 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Massive Multitask Chinese Understanding
May 15, 2023



The development of large-scale Chinese language models is flourishing, yet there is a lack of corresponding capability assessments. Therefore, we propose a test to measure the multitask accuracy of large Chinese language models. This test encompasses four major domains, including medicine, law, psychology, and education, with 15 subtasks in medicine and 8 subtasks in education. We found that the best-performing models in the zero-shot setting outperformed the worst-performing models by nearly 18.6 percentage points on average. Across the four major domains, the highest average zero-shot accuracy of all models is 0.512. In the subdomains, only the GPT-3.5-turbo model achieved a zero-shot accuracy of 0.693 in clinical medicine, which was the highest accuracy among all models across all subtasks. All models performed poorly in the legal domain, with the highest zero-shot accuracy reaching only 0.239. By comprehensively evaluating the breadth and depth of knowledge across multiple disciplines, this test can more accurately identify the shortcomings of the models.
Human Guided Ground-truth Generation for Realistic Image Super-resolution
Mar 23, 2023



How to generate the ground-truth (GT) image is a critical issue for training realistic image super-resolution (Real-ISR) models. Existing methods mostly take a set of high-resolution (HR) images as GTs and apply various degradations to simulate their low-resolution (LR) counterparts. Though great progress has been achieved, such an LR-HR pair generation scheme has several limitations. First, the perceptual quality of HR images may not be high enough, limiting the quality of Real-ISR outputs. Second, existing schemes do not consider much human perception in GT generation, and the trained models tend to produce over-smoothed results or unpleasant artifacts. With the above considerations, we propose a human guided GT generation scheme. We first elaborately train multiple image enhancement models to improve the perceptual quality of HR images, and enable one LR image having multiple HR counterparts. Human subjects are then involved to annotate the high quality regions among the enhanced HR images as GTs, and label the regions with unpleasant artifacts as negative samples. A human guided GT image dataset with both positive and negative samples is then constructed, and a loss function is proposed to train the Real-ISR models. Experiments show that the Real-ISR models trained on our dataset can produce perceptually more realistic results with less artifacts. Dataset and codes can be found at https://github.com/ChrisDud0257/HGGT
Efficient and Degradation-Adaptive Network for Real-World Image Super-Resolution
Mar 27, 2022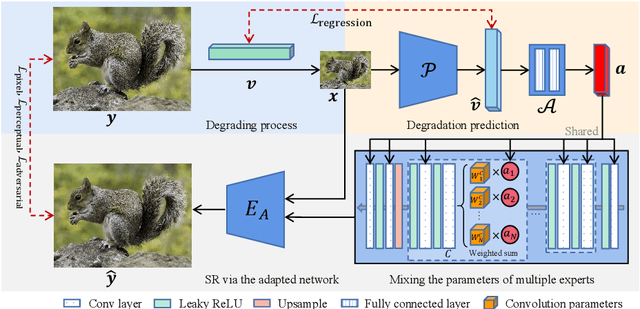
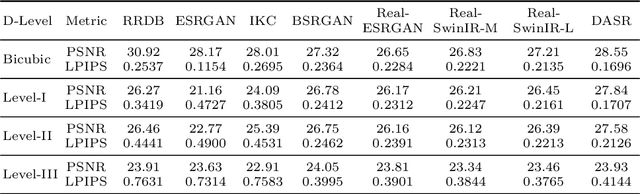

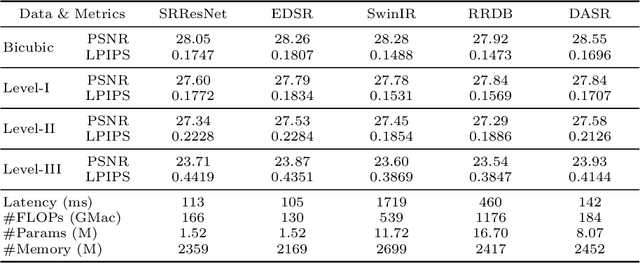
Efficient and effective real-world image super-resolution (Real-ISR) is a challenging task due to the unknown complex degradation of real-world images and the limited computation resources in practical applications. Recent research on Real-ISR has achieved significant progress by modeling the image degradation space; however, these methods largely rely on heavy backbone networks and they are inflexible to handle images of different degradation levels. In this paper, we propose an efficient and effective degradation-adaptive super-resolution (DASR) network, whose parameters are adaptively specified by estimating the degradation of each input image. Specifically, a tiny regression network is employed to predict the degradation parameters of the input image, while several convolutional experts with the same topology are jointly optimized to specify the network parameters via a non-linear mixture of experts. The joint optimization of multiple experts and the degradation-adaptive pipeline significantly extend the model capacity to handle degradations of various levels, while the inference remains efficient since only one adaptively specified network is used for super-resolving the input image. Our extensive experiments demonstrate that the proposed DASR is not only much more effective than existing methods on handling real-world images with different degradation levels but also efficient for easy deployment. Codes, models and datasets are available at https://github.com/csjliang/DASR.
Details or Artifacts: A Locally Discriminative Learning Approach to Realistic Image Super-Resolution
Mar 17, 2022
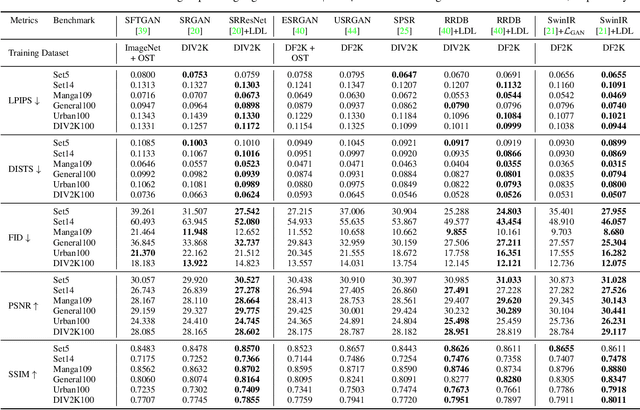
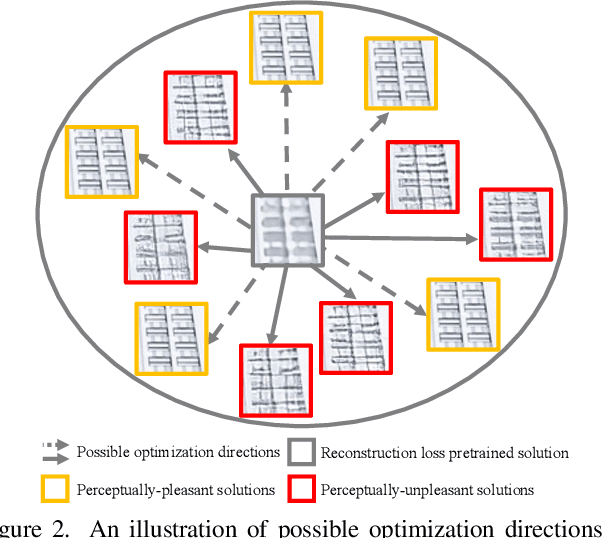
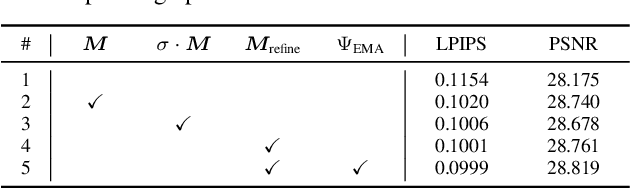
Single image super-resolution (SISR) with generative adversarial networks (GAN) has recently attracted increasing attention due to its potentials to generate rich details. However, the training of GAN is unstable, and it often introduces many perceptually unpleasant artifacts along with the generated details. In this paper, we demonstrate that it is possible to train a GAN-based SISR model which can stably generate perceptually realistic details while inhibiting visual artifacts. Based on the observation that the local statistics (e.g., residual variance) of artifact areas are often different from the areas of perceptually friendly details, we develop a framework to discriminate between GAN-generated artifacts and realistic details, and consequently generate an artifact map to regularize and stabilize the model training process. Our proposed locally discriminative learning (LDL) method is simple yet effective, which can be easily plugged in off-the-shelf SISR methods and boost their performance. Experiments demonstrate that LDL outperforms the state-of-the-art GAN based SISR methods, achieving not only higher reconstruction accuracy but also superior perceptual quality on both synthetic and real-world datasets. Codes and models are available at https://github.com/csjliang/LDL.
Efficient Long-Range Attention Network for Image Super-resolution
Mar 13, 2022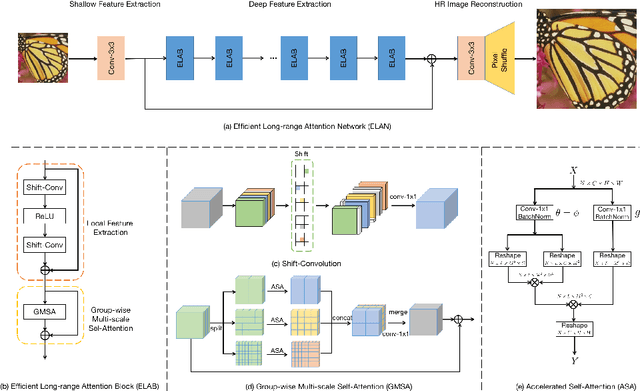
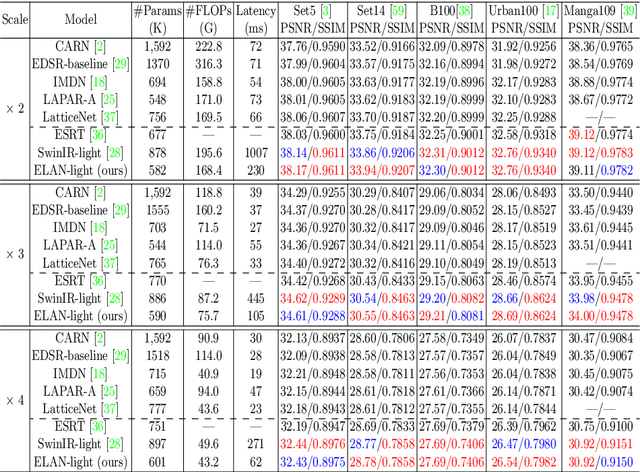
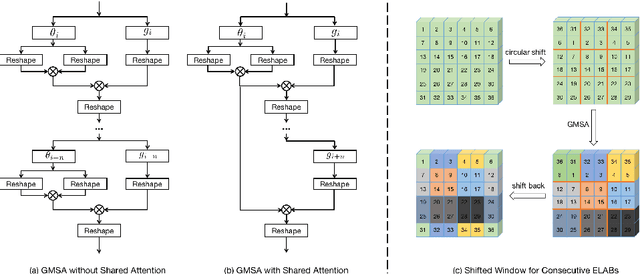
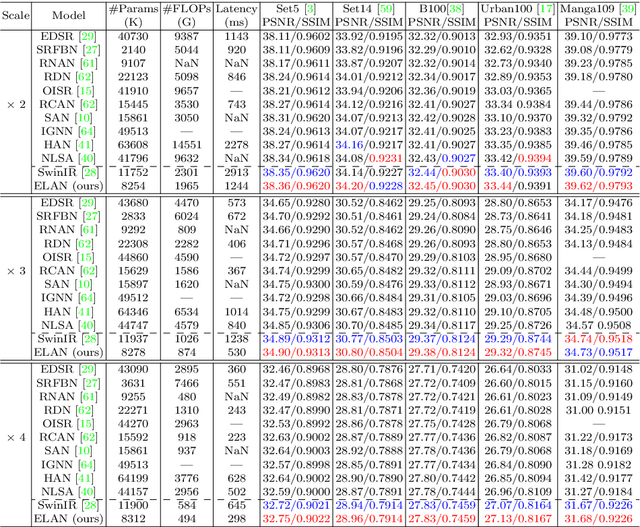
Recently, transformer-based methods have demonstrated impressive results in various vision tasks, including image super-resolution (SR), by exploiting the self-attention (SA) for feature extraction. However, the computation of SA in most existing transformer based models is very expensive, while some employed operations may be redundant for the SR task. This limits the range of SA computation and consequently the SR performance. In this work, we propose an efficient long-range attention network (ELAN) for image SR. Specifically, we first employ shift convolution (shift-conv) to effectively extract the image local structural information while maintaining the same level of complexity as 1x1 convolution, then propose a group-wise multi-scale self-attention (GMSA) module, which calculates SA on non-overlapped groups of features using different window sizes to exploit the long-range image dependency. A highly efficient long-range attention block (ELAB) is then built by simply cascading two shift-conv with a GMSA module, which is further accelerated by using a shared attention mechanism. Without bells and whistles, our ELAN follows a fairly simple design by sequentially cascading the ELABs. Extensive experiments demonstrate that ELAN obtains even better results against the transformer-based SR models but with significantly less complexity. The source code can be found at https://github.com/xindongzhang/ELAN.
A comparison study of CNN denoisers on PRNU extraction
Dec 06, 2021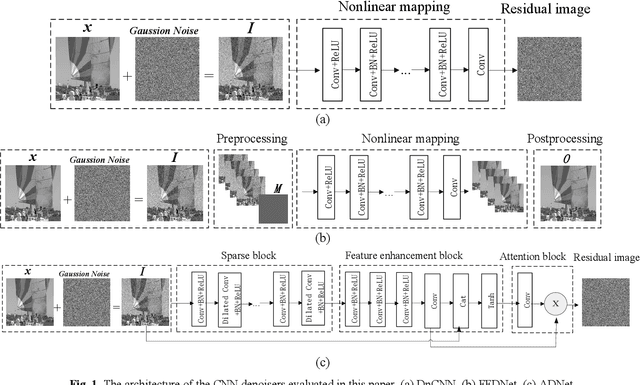
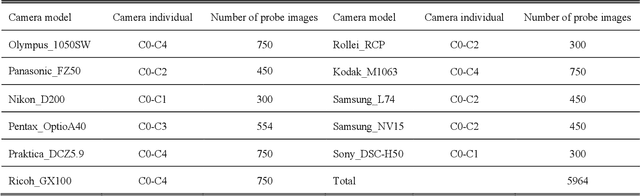
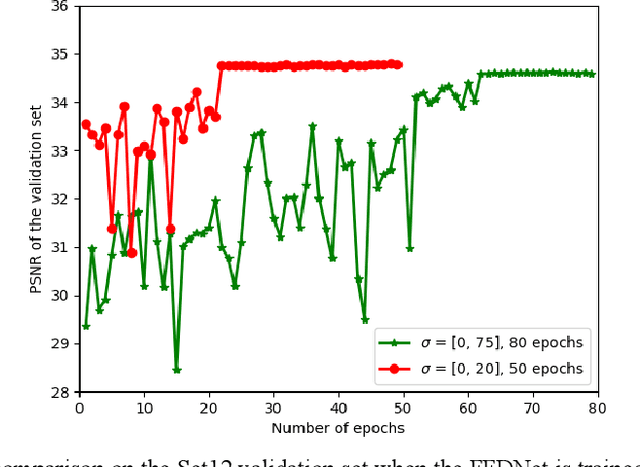
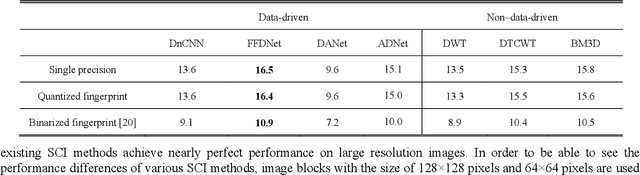
Performance of the sensor-based camera identification (SCI) method heavily relies on the denoising filter in estimating Photo-Response Non-Uniformity (PRNU). Given various attempts on enhancing the quality of the extracted PRNU, it still suffers from unsatisfactory performance in low-resolution images and high computational demand. Leveraging the similarity of PRNU estimation and image denoising, we take advantage of the latest achievements of Convolutional Neural Network (CNN)-based denoisers for PRNU extraction. In this paper, a comparative evaluation of such CNN denoisers on SCI performance is carried out on the public "Dresden Image Database". Our findings are two-fold. From one aspect, both the PRNU extraction and image denoising separate noise from the image content. Hence, SCI can benefit from the recent CNN denoisers if carefully trained. From another aspect, the goals and the scenarios of PRNU extraction and image denoising are different since one optimizes the quality of noise and the other optimizes the image quality. A carefully tailored training is needed when CNN denoisers are used for PRNU estimation. Alternative strategies of training data preparation and loss function design are analyzed theoretically and evaluated experimentally. We point out that feeding the CNNs with image-PRNU pairs and training them with correlation-based loss function result in the best PRNU estimation performance. To facilitate further studies of SCI, we also propose a minimum-loss camera fingerprint quantization scheme using which we save the fingerprints as image files in PNG format. Furthermore, we make the quantized fingerprints of the cameras from the "Dresden Image Database" publicly available.
High-Resolution Photorealistic Image Translation in Real-Time: A Laplacian Pyramid Translation Network
May 19, 2021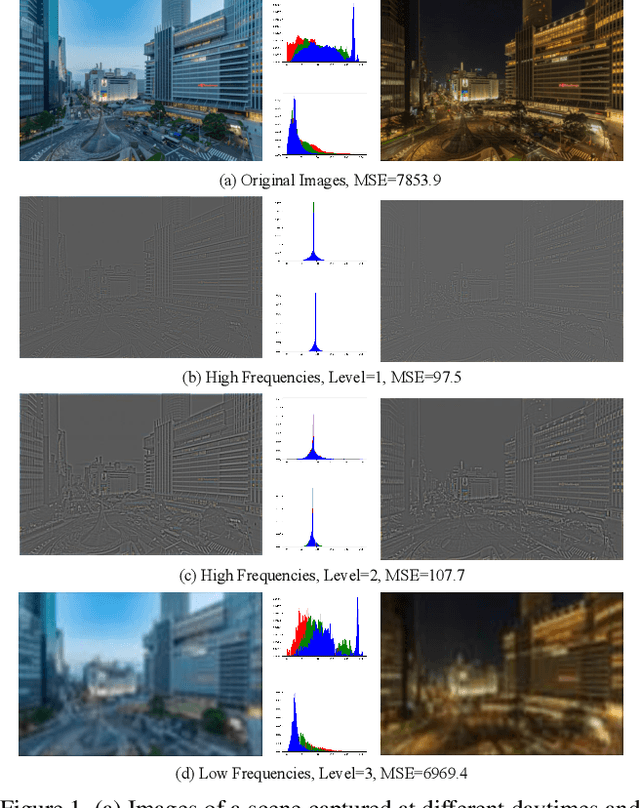
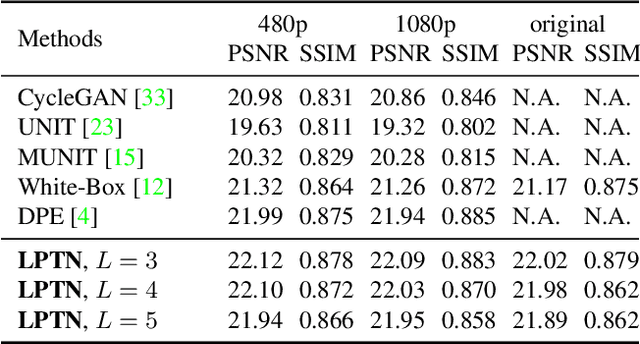
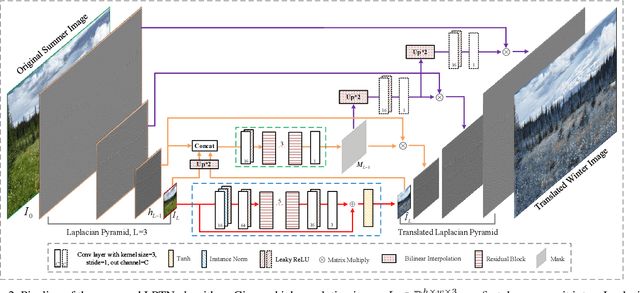
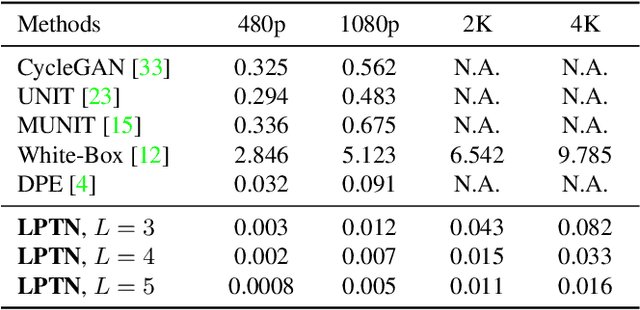
Existing image-to-image translation (I2IT) methods are either constrained to low-resolution images or long inference time due to their heavy computational burden on the convolution of high-resolution feature maps. In this paper, we focus on speeding-up the high-resolution photorealistic I2IT tasks based on closed-form Laplacian pyramid decomposition and reconstruction. Specifically, we reveal that the attribute transformations, such as illumination and color manipulation, relate more to the low-frequency component, while the content details can be adaptively refined on high-frequency components. We consequently propose a Laplacian Pyramid Translation Network (LPTN) to simultaneously perform these two tasks, where we design a lightweight network for translating the low-frequency component with reduced resolution and a progressive masking strategy to efficiently refine the high-frequency ones. Our model avoids most of the heavy computation consumed by processing high-resolution feature maps and faithfully preserves the image details. Extensive experimental results on various tasks demonstrate that the proposed method can translate 4K images in real-time using one normal GPU while achieving comparable transformation performance against existing methods. Datasets and codes are available: https://github.com/csjliang/LPTN.
PPR10K: A Large-Scale Portrait Photo Retouching Dataset with Human-Region Mask and Group-Level Consistency
May 19, 2021



Different from general photo retouching tasks, portrait photo retouching (PPR), which aims to enhance the visual quality of a collection of flat-looking portrait photos, has its special and practical requirements such as human-region priority (HRP) and group-level consistency (GLC). HRP requires that more attention should be paid to human regions, while GLC requires that a group of portrait photos should be retouched to a consistent tone. Models trained on existing general photo retouching datasets, however, can hardly meet these requirements of PPR. To facilitate the research on this high-frequency task, we construct a large-scale PPR dataset, namely PPR10K, which is the first of its kind to our best knowledge. PPR10K contains $1, 681$ groups and $11, 161$ high-quality raw portrait photos in total. High-resolution segmentation masks of human regions are provided. Each raw photo is retouched by three experts, while they elaborately adjust each group of photos to have consistent tones. We define a set of objective measures to evaluate the performance of PPR and propose strategies to learn PPR models with good HRP and GLC performance. The constructed PPR10K dataset provides a good benchmark for studying automatic PPR methods, and experiments demonstrate that the proposed learning strategies are effective to improve the retouching performance. Datasets and codes are available: https://github.com/csjliang/PPR10K.
Real-Time Quantized Image Super-Resolution on Mobile NPUs, Mobile AI 2021 Challenge: Report
May 17, 2021
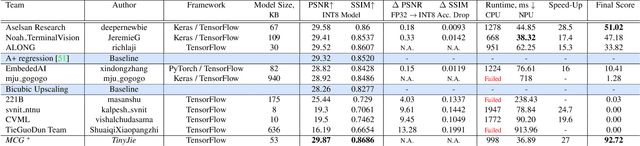
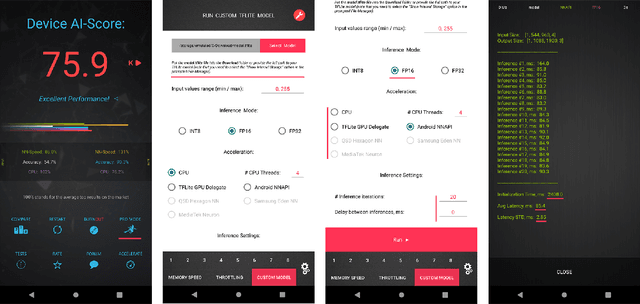
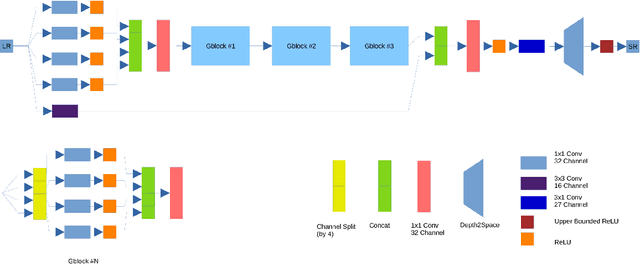
Image super-resolution is one of the most popular computer vision problems with many important applications to mobile devices. While many solutions have been proposed for this task, they are usually not optimized even for common smartphone AI hardware, not to mention more constrained smart TV platforms that are often supporting INT8 inference only. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based image super-resolution solutions that can demonstrate a real-time performance on mobile or edge NPUs. For this, the participants were provided with the DIV2K dataset and trained quantized models to do an efficient 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated NPU capable of accelerating quantized neural networks. The proposed solutions are fully compatible with all major mobile AI accelerators and are capable of reconstructing Full HD images under 40-60 ms while achieving high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.
Learning Image-adaptive 3D Lookup Tables for High Performance Photo Enhancement in Real-time
Sep 30, 2020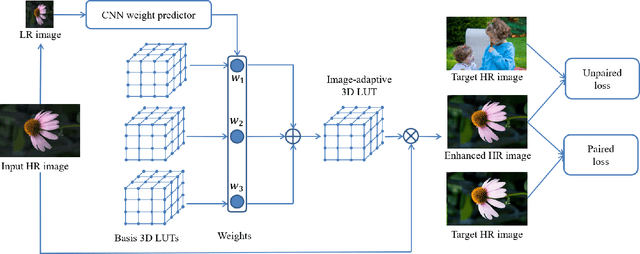

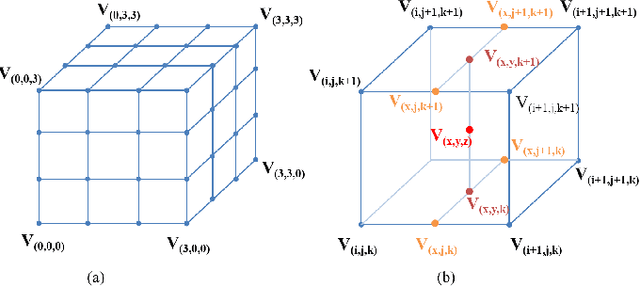
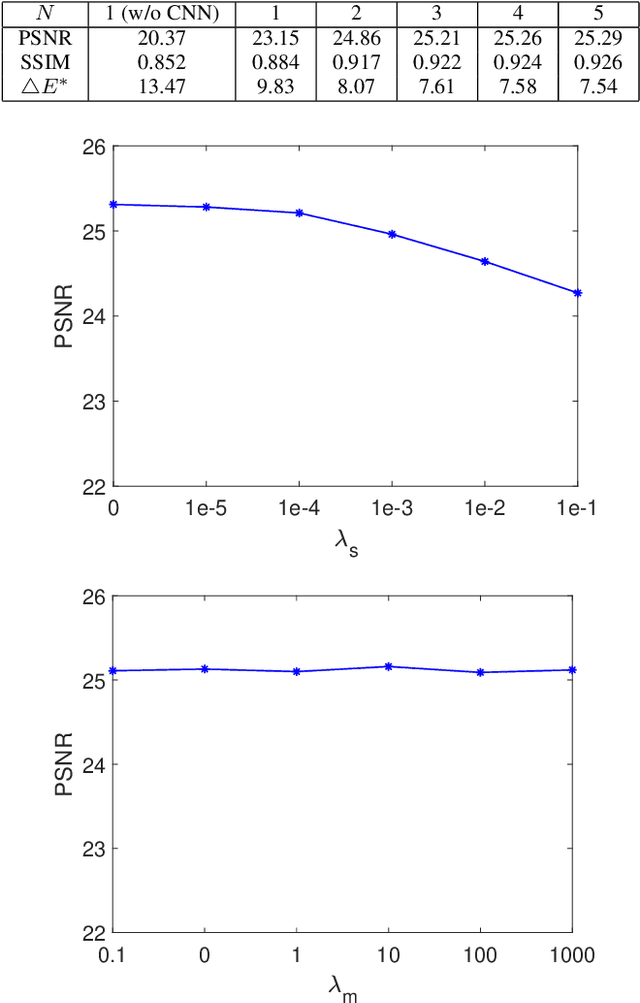
Recent years have witnessed the increasing popularity of learning based methods to enhance the color and tone of photos. However, many existing photo enhancement methods either deliver unsatisfactory results or consume too much computational and memory resources, hindering their application to high-resolution images (usually with more than 12 megapixels) in practice. In this paper, we learn image-adaptive 3-dimensional lookup tables (3D LUTs) to achieve fast and robust photo enhancement. 3D LUTs are widely used for manipulating color and tone of photos, but they are usually manually tuned and fixed in camera imaging pipeline or photo editing tools. We, for the first time to our best knowledge, propose to learn 3D LUTs from annotated data using pairwise or unpaired learning. More importantly, our learned 3D LUT is image-adaptive for flexible photo enhancement. We learn multiple basis 3D LUTs and a small convolutional neural network (CNN) simultaneously in an end-to-end manner. The small CNN works on the down-sampled version of the input image to predict content-dependent weights to fuse the multiple basis 3D LUTs into an image-adaptive one, which is employed to transform the color and tone of source images efficiently. Our model contains less than 600K parameters and takes less than 2 ms to process an image of 4K resolution using one Titan RTX GPU. While being highly efficient, our model also outperforms the state-of-the-art photo enhancement methods by a large margin in terms of PSNR, SSIM and a color difference metric on two publically available benchmark datasets.