 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLASER: A Text-Free Speech-to-Speech Translation Evaluation Metric
Dec 16, 2022



End-to-End speech-to-speech translation (S2ST) is generally evaluated with text-based metrics. This means that generated speech has to be automatically transcribed, making the evaluation dependent on the availability and quality of automatic speech recognition (ASR) systems. In this paper, we propose a text-free evaluation metric for end-to-end S2ST, named BLASER, to avoid the dependency on ASR systems. BLASER leverages a multilingual multimodal encoder to directly encode the speech segments for source input, translation output and reference into a shared embedding space and computes a score of the translation quality that can be used as a proxy to human evaluation. To evaluate our approach, we construct training and evaluation sets from more than 40k human annotations covering seven language directions. The best results of BLASER are achieved by training with supervision from human rating scores. We show that when evaluated at the sentence level, BLASER correlates significantly better with human judgment compared to ASR-dependent metrics including ASR-SENTBLEU in all translation directions and ASR-COMET in five of them. Our analysis shows combining speech and text as inputs to BLASER does not increase the correlation with human scores, but best correlations are achieved when using speech, which motivates the goal of our research. Moreover, we show that using ASR for references is detrimental for text-based metrics.
Speech-to-Speech Translation For A Real-world Unwritten Language
Nov 11, 2022



We study speech-to-speech translation (S2ST) that translates speech from one language into another language and focuses on building systems to support languages without standard text writing systems. We use English-Taiwanese Hokkien as a case study, and present an end-to-end solution from training data collection, modeling choices to benchmark dataset release. First, we present efforts on creating human annotated data, automatically mining data from large unlabeled speech datasets, and adopting pseudo-labeling to produce weakly supervised data. On the modeling, we take advantage of recent advances in applying self-supervised discrete representations as target for prediction in S2ST and show the effectiveness of leveraging additional text supervision from Mandarin, a language similar to Hokkien, in model training. Finally, we release an S2ST benchmark set to facilitate future research in this field. The demo can be found at https://huggingface.co/spaces/facebook/Hokkien_Translation .
SpeechMatrix: A Large-Scale Mined Corpus of Multilingual Speech-to-Speech Translations
Nov 08, 2022



We present SpeechMatrix, a large-scale multilingual corpus of speech-to-speech translations mined from real speech of European Parliament recordings. It contains speech alignments in 136 language pairs with a total of 418 thousand hours of speech. To evaluate the quality of this parallel speech, we train bilingual speech-to-speech translation models on mined data only and establish extensive baseline results on EuroParl-ST, VoxPopuli and FLEURS test sets. Enabled by the multilinguality of SpeechMatrix, we also explore multilingual speech-to-speech translation, a topic which was addressed by few other works. We also demonstrate that model pre-training and sparse scaling using Mixture-of-Experts bring large gains to translation performance. The mined data and models are freely available.
DiffEdit: Diffusion-based semantic image editing with mask guidance
Oct 20, 2022
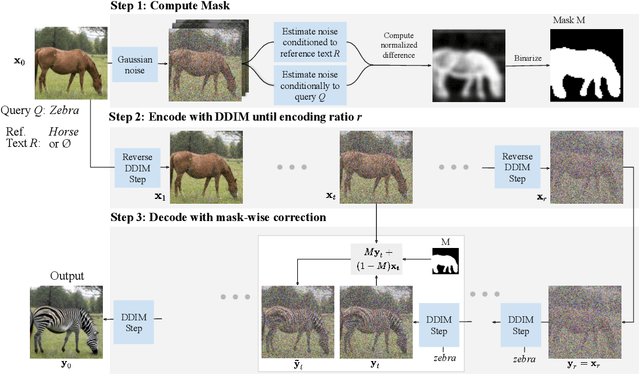
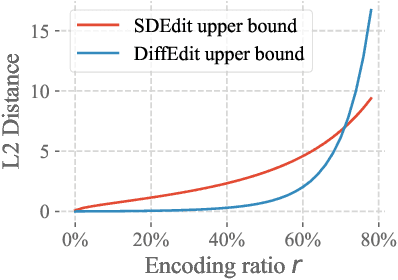
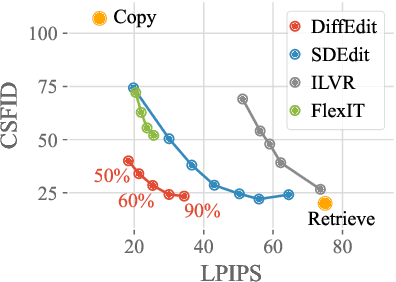
Image generation has recently seen tremendous advances, with diffusion models allowing to synthesize convincing images for a large variety of text prompts. In this article, we propose DiffEdit, a method to take advantage of text-conditioned diffusion models for the task of semantic image editing, where the goal is to edit an image based on a text query. Semantic image editing is an extension of image generation, with the additional constraint that the generated image should be as similar as possible to a given input image. Current editing methods based on diffusion models usually require to provide a mask, making the task much easier by treating it as a conditional inpainting task. In contrast, our main contribution is able to automatically generate a mask highlighting regions of the input image that need to be edited, by contrasting predictions of a diffusion model conditioned on different text prompts. Moreover, we rely on latent inference to preserve content in those regions of interest and show excellent synergies with mask-based diffusion. DiffEdit achieves state-of-the-art editing performance on ImageNet. In addition, we evaluate semantic image editing in more challenging settings, using images from the COCO dataset as well as text-based generated images.
Multilingual Representation Distillation with Contrastive Learning
Oct 10, 2022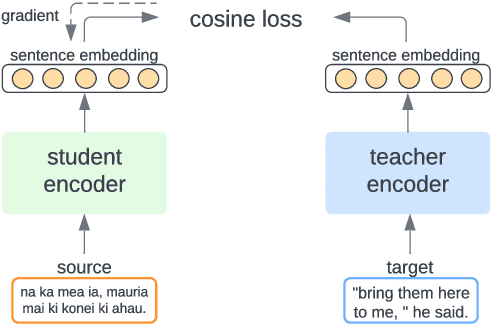

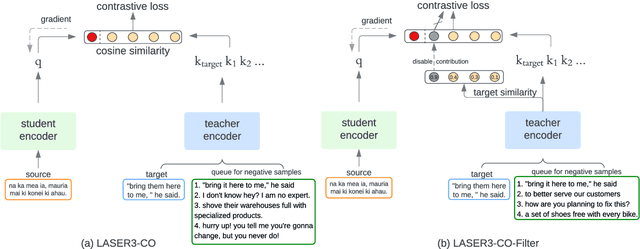
Multilingual sentence representations from large models can encode semantic information from two or more languages and can be used for different cross-lingual information retrieval tasks. In this paper, we integrate contrastive learning into multilingual representation distillation and use it for quality estimation of parallel sentences (find semantically similar sentences that can be used as translations of each other). We validate our approach with multilingual similarity search and corpus filtering tasks. Experiments across different low-resource languages show that our method significantly outperforms previous sentence encoders such as LASER, LASER3, and LaBSE.
No Language Left Behind: Scaling Human-Centered Machine Translation
Jul 11, 2022
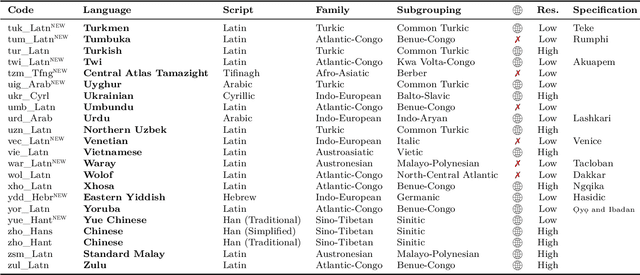
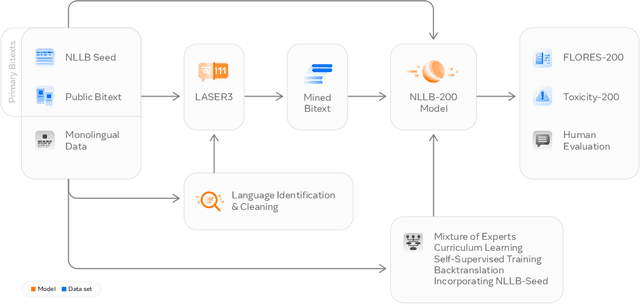
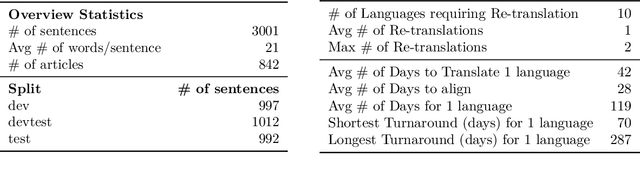
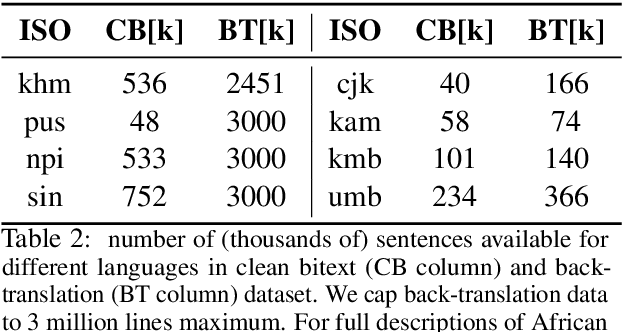
Driven by the goal of eradicating language barriers on a global scale, machine translation has solidified itself as a key focus of artificial intelligence research today. However, such efforts have coalesced around a small subset of languages, leaving behind the vast majority of mostly low-resource languages. What does it take to break the 200 language barrier while ensuring safe, high quality results, all while keeping ethical considerations in mind? In No Language Left Behind, we took on this challenge by first contextualizing the need for low-resource language translation support through exploratory interviews with native speakers. Then, we created datasets and models aimed at narrowing the performance gap between low and high-resource languages. More specifically, we developed a conditional compute model based on Sparsely Gated Mixture of Experts that is trained on data obtained with novel and effective data mining techniques tailored for low-resource languages. We propose multiple architectural and training improvements to counteract overfitting while training on thousands of tasks. Critically, we evaluated the performance of over 40,000 different translation directions using a human-translated benchmark, Flores-200, and combined human evaluation with a novel toxicity benchmark covering all languages in Flores-200 to assess translation safety. Our model achieves an improvement of 44% BLEU relative to the previous state-of-the-art, laying important groundwork towards realizing a universal translation system. Finally, we open source all contributions described in this work, accessible at https://github.com/facebookresearch/fairseq/tree/nllb.
Bitext Mining Using Distilled Sentence Representations for Low-Resource Languages
May 25, 2022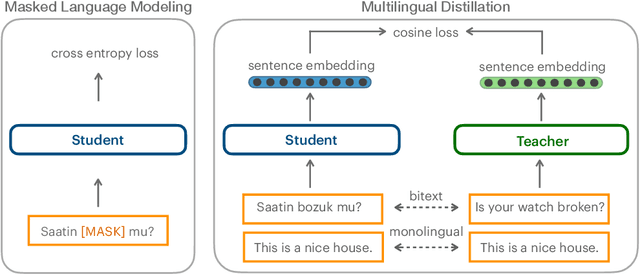
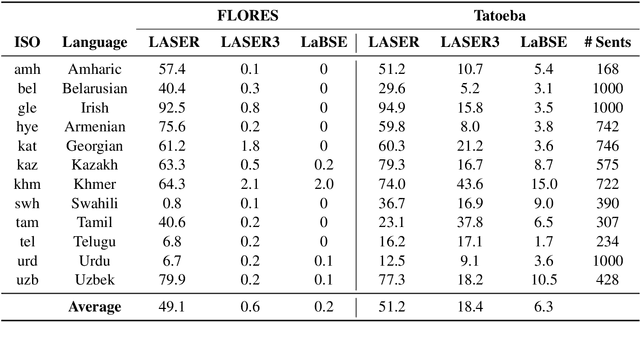
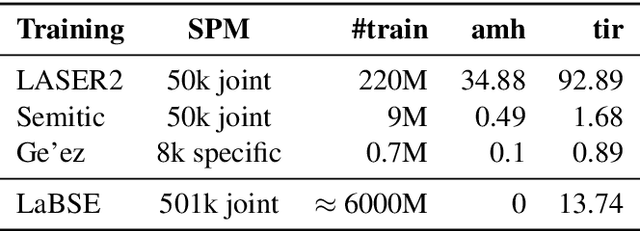

Scaling multilingual representation learning beyond the hundred most frequent languages is challenging, in particular to cover the long tail of low-resource languages. A promising approach has been to train one-for-all multilingual models capable of cross-lingual transfer, but these models often suffer from insufficient capacity and interference between unrelated languages. Instead, we move away from this approach and focus on training multiple language (family) specific representations, but most prominently enable all languages to still be encoded in the same representational space. To achieve this, we focus on teacher-student training, allowing all encoders to be mutually compatible for bitext mining, and enabling fast learning of new languages. We introduce a new teacher-student training scheme which combines supervised and self-supervised training, allowing encoders to take advantage of monolingual training data, which is valuable in the low-resource setting. Our approach significantly outperforms the original LASER encoder. We study very low-resource languages and handle 50 African languages, many of which are not covered by any other model. For these languages, we train sentence encoders, mine bitexts, and validate the bitexts by training NMT systems.
T-Modules: Translation Modules for Zero-Shot Cross-Modal Machine Translation
May 24, 2022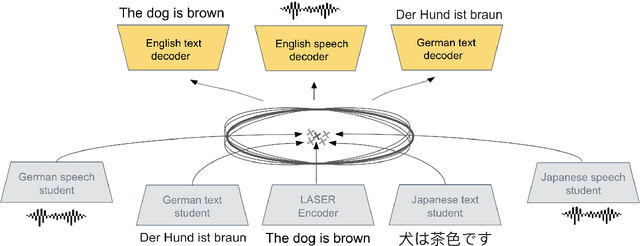

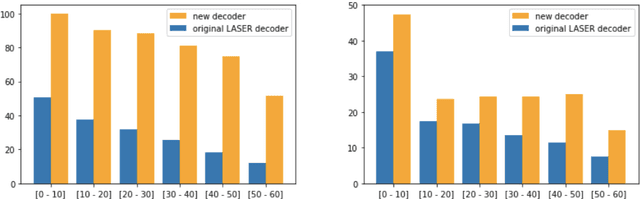
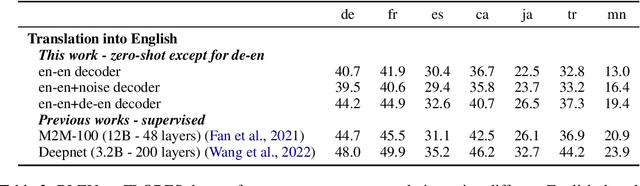
We present a new approach to perform zero-shot cross-modal transfer between speech and text for translation tasks. Multilingual speech and text are encoded in a joint fixed-size representation space. Then, we compare different approaches to decode these multimodal and multilingual fixed-size representations, enabling zero-shot translation between languages and modalities. All our models are trained without the need of cross-modal labeled translation data. Despite a fixed-size representation, we achieve very competitive results on several text and speech translation tasks. In particular, we significantly improve the state-of-the-art for zero-shot speech translation on Must-C. Incorporating a speech decoder in our framework, we introduce the first results for zero-shot direct speech-to-speech and text-to-speech translation.
FlexIT: Towards Flexible Semantic Image Translation
Mar 09, 2022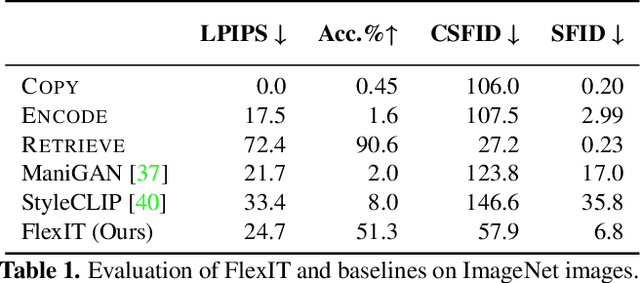
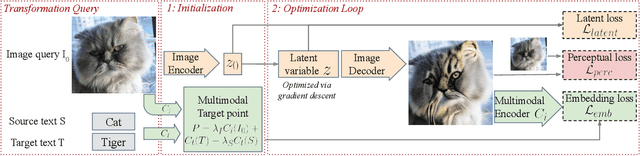

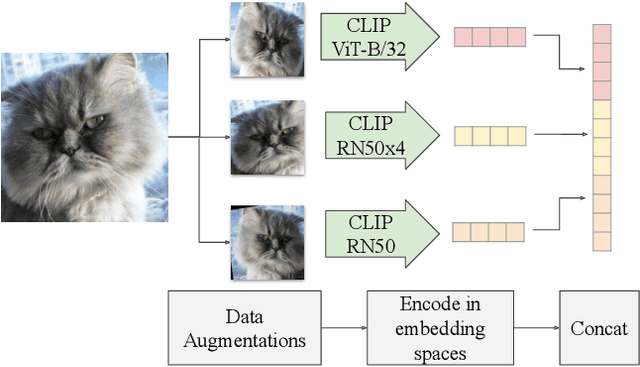
Deep generative models, like GANs, have considerably improved the state of the art in image synthesis, and are able to generate near photo-realistic images in structured domains such as human faces. Based on this success, recent work on image editing proceeds by projecting images to the GAN latent space and manipulating the latent vector. However, these approaches are limited in that only images from a narrow domain can be transformed, and with only a limited number of editing operations. We propose FlexIT, a novel method which can take any input image and a user-defined text instruction for editing. Our method achieves flexible and natural editing, pushing the limits of semantic image translation. First, FlexIT combines the input image and text into a single target point in the CLIP multimodal embedding space. Via the latent space of an auto-encoder, we iteratively transform the input image toward the target point, ensuring coherence and quality with a variety of novel regularization terms. We propose an evaluation protocol for semantic image translation, and thoroughly evaluate our method on ImageNet. Code will be made publicly available.
Textless Speech-to-Speech Translation on Real Data
Dec 15, 2021
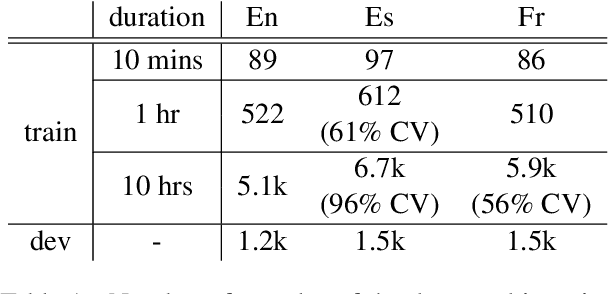
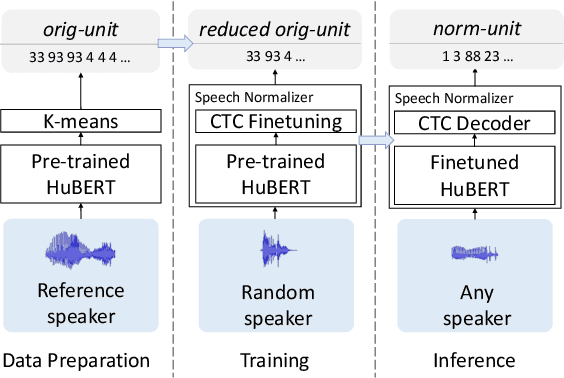
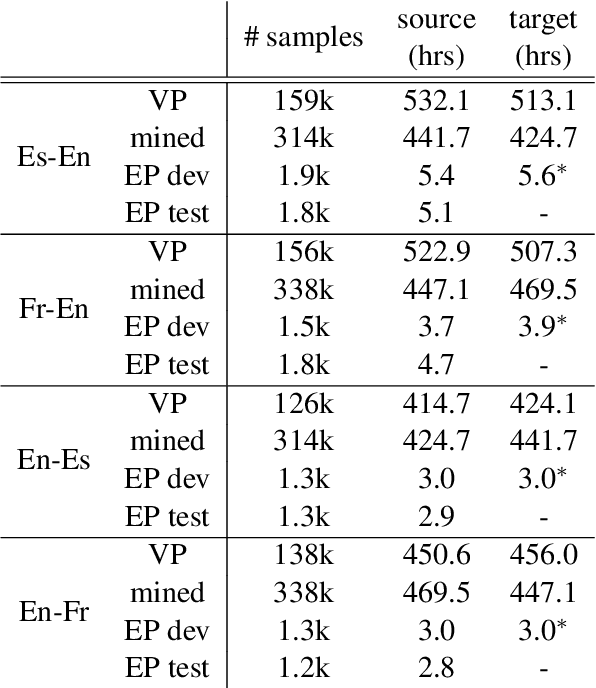
We present a textless speech-to-speech translation (S2ST) system that can translate speech from one language into another language and can be built without the need of any text data. Different from existing work in the literature, we tackle the challenge in modeling multi-speaker target speech and train the systems with real-world S2ST data. The key to our approach is a self-supervised unit-based speech normalization technique, which finetunes a pre-trained speech encoder with paired audios from multiple speakers and a single reference speaker to reduce the variations due to accents, while preserving the lexical content. With only 10 minutes of paired data for speech normalization, we obtain on average 3.2 BLEU gain when training the S2ST model on the \vp~S2ST dataset, compared to a baseline trained on un-normalized speech target. We also incorporate automatically mined S2ST data and show an additional 2.0 BLEU gain. To our knowledge, we are the first to establish a textless S2ST technique that can be trained with real-world data and works for multiple language pairs.