 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHui Huang
Prior-agnostic Multi-scale Contrastive Text-Audio Pre-training for Parallelized TTS Frontend Modeling
Apr 14, 2024
Over the past decade, a series of unflagging efforts have been dedicated to developing highly expressive and controllable text-to-speech (TTS) systems. In general, the holistic TTS comprises two interconnected components: the frontend module and the backend module. The frontend excels in capturing linguistic representations from the raw text input, while the backend module converts linguistic cues to speech. The research community has shown growing interest in the study of the frontend component, recognizing its pivotal role in text-to-speech systems, including Text Normalization (TN), Prosody Boundary Prediction (PBP), and Polyphone Disambiguation (PD). Nonetheless, the limitations posed by insufficient annotated textual data and the reliance on homogeneous text signals significantly undermine the effectiveness of its supervised learning. To evade this obstacle, a novel two-stage TTS frontend prediction pipeline, named TAP-FM, is proposed in this paper. Specifically, during the first learning phase, we present a Multi-scale Contrastive Text-audio Pre-training protocol (MC-TAP), which hammers at acquiring richer insights via multi-granularity contrastive pre-training in an unsupervised manner. Instead of mining homogeneous features in prior pre-training approaches, our framework demonstrates the ability to delve deep into both global and local text-audio semantic and acoustic representations. Furthermore, a parallelized TTS frontend model is delicately devised to execute TN, PD, and PBP prediction tasks, respectively in the second stage. Finally, extensive experiments illustrate the superiority of our proposed method, achieving state-of-the-art performance.
InterFusion: Text-Driven Generation of 3D Human-Object Interaction
Mar 22, 2024In this study, we tackle the complex task of generating 3D human-object interactions (HOI) from textual descriptions in a zero-shot text-to-3D manner. We identify and address two key challenges: the unsatisfactory outcomes of direct text-to-3D methods in HOI, largely due to the lack of paired text-interaction data, and the inherent difficulties in simultaneously generating multiple concepts with complex spatial relationships. To effectively address these issues, we present InterFusion, a two-stage framework specifically designed for HOI generation. InterFusion involves human pose estimations derived from text as geometric priors, which simplifies the text-to-3D conversion process and introduces additional constraints for accurate object generation. At the first stage, InterFusion extracts 3D human poses from a synthesized image dataset depicting a wide range of interactions, subsequently mapping these poses to interaction descriptions. The second stage of InterFusion capitalizes on the latest developments in text-to-3D generation, enabling the production of realistic and high-quality 3D HOI scenes. This is achieved through a local-global optimization process, where the generation of human body and object is optimized separately, and jointly refined with a global optimization of the entire scene, ensuring a seamless and contextually coherent integration. Our experimental results affirm that InterFusion significantly outperforms existing state-of-the-art methods in 3D HOI generation.
Synchronized Dual-arm Rearrangement via Cooperative mTSP
Mar 13, 2024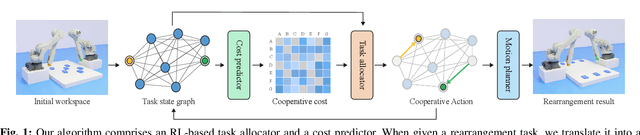
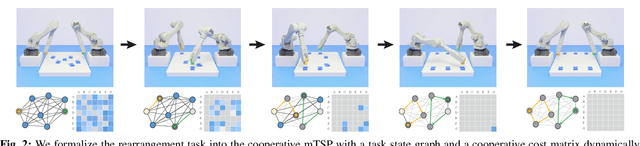
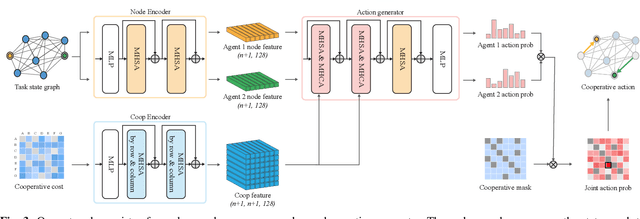

Synchronized dual-arm rearrangement is widely studied as a common scenario in industrial applications. It often faces scalability challenges due to the computational complexity of robotic arm rearrangement and the high-dimensional nature of dual-arm planning. To address these challenges, we formulated the problem as cooperative mTSP, a variant of mTSP where agents share cooperative costs, and utilized reinforcement learning for its solution. Our approach involved representing rearrangement tasks using a task state graph that captured spatial relationships and a cooperative cost matrix that provided details about action costs. Taking these representations as observations, we designed an attention-based network to effectively combine them and provide rational task scheduling. Furthermore, a cost predictor is also introduced to directly evaluate actions during both training and planning, significantly expediting the planning process. Our experimental results demonstrate that our approach outperforms existing methods in terms of both performance and planning efficiency.
Self-Evaluation of Large Language Model based on Glass-box Features
Mar 07, 2024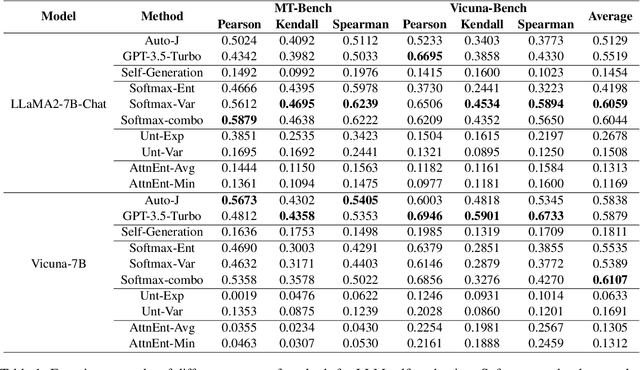

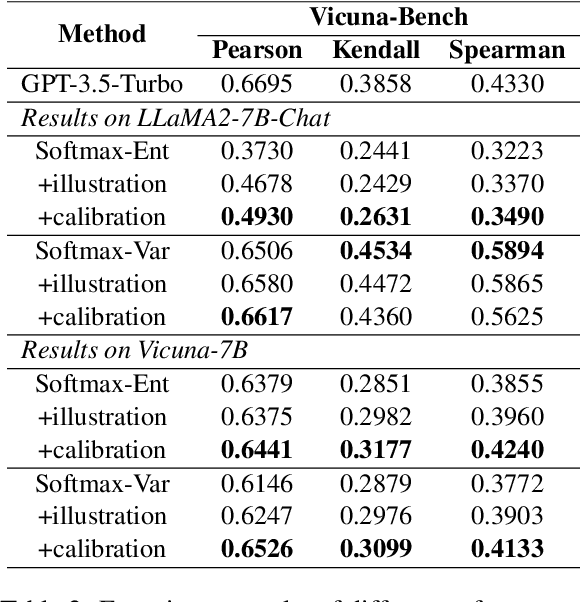
The proliferation of open-source Large Language Models (LLMs) underscores the pressing need for evaluation methods. Existing works primarily rely on external evaluators, focusing on training and prompting strategies. However, a crucial aspect - model-aware glass-box features - is overlooked. In this study, we explore the utility of glass-box features under the scenario of self-evaluation, namely applying an LLM to evaluate its own output. We investigate various glass-box feature groups and discovered that the softmax distribution serves as a reliable indicator for quality evaluation. Furthermore, we propose two strategies to enhance the evaluation by incorporating features derived from references. Experimental results on public benchmarks validate the feasibility of self-evaluation of LLMs using glass-box features.
An Empirical Study of LLM-as-a-Judge for LLM Evaluation: Fine-tuned Judge Models are Task-specific Classifiers
Mar 05, 2024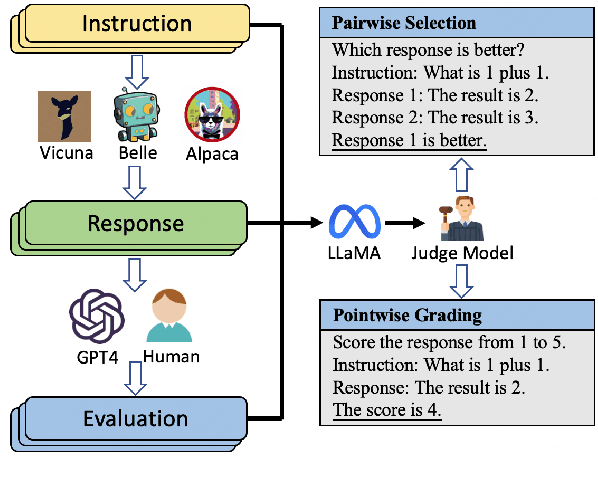
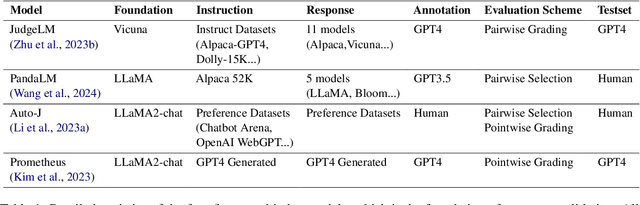
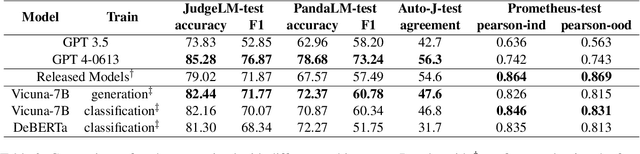
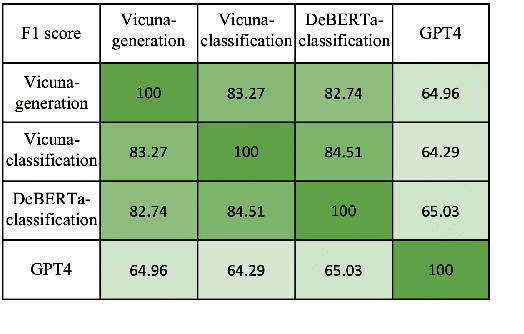
Recently, there has been a growing trend of utilizing Large Language Model (LLM) to evaluate the quality of other LLMs. Many studies have employed proprietary close-source models, especially GPT4, as the evaluator. Alternatively, other works have fine-tuned judge models based on open-source LLMs as the evaluator. In this study, we conduct an empirical study of different judge models on their evaluation capability. Our findings indicate that although the fine-tuned judge models achieve high accuracy on in-domain test sets, even surpassing GPT4, they are inherently task-specific classifiers, and their generalizability and fairness severely underperform GPT4.
Deformable One-shot Face Stylization via DINO Semantic Guidance
Mar 04, 2024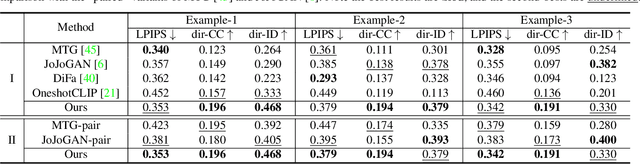


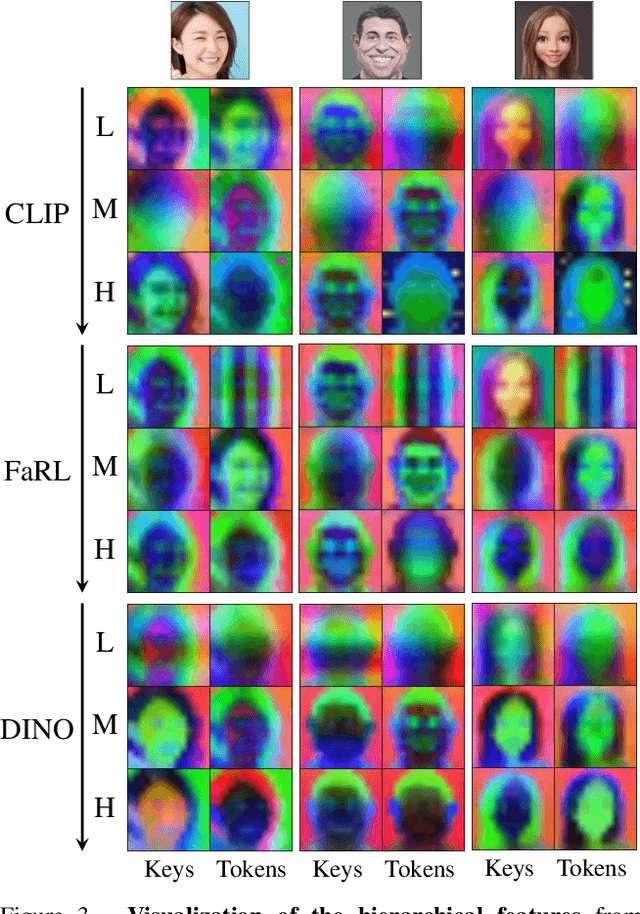
This paper addresses the complex issue of one-shot face stylization, focusing on the simultaneous consideration of appearance and structure, where previous methods have fallen short. We explore deformation-aware face stylization that diverges from traditional single-image style reference, opting for a real-style image pair instead. The cornerstone of our method is the utilization of a self-supervised vision transformer, specifically DINO-ViT, to establish a robust and consistent facial structure representation across both real and style domains. Our stylization process begins by adapting the StyleGAN generator to be deformation-aware through the integration of spatial transformers (STN). We then introduce two innovative constraints for generator fine-tuning under the guidance of DINO semantics: i) a directional deformation loss that regulates directional vectors in DINO space, and ii) a relative structural consistency constraint based on DINO token self-similarities, ensuring diverse generation. Additionally, style-mixing is employed to align the color generation with the reference, minimizing inconsistent correspondences. This framework delivers enhanced deformability for general one-shot face stylization, achieving notable efficiency with a fine-tuning duration of approximately 10 minutes. Extensive qualitative and quantitative comparisons demonstrate our superiority over state-of-the-art one-shot face stylization methods. Code is available at https://github.com/zichongc/DoesFS
Unsupervised Generation of Pseudo Normal PET from MRI with Diffusion Model for Epileptic Focus Localization
Feb 02, 2024[$^{18}$F]fluorodeoxyglucose (FDG) positron emission tomography (PET) has emerged as a crucial tool in identifying the epileptic focus, especially in cases where magnetic resonance imaging (MRI) diagnosis yields indeterminate results. FDG PET can provide the metabolic information of glucose and help identify abnormal areas that are not easily found through MRI. However, the effectiveness of FDG PET-based assessment and diagnosis depends on the selection of a healthy control group. The healthy control group typically consists of healthy individuals similar to epilepsy patients in terms of age, gender, and other aspects for providing normal FDG PET data, which will be used as a reference for enhancing the accuracy and reliability of the epilepsy diagnosis. However, significant challenges arise when a healthy PET control group is unattainable. Yaakub \emph{et al.} have previously introduced a Pix2PixGAN-based method for MRI to PET translation. This method used paired MRI and FDG PET scans from healthy individuals for training, and produced pseudo normal FDG PET images from patient MRIs that are subsequently used for lesion detection. However, this approach requires a large amount of high-quality, paired MRI and PET images from healthy control subjects, which may not always be available. In this study, we investigated unsupervised learning methods for unpaired MRI to PET translation for generating pseudo normal FDG PET for epileptic focus localization. Two deep learning methods, CycleGAN and SynDiff, were employed, and we found that diffusion-based method achieved improved performance in accurately localizing the epileptic focus.
Cross Domain Early Crop Mapping using CropGAN and CNN Classifier
Jan 15, 2024Driven by abundant satellite imagery, machine learning-based approaches have recently been promoted to generate high-resolution crop cultivation maps to support many agricultural applications. One of the major challenges faced by these approaches is the limited availability of ground truth labels. In the absence of ground truth, existing work usually adopts the "direct transfer strategy" that trains a classifier using historical labels collected from other regions and then applies the trained model to the target region. Unfortunately, the spectral features of crops exhibit inter-region and inter-annual variability due to changes in soil composition, climate conditions, and crop progress, the resultant models perform poorly on new and unseen regions or years. This paper presents the Crop Generative Adversarial Network (CropGAN) to address the above cross-domain issue. Our approach does not need labels from the target domain. Instead, it learns a mapping function to transform the spectral features of the target domain to the source domain (with labels) while preserving their local structure. The classifier trained by the source domain data can be directly applied to the transformed data to produce high-accuracy early crop maps of the target domain. Comprehensive experiments across various regions and years demonstrate the benefits and effectiveness of the proposed approach. Compared with the widely adopted direct transfer strategy, the F1 score after applying the proposed CropGAN is improved by 13.13% - 50.98%
EmoGen: Emotional Image Content Generation with Text-to-Image Diffusion Models
Jan 09, 2024Recent years have witnessed remarkable progress in image generation task, where users can create visually astonishing images with high-quality. However, existing text-to-image diffusion models are proficient in generating concrete concepts (dogs) but encounter challenges with more abstract ones (emotions). Several efforts have been made to modify image emotions with color and style adjustments, facing limitations in effectively conveying emotions with fixed image contents. In this work, we introduce Emotional Image Content Generation (EICG), a new task to generate semantic-clear and emotion-faithful images given emotion categories. Specifically, we propose an emotion space and construct a mapping network to align it with the powerful Contrastive Language-Image Pre-training (CLIP) space, providing a concrete interpretation of abstract emotions. Attribute loss and emotion confidence are further proposed to ensure the semantic diversity and emotion fidelity of the generated images. Our method outperforms the state-of-the-art text-to-image approaches both quantitatively and qualitatively, where we derive three custom metrics, i.e., emotion accuracy, semantic clarity and semantic diversity. In addition to generation, our method can help emotion understanding and inspire emotional art design.
Generating Non-Stationary Textures using Self-Rectification
Jan 05, 2024This paper addresses the challenge of example-based non-stationary texture synthesis. We introduce a novel twostep approach wherein users first modify a reference texture using standard image editing tools, yielding an initial rough target for the synthesis. Subsequently, our proposed method, termed "self-rectification", automatically refines this target into a coherent, seamless texture, while faithfully preserving the distinct visual characteristics of the reference exemplar. Our method leverages a pre-trained diffusion network, and uses self-attention mechanisms, to gradually align the synthesized texture with the reference, ensuring the retention of the structures in the provided target. Through experimental validation, our approach exhibits exceptional proficiency in handling non-stationary textures, demonstrating significant advancements in texture synthesis when compared to existing state-of-the-art techniques. Code is available at https://github.com/xiaorongjun000/Self-Rectification