 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSDFormer: An Innovative Transformer-Mamba Framework for Robust High-Precision Driver Distraction Identification
Sep 09, 2024



Driver distraction remains a leading cause of traffic accidents, posing a critical threat to road safety globally. As intelligent transportation systems evolve, accurate and real-time identification of driver distraction has become essential. However, existing methods struggle to capture both global contextual and fine-grained local features while contending with noisy labels in training datasets. To address these challenges, we propose DSDFormer, a novel framework that integrates the strengths of Transformer and Mamba architectures through a Dual State Domain Attention (DSDA) mechanism, enabling a balance between long-range dependencies and detailed feature extraction for robust driver behavior recognition. Additionally, we introduce Temporal Reasoning Confident Learning (TRCL), an unsupervised approach that refines noisy labels by leveraging spatiotemporal correlations in video sequences. Our model achieves state-of-the-art performance on the AUC-V1, AUC-V2, and 100-Driver datasets and demonstrates real-time processing efficiency on the NVIDIA Jetson AGX Orin platform. Extensive experimental results confirm that DSDFormer and TRCL significantly improve both the accuracy and robustness of driver distraction detection, offering a scalable solution to enhance road safety.
DTR: A Unified Deep Tensor Representation Framework for Multimedia Data Recovery
Jul 07, 2024



Recently, the transform-based tensor representation has attracted increasing attention in multimedia data (e.g., images and videos) recovery problems, which consists of two indispensable components, i.e., transform and characterization. Previously, the development of transform-based tensor representation mainly focuses on the transform aspect. Although several attempts consider using shallow matrix factorization (e.g., singular value decomposition and negative matrix factorization) to characterize the frontal slices of transformed tensor (termed as latent tensor), the faithful characterization aspect is underexplored. To address this issue, we propose a unified Deep Tensor Representation (termed as DTR) framework by synergistically combining the deep latent generative module and the deep transform module. Especially, the deep latent generative module can faithfully generate the latent tensor as compared with shallow matrix factorization. The new DTR framework not only allows us to better understand the classic shallow representations, but also leads us to explore new representation. To examine the representation ability of the proposed DTR, we consider the representative multi-dimensional data recovery task and suggest an unsupervised DTR-based multi-dimensional data recovery model. Extensive experiments demonstrate that DTR achieves superior performance compared to state-of-the-art methods in both quantitative and qualitative aspects, especially for fine details recovery.
RO-SVD: A Reconfigurable Hardware Copyright Protection Framework for AIGC Applications
Jun 17, 2024



The dramatic surge in the utilisation of generative artificial intelligence (GenAI) underscores the need for a secure and efficient mechanism to responsibly manage, use and disseminate multi-dimensional data generated by artificial intelligence (AI). In this paper, we propose a blockchain-based copyright traceability framework called ring oscillator-singular value decomposition (RO-SVD), which introduces decomposition computing to approximate low-rank matrices generated from hardware entropy sources and establishes an AI-generated content (AIGC) copyright traceability mechanism at the device level. By leveraging the parallelism and reconfigurability of field-programmable gate arrays (FPGAs), our framework can be easily constructed on existing AI-accelerated devices and provide a low-cost solution to emerging copyright issues of AIGC. We developed a hardware-software (HW/SW) co-design prototype based on comprehensive analysis and on-board experiments with multiple AI-applicable FPGAs. Using AI-generated images as a case study, our framework demonstrated effectiveness and emphasised customisation, unpredictability, efficiency, management and reconfigurability. To the best of our knowledge, this is the first practical hardware study discussing and implementing copyright traceability specifically for AI-generated content.
CURSOR: Scalable Mixed-Order Hypergraph Matching with CUR Decomposition
Feb 26, 2024



To achieve greater accuracy, hypergraph matching algorithms require exponential increases in computational resources. Recent kd-tree-based approximate nearest neighbor (ANN) methods, despite the sparsity of their compatibility tensor, still require exhaustive calculations for large-scale graph matching. This work utilizes CUR tensor decomposition and introduces a novel cascaded second and third-order hypergraph matching framework (CURSOR) for efficient hypergraph matching. A CUR-based second-order graph matching algorithm is used to provide a rough match, and then the core of CURSOR, a fiber-CUR-based tensor generation method, directly calculates entries of the compatibility tensor by leveraging the initial second-order match result. This significantly decreases the time complexity and tensor density. A probability relaxation labeling (PRL)-based matching algorithm, specifically suitable for sparse tensors, is developed. Experiment results on large-scale synthetic datasets and widely-adopted benchmark sets demonstrate the superiority of CURSOR over existing methods. The tensor generation method in CURSOR can be integrated seamlessly into existing hypergraph matching methods to improve their performance and lower their computational costs.
Domain Generalization with Small Data
Feb 09, 2024



In this work, we propose to tackle the problem of domain generalization in the context of \textit{insufficient samples}. Instead of extracting latent feature embeddings based on deterministic models, we propose to learn a domain-invariant representation based on the probabilistic framework by mapping each data point into probabilistic embeddings. Specifically, we first extend empirical maximum mean discrepancy (MMD) to a novel probabilistic MMD that can measure the discrepancy between mixture distributions (i.e., source domains) consisting of a series of latent distributions rather than latent points. Moreover, instead of imposing the contrastive semantic alignment (CSA) loss based on pairs of latent points, a novel probabilistic CSA loss encourages positive probabilistic embedding pairs to be closer while pulling other negative ones apart. Benefiting from the learned representation captured by probabilistic models, our proposed method can marriage the measurement on the \textit{distribution over distributions} (i.e., the global perspective alignment) and the distribution-based contrastive semantic alignment (i.e., the local perspective alignment). Extensive experimental results on three challenging medical datasets show the effectiveness of our proposed method in the context of insufficient data compared with state-of-the-art methods.
Joint Sparse Representations and Coupled Dictionary Learning in Multi-Source Heterogeneous Image Pseudo-color Fusion
Oct 15, 2023



Considering that Coupled Dictionary Learning (CDL) method can obtain a reasonable linear mathematical relationship between resource images, we propose a novel CDL-based Synthetic Aperture Radar (SAR) and multispectral pseudo-color fusion method. Firstly, the traditional Brovey transform is employed as a pre-processing method on the paired SAR and multispectral images. Then, CDL is used to capture the correlation between the pre-processed image pairs based on the dictionaries generated from the source images via enforced joint sparse coding. Afterward, the joint sparse representation in the pair of dictionaries is utilized to construct an image mask via calculating the reconstruction errors, and therefore generate the final fusion image. The experimental verification results of the SAR images from the Sentinel-1 satellite and the multispectral images from the Landsat-8 satellite show that the proposed method can achieve superior visual effects, and excellent quantitative performance in terms of spectral distortion, correlation coefficient, MSE, NIQE, BRISQUE, and PIQE.
Efficient RRT*-based Safety-Constrained Motion Planning for Continuum Robots in Dynamic Environments
Sep 25, 2023



Continuum robots, characterized by their high flexibility and infinite degrees of freedom (DoFs), have gained prominence in applications such as minimally invasive surgery and hazardous environment exploration. However, the intrinsic complexity of continuum robots requires a significant amount of time for their motion planning, posing a hurdle to their practical implementation. To tackle these challenges, efficient motion planning methods such as Rapidly Exploring Random Trees (RRT) and its variant, RRT*, have been employed. This paper introduces a unique RRT*-based motion control method tailored for continuum robots. Our approach embeds safety constraints derived from the robots' posture states, facilitating autonomous navigation and obstacle avoidance in rapidly changing environments. Simulation results show efficient trajectory planning amidst multiple dynamic obstacles and provide a robust performance evaluation based on the generated postures. Finally, preliminary tests were conducted on a two-segment cable-driven continuum robot prototype, confirming the effectiveness of the proposed planning approach. This method is versatile and can be adapted and deployed for various types of continuum robots through parameter adjustments.
SkeletonMAE: Graph-based Masked Autoencoder for Skeleton Sequence Pre-training
Jul 17, 2023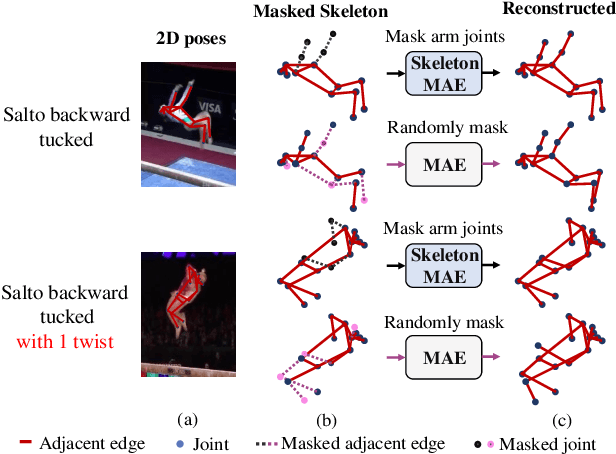
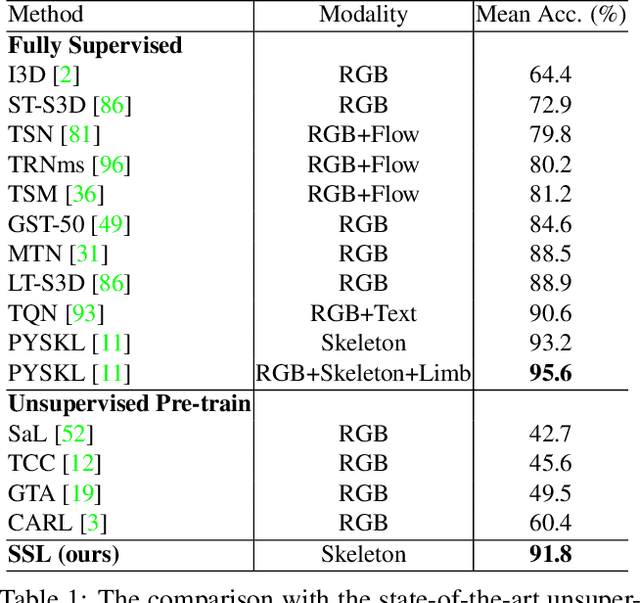
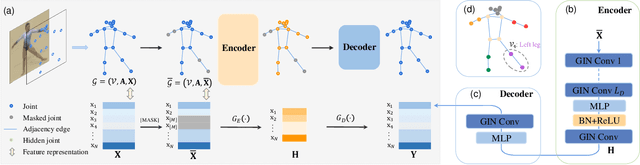
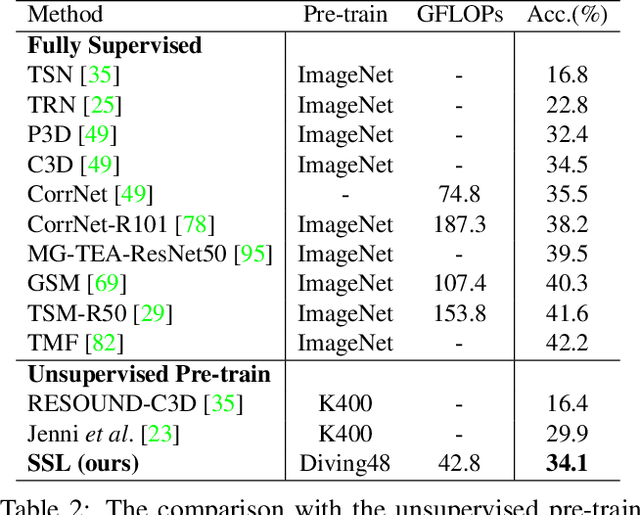
Skeleton sequence representation learning has shown great advantages for action recognition due to its promising ability to model human joints and topology. However, the current methods usually require sufficient labeled data for training computationally expensive models, which is labor-intensive and time-consuming. Moreover, these methods ignore how to utilize the fine-grained dependencies among different skeleton joints to pre-train an efficient skeleton sequence learning model that can generalize well across different datasets. In this paper, we propose an efficient skeleton sequence learning framework, named Skeleton Sequence Learning (SSL). To comprehensively capture the human pose and obtain discriminative skeleton sequence representation, we build an asymmetric graph-based encoder-decoder pre-training architecture named SkeletonMAE, which embeds skeleton joint sequence into Graph Convolutional Network (GCN) and reconstructs the masked skeleton joints and edges based on the prior human topology knowledge. Then, the pre-trained SkeletonMAE encoder is integrated with the Spatial-Temporal Representation Learning (STRL) module to build the SSL framework. Extensive experimental results show that our SSL generalizes well across different datasets and outperforms the state-of-the-art self-supervised skeleton-based action recognition methods on FineGym, Diving48, NTU 60 and NTU 120 datasets. Additionally, we obtain comparable performance to some fully supervised methods. The code is avaliable at https://github.com/HongYan1123/SkeletonMAE.
Visual Causal Scene Refinement for Video Question Answering
May 07, 2023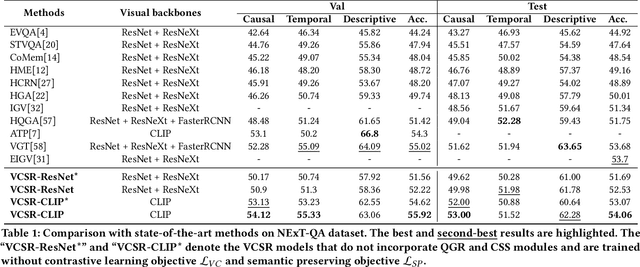
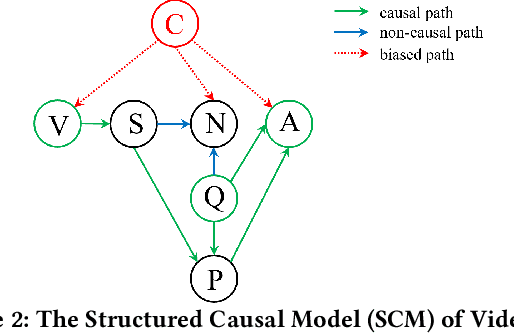
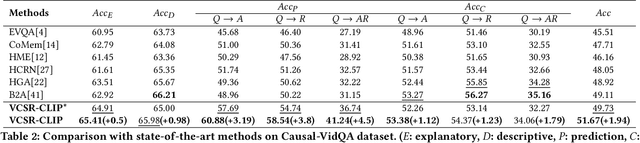
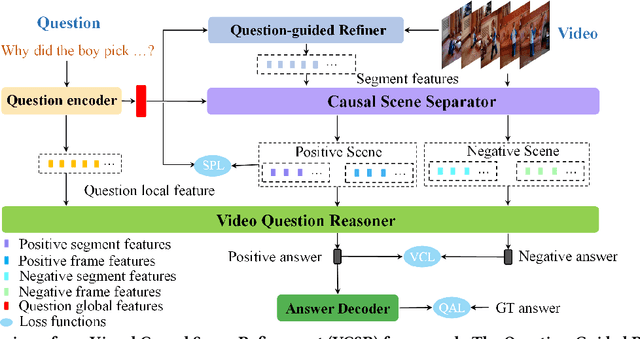
Existing methods for video question answering (VideoQA) often suffer from spurious correlations between different modalities, leading to a failure in identifying the dominant visual evidence and the intended question. Moreover, these methods function as black boxes, making it difficult to interpret the visual scene during the QA process. In this paper, to discover critical video segments and frames that serve as the visual causal scene for generating reliable answers, we present a causal analysis of VideoQA and propose a framework for cross-modal causal relational reasoning, named Visual Causal Scene Refinement (VCSR). Particularly, a set of causal front-door intervention operations is introduced to explicitly find the visual causal scenes at both segment and frame levels. Our VCSR involves two essential modules: i) the Question-Guided Refiner (QGR) module, which refines consecutive video frames guided by the question semantics to obtain more representative segment features for causal front-door intervention; ii) the Causal Scene Separator (CSS) module, which discovers a collection of visual causal and non-causal scenes based on the visual-linguistic causal relevance and estimates the causal effect of the scene-separating intervention in a contrastive learning manner. Extensive experiments on the NExT-QA, Causal-VidQA, and MSRVTT-QA datasets demonstrate the superiority of our VCSR in discovering visual causal scene and achieving robust video question answering.
Robust Cross-domain CT Image Reconstruction via Bayesian Noise Uncertainty Alignment
Feb 26, 2023



In this work, we tackle the problem of robust computed tomography (CT) reconstruction issue under a cross-domain scenario, i.e., the training CT data as the source domain and the testing CT data as the target domain are collected from different anatomical regions. Due to the mismatches of the scan region and corresponding scan protocols, there is usually a difference of noise distributions between source and target domains (a.k.a. noise distribution shifts), resulting in a catastrophic deterioration of the reconstruction performance on target domain. To render a robust cross-domain CT reconstruction performance, instead of using deterministic models (e.g., convolutional neural network), a Bayesian-endowed probabilistic framework is introduced into robust cross-domain CT reconstruction task due to its impressive robustness. Under this probabilistic framework, we propose to alleviate the noise distribution shifts between source and target domains via implicit noise modeling schemes in the latent space and image space, respectively. Specifically, a novel Bayesian noise uncertainty alignment (BNUA) method is proposed to conduct implicit noise distribution modeling and alignment in the latent space. Moreover, an adversarial learning manner is imposed to reduce the discrepancy of noise distribution between two domains in the image space via a novel residual distribution alignment (RDA). Extensive experiments on the head and abdomen scans show that our proposed method can achieve a better performance of robust cross-domain CT reconstruction than existing approaches in terms of both quantitative and qualitative results.