 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHsin-Min Wang
Deep Complex U-Net with Conformer for Audio-Visual Speech Enhancement
Sep 20, 2023
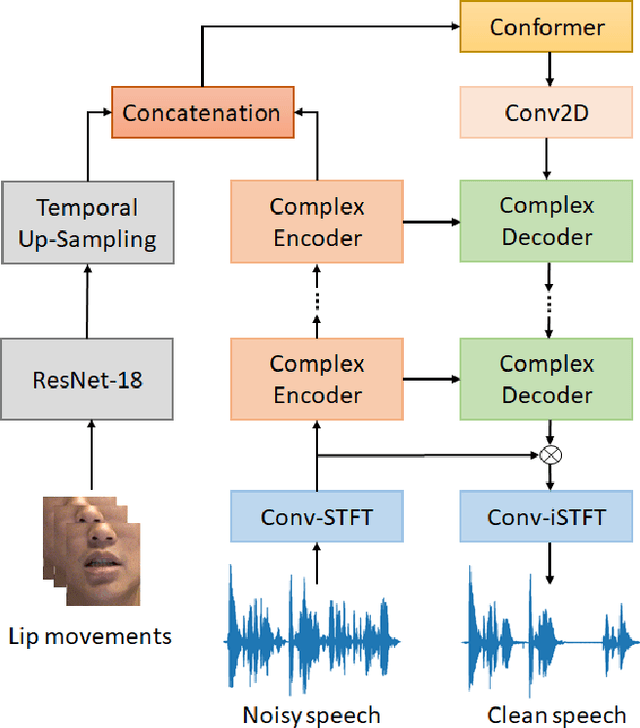
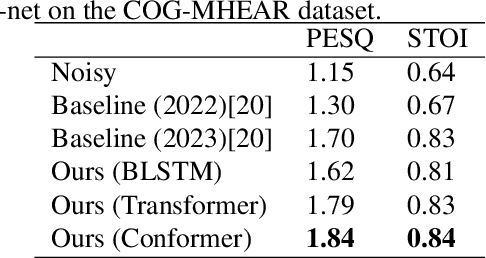

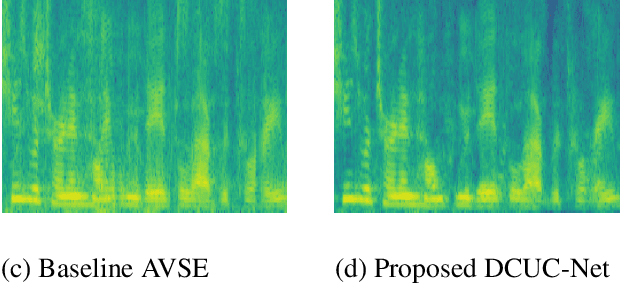
Recent studies have increasingly acknowledged the advantages of incorporating visual data into speech enhancement (SE) systems. In this paper, we introduce a novel audio-visual SE approach, termed DCUC-Net (deep complex U-Net with conformer network). The proposed DCUC-Net leverages complex domain features and a stack of conformer blocks. The encoder and decoder of DCUC-Net are designed using a complex U-Net-based framework. The audio and visual signals are processed using a complex encoder and a ResNet-18 model, respectively. These processed signals are then fused using the conformer blocks and transformed into enhanced speech waveforms via a complex decoder. The conformer blocks consist of a combination of self-attention mechanisms and convolutional operations, enabling DCUC-Net to effectively capture both global and local audio-visual dependencies. Our experimental results demonstrate the effectiveness of DCUC-Net, as it outperforms the baseline model from the COG-MHEAR AVSE Challenge 2023 by a notable margin of 0.14 in terms of PESQ. Additionally, the proposed DCUC-Net performs comparably to a state-of-the-art model and outperforms all other compared models on the Taiwan Mandarin speech with video (TMSV) dataset.
Utilizing Whisper to Enhance Multi-Branched Speech Intelligibility Prediction Model for Hearing Aids
Sep 18, 2023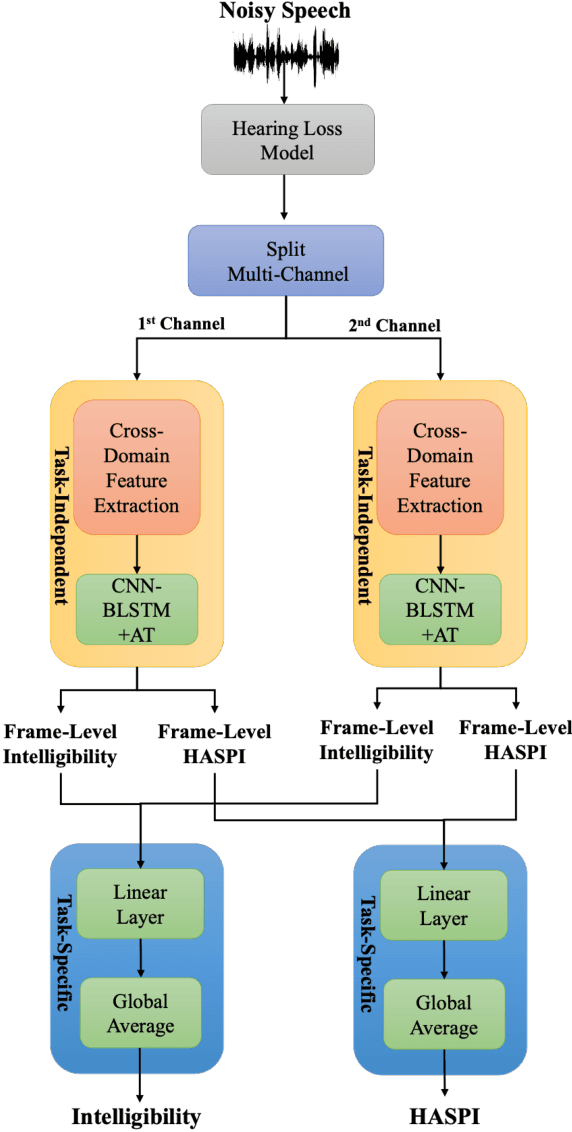
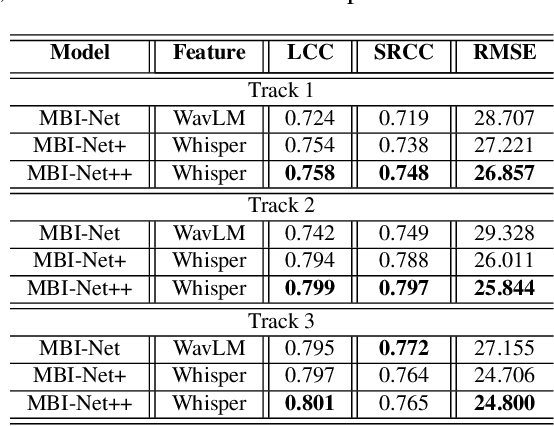
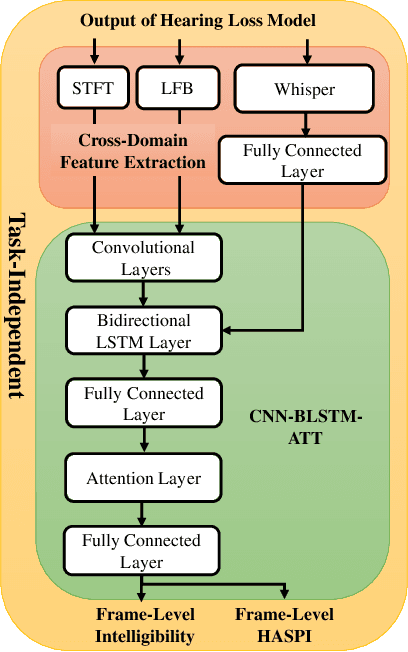
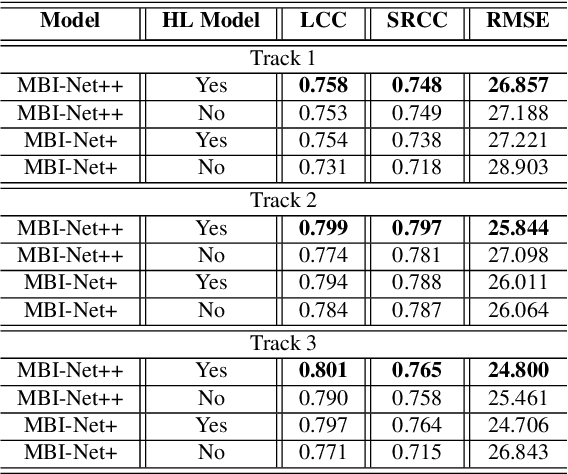
Automated assessment of speech intelligibility in hearing aid (HA) devices is of great importance. Our previous work introduced a non-intrusive multi-branched speech intelligibility prediction model called MBI-Net, which achieved top performance in the Clarity Prediction Challenge 2022. Based on the promising results of the MBI-Net model, we aim to further enhance its performance by leveraging Whisper embeddings to enrich acoustic features. In this study, we propose two improved models, namely MBI-Net+ and MBI-Net++. MBI-Net+ maintains the same model architecture as MBI-Net, but replaces self-supervised learning (SSL) speech embeddings with Whisper embeddings to deploy cross-domain features. On the other hand, MBI-Net++ further employs a more elaborate design, incorporating an auxiliary task to predict frame-level and utterance-level scores of the objective speech intelligibility metric HASPI (Hearing Aid Speech Perception Index) and multi-task learning. Experimental results confirm that both MBI-Net++ and MBI-Net+ achieve better prediction performance than MBI-Net in terms of multiple metrics, and MBI-Net++ is better than MBI-Net+.
Multi-Task Pseudo-Label Learning for Non-Intrusive Speech Quality Assessment Model
Aug 18, 2023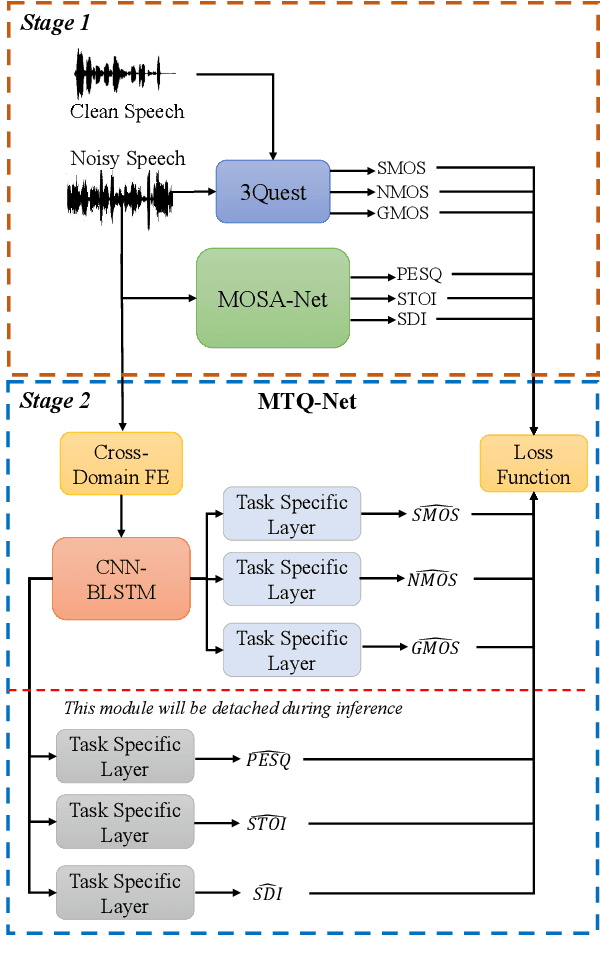
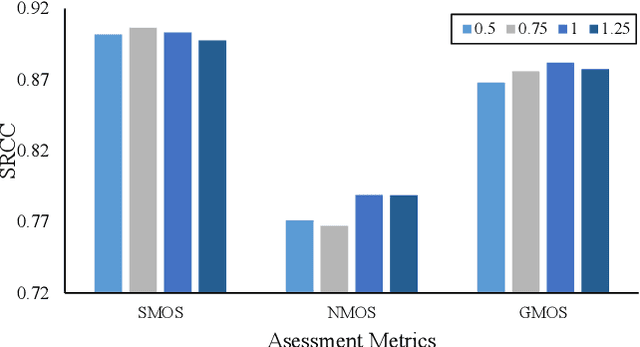
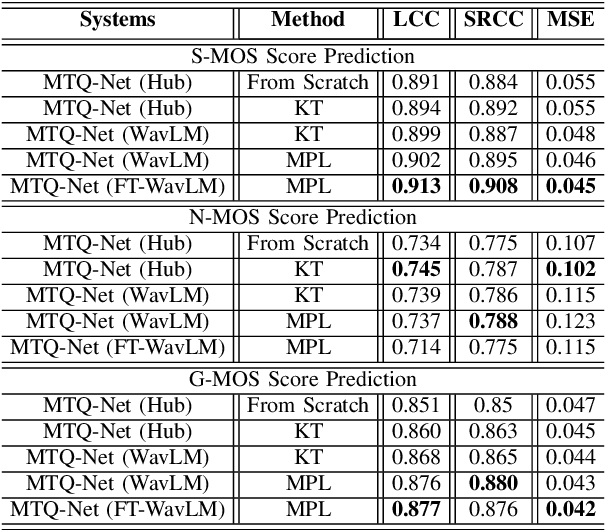
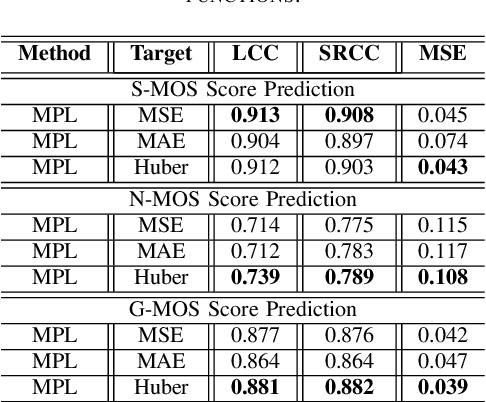
This study introduces multi-task pseudo-label (MPL) learning for a non-intrusive speech quality assessment model. MPL consists of two stages which are obtaining pseudo-label scores from a pretrained model and performing multi-task learning. The 3QUEST metrics, namely Speech-MOS (S-MOS), Noise-MOS (N-MOS), and General-MOS (G-MOS) are selected as the primary ground-truth labels. Additionally, the pretrained MOSA-Net model is utilized to estimate three pseudo-labels: perceptual evaluation of speech quality (PESQ), short-time objective intelligibility (STOI), and speech distortion index (SDI). Multi-task learning stage of MPL is then employed to train the MTQ-Net model (multi-target speech quality assessment network). The model is optimized by incorporating Loss supervision (derived from the difference between the estimated score and the real ground-truth labels) and Loss semi-supervision (derived from the difference between the estimated score and pseudo-labels), where Huber loss is employed to calculate the loss function. Experimental results first demonstrate the advantages of MPL compared to training the model from scratch and using knowledge transfer mechanisms. Secondly, the benefits of Huber Loss in improving the prediction model of MTQ-Net are verified. Finally, the MTQ-Net with the MPL approach exhibits higher overall prediction capabilities when compared to other SSL-based speech assessment models.
Mandarin Electrolaryngeal Speech Voice Conversion using Cross-domain Features
Jun 11, 2023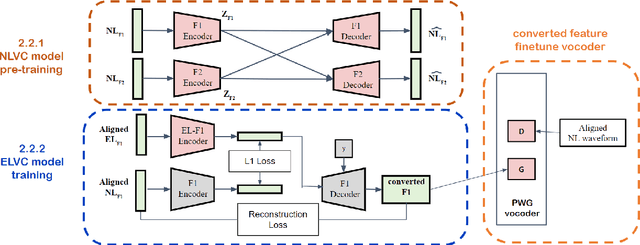

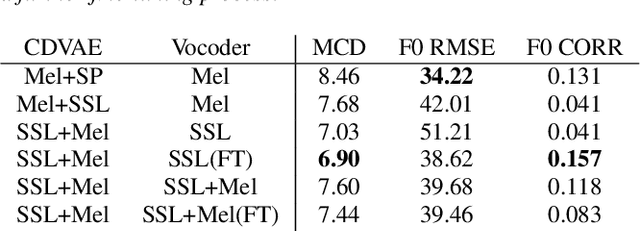
Patients who have had their entire larynx removed, including the vocal folds, owing to throat cancer may experience difficulties in speaking. In such cases, electrolarynx devices are often prescribed to produce speech, which is commonly referred to as electrolaryngeal speech (EL speech). However, the quality and intelligibility of EL speech are poor. To address this problem, EL voice conversion (ELVC) is a method used to improve the intelligibility and quality of EL speech. In this paper, we propose a novel ELVC system that incorporates cross-domain features, specifically spectral features and self-supervised learning (SSL) embeddings. The experimental results show that applying cross-domain features can notably improve the conversion performance for the ELVC task compared with utilizing only traditional spectral features.
Audio-Visual Mandarin Electrolaryngeal Speech Voice Conversion
Jun 11, 2023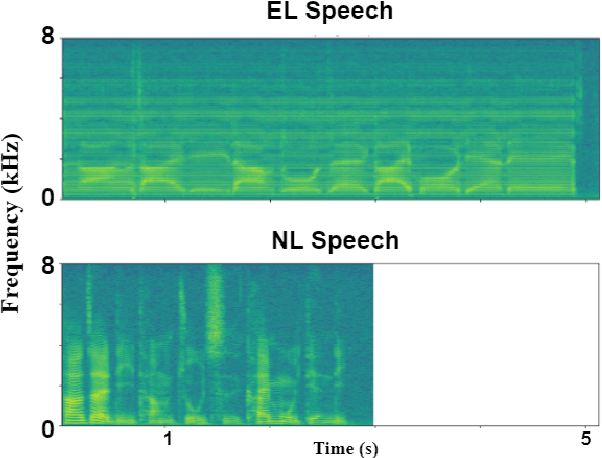

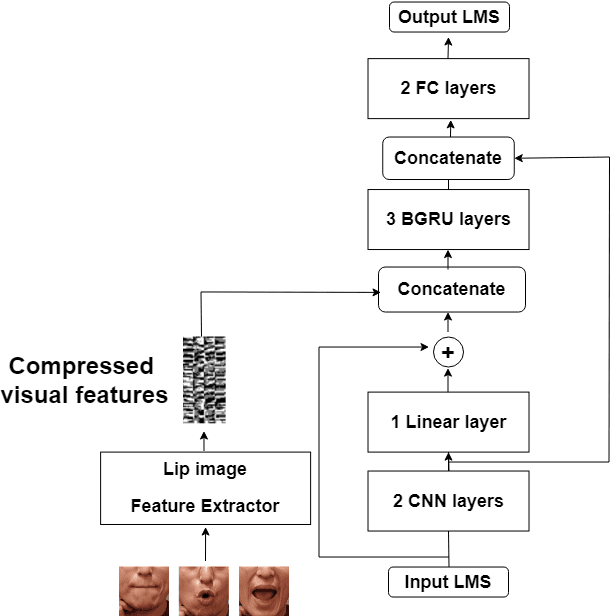
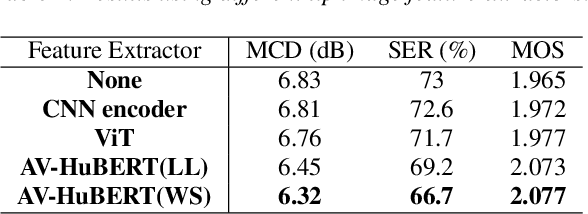
Electrolarynx is a commonly used assistive device to help patients with removed vocal cords regain their ability to speak. Although the electrolarynx can generate excitation signals like the vocal cords, the naturalness and intelligibility of electrolaryngeal (EL) speech are very different from those of natural (NL) speech. Many deep-learning-based models have been applied to electrolaryngeal speech voice conversion (ELVC) for converting EL speech to NL speech. In this study, we propose a multimodal voice conversion (VC) model that integrates acoustic and visual information into a unified network. We compared different pre-trained models as visual feature extractors and evaluated the effectiveness of these features in the ELVC task. The experimental results demonstrate that the proposed multimodal VC model outperforms single-modal models in both objective and subjective metrics, suggesting that the integration of visual information can significantly improve the quality of ELVC.
CasNet: Investigating Channel Robustness for Speech Separation
Oct 27, 2022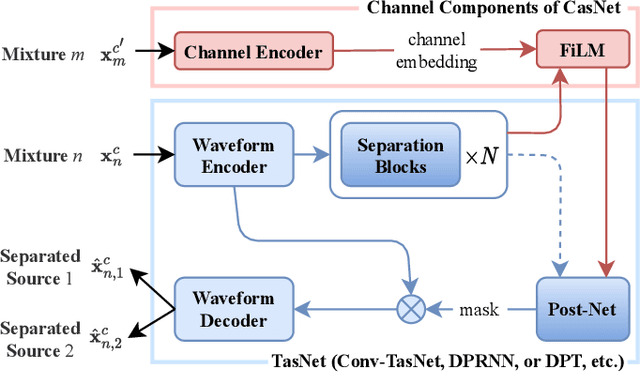
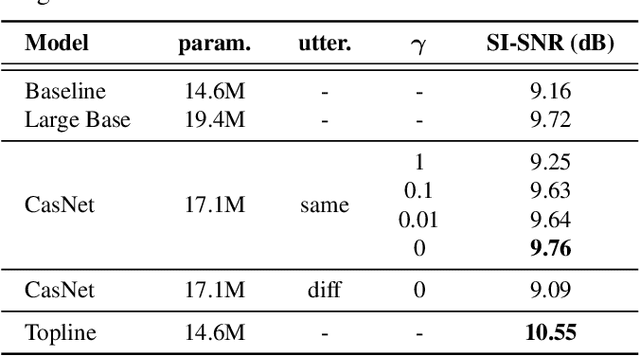
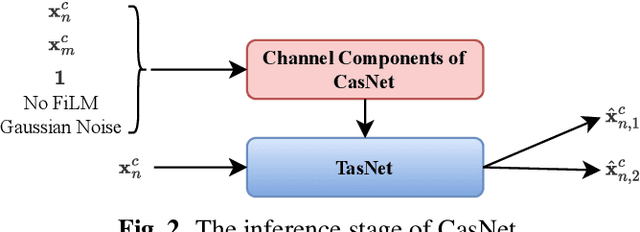
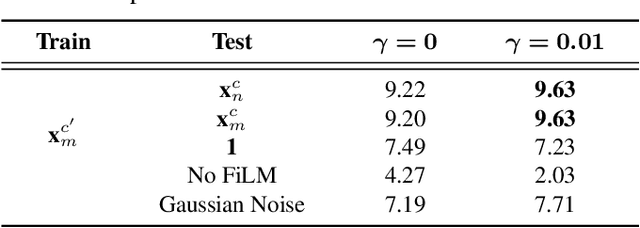
Recording channel mismatch between training and testing conditions has been shown to be a serious problem for speech separation. This situation greatly reduces the separation performance, and cannot meet the requirement of daily use. In this study, inheriting the use of our previously constructed TAT-2mix corpus, we address the channel mismatch problem by proposing a channel-aware audio separation network (CasNet), a deep learning framework for end-to-end time-domain speech separation. CasNet is implemented on top of TasNet. Channel embedding (characterizing channel information in a mixture of multiple utterances) generated by Channel Encoder is introduced into the separation module by the FiLM technique. Through two training strategies, we explore two roles that channel embedding may play: 1) a real-life noise disturbance, making the model more robust, or 2) a guide, instructing the separation model to retain the desired channel information. Experimental results on TAT-2mix show that CasNet trained with both training strategies outperforms the TasNet baseline, which does not use channel embeddings.
A Teacher-student Framework for Unsupervised Speech Enhancement Using Noise Remixing Training and Two-stage Inference
Oct 27, 2022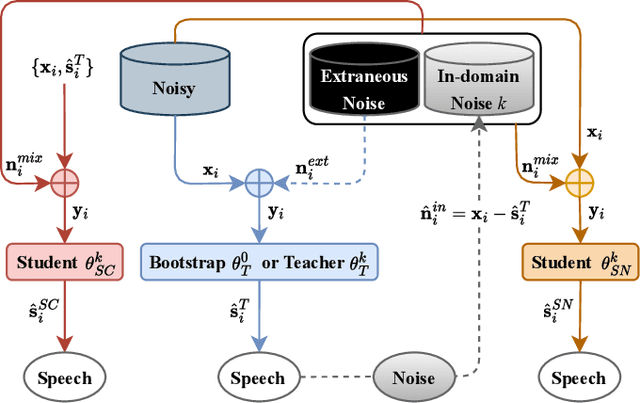

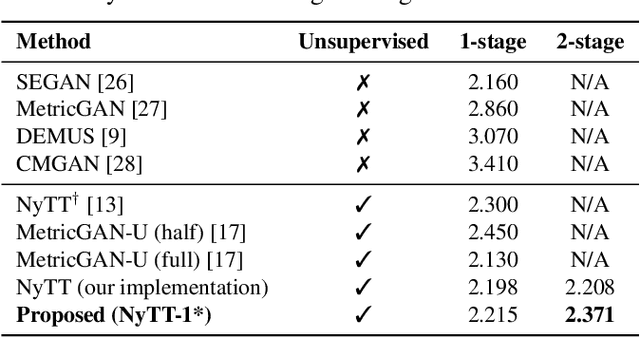
The lack of clean speech is a practical challenge to the development of speech enhancement systems, which means that the training of neural network models must be done in an unsupervised manner, and there is an inevitable mismatch between their training criterion and evaluation metric. In response to this unfavorable situation, we propose a teacher-student training strategy that does not require any subjective/objective speech quality metrics as learning reference by improving the previously proposed noisy-target training (NyTT). Because homogeneity between in-domain noise and extraneous noise is the key to the effectiveness of NyTT, we train various student models by remixing the teacher model's estimated speech and noise for clean-target training or raw noisy speech and the teacher model's estimated noise for noisy-target training. We use the NyTT model as the initial teacher model. Experimental results show that our proposed method outperforms several baselines, especially with two-stage inference, where clean speech is derived successively through the bootstrap model and the final student model.
Mandarin Singing Voice Synthesis with Denoising Diffusion Probabilistic Wasserstein GAN
Sep 21, 2022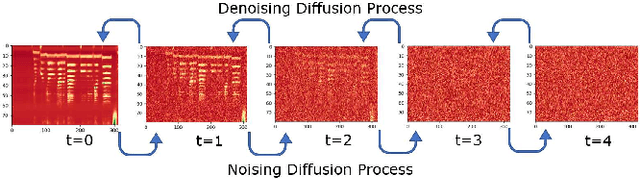

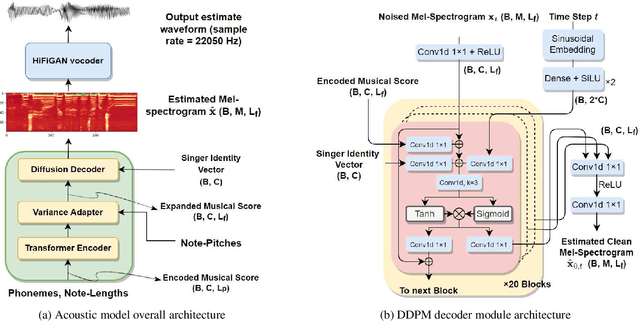
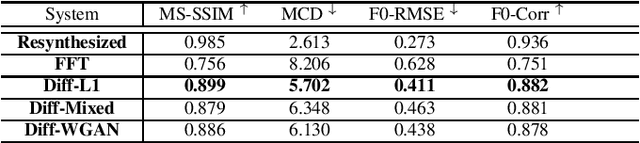
Singing voice synthesis (SVS) is the computer production of a human-like singing voice from given musical scores. To accomplish end-to-end SVS effectively and efficiently, this work adopts the acoustic model-neural vocoder architecture established for high-quality speech and singing voice synthesis. Specifically, this work aims to pursue a higher level of expressiveness in synthesized voices by combining the diffusion denoising probabilistic model (DDPM) and \emph{Wasserstein} generative adversarial network (WGAN) to construct the backbone of the acoustic model. On top of the proposed acoustic model, a HiFi-GAN neural vocoder is adopted with integrated fine-tuning to ensure optimal synthesis quality for the resulting end-to-end SVS system. This end-to-end system was evaluated with the multi-singer Mpop600 Mandarin singing voice dataset. In the experiments, the proposed system exhibits improvements over previous landmark counterparts in terms of musical expressiveness and high-frequency acoustic details. Moreover, the adversarial acoustic model converged stably without the need to enforce reconstruction objectives, indicating the convergence stability of the proposed DDPM and WGAN combined architecture over alternative GAN-based SVS systems.
NASTAR: Noise Adaptive Speech Enhancement with Target-Conditional Resampling
Jun 18, 2022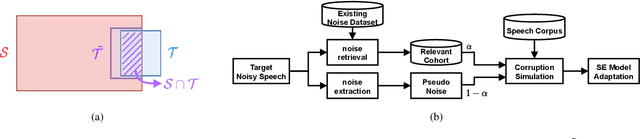
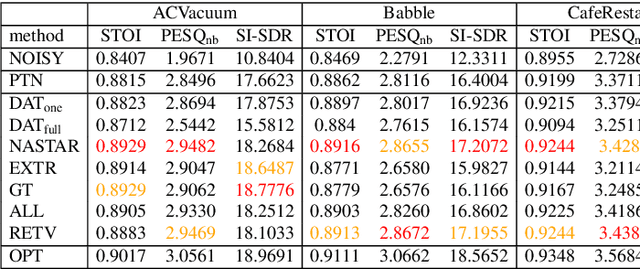
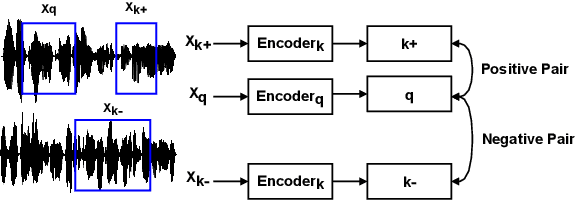
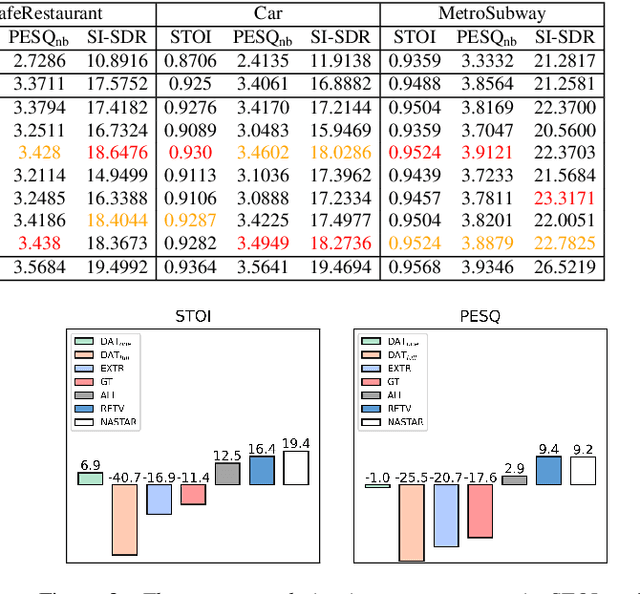
For deep learning-based speech enhancement (SE) systems, the training-test acoustic mismatch can cause notable performance degradation. To address the mismatch issue, numerous noise adaptation strategies have been derived. In this paper, we propose a novel method, called noise adaptive speech enhancement with target-conditional resampling (NASTAR), which reduces mismatches with only one sample (one-shot) of noisy speech in the target environment. NASTAR uses a feedback mechanism to simulate adaptive training data via a noise extractor and a retrieval model. The noise extractor estimates the target noise from the noisy speech, called pseudo-noise. The noise retrieval model retrieves relevant noise samples from a pool of noise signals according to the noisy speech, called relevant-cohort. The pseudo-noise and the relevant-cohort set are jointly sampled and mixed with the source speech corpus to prepare simulated training data for noise adaptation. Experimental results show that NASTAR can effectively use one noisy speech sample to adapt an SE model to a target condition. Moreover, both the noise extractor and the noise retrieval model contribute to model adaptation. To our best knowledge, NASTAR is the first work to perform one-shot noise adaptation through noise extraction and retrieval.
A Study of Using Cepstrogram for Countermeasure Against Replay Attacks
Apr 09, 2022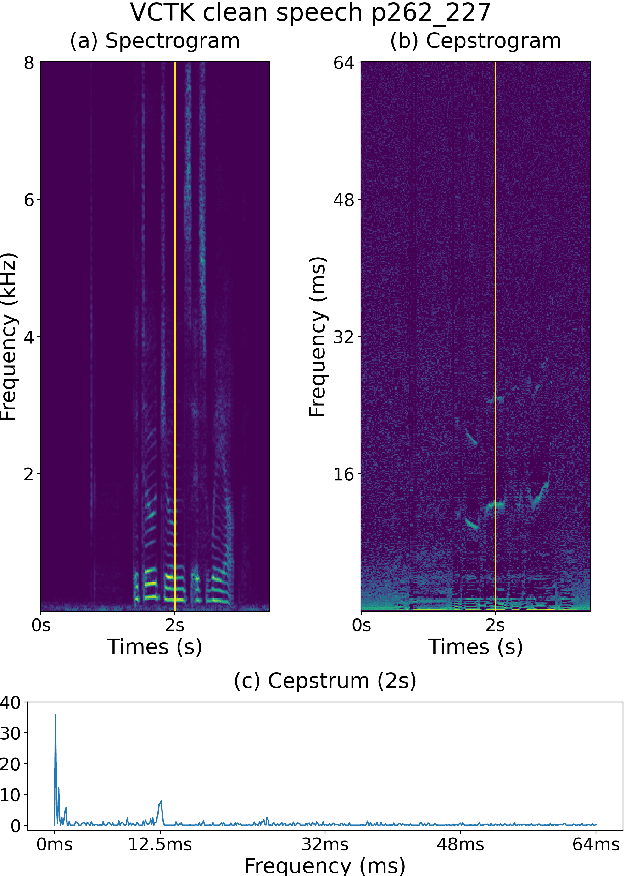
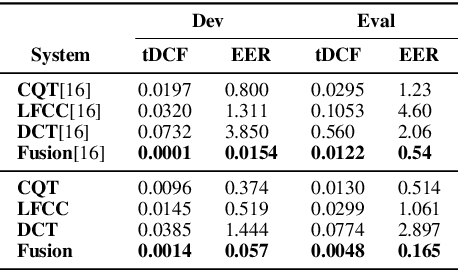
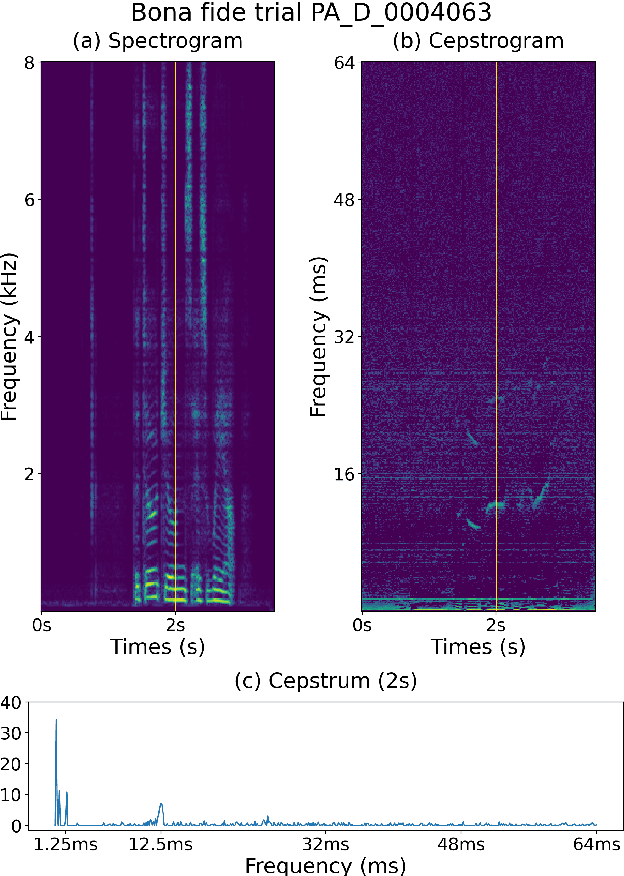
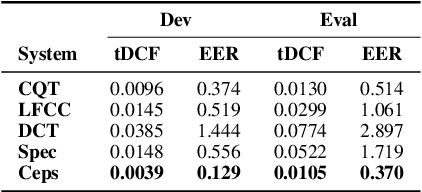
In this paper, we investigate the properties of the cepstrogram and demonstrate its effectiveness as a powerful feature for countermeasure against replay attacks. Cepstrum analysis of replay attacks suggests that crucial information for anti-spoofing against replay attacks may retain in the cepstrogram. Experimental results on the ASVspoof 2019 physical access (PA) database demonstrate that, compared with other features, the cepstrogram dominates in both single and fusion systems when building countermeasures against replay attacks. Our LCNN-based single and fusion systems with the cepstrogram feature outperform the corresponding LCNN-based systems without using the cepstrogram feature and several state-of-the-art (SOTA) single and fusion systems in the literature.