 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Variational Reward Factorization via Probabilistic Preference Bases for LLM Personalization
Apr 01, 2026Reward factorization personalizes large language models (LLMs) by decomposing rewards into shared basis functions and user-specific weights. Yet, existing methods estimate user weights from scarce data in isolation and as deterministic points, leading to inaccurate and unreliable inference. We introduce Variational Reward Factorization (VRF), an uncertainty-aware framework that represents each user's preferences as a variational distribution in a shared preference space. VRF infers user distributions via a variational encoder, derives weights through Wasserstein distance matching with shared probabilistic bases, and downweights uncertain estimates through a variance-attenuated loss. On three benchmarks, VRF outperforms all baselines across seen and unseen users, few-shot scenarios, and varying uncertainty levels, with gains extending to downstream alignment.
Harmonic Dataset Distillation for Time Series Forecasting
Mar 04, 2026Time Series forecasting (TSF) in the modern era faces significant computational and storage cost challenges due to the massive scale of real-world data. Dataset Distillation (DD), a paradigm that synthesizes a small, compact dataset to achieve training performance comparable to that of the original dataset, has emerged as a promising solution. However, conventional DD methods are not tailored for time series and suffer from architectural overfitting and limited scalability. To address these issues, we propose Harmonic Dataset Distillation for Time Series Forecasting (HDT). HDT decomposes the time series into its sinusoidal basis through the FFT and aligns the core periodic structure by Harmonic Matching. Since this process operates in the frequency domain, all updates during distillation are applied globally without disrupting temporal dependencies of time series. Extensive experiments demonstrate that HDT achieves strong cross-architecture generalization and scalability, validating its practicality for large-scale, real-world applications.
Leveraging Historical and Current Interests for Continual Sequential Recommendation
Jun 09, 2025Sequential recommendation models based on the Transformer architecture show superior performance in harnessing long-range dependencies within user behavior via self-attention. However, naively updating them on continuously arriving non-stationary data streams incurs prohibitive computation costs or leads to catastrophic forgetting. To address this, we propose Continual Sequential Transformer for Recommendation (CSTRec) that effectively leverages well-preserved historical user interests while capturing current interests. At its core is Continual Sequential Attention (CSA), a linear attention mechanism that retains past knowledge without direct access to old data. CSA integrates two key components: (1) Cauchy-Schwarz Normalization that stabilizes training under uneven interaction frequencies, and (2) Collaborative Interest Enrichment that mitigates forgetting through shared, learnable interest pools. We further introduce a technique that facilitates learning for cold-start users by transferring historical knowledge from behaviorally similar existing users. Extensive experiments on three real-world datasets indicate that CSTRec outperforms state-of-the-art baselines in both knowledge retention and acquisition.
Collaborative Diffusion Model for Recommender System
Jan 31, 2025



Diffusion-based recommender systems (DR) have gained increasing attention for their advanced generative and denoising capabilities. However, existing DR face two central limitations: (i) a trade-off between enhancing generative capacity via noise injection and retaining the loss of personalized information. (ii) the underutilization of rich item-side information. To address these challenges, we present a Collaborative Diffusion model for Recommender System (CDiff4Rec). Specifically, CDiff4Rec generates pseudo-users from item features and leverages collaborative signals from both real and pseudo personalized neighbors identified through behavioral similarity, thereby effectively reconstructing nuanced user preferences. Experimental results on three public datasets show that CDiff4Rec outperforms competitors by effectively mitigating the loss of personalized information through the integration of item content and collaborative signals.
Continual Collaborative Distillation for Recommender System
May 29, 2024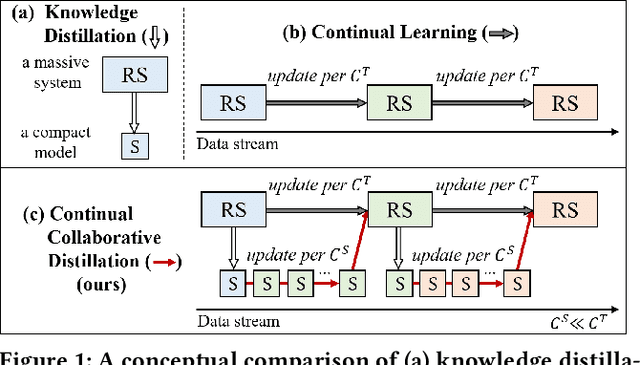
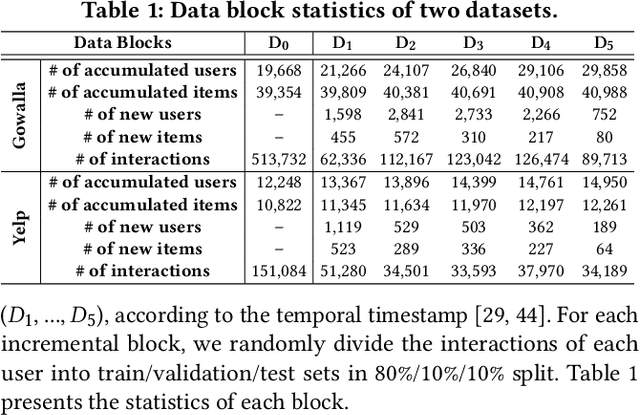
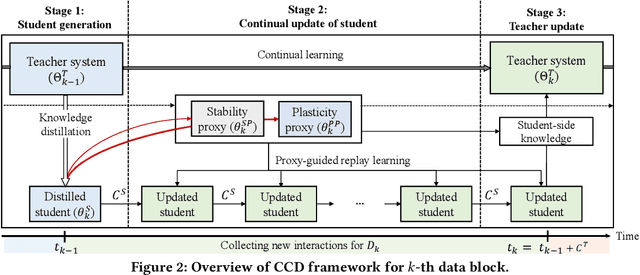
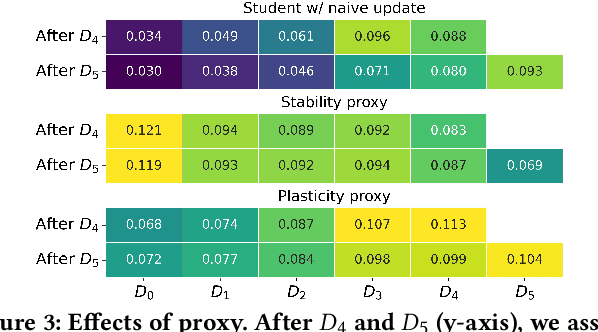
Knowledge distillation (KD) has emerged as a promising technique for addressing the computational challenges associated with deploying large-scale recommender systems. KD transfers the knowledge of a massive teacher system to a compact student model, to reduce the huge computational burdens for inference while retaining high accuracy. The existing KD studies primarily focus on one-time distillation in static environments, leaving a substantial gap in their applicability to real-world scenarios dealing with continuously incoming users, items, and their interactions. In this work, we delve into a systematic approach to operating the teacher-student KD in a non-stationary data stream. Our goal is to enable efficient deployment through a compact student, which preserves the high performance of the massive teacher, while effectively adapting to continuously incoming data. We propose Continual Collaborative Distillation (CCD) framework, where both the teacher and the student continually and collaboratively evolve along the data stream. CCD facilitates the student in effectively adapting to new data, while also enabling the teacher to fully leverage accumulated knowledge. We validate the effectiveness of CCD through extensive quantitative, ablative, and exploratory experiments on two real-world datasets. We expect this research direction to contribute to narrowing the gap between existing KD studies and practical applications, thereby enhancing the applicability of KD in real-world systems.