 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFD-MAR: Fourier Dual-domain Network for CT Metal Artifact Reduction
Jul 24, 2022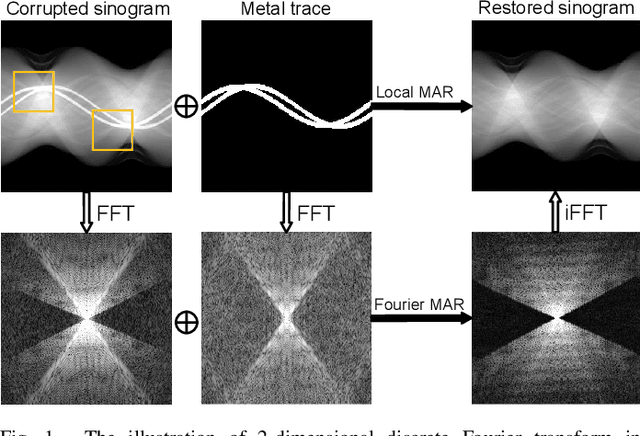
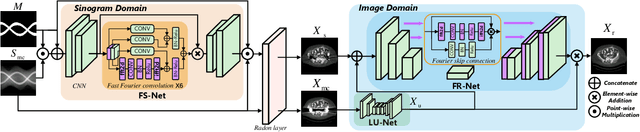
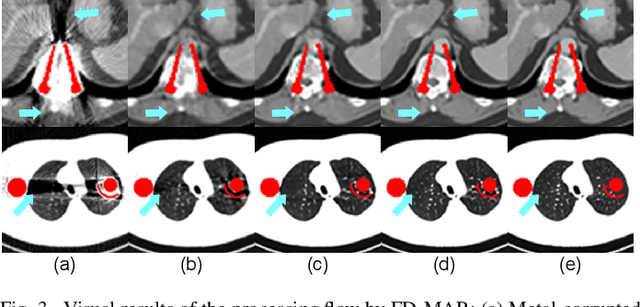
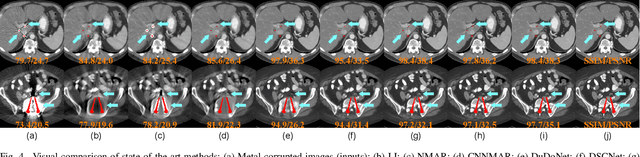
The presence of high-density objects such as metal implants and dental fillings can introduce severely streak-like artifacts in computed tomography (CT) images, greatly limiting subsequent diagnosis. Although various deep neural networks-based methods have been proposed for metal artifact reduction (MAR), they usually suffer from poor performance due to limited exploitation of global context in the sinogram domain, secondary artifacts introduced in the image domain, and the requirement of precise metal masks. To address these issues, this paper explores fast Fourier convolution for MAR in both sinogram and image domains, and proposes a Fourier dual-domain network for MAR, termed FD-MAR. Specifically, we first propose a Fourier sinogram restoration network, which can leverage sinogram-wide receptive context to fill in the metal-corrupted region from uncorrupted region and, hence, is robust to the metal trace. Second, we propose a Fourier refinement network in the image domain, which can refine the reconstructed images in a local-to-global manner by exploring image-wide context information. As a result, the proposed FD-MAR can explore the sinogram- and image-wide receptive fields for MAR. By optimizing FD-MAR with a composite loss function, extensive experimental results demonstrate the superiority of the proposed FD-MAR over the state-of-the-art MAR methods in terms of quantitative metrics and visual comparison. Notably, FD-MAR does not require precise metal masks, which is of great importance in clinical routine.
Site Generalization: Stroke Lesion Segmentation on Magnetic Resonance Images from Unseen Sites
May 09, 2022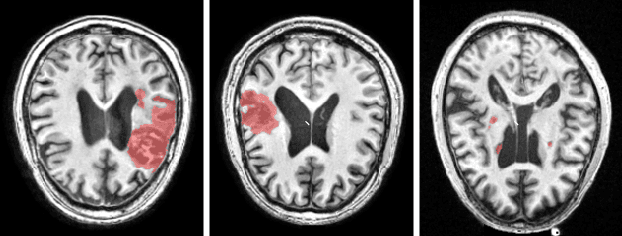
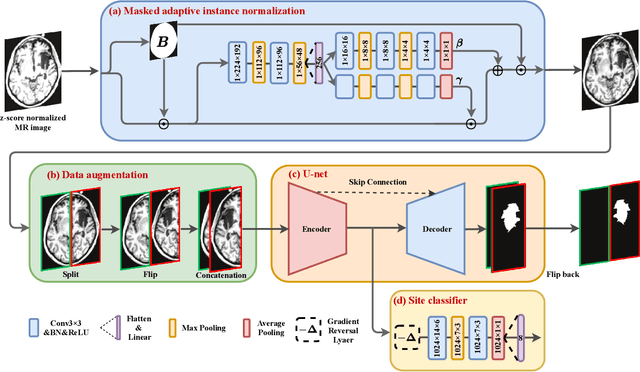
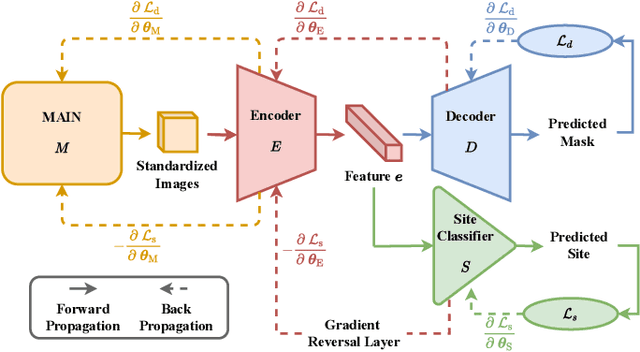
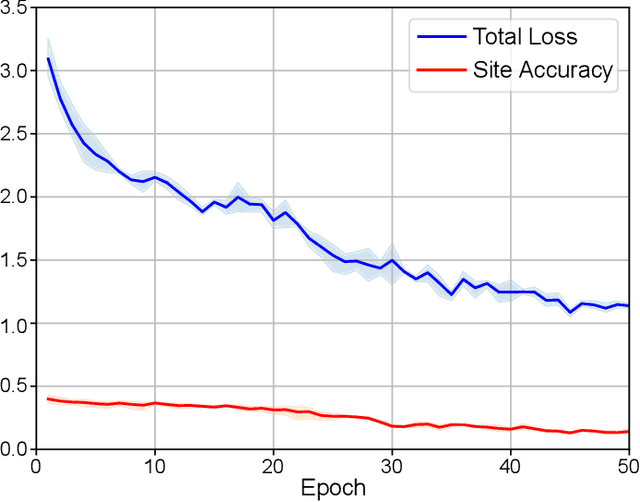
There are considerable interests in automatic stroke lesion segmentation on magnetic resonance (MR) images in the medical imaging field, as strokes are the main cause of various cerebrovascular diseases. Although deep learning-based models have been proposed for this task, generalizing these models to unseen sites is difficult due to not only the large intersite discrepancy among different scanners, imaging protocols, and populations but also the variations in stroke lesion shape, size, and location. Thus, we propose a U-net--based segmentation network termed SG-Net to improve unseen site generalization for stroke lesion segmentation on MR images. Specifically, we first propose masked adaptive instance normalization (MAIN) to minimize intersite discrepancies, standardizing input MR images from different sites into a site-unrelated style by dynamically learning affine parameters from the input. Then, we leverage a gradient reversal layer to force the U-net encoder to learn site-invariant representation, which further improves the model generalization in conjunction with MAIN. Finally, inspired by the "pseudosymmetry" of the human brain, we introduce a simple, yet effective data augmentation technique that can be embedded within SG-Net to double the sample size while halving memory consumption. As a result, stroke lesions from the whole brain can be easily identified within a hemisphere, improving the simplicity of training. Experimental results on the benchmark Anatomical Tracings of Lesions After Stroke (ATLAS) dataset, which includes MR images from 9 different sites, demonstrate that under the "leave-one-site-out" setting, the proposed SG-Net substantially outperforms recently published methods in terms of quantitative metrics and qualitative comparisons.
Forget Less, Count Better: A Domain-Incremental Self-Distillation Learning Benchmark for Lifelong Crowd Counting
May 06, 2022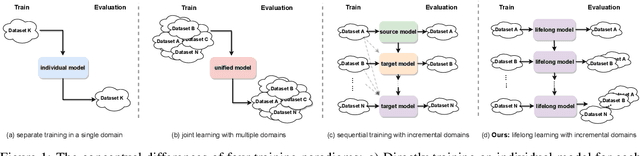
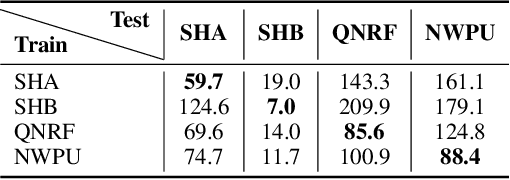
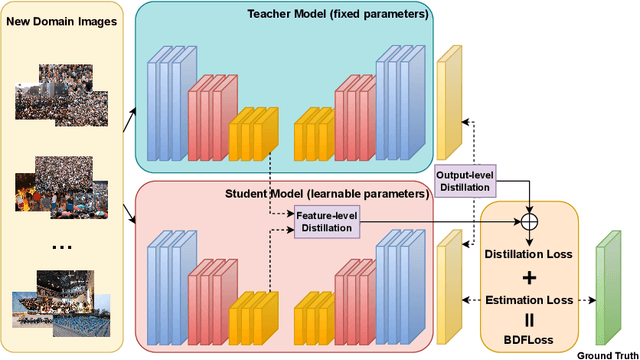
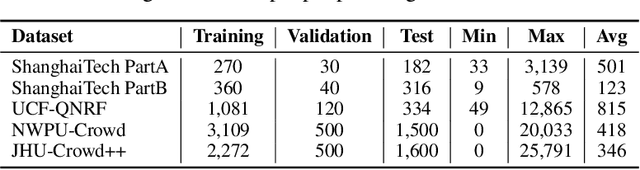
Crowd Counting has important applications in public safety and pandemic control. A robust and practical crowd counting system has to be capable of continuously learning with the new-coming domain data in real-world scenarios instead of fitting one domain only. Off-the-shelf methods have some drawbacks to handle multiple domains. 1) The models will achieve limited performance (even drop dramatically) among old domains after training images from new domains due to the discrepancies of intrinsic data distributions from various domains, which is called catastrophic forgetting. 2) The well-trained model in a specific domain achieves imperfect performance among other unseen domains because of the domain shift. 3) It leads to linearly-increased storage overhead either mixing all the data for training or simply training dozens of separate models for different domains when new ones are available. To overcome these issues, we investigate a new task of crowd counting under the incremental domains training setting, namely, Lifelong Crowd Counting. It aims at alleviating the catastrophic forgetting and improving the generalization ability using a single model updated by the incremental domains. To be more specific, we propose a self-distillation learning framework as a benchmark~(Forget Less, Count Better, FLCB) for lifelong crowd counting, which helps the model sustainably leverage previous meaningful knowledge for better crowd counting to mitigate the forgetting when the new data arrive. Meanwhile, a new quantitative metric, normalized backward transfer~(nBwT), is developed to evaluate the forgetting degree of the model in the lifelong learning process. Extensive experimental results demonstrate the superiority of our proposed benchmark in achieving a low catastrophic forgetting degree and strong generalization ability.
Synergizing Physics/Model-based and Data-driven Methods for Low-Dose CT
Mar 29, 2022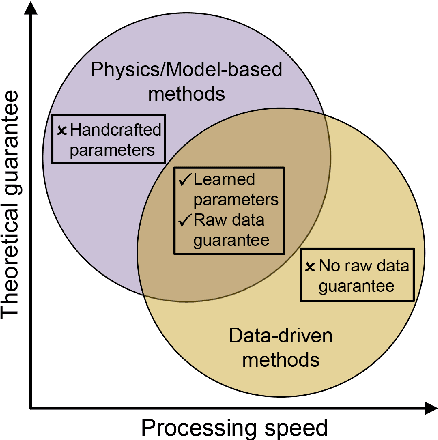
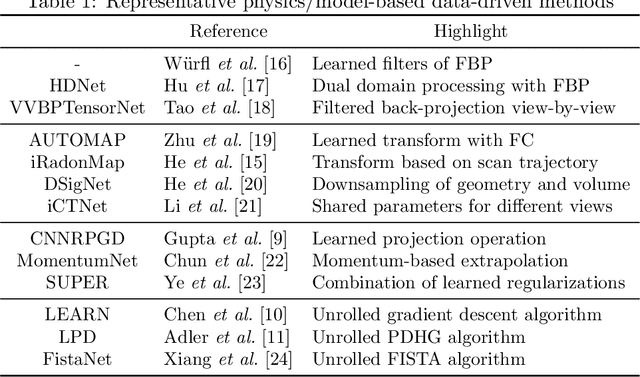

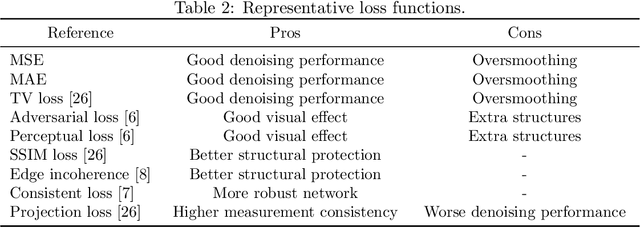
Since 2016, deep learning (DL) has advanced tomographic imaging with remarkable successes, especially in low-dose computed tomography (LDCT) imaging. Despite being driven by big data, the LDCT denoising and pure end-to-end reconstruction networks often suffer from the black box nature and major issues such as instabilities, which is a major barrier to apply deep learning methods in low-dose CT applications. An emerging trend is to integrate imaging physics and model into deep networks, enabling a hybridization of physics/model-based and data-driven elements. In this paper, we systematically review the physics/model-based data-driven methods for LDCT, summarize the loss functions and training strategies, evaluate the performance of different methods, and discuss relevant issues and future directions
Convolutional Neural Network to Restore Low-Dose Digital Breast Tomosynthesis Projections in a Variance Stabilization Domain
Mar 22, 2022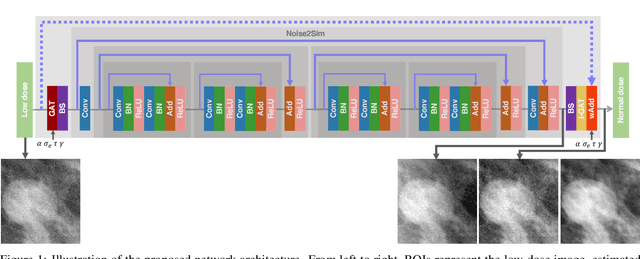
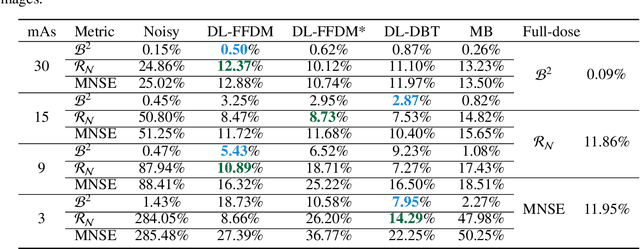

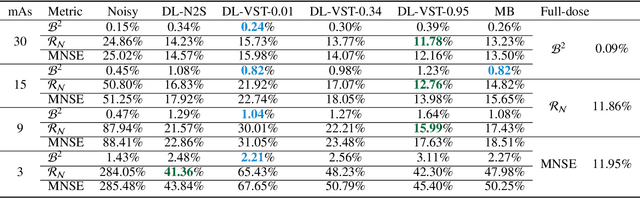
Digital breast tomosynthesis (DBT) exams should utilize the lowest possible radiation dose while maintaining sufficiently good image quality for accurate medical diagnosis. In this work, we propose a convolution neural network (CNN) to restore low-dose (LD) DBT projections to achieve an image quality equivalent to a standard full-dose (FD) acquisition. The proposed network architecture benefits from priors in terms of layers that were inspired by traditional model-based (MB) restoration methods, considering a model-based deep learning approach, where the network is trained to operate in the variance stabilization transformation (VST) domain. To accurately control the network operation point, in terms of noise and blur of the restored image, we propose a loss function that minimizes the bias and matches residual noise between the input and the output. The training dataset was composed of clinical data acquired at the standard FD and low-dose pairs obtained by the injection of quantum noise. The network was tested using real DBT projections acquired with a physical anthropomorphic breast phantom. The proposed network achieved superior results in terms of the mean normalized squared error (MNSE), training time and noise spatial correlation compared with networks trained with traditional data-driven methods. The proposed approach can be extended for other medical imaging application that requires LD acquisitions.
Meta Ordinal Regression Forest for Medical Image Classification with Ordinal Labels
Mar 15, 2022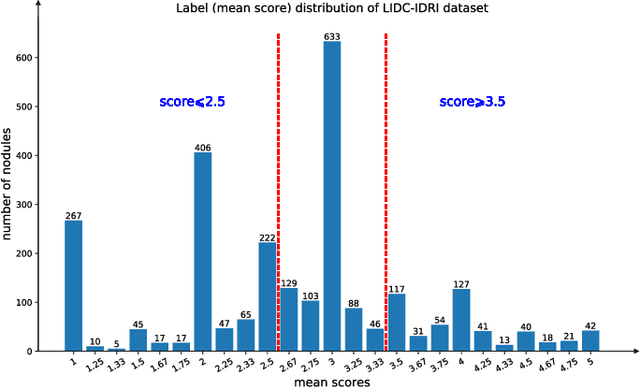
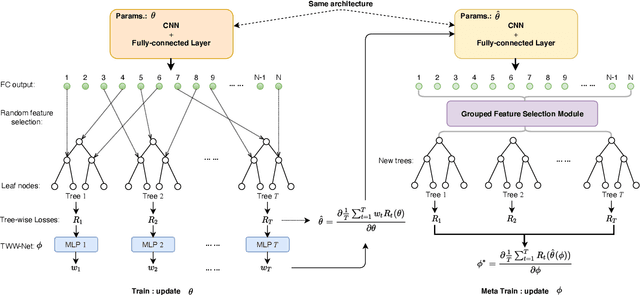
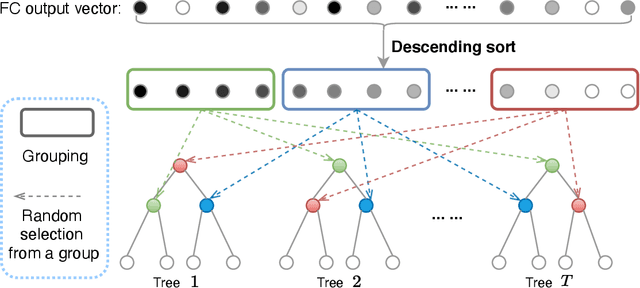
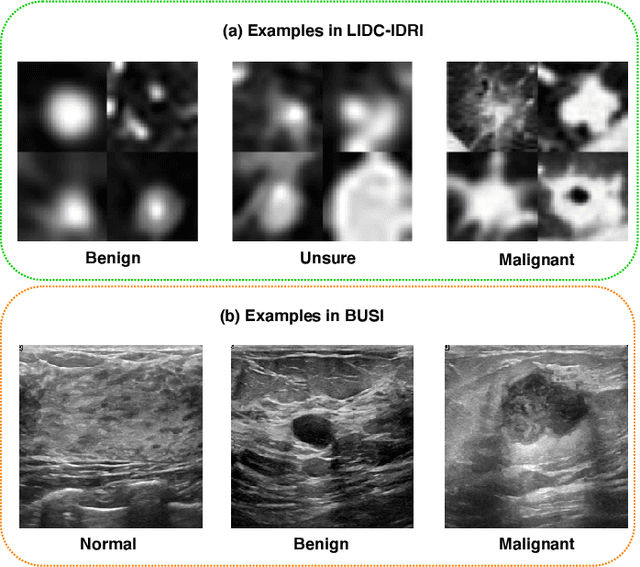
The performance of medical image classification has been enhanced by deep convolutional neural networks (CNNs), which are typically trained with cross-entropy (CE) loss. However, when the label presents an intrinsic ordinal property in nature, e.g., the development from benign to malignant tumor, CE loss cannot take into account such ordinal information to allow for better generalization. To improve model generalization with ordinal information, we propose a novel meta ordinal regression forest (MORF) method for medical image classification with ordinal labels, which learns the ordinal relationship through the combination of convolutional neural network and differential forest in a meta-learning framework. The merits of the proposed MORF come from the following two components: a tree-wise weighting net (TWW-Net) and a grouped feature selection (GFS) module. First, the TWW-Net assigns each tree in the forest with a specific weight that is mapped from the classification loss of the corresponding tree. Hence, all the trees possess varying weights, which is helpful for alleviating the tree-wise prediction variance. Second, the GFS module enables a dynamic forest rather than a fixed one that was previously used, allowing for random feature perturbation. During training, we alternatively optimize the parameters of the CNN backbone and TWW-Net in the meta-learning framework through calculating the Hessian matrix. Experimental results on two medical image classification datasets with ordinal labels, i.e., LIDC-IDRI and Breast Ultrasound Dataset, demonstrate the superior performances of our MORF method over existing state-of-the-art methods.
OpenKBP-Opt: An international and reproducible evaluation of 76 knowledge-based planning pipelines
Feb 16, 2022

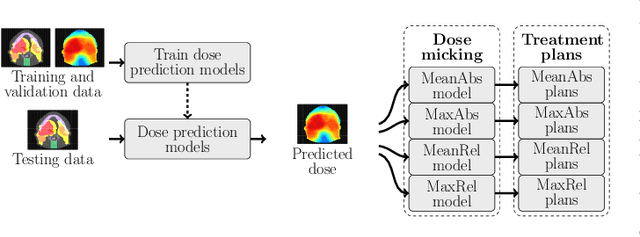
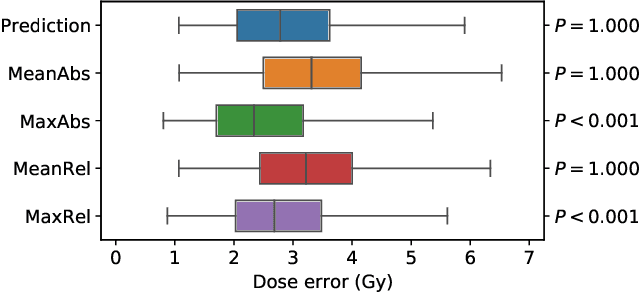
We establish an open framework for developing plan optimization models for knowledge-based planning (KBP) in radiotherapy. Our framework includes reference plans for 100 patients with head-and-neck cancer and high-quality dose predictions from 19 KBP models that were developed by different research groups during the OpenKBP Grand Challenge. The dose predictions were input to four optimization models to form 76 unique KBP pipelines that generated 7600 plans. The predictions and plans were compared to the reference plans via: dose score, which is the average mean absolute voxel-by-voxel difference in dose a model achieved; the deviation in dose-volume histogram (DVH) criterion; and the frequency of clinical planning criteria satisfaction. We also performed a theoretical investigation to justify our dose mimicking models. The range in rank order correlation of the dose score between predictions and their KBP pipelines was 0.50 to 0.62, which indicates that the quality of the predictions is generally positively correlated with the quality of the plans. Additionally, compared to the input predictions, the KBP-generated plans performed significantly better (P<0.05; one-sided Wilcoxon test) on 18 of 23 DVH criteria. Similarly, each optimization model generated plans that satisfied a higher percentage of criteria than the reference plans. Lastly, our theoretical investigation demonstrated that the dose mimicking models generated plans that are also optimal for a conventional planning model. This was the largest international effort to date for evaluating the combination of KBP prediction and optimization models. In the interest of reproducibility, our data and code is freely available at https://github.com/ababier/open-kbp-opt.
Exploring Non-Contrastive Representation Learning for Deep Clustering
Nov 23, 2021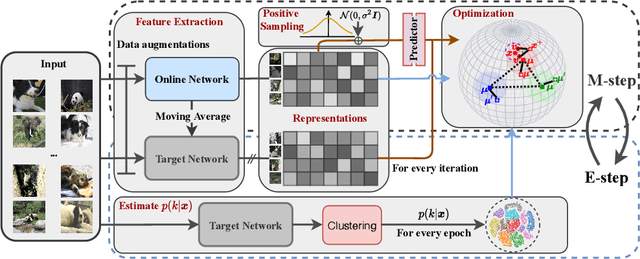
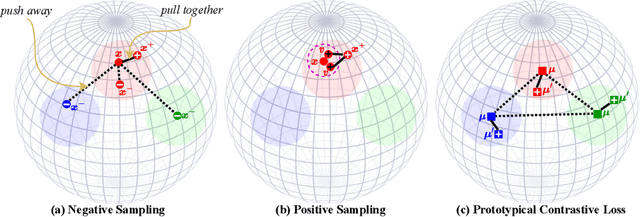
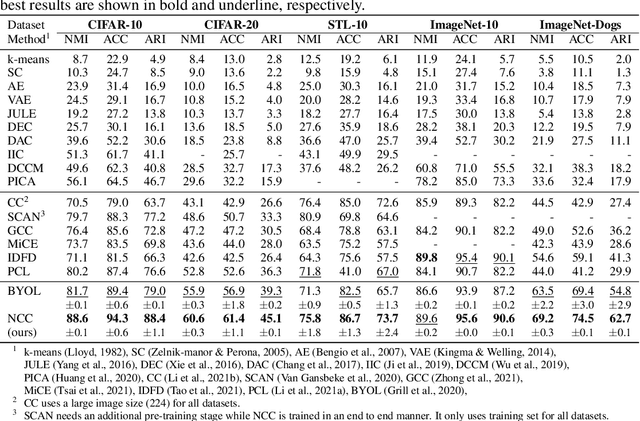
Existing deep clustering methods rely on contrastive learning for representation learning, which requires negative examples to form an embedding space where all instances are well-separated. However, the negative examples inevitably give rise to the class collision issue, compromising the representation learning for clustering. In this paper, we explore non-contrastive representation learning for deep clustering, termed NCC, which is based on BYOL, a representative method without negative examples. First, we propose to align one augmented view of instance with the neighbors of another view in the embedding space, called positive sampling strategy, which avoids the class collision issue caused by the negative examples and hence improves the within-cluster compactness. Second, we propose to encourage alignment between two augmented views of one prototype and uniformity among all prototypes, named prototypical contrastive loss or ProtoCL, which can maximize the inter-cluster distance. Moreover, we formulate NCC in an Expectation-Maximization (EM) framework, in which E-step utilizes spherical k-means to estimate the pseudo-labels of instances and distribution of prototypes from a target network and M-step leverages the proposed losses to optimize an online network. As a result, NCC forms an embedding space where all clusters are well-separated and within-cluster examples are compact. Experimental results on several clustering benchmark datasets including ImageNet-1K demonstrate that NCC outperforms the state-of-the-art methods by a significant margin.
Impact of loss functions on the performance of a deep neural network designed to restore low-dose digital mammography
Nov 12, 2021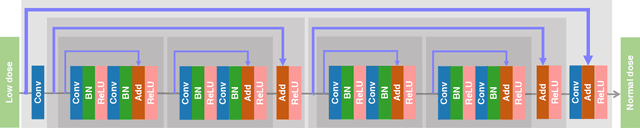
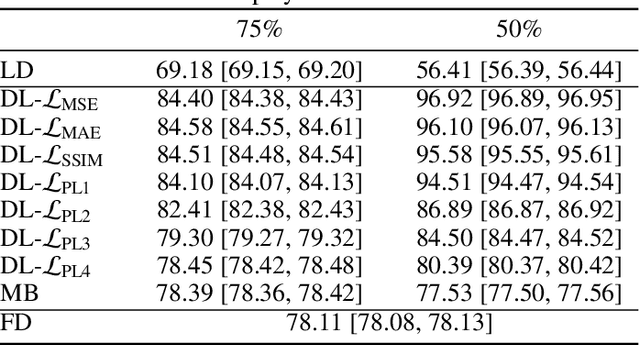
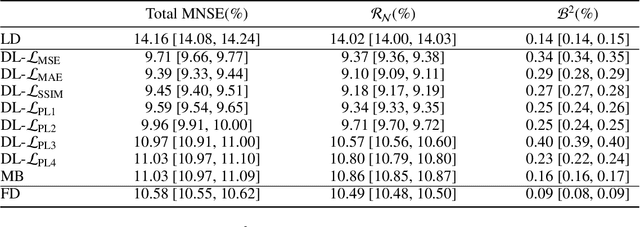
Digital mammography is still the most common imaging tool for breast cancer screening. Although the benefits of using digital mammography for cancer screening outweigh the risks associated with the x-ray exposure, the radiation dose must be kept as low as possible while maintaining the diagnostic utility of the generated images, thus minimizing patient risks. Many studies investigated the feasibility of dose reduction by restoring low-dose images using deep neural networks. In these cases, choosing the appropriate training database and loss function is crucial and impacts the quality of the results. In this work, a modification of the ResNet architecture, with hierarchical skip connections, is proposed to restore low-dose digital mammography. We compared the restored images to the standard full-dose images. Moreover, we evaluated the performance of several loss functions for this task. For training purposes, we extracted 256,000 image patches from a dataset of 400 images of retrospective clinical mammography exams, where different dose levels were simulated to generate low and standard-dose pairs. To validate the network in a real scenario, a physical anthropomorphic breast phantom was used to acquire real low-dose and standard full-dose images in a commercially avaliable mammography system, which were then processed through our trained model. An analytical restoration model for low-dose digital mammography, previously presented, was used as a benchmark in this work. Objective assessment was performed through the signal-to-noise ratio (SNR) and mean normalized squared error (MNSE), decomposed into residual noise and bias. Results showed that the perceptual loss function (PL4) is able to achieve virtually the same noise levels of a full-dose acquisition, while resulting in smaller signal bias compared to other loss functions.
DU-GAN: Generative Adversarial Networks with Dual-Domain U-Net Based Discriminators for Low-Dose CT Denoising
Aug 24, 2021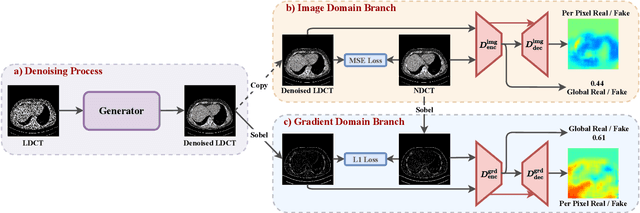
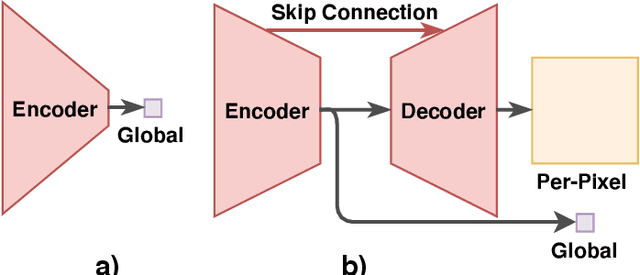
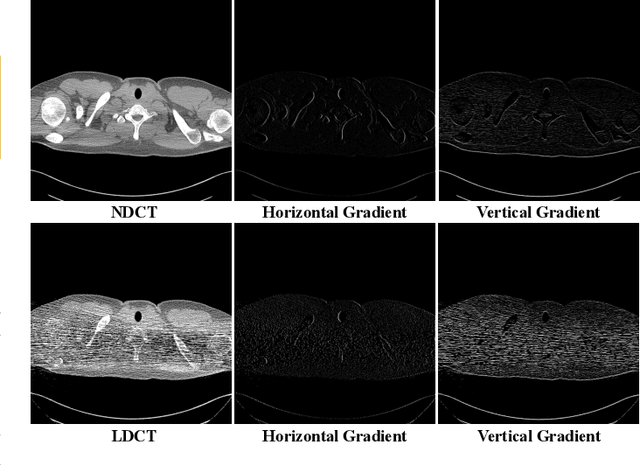
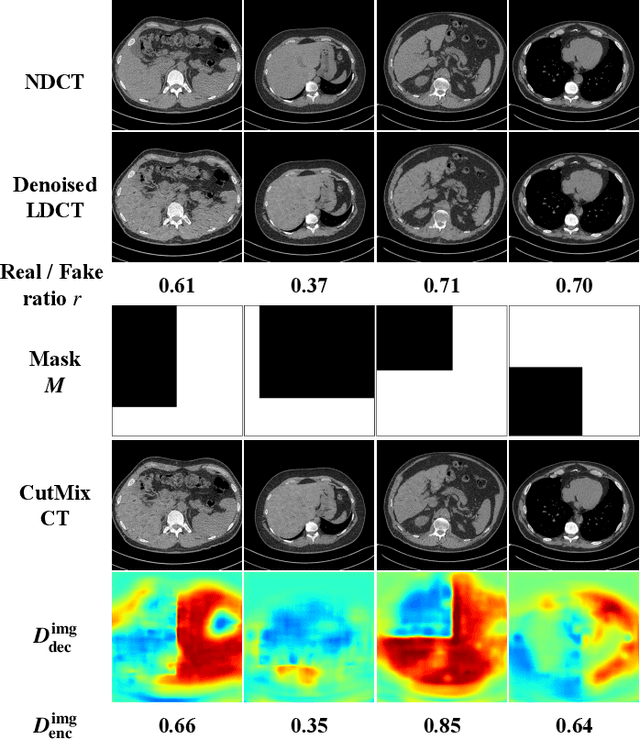
LDCT has drawn major attention in the medical imaging field due to the potential health risks of CT-associated X-ray radiation to patients. Reducing the radiation dose, however, decreases the quality of the reconstructed images, which consequently compromises the diagnostic performance. Various deep learning techniques have been introduced to improve the image quality of LDCT images through denoising. GANs-based denoising methods usually leverage an additional classification network, i.e. discriminator, to learn the most discriminate difference between the denoised and normal-dose images and, hence, regularize the denoising model accordingly; it often focuses either on the global structure or local details. To better regularize the LDCT denoising model, this paper proposes a novel method, termed DU-GAN, which leverages U-Net based discriminators in the GANs framework to learn both global and local difference between the denoised and normal-dose images in both image and gradient domains. The merit of such a U-Net based discriminator is that it can not only provide the per-pixel feedback to the denoising network through the outputs of the U-Net but also focus on the global structure in a semantic level through the middle layer of the U-Net. In addition to the adversarial training in the image domain, we also apply another U-Net based discriminator in the image gradient domain to alleviate the artifacts caused by photon starvation and enhance the edge of the denoised CT images. Furthermore, the CutMix technique enables the per-pixel outputs of the U-Net based discriminator to provide radiologists with a confidence map to visualize the uncertainty of the denoised results, facilitating the LDCT-based screening and diagnosis. Extensive experiments on the simulated and real-world datasets demonstrate superior performance over recently published methods both qualitatively and quantitatively.