 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLM2Rec: Resolving Modality Collapse in Vision-Language Model Embedders for Multimodal Sequential Recommendation
Mar 18, 2026Sequential Recommendation (SR) in multimodal settings typically relies on small frozen pretrained encoders, which limits semantic capacity and prevents Collaborative Filtering (CF) signals from being fully integrated into item representations. Inspired by the recent success of Large Language Models (LLMs) as high-capacity embedders, we investigate the use of Vision-Language Models (VLMs) as CF-aware multimodal encoders for SR. However, we find that standard contrastive supervised fine-tuning (SFT), which adapts VLMs for embedding generation and injects CF signals, can amplify its inherent modality collapse. In this state, optimization is dominated by a single modality while the other degrades, ultimately undermining recommendation accuracy. To address this, we propose VLM2Rec, a VLM embedder-based framework for multimodal sequential recommendation designed to ensure balanced modality utilization. Specifically, we introduce Weak-modality Penalized Contrastive Learning to rectify gradient imbalance during optimization and Cross-Modal Relational Topology Regularization to preserve geometric consistency between modalities. Extensive experiments demonstrate that VLM2Rec consistently outperforms state-of-the-art baselines in both accuracy and robustness across diverse scenarios.
Personalized Federated Recommendation With Knowledge Guidance
Nov 18, 2025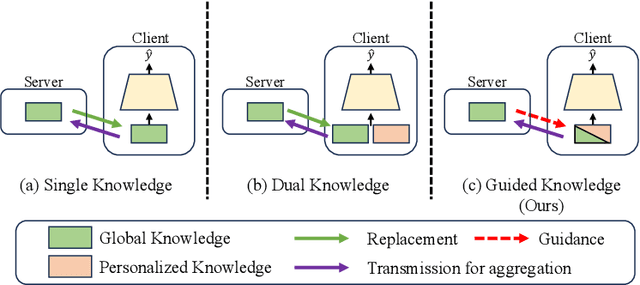


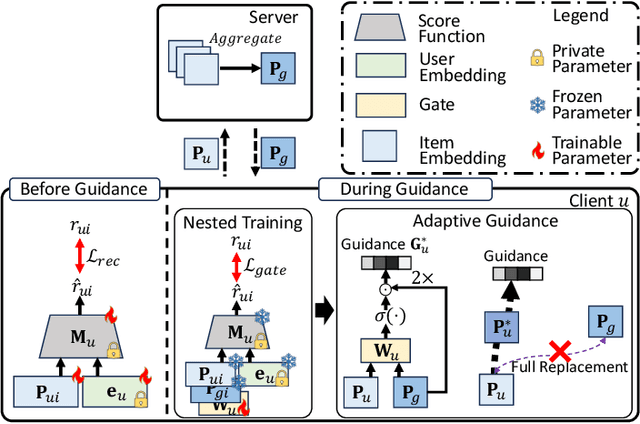
Federated Recommendation (FedRec) has emerged as a key paradigm for building privacy-preserving recommender systems. However, existing FedRec models face a critical dilemma: memory-efficient single-knowledge models suffer from a suboptimal knowledge replacement practice that discards valuable personalization, while high-performance dual-knowledge models are often too memory-intensive for practical on-device deployment. We propose Federated Recommendation with Knowledge Guidance (FedRKG), a model-agnostic framework that resolves this dilemma. The core principle, Knowledge Guidance, avoids full replacement and instead fuses global knowledge into preserved local embeddings, attaining the personalization benefits of dual-knowledge within a single-knowledge memory footprint. Furthermore, we introduce Adaptive Guidance, a fine-grained mechanism that dynamically modulates the intensity of this guidance for each user-item interaction, overcoming the limitations of static fusion methods. Extensive experiments on benchmark datasets demonstrate that FedRKG significantly outperforms state-of-the-art methods, validating the effectiveness of our approach. The code is available at https://github.com/Jaehyung-Lim/fedrkg.
Federated Continual Recommendation
Aug 06, 2025The increasing emphasis on privacy in recommendation systems has led to the adoption of Federated Learning (FL) as a privacy-preserving solution, enabling collaborative training without sharing user data. While Federated Recommendation (FedRec) effectively protects privacy, existing methods struggle with non-stationary data streams, failing to maintain consistent recommendation quality over time. On the other hand, Continual Learning Recommendation (CLRec) methods address evolving user preferences but typically assume centralized data access, making them incompatible with FL constraints. To bridge this gap, we introduce Federated Continual Recommendation (FCRec), a novel task that integrates FedRec and CLRec, requiring models to learn from streaming data while preserving privacy. As a solution, we propose F3CRec, a framework designed to balance knowledge retention and adaptation under the strict constraints of FCRec. F3CRec introduces two key components: Adaptive Replay Memory on the client side, which selectively retains past preferences based on user-specific shifts, and Item-wise Temporal Mean on the server side, which integrates new knowledge while preserving prior information. Extensive experiments demonstrate that F3CRec outperforms existing approaches in maintaining recommendation quality over time in a federated environment.