 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Euphemism Detection and Identification for Content Moderation
Mar 31, 2021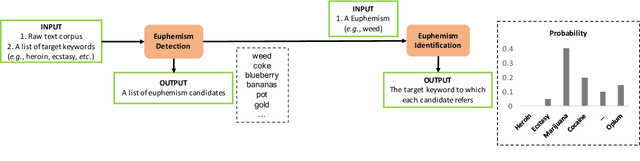
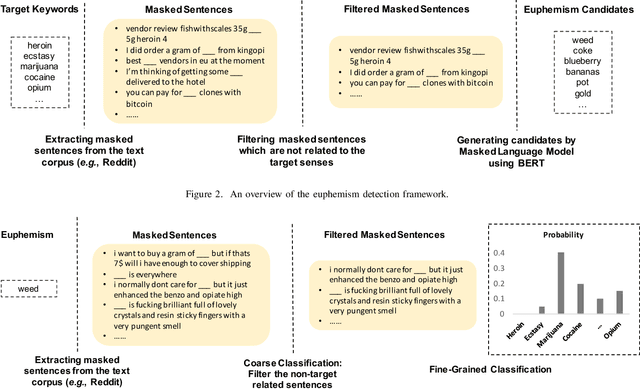
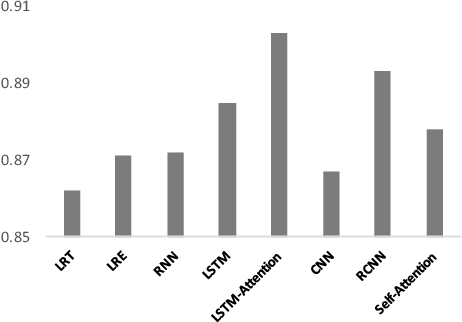
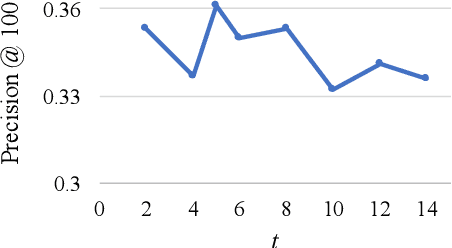
Fringe groups and organizations have a long history of using euphemisms--ordinary-sounding words with a secret meaning--to conceal what they are discussing. Nowadays, one common use of euphemisms is to evade content moderation policies enforced by social media platforms. Existing tools for enforcing policy automatically rely on keyword searches for words on a "ban list", but these are notoriously imprecise: even when limited to swearwords, they can still cause embarrassing false positives. When a commonly used ordinary word acquires a euphemistic meaning, adding it to a keyword-based ban list is hopeless: consider "pot" (storage container or marijuana?) or "heater" (household appliance or firearm?) The current generation of social media companies instead hire staff to check posts manually, but this is expensive, inhumane, and not much more effective. It is usually apparent to a human moderator that a word is being used euphemistically, but they may not know what the secret meaning is, and therefore whether the message violates policy. Also, when a euphemism is banned, the group that used it need only invent another one, leaving moderators one step behind. This paper will demonstrate unsupervised algorithms that, by analyzing words in their sentence-level context, can both detect words being used euphemistically, and identify the secret meaning of each word. Compared to the existing state of the art, which uses context-free word embeddings, our algorithm for detecting euphemisms achieves 30-400% higher detection accuracies of unlabeled euphemisms in a text corpus. Our algorithm for revealing euphemistic meanings of words is the first of its kind, as far as we are aware. In the arms race between content moderators and policy evaders, our algorithms may help shift the balance in the direction of the moderators.
Enriching Word Embeddings with Temporal and Spatial Information
Oct 02, 2020
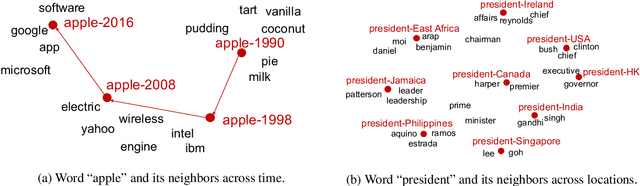
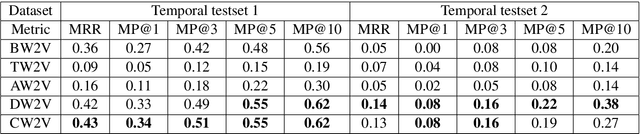
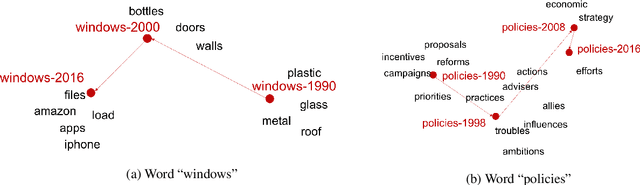
The meaning of a word is closely linked to sociocultural factors that can change over time and location, resulting in corresponding meaning changes. Taking a global view of words and their meanings in a widely used language, such as English, may require us to capture more refined semantics for use in time-specific or location-aware situations, such as the study of cultural trends or language use. However, popular vector representations for words do not adequately include temporal or spatial information. In this work, we present a model for learning word representation conditioned on time and location. In addition to capturing meaning changes over time and location, we require that the resulting word embeddings retain salient semantic and geometric properties. We train our model on time- and location-stamped corpora, and show using both quantitative and qualitative evaluations that it can capture semantics across time and locations. We note that our model compares favorably with the state-of-the-art for time-specific embedding, and serves as a new benchmark for location-specific embeddings.
Recurrent Chunking Mechanisms for Long-Text Machine Reading Comprehension
May 19, 2020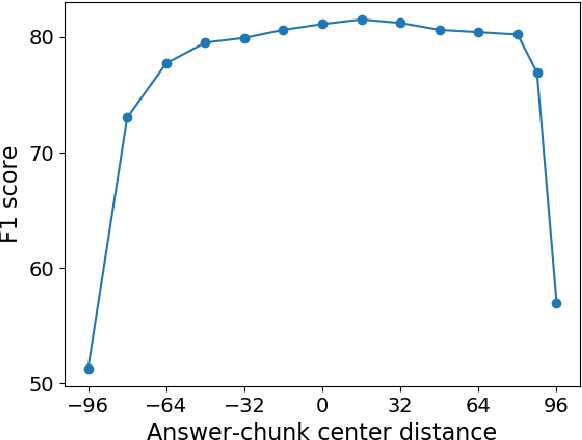

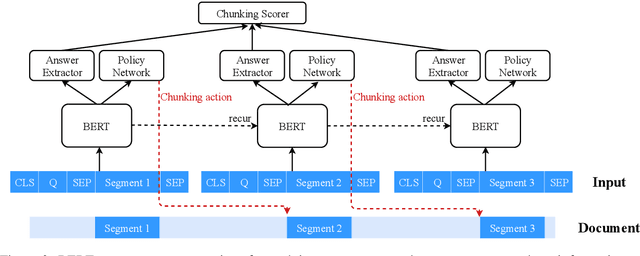
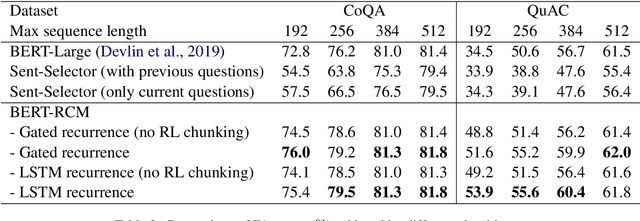
In this paper, we study machine reading comprehension (MRC) on long texts, where a model takes as inputs a lengthy document and a question and then extracts a text span from the document as an answer. State-of-the-art models tend to use a pretrained transformer model (e.g., BERT) to encode the joint contextual information of document and question. However, these transformer-based models can only take a fixed-length (e.g., 512) text as its input. To deal with even longer text inputs, previous approaches usually chunk them into equally-spaced segments and predict answers based on each segment independently without considering the information from other segments. As a result, they may form segments that fail to cover the correct answer span or retain insufficient contexts around it, which significantly degrades the performance. Moreover, they are less capable of answering questions that need cross-segment information. We propose to let a model learn to chunk in a more flexible way via reinforcement learning: a model can decide the next segment that it wants to process in either direction. We also employ recurrent mechanisms to enable information to flow across segments. Experiments on three MRC datasets -- CoQA, QuAC, and TriviaQA -- demonstrate the effectiveness of our proposed recurrent chunking mechanisms: we can obtain segments that are more likely to contain complete answers and at the same time provide sufficient contexts around the ground truth answers for better predictions.
FUSE: Multi-Faceted Set Expansion by Coherent Clustering of Skip-grams
Oct 22, 2019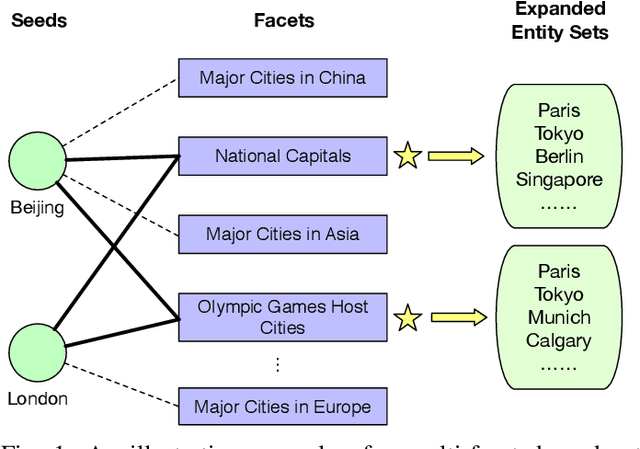
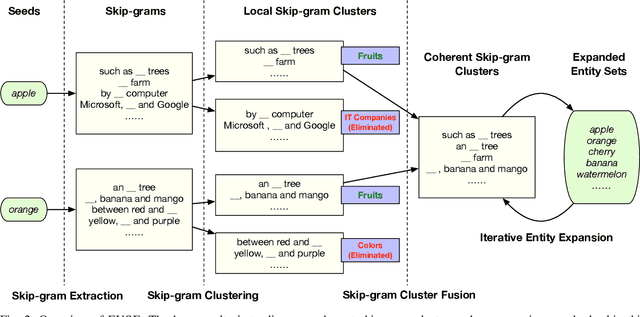
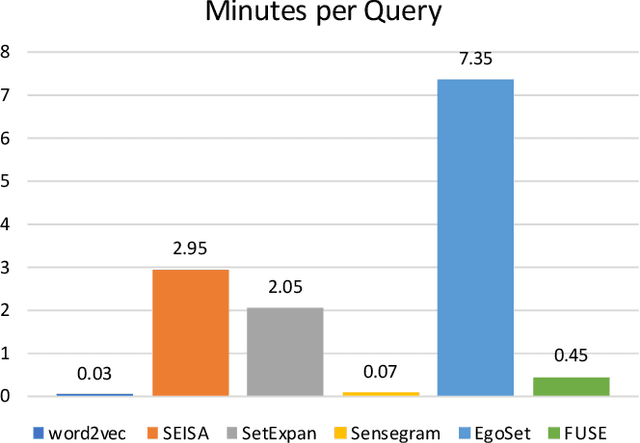
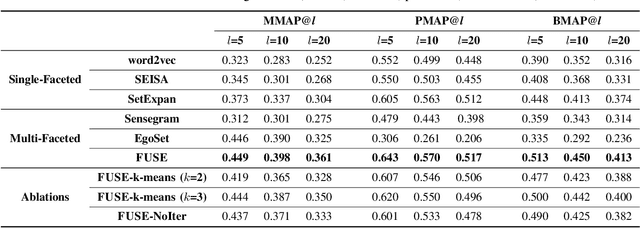
Set expansion aims to expand a small set of seed entities into a complete set of relevant entities. Most existing approaches assume the input seed set is unambiguous and completely ignore the multi-faceted semantics of seed entities. As a result, given the seed set {"Canon", "Sony", "Nikon"}, previous methods return one mixed set of entities that are either Camera Brands or Japanese Companies. In this paper, we study the task of multi-faceted set expansion, which aims to capture all semantic facets in the seed set and return multiple sets of entities, one for each semantic facet. We propose an unsupervised framework, FUSE, which consists of three major components: (1) facet discovery module: identifies all semantic facets of each seed entity by extracting and clustering its skip-grams, and (2) facet fusion module: discovers shared semantic facets of the entire seed set by an optimization formulation, and (3) entity expansion module: expands each semantic facet by utilizing an iterative algorithm robust to skip-gram noise. Extensive experiments demonstrate that our algorithm, FUSE, can accurately identify multiple semantic facets of the seed set and generate quality entities for each facet.
PaRe: A Paper-Reviewer Matching Approach Using a Common Topic Space
Sep 25, 2019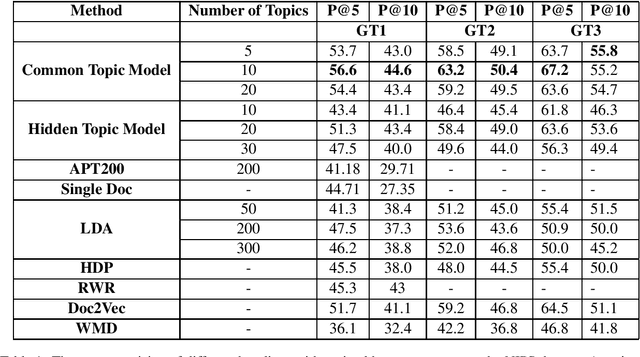
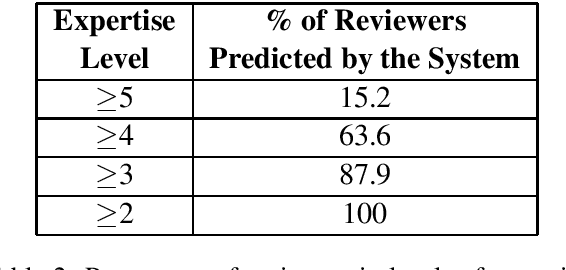


Finding the right reviewers to assess the quality of conference submissions is a time consuming process for conference organizers. Given the importance of this step, various automated reviewer-paper matching solutions have been proposed to alleviate the burden. Prior approaches, including bag-of-words models and probabilistic topic models have been inadequate to deal with the vocabulary mismatch and partial topic overlap between a paper submission and the reviewer's expertise. Our approach, the common topic model, jointly models the topics common to the submission and the reviewer's profile while relying on abstract topic vectors. Experiments and insightful evaluations on two datasets demonstrate that the proposed method achieves consistent improvements compared to available state-of-the-art implementations of paper-reviewer matching.
WikiMatrix: Mining 135M Parallel Sentences in 1620 Language Pairs from Wikipedia
Jul 16, 2019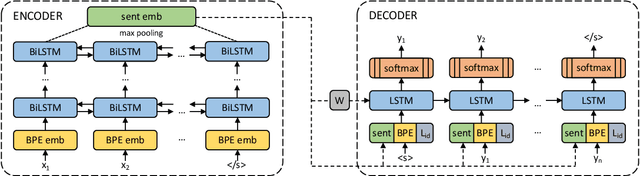

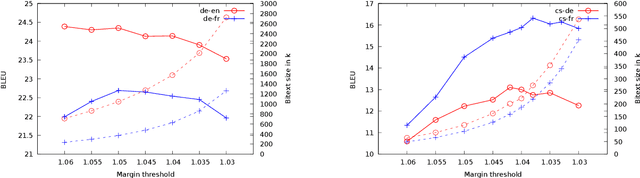
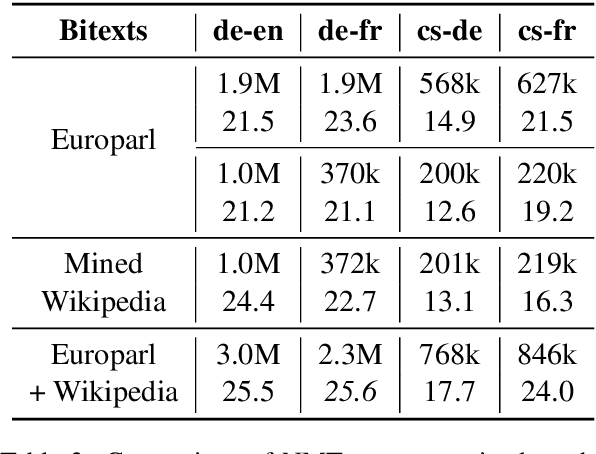
We present an approach based on multilingual sentence embeddings to automatically extract parallel sentences from the content of Wikipedia articles in 85 languages, including several dialects or low-resource languages. We do not limit the the extraction process to alignments with English, but systematically consider all possible language pairs. In total, we are able to extract 135M parallel sentences for 1620 different language pairs, out of which only 34M are aligned with English. This corpus of parallel sentences is freely available at https://github.com/facebookresearch/LASER/tree/master/tasks/WikiMatrix. To get an indication on the quality of the extracted bitexts, we train neural MT baseline systems on the mined data only for 1886 languages pairs, and evaluate them on the TED corpus, achieving strong BLEU scores for many language pairs. The WikiMatrix bitexts seem to be particularly interesting to train MT systems between distant languages without the need to pivot through English.
Reinforcement Learning Based Text Style Transfer without Parallel Training Corpus
Apr 08, 2019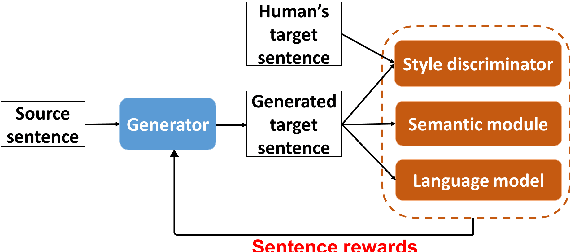
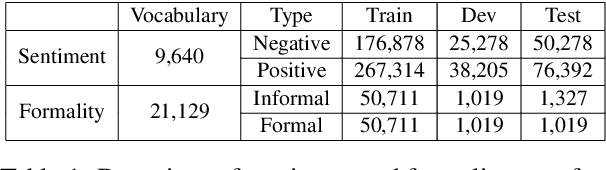
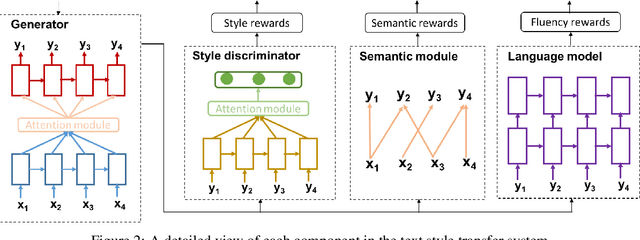

Text style transfer rephrases a text from a source style (e.g., informal) to a target style (e.g., formal) while keeping its original meaning. Despite the success existing works have achieved using a parallel corpus for the two styles, transferring text style has proven significantly more challenging when there is no parallel training corpus. In this paper, we address this challenge by using a reinforcement-learning-based generator-evaluator architecture. Our generator employs an attention-based encoder-decoder to transfer a sentence from the source style to the target style. Our evaluator is an adversarially trained style discriminator with semantic and syntactic constraints that score the generated sentence for style, meaning preservation, and fluency. Experimental results on two different style transfer tasks (sentiment transfer and formality transfer) show that our model outperforms state-of-the-art approaches. Furthermore, we perform a manual evaluation that demonstrates the effectiveness of the proposed method using subjective metrics of generated text quality.
Document Similarity for Texts of Varying Lengths via Hidden Topics
Mar 26, 2019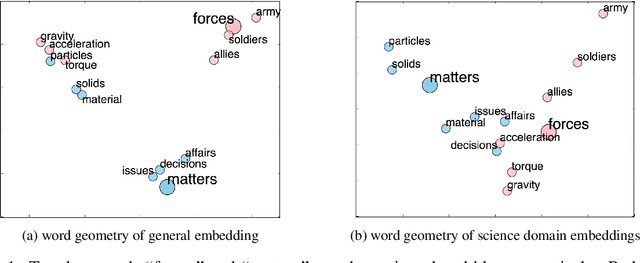
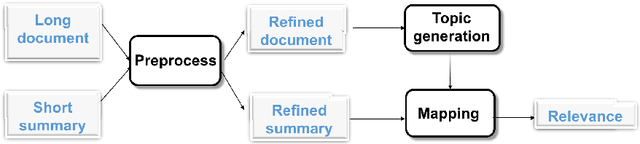

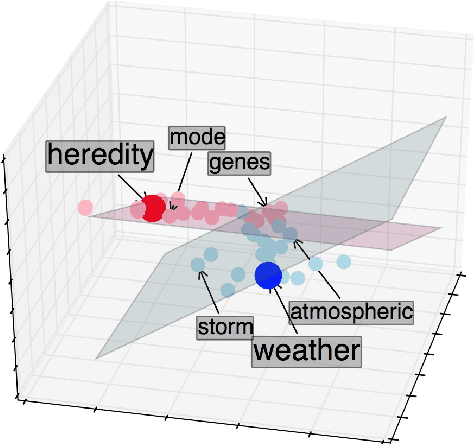
Measuring similarity between texts is an important task for several applications. Available approaches to measure document similarity are inadequate for document pairs that have non-comparable lengths, such as a long document and its summary. This is because of the lexical, contextual and the abstraction gaps between a long document of rich details and its concise summary of abstract information. In this paper, we present a document matching approach to bridge this gap, by comparing the texts in a common space of hidden topics. We evaluate the matching algorithm on two matching tasks and find that it consistently and widely outperforms strong baselines. We also highlight the benefits of incorporating domain knowledge to text matching.
Context-Sensitive Malicious Spelling Error Correction
Jan 23, 2019
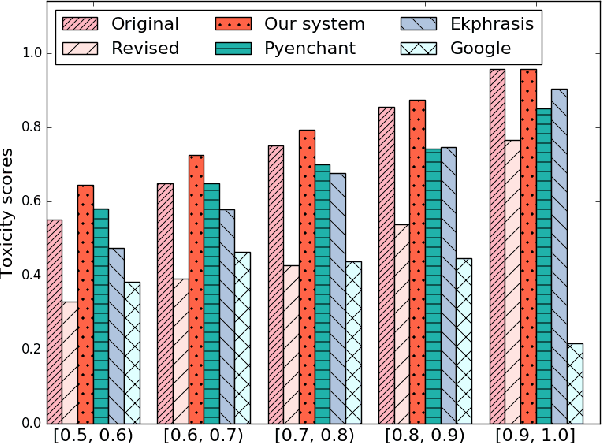

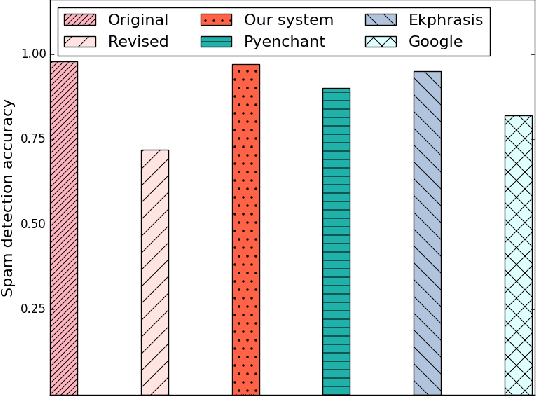
Misspelled words of the malicious kind work by changing specific keywords and are intended to thwart existing automated applications for cyber-environment control such as harassing content detection on the Internet and email spam detection. In this paper, we focus on malicious spelling correction, which requires an approach that relies on the context and the surface forms of targeted keywords. In the context of two applications--profanity detection and email spam detection--we show that malicious misspellings seriously degrade their performance. We then propose a context-sensitive approach for malicious spelling correction using word embeddings and demonstrate its superior performance compared to state-of-the-art spell checkers.
Embedding Syntax and Semantics of Prepositions via Tensor Decomposition
May 23, 2018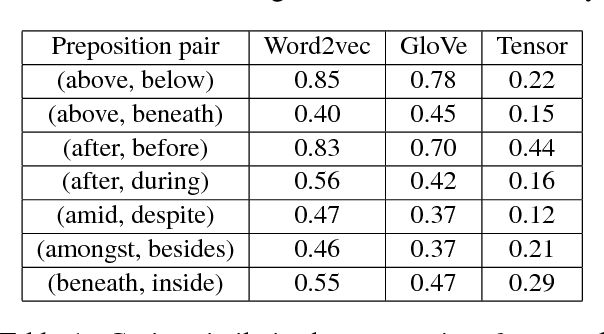
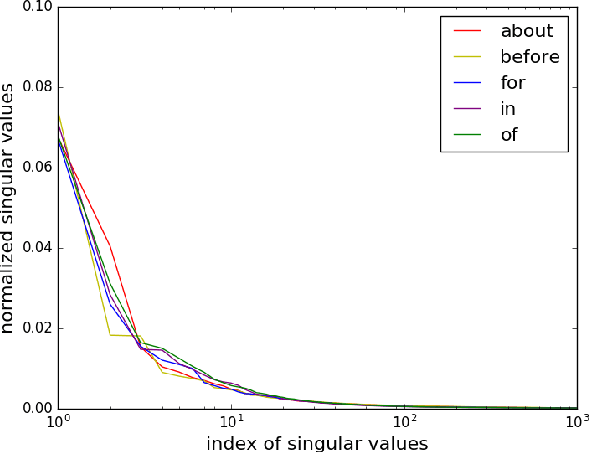

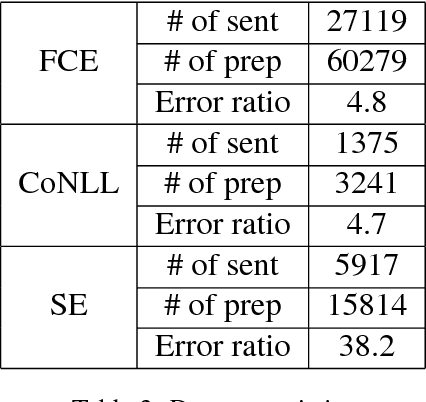
Prepositions are among the most frequent words in English and play complex roles in the syntax and semantics of sentences. Not surprisingly, they pose well-known difficulties in automatic processing of sentences (prepositional attachment ambiguities and idiosyncratic uses in phrases). Existing methods on preposition representation treat prepositions no different from content words (e.g., word2vec and GloVe). In addition, recent studies aiming at solving prepositional attachment and preposition selection problems depend heavily on external linguistic resources and use dataset-specific word representations. In this paper we use word-triple counts (one of the triples being a preposition) to capture a preposition's interaction with its attachment and complement. We then derive preposition embeddings via tensor decomposition on a large unlabeled corpus. We reveal a new geometry involving Hadamard products and empirically demonstrate its utility in paraphrasing phrasal verbs. Furthermore, our preposition embeddings are used as simple features in two challenging downstream tasks: preposition selection and prepositional attachment disambiguation. We achieve results comparable to or better than the state-of-the-art on multiple standardized datasets.