 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocument Similarity for Texts of Varying Lengths via Hidden Topics
Mar 26, 2019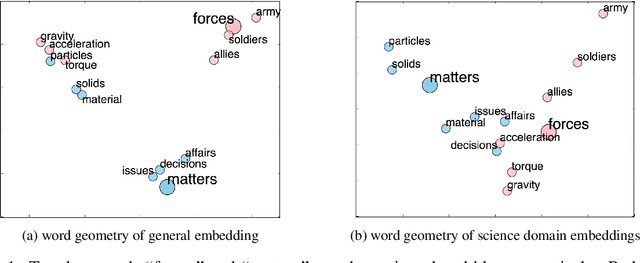
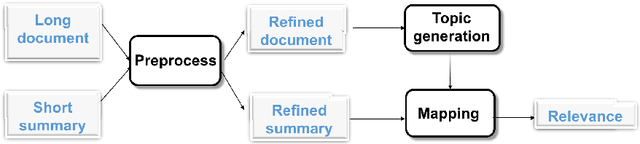

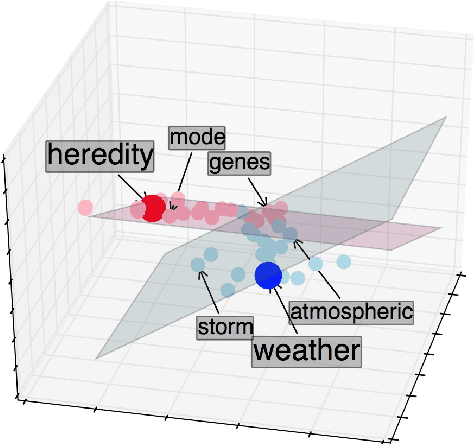
Measuring similarity between texts is an important task for several applications. Available approaches to measure document similarity are inadequate for document pairs that have non-comparable lengths, such as a long document and its summary. This is because of the lexical, contextual and the abstraction gaps between a long document of rich details and its concise summary of abstract information. In this paper, we present a document matching approach to bridge this gap, by comparing the texts in a common space of hidden topics. We evaluate the matching algorithm on two matching tasks and find that it consistently and widely outperforms strong baselines. We also highlight the benefits of incorporating domain knowledge to text matching.
MORSE: Semantic-ally Drive-n MORpheme SEgment-er
May 01, 2017
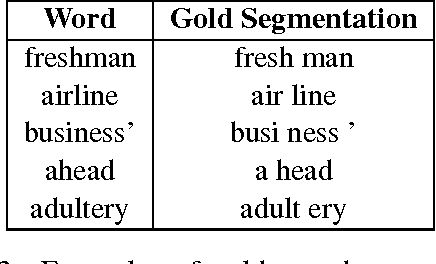
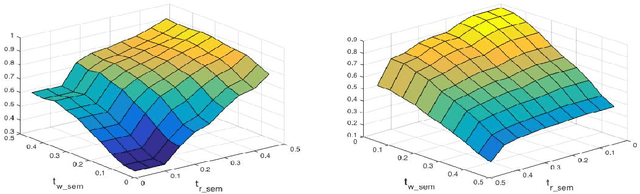
We present in this paper a novel framework for morpheme segmentation which uses the morpho-syntactic regularities preserved by word representations, in addition to orthographic features, to segment words into morphemes. This framework is the first to consider vocabulary-wide syntactico-semantic information for this task. We also analyze the deficiencies of available benchmarking datasets and introduce our own dataset that was created on the basis of compositionality. We validate our algorithm across datasets and present state-of-the-art results.
Fixing the Infix: Unsupervised Discovery of Root-and-Pattern Morphology
Feb 11, 2017

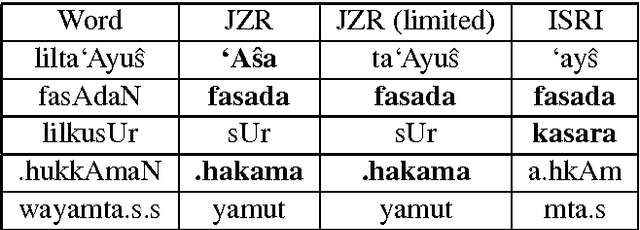

We present an unsupervised and language-agnostic method for learning root-and-pattern morphology in Semitic languages. This form of morphology, abundant in Semitic languages, has not been handled in prior unsupervised approaches. We harness the syntactico-semantic information in distributed word representations to solve the long standing problem of root-and-pattern discovery in Semitic languages. Moreover, we construct an unsupervised root extractor based on the learned rules. We prove the validity of learned rules across Arabic, Hebrew, and Amharic, alongside showing that our root extractor compares favorably with a widely used, carefully engineered root extractor: ISRI.