-time pose estimates based on a learned embedding space free of sensing artefacts and distractor objects. The system deploys a fully differentiable, correlation-based radar matching approach. This provides the same level of interpretability as established scan-matching methods and allows for a principled derivation of uncertainty estimates. The system is trained in a (self-)supervised way using only previously obtained pose information as a training signal. Using 280km of urban driving data, we demonstrate that our approach outperforms the previous state-of-the-art in radar odometry by reducing errors by up 68% whilst running an order of magnitude faster.
End-to-end Recurrent Multi-Object Tracking and Trajectory Prediction with Relational Reasoning
Aug 09, 2019
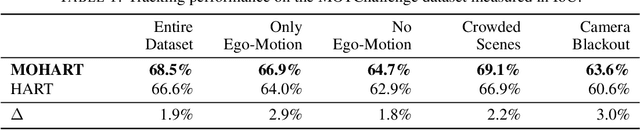
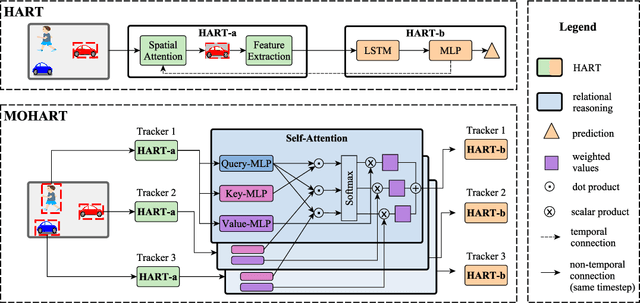
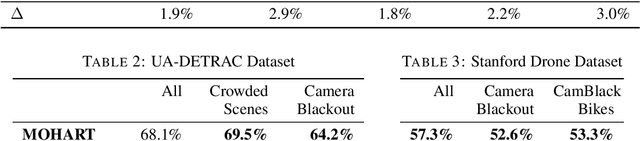
The majority of contemporary object-tracking approaches used in autonomous vehicles do not model interactions between objects. This contrasts with the fact that objects' paths are not independent: a cyclist might abruptly deviate from a previously planned trajectory in order to avoid colliding with a car. Building upon HART, a neural, class-agnostic single-object tracker, we introduce a multi-object tracking method MOHART capable of relational reasoning. Importantly, the entire system, including the understanding of interactions and relations between objects, is class-agnostic and learned simultaneously in an end-to-end fashion. We find that the addition of relational-reasoning capabilities to HART leads to consistent performance gains in tracking as well as future trajectory prediction on several real-world datasets (MOTChallenge, UA-DETRAC, and Stanford Drone dataset), particularly in the presence of ego-motion, occlusions, crowded scenes, and faulty sensor inputs. Finally, based on controlled simulations, we propose that a comparison of MOHART and HART may be used as a novel way to measure the degree to which the objects in a video depend upon each other as they move together through time.
GENESIS: Generative Scene Inference and Sampling with Object-Centric Latent Representations
Jul 30, 2019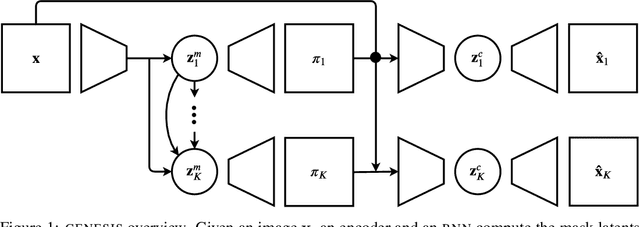
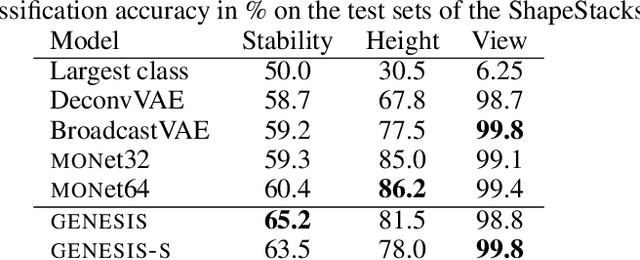
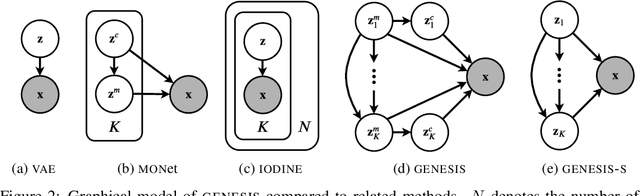

Generative models are emerging as promising tools in robotics and reinforcement learning. Yet, even though tasks in these domains typically involve distinct objects, most state-of-the-art methods do not explicitly capture the compositional nature of visual scenes. Two exceptions, MONet and IODINE, decompose scenes into objects in an unsupervised fashion via a set of latent variables. Their underlying generative processes, however, do not account for component interactions. Hence, neither of them allows for principled sampling of coherent scenes. Here we present GENESIS, the first object-centric generative model of visual scenes capable of both decomposing and generating complete scenes by explicitly capturing relationships between scene components. GENESIS parameterises a spatial GMM over pixels which is encoded by component-wise latent variables that are inferred sequentially or sampled from an autoregressive prior. We train GENESIS on two publicly available datasets and probe the information in the latent representations through a set of classification tasks, outperforming several baselines.
On the Limitations of Representing Functions on Sets
Jan 25, 2019
Recent work on the representation of functions on sets has considered the use of summation in a latent space to enforce permutation invariance. In particular, it has been conjectured that the dimension of this latent space may remain fixed as the cardinality of the sets under consideration increases. However, we demonstrate that the analysis leading to this conjecture requires mappings which are highly discontinuous and argue that this is only of limited practical use. Motivated by this observation, we prove that an implementation of this model via continuous mappings (as provided by e.g. neural networks or Gaussian processes) actually imposes a constraint on the dimensionality of the latent space. Practical universal function representation for set inputs can only be achieved with a latent dimension at least the size of the maximum number of input elements.
Probably Unknown: Deep Inverse Sensor Modelling In Radar
Oct 18, 2018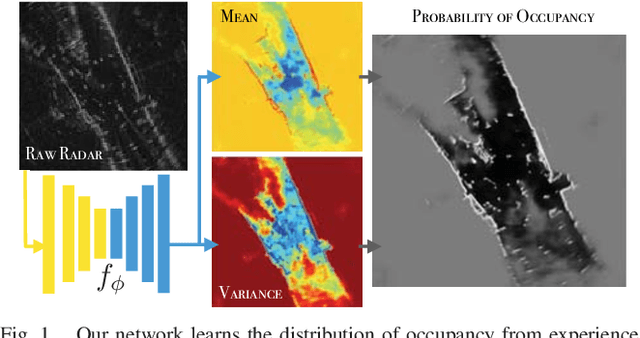

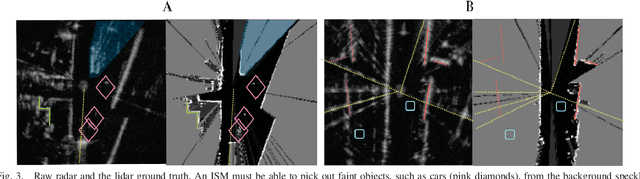
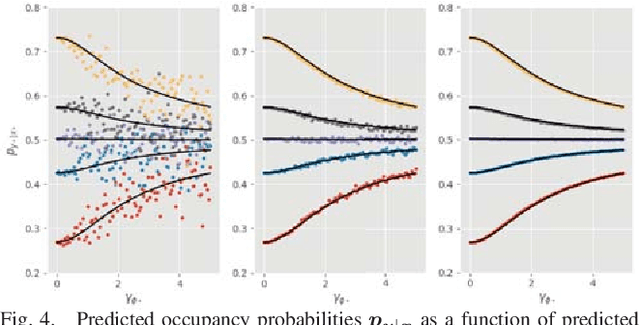
Radar presents a promising alternative to lidar and vision in autonomous vehicle applications, being able to detect objects at long range under a variety of weather conditions. However, distinguishing between occupied and free space from a raw radar scan is notoriously difficult. We consider the challenge of learning an Inverse Sensor Model (ISM) mapping a raw radar observation to occupancy probabilities in a discretised space. We frame this problem as a segmentation task, utilising a deep neural network that is able to learn an inherently probabilistic ISM from raw sensor data considers scene context. In doing so our approach explicitly accounts for the heteroscedastic aleatoric uncertainty for radar that arises due to complex interactions between occlusion and sensor noise. Our network is trained using only partial occupancy labels generated from lidar and able to successfully distinguish between occupied and free space. We evaluate our approach on five hours of data recorded in a dynamic urban environment and show that it significantly outperforms classical constant false-alarm rate (CFAR) filtering approaches in light of challenging noise artefacts whilst identifying space that is inherently uncertain because of occlusion.
Dropout Distillation for Efficiently Estimating Model Confidence
Sep 27, 2018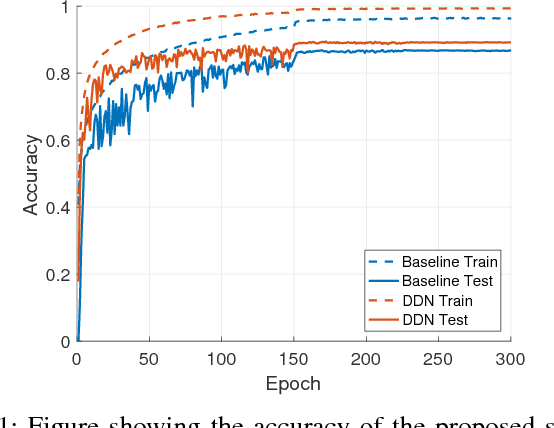
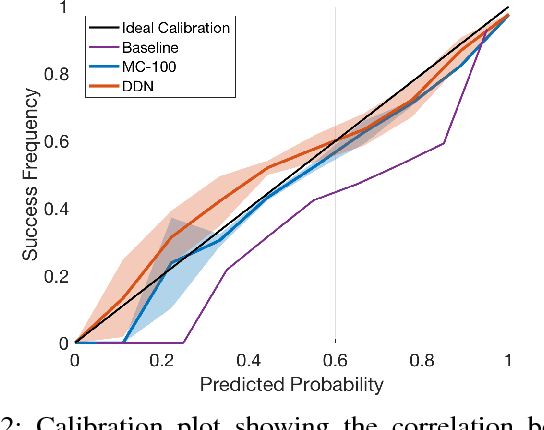
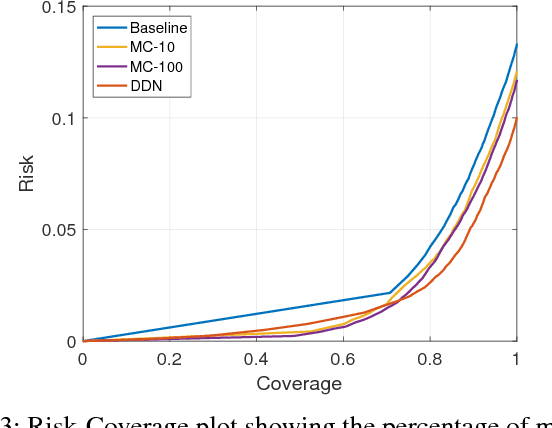
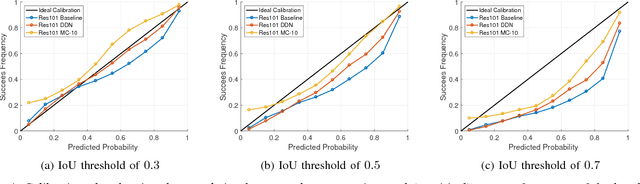
We propose an efficient way to output better calibrated uncertainty scores from neural networks. The Distilled Dropout Network (DDN) makes standard (non-Bayesian) neural networks more introspective by adding a new training loss which prevents them from being overconfident. Our method is more efficient than Bayesian neural networks or model ensembles which, despite providing more reliable uncertainty scores, are more cumbersome to train and slower to test. We evaluate DDN on the the task of image classification on the CIFAR-10 dataset and show that our calibration results are competitive even when compared to 100 Monte Carlo samples from a dropout network while they also increase the classification accuracy. We also propose better calibration within the state of the art Faster R-CNN object detection framework and show, using the COCO dataset, that DDN helps train better calibrated object detectors.
TACO: Learning Task Decomposition via Temporal Alignment for Control
Aug 10, 2018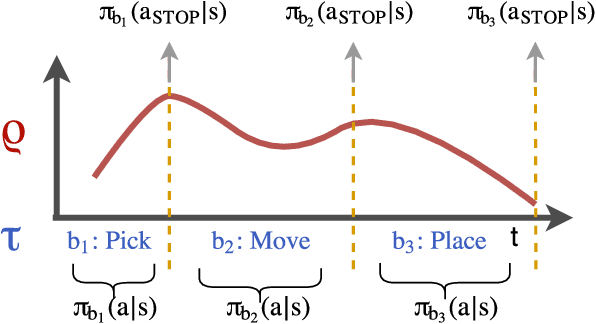
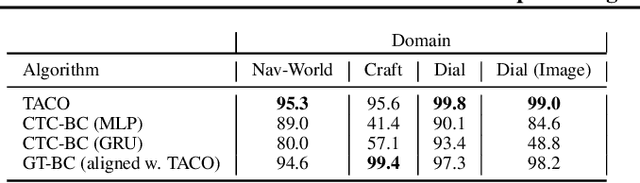
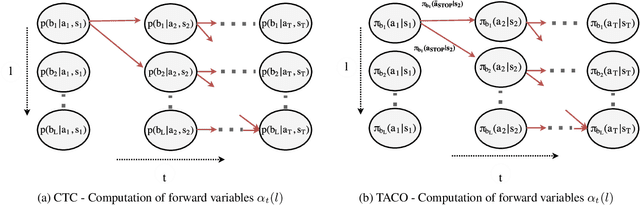

Many advanced Learning from Demonstration (LfD) methods consider the decomposition of complex, real-world tasks into simpler sub-tasks. By reusing the corresponding sub-policies within and between tasks, they provide training data for each policy from different high-level tasks and compose them to perform novel ones. Existing approaches to modular LfD focus either on learning a single high-level task or depend on domain knowledge and temporal segmentation. In contrast, we propose a weakly supervised, domain-agnostic approach based on task sketches, which include only the sequence of sub-tasks performed in each demonstration. Our approach simultaneously aligns the sketches with the observed demonstrations and learns the required sub-policies. This improves generalisation in comparison to separate optimisation procedures. We evaluate the approach on multiple domains, including a simulated 3D robot arm control task using purely image-based observations. The results show that our approach performs commensurately with fully supervised approaches, while requiring significantly less annotation effort.
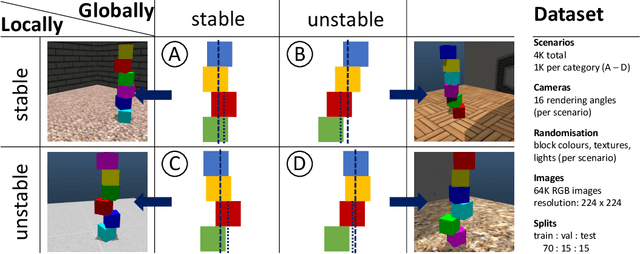
ShapeStacks: Learning Vision-Based Physical Intuition for Generalised Object Stacking
Jul 06, 2018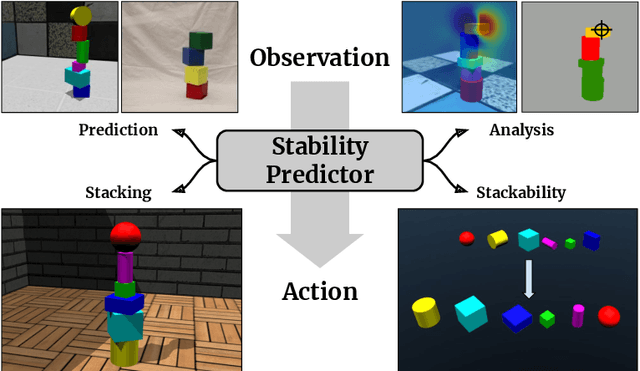
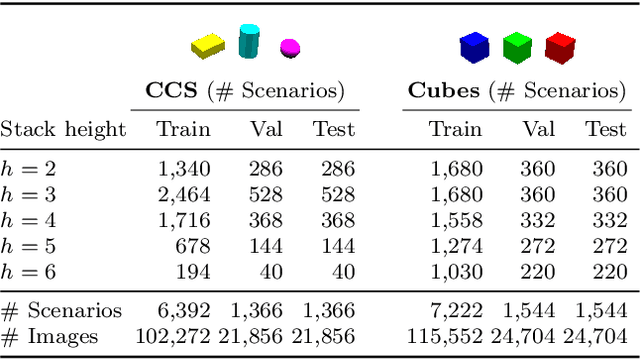
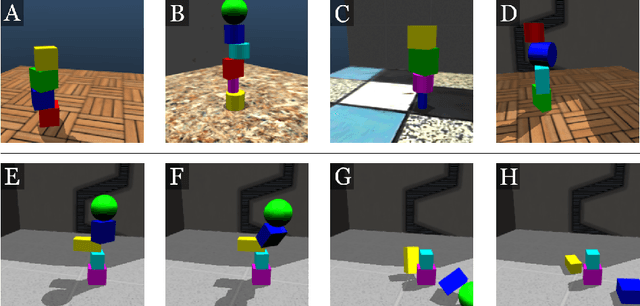
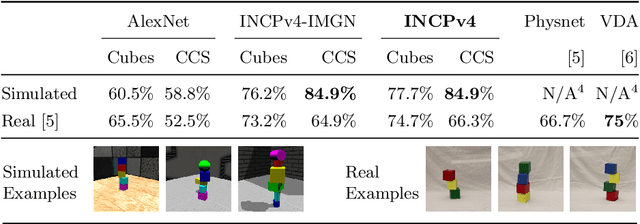
Physical intuition is pivotal for intelligent agents to perform complex tasks. In this paper we investigate the passive acquisition of an intuitive understanding of physical principles as well as the active utilisation of this intuition in the context of generalised object stacking. To this end, we provide: a simulation-based dataset featuring 20,000 stack configurations composed of a variety of elementary geometric primitives richly annotated regarding semantics and structural stability. We train visual classifiers for binary stability prediction on the ShapeStacks data and scrutinise their learned physical intuition. Due to the richness of the training data our approach also generalises favourably to real-world scenarios achieving state-of-the-art stability prediction on a publicly available benchmark of block towers. We then leverage the physical intuition learned by our model to actively construct stable stacks and observe the emergence of an intuitive notion of stackability - an inherent object affordance - induced by the active stacking task. Our approach performs well even in challenging conditions where it considerably exceeds the stack height observed during training or in cases where initially unstable structures must be stabilised via counterbalancing.
Neural Stethoscopes: Unifying Analytic, Auxiliary and Adversarial Network Probing
Jun 15, 2018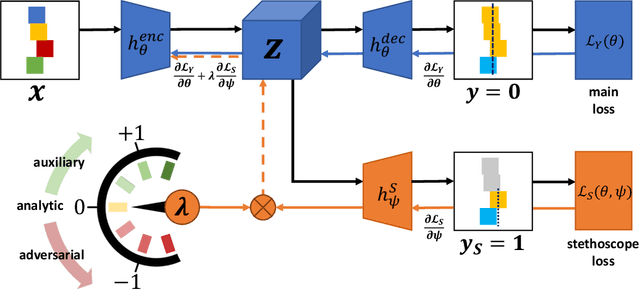
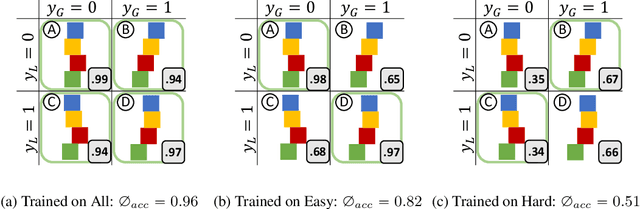
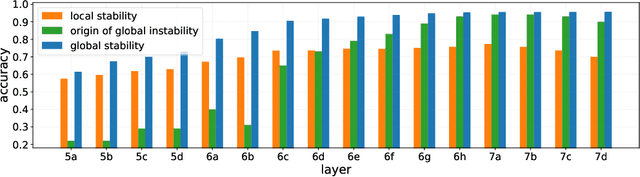
Model interpretability and systematic, targeted model adaptation present central tenets in machine learning for addressing limited or biased datasets. In this paper, we introduce neural stethoscopes as a framework for quantifying the degree of importance of specific factors of influence in deep networks as well as for actively promoting and suppressing information as appropriate. In doing so we unify concepts from multitask learning as well as training with auxiliary and adversarial losses. We showcase the efficacy of neural stethoscopes in an intuitive physics domain. Specifically, we investigate the challenge of visually predicting stability of block towers and demonstrate that the network uses visual cues which makes it susceptible to biases in the dataset. Through the use of stethoscopes we interrogate the accessibility of specific information throughout the network stack and show that we are able to actively de-bias network predictions as well as enhance performance via suitable auxiliary and adversarial stethoscope losses.