 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEPER: Step-wise Knowledge Distillation for Enhancing Reasoning Ability in Multi-Step Retrieval-Augmented Language Models
Oct 09, 2025Answering complex real-world questions requires step-by-step retrieval and integration of relevant information to generate well-grounded responses. However, existing knowledge distillation methods overlook the need for different reasoning abilities at different steps, hindering transfer in multi-step retrieval-augmented frameworks. To address this, we propose Stepwise Knowledge Distillation for Enhancing Reasoning Ability in Multi-Step Retrieval-Augmented Language Models (StepER). StepER employs step-wise supervision to align with evolving information and reasoning demands across stages. Additionally, it incorporates difficulty-aware training to progressively optimize learning by prioritizing suitable steps. Our method is adaptable to various multi-step retrieval-augmented language models, including those that use retrieval queries for reasoning paths or decomposed questions. Extensive experiments show that StepER outperforms prior methods on multi-hop QA benchmarks, with an 8B model achieving performance comparable to a 70B teacher model.
From What to Respond to When to Respond: Timely Response Generation for Open-domain Dialogue Agents
Jun 17, 2025While research on dialogue response generation has primarily focused on generating coherent responses conditioning on textual context, the critical question of when to respond grounded on the temporal context remains underexplored. To bridge this gap, we propose a novel task called timely dialogue response generation and introduce the TimelyChat benchmark, which evaluates the capabilities of language models to predict appropriate time intervals and generate time-conditioned responses. Additionally, we construct a large-scale training dataset by leveraging unlabeled event knowledge from a temporal commonsense knowledge graph and employing a large language model (LLM) to synthesize 55K event-driven dialogues. We then train Timer, a dialogue agent designed to proactively predict time intervals and generate timely responses that align with those intervals. Experimental results show that Timer outperforms prompting-based LLMs and other fine-tuned baselines in both turn-level and dialogue-level evaluations. We publicly release our data, model, and code.
Rectifying Demonstration Shortcut in In-Context Learning
Mar 29, 2024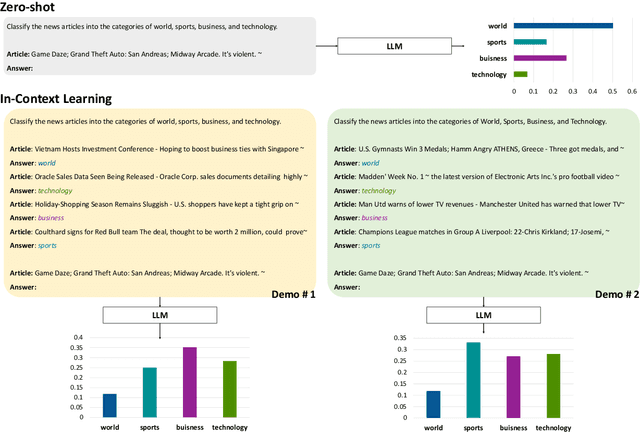
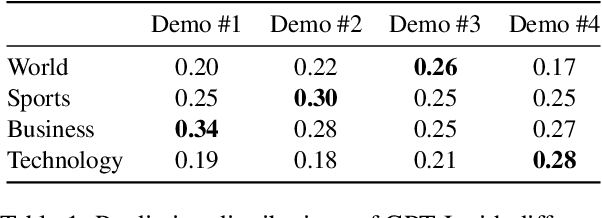
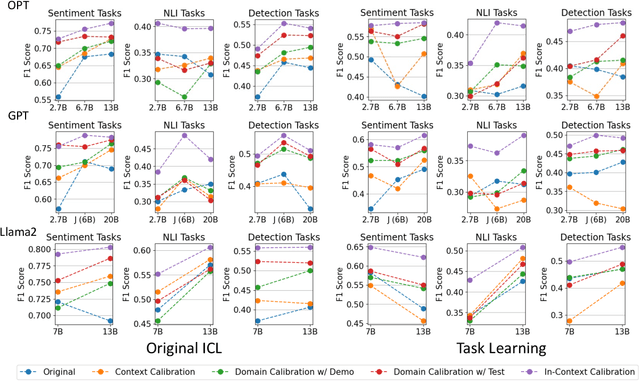

Large language models (LLMs) are able to solve various tasks with only a few demonstrations utilizing their in-context learning (ICL) abilities. However, LLMs often rely on their pre-trained semantic priors of demonstrations rather than on the input-label relationships to proceed with ICL prediction. In this work, we term this phenomenon as the 'Demonstration Shortcut'. While previous works have primarily focused on improving ICL prediction results for predefined tasks, we aim to rectify the Demonstration Shortcut, thereby enabling the LLM to effectively learn new input-label relationships from demonstrations. To achieve this, we introduce In-Context Calibration, a demonstration-aware calibration method. We evaluate the effectiveness of the proposed method in two settings: (1) the Original ICL Task using the standard label space and (2) the Task Learning setting, where the label space is replaced with semantically unrelated tokens. In both settings, In-Context Calibration demonstrates substantial improvements, with results generalized across three LLM families (OPT, GPT, and Llama2) under various configurations.