 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteraction-via-Actions: Cattle Interaction Detection with Joint Learning of Action-Interaction Latent Space
Dec 18, 2025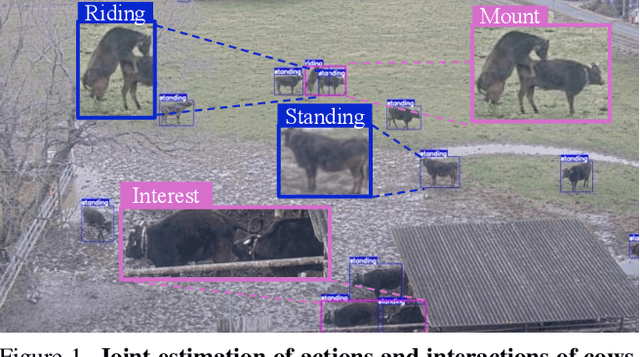
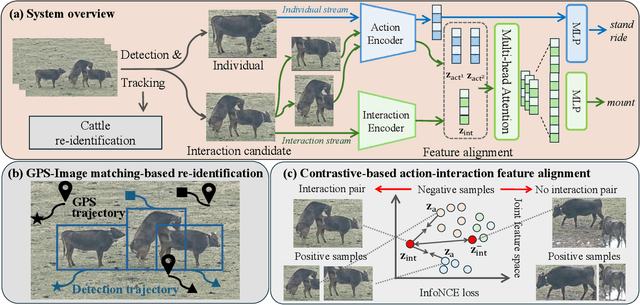
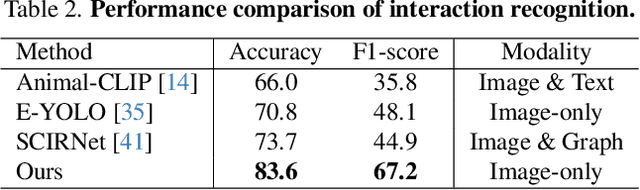
This paper introduces a method and application for automatically detecting behavioral interactions between grazing cattle from a single image, which is essential for smart livestock management in the cattle industry, such as for detecting estrus. Although interaction detection for humans has been actively studied, a non-trivial challenge lies in cattle interaction detection, specifically the lack of a comprehensive behavioral dataset that includes interactions, as the interactions of grazing cattle are rare events. We, therefore, propose CattleAct, a data-efficient method for interaction detection by decomposing interactions into the combinations of actions by individual cattle. Specifically, we first learn an action latent space from a large-scale cattle action dataset. Then, we embed rare interactions via the fine-tuning of the pre-trained latent space using contrastive learning, thereby constructing a unified latent space of actions and interactions. On top of the proposed method, we develop a practical working system integrating video and GPS inputs. Experiments on a commercial-scale pasture demonstrate the accurate interaction detection achieved by our method compared to the baselines. Our implementation is available at https://github.com/rakawanegan/CattleAct.
Real-Time Cattle Interaction Recognition via Triple-stream Network
Sep 06, 2022
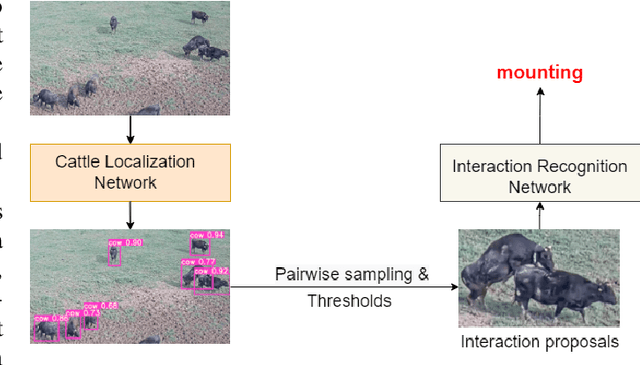
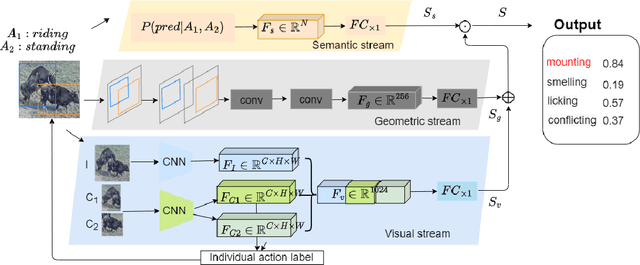
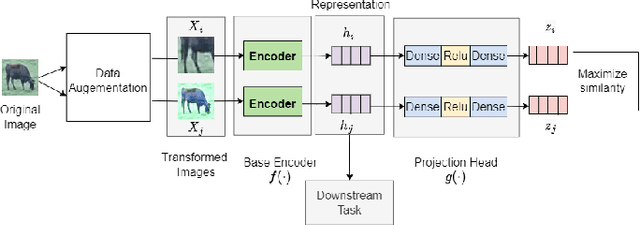
In stockbreeding of beef cattle, computer vision-based approaches have been widely employed to monitor cattle conditions (e.g. the physical, physiology, and health). To this end, the accurate and effective recognition of cattle action is a prerequisite. Generally, most existing models are confined to individual behavior that uses video-based methods to extract spatial-temporal features for recognizing the individual actions of each cattle. However, there is sociality among cattle and their interaction usually reflects important conditions, e.g. estrus, and also video-based method neglects the real-time capability of the model. Based on this, we tackle the challenging task of real-time recognizing interactions between cattle in a single frame in this paper. The pipeline of our method includes two main modules: Cattle Localization Network and Interaction Recognition Network. At every moment, cattle localization network outputs high-quality interaction proposals from every detected cattle and feeds them into the interaction recognition network with a triple-stream architecture. Such a triple-stream network allows us to fuse different features relevant to recognizing interactions. Specifically, the three kinds of features are a visual feature that extracts the appearance representation of interaction proposals, a geometric feature that reflects the spatial relationship between cattle, and a semantic feature that captures our prior knowledge of the relationship between the individual action and interaction of cattle. In addition, to solve the problem of insufficient quantity of labeled data, we pre-train the model based on self-supervised learning. Qualitative and quantitative evaluation evidences the performance of our framework as an effective method to recognize cattle interaction in real time.