 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModularity through Attention: Efficient Training and Transfer of Language-Conditioned Policies for Robot Manipulation
Dec 08, 2022



Language-conditioned policies allow robots to interpret and execute human instructions. Learning such policies requires a substantial investment with regards to time and compute resources. Still, the resulting controllers are highly device-specific and cannot easily be transferred to a robot with different morphology, capability, appearance or dynamics. In this paper, we propose a sample-efficient approach for training language-conditioned manipulation policies that allows for rapid transfer across different types of robots. By introducing a novel method, namely Hierarchical Modularity, and adopting supervised attention across multiple sub-modules, we bridge the divide between modular and end-to-end learning and enable the reuse of functional building blocks. In both simulated and real world robot manipulation experiments, we demonstrate that our method outperforms the current state-of-the-art methods and can transfer policies across 4 different robots in a sample-efficient manner. Finally, we show that the functionality of learned sub-modules is maintained beyond the training process and can be used to introspect the robot decision-making process. Code is available at https://github.com/ir-lab/ModAttn.
Learning and Blending Robot Hugging Behaviors in Time and Space
Dec 03, 2022We introduce an imitation learning-based physical human-robot interaction algorithm capable of predicting appropriate robot responses in complex interactions involving a superposition of multiple interactions. Our proposed algorithm, Blending Bayesian Interaction Primitives (B-BIP) allows us to achieve responsive interactions in complex hugging scenarios, capable of reciprocating and adapting to a hugs motion and timing. We show that this algorithm is a generalization of prior work, for which the original formulation reduces to the particular case of a single interaction, and evaluate our method through both an extensive user study and empirical experiments. Our algorithm yields significantly better quantitative prediction error and more-favorable participant responses with respect to accuracy, responsiveness, and timing, when compared to existing state-of-the-art methods.
A System for Imitation Learning of Contact-Rich Bimanual Manipulation Policies
Aug 01, 2022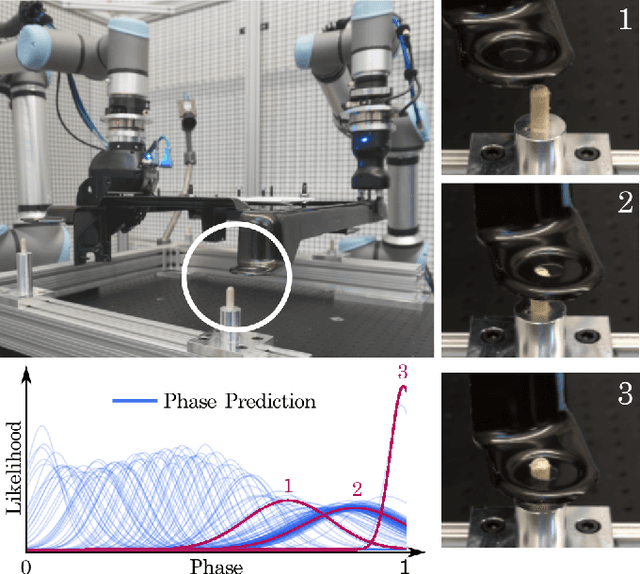
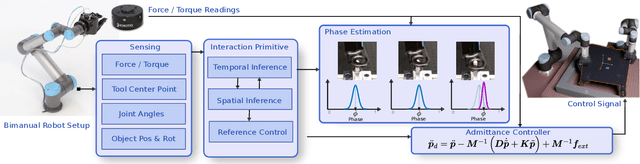

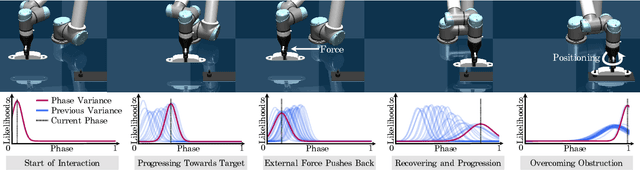
In this paper, we discuss a framework for teaching bimanual manipulation tasks by imitation. To this end, we present a system and algorithms for learning compliant and contact-rich robot behavior from human demonstrations. The presented system combines insights from admittance control and machine learning to extract control policies that can (a) recover from and adapt to a variety of disturbances in time and space, while also (b) effectively leveraging physical contact with the environment. We demonstrate the effectiveness of our approach using a real-world insertion task involving multiple simultaneous contacts between a manipulated object and insertion pegs. We also investigate efficient means of collecting training data for such bimanual settings. To this end, we conduct a human-subject study and analyze the effort and mental demand as reported by the users. Our experiments show that, while harder to provide, the additional force/torque information available in teleoperated demonstrations is crucial for phase estimation and task success. Ultimately, force/torque data substantially improves manipulation robustness, resulting in a 90% success rate in a multipoint insertion task. Code and videos can be found at https://bimanualmanipulation.com/
Local Repair of Neural Networks Using Optimization
Sep 28, 2021
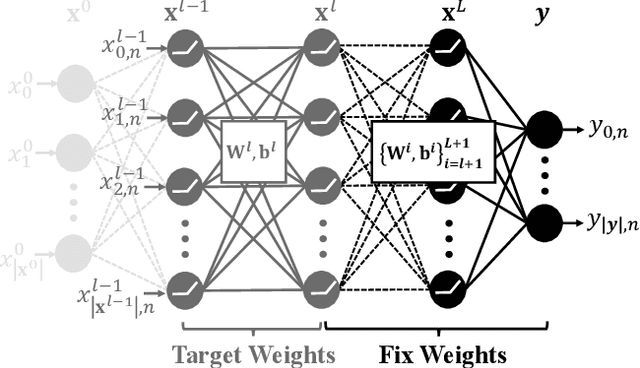
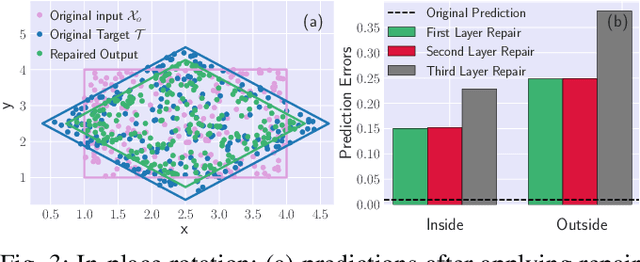
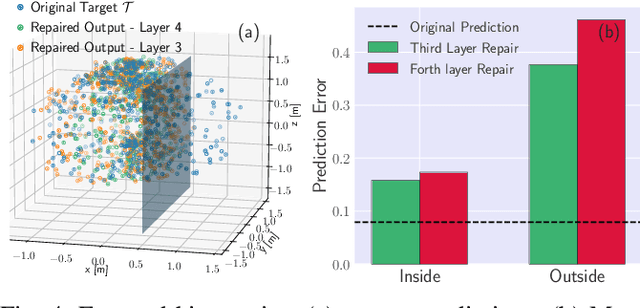
In this paper, we propose a framework to repair a pre-trained feed-forward neural network (NN) to satisfy a set of properties. We formulate the properties as a set of predicates that impose constraints on the output of NN over the target input domain. We define the NN repair problem as a Mixed Integer Quadratic Program (MIQP) to adjust the weights of a single layer subject to the given predicates while minimizing the original loss function over the original training domain. We demonstrate the application of our framework in bounding an affine transformation, correcting an erroneous NN in classification, and bounding the inputs of a NN controller.
Multimodal Data Fusion for Power-On-and-GoRobotic Systems in Retail
Mar 23, 2021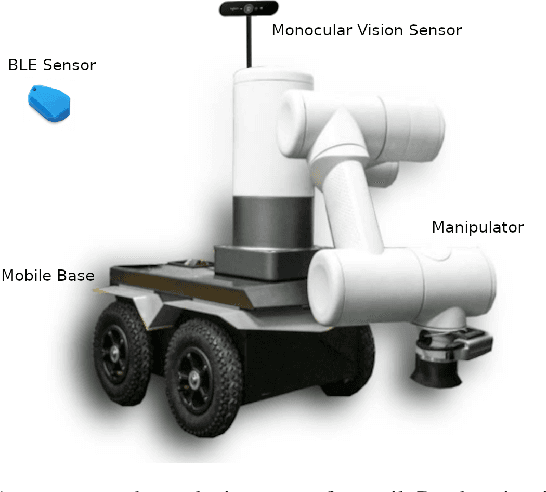
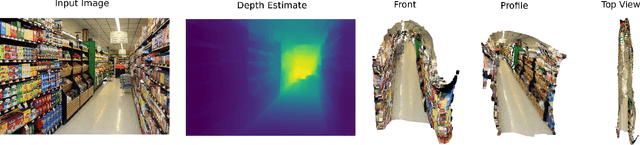
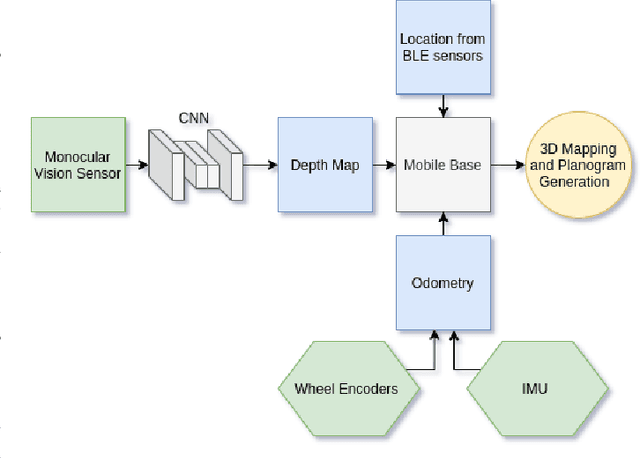

Robotic systems for retail have gained a lot of attention due to the labor-intensive nature of such business environments. Many tasks have the potential to be automated via intelligent robotic systems that have manipulation capabilities. For example, empty shelves can be replenished, stray products can be picked up or new items can be delivered. However, many challenges make the realization of this vision a challenge. In particular, robots are still too expensive and do not work out of the box. In this paper, we discuss a work-in-progress approach for enabling power-on-and-go robots in retail environments through a combination of active, physical sensors and passive, artificial sensors. In particular, we use low-cost hardware sensors in conjunction with machine learning techniques in order to generate high-quality environmental information. More specifically, we present a setup in which a standard monocular camera and Bluetooth low-energy yield a reliable robot system that can immediately be used after placing a couple of sensors in the environment. The camera information is used to synthesize accurate 3D point clouds, whereas the BLE data is used to integrate the data into a complex map of the environment. The combination of active and passive sensing enables high-quality sensing capabilities at a fraction of the costs traditionally associated with such tasks.
Learning Predictive Models for Ergonomic Control of Prosthetic Devices
Nov 13, 2020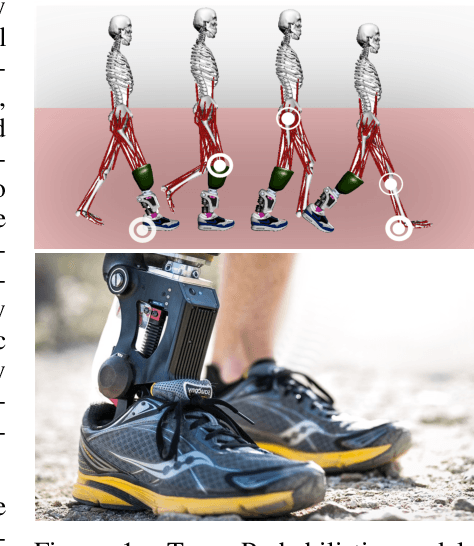

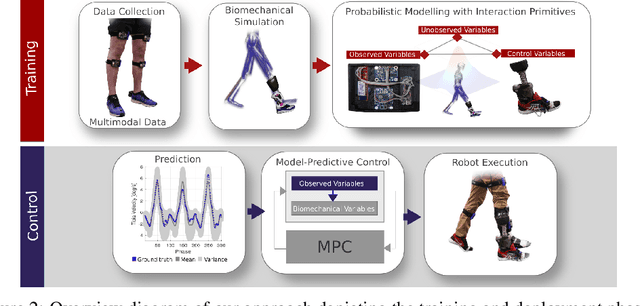
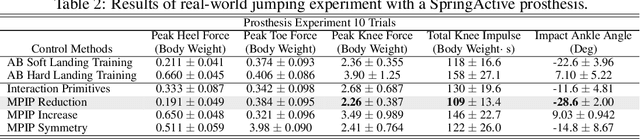
We present Model-Predictive Interaction Primitives -- a robot learning framework for assistive motion in human-machine collaboration tasks which explicitly accounts for biomechanical impact on the human musculoskeletal system. First, we extend Interaction Primitives to enable predictive biomechanics: the prediction of future biomechanical states of a human partner conditioned on current observations and intended robot control signals. In turn, we leverage this capability within a model-predictive control strategy to identify the future ergonomic and biomechanical ramifications of potential robot actions. Optimal control trajectories are selected so as to minimize future physical impact on the human musculoskeletal system. We empirically demonstrate that our approach minimizes knee or muscle forces via generated control actions selected according to biomechanical cost functions. Experiments are performed in synthetic and real-world experiments involving powered prosthetic devices.
Language-Conditioned Imitation Learning for Robot Manipulation Tasks
Oct 22, 2020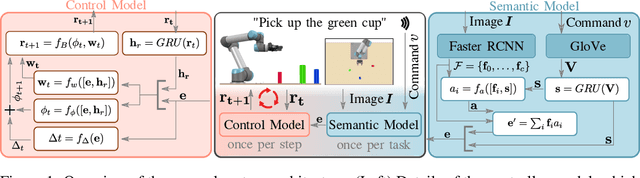
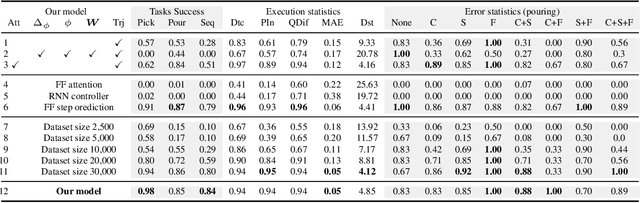
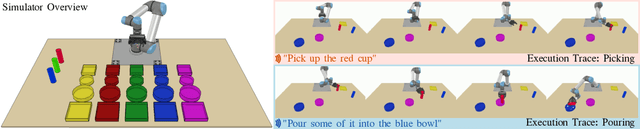
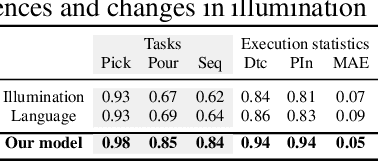
Imitation learning is a popular approach for teaching motor skills to robots. However, most approaches focus on extracting policy parameters from execution traces alone (i.e., motion trajectories and perceptual data). No adequate communication channel exists between the human expert and the robot to describe critical aspects of the task, such as the properties of the target object or the intended shape of the motion. Motivated by insights into the human teaching process, we introduce a method for incorporating unstructured natural language into imitation learning. At training time, the expert can provide demonstrations along with verbal descriptions in order to describe the underlying intent (e.g., "go to the large green bowl"). The training process then interrelates these two modalities to encode the correlations between language, perception, and motion. The resulting language-conditioned visuomotor policies can be conditioned at runtime on new human commands and instructions, which allows for more fine-grained control over the trained policies while also reducing situational ambiguity. We demonstrate in a set of simulation experiments how our approach can learn language-conditioned manipulation policies for a seven-degree-of-freedom robot arm and compare the results to a variety of alternative methods.
Predictive Modeling of Periodic Behavior for Human-Robot Symbiotic Walking
May 27, 2020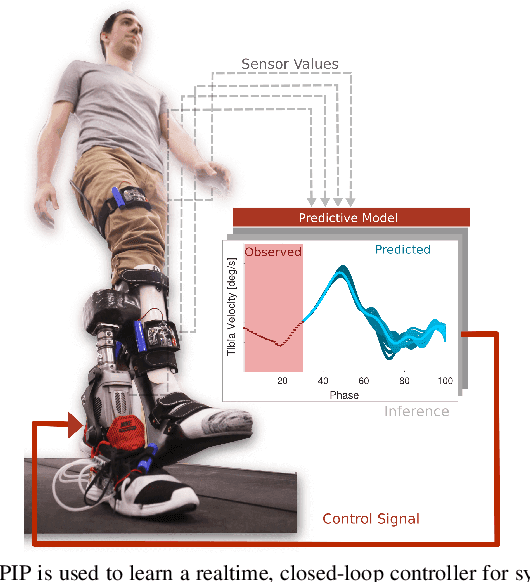
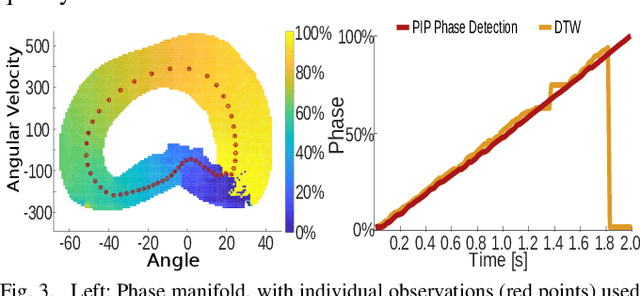
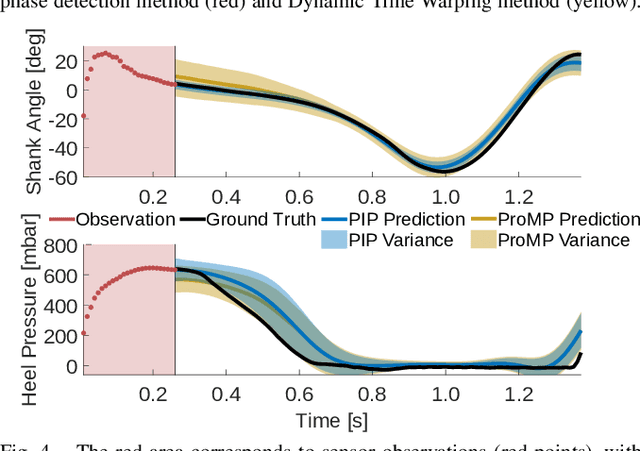
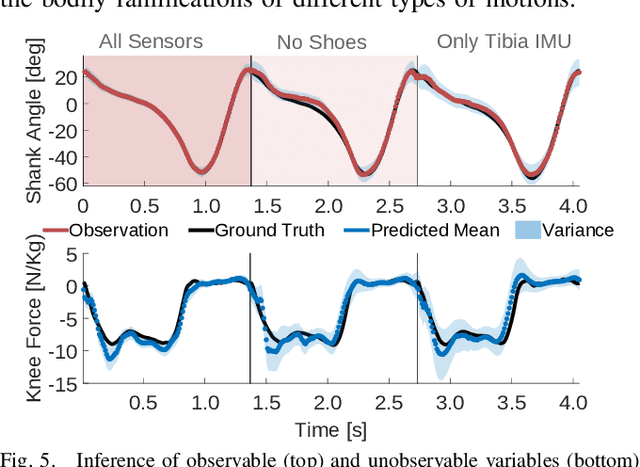
We propose in this paper Periodic Interaction Primitives - a probabilistic framework that can be used to learn compact models of periodic behavior. Our approach extends existing formulations of Interaction Primitives to periodic movement regimes, i.e., walking. We show that this model is particularly well-suited for learning data-driven, customized models of human walking, which can then be used for generating predictions over future states or for inferring latent, biomechanical variables. We also demonstrate how the same framework can be used to learn controllers for a robotic prosthesis using an imitation learning approach. Results in experiments with human participants indicate that Periodic Interaction Primitives efficiently generate predictions and ankle angle control signals for a robotic prosthetic ankle, with MAE of 2.21 degrees in 0.0008s per inference. Performance degrades gracefully in the presence of noise or sensor fall outs. Compared to alternatives, this algorithm functions 20 times faster and performed 4.5 times more accurately on test subjects.
DeepCrashTest: Turning Dashcam Videos into Virtual Crash Tests for Automated Driving Systems
Mar 26, 2020
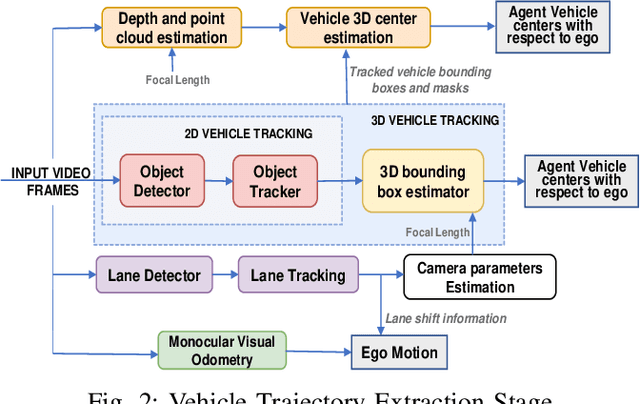

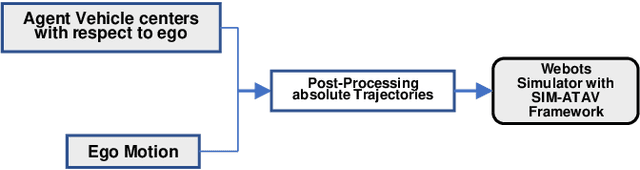
The goal of this paper is to generate simulations with real-world collision scenarios for training and testing autonomous vehicles. We use numerous dashcam crash videos uploaded on the internet to extract valuable collision data and recreate the crash scenarios in a simulator. We tackle the problem of extracting 3D vehicle trajectories from videos recorded by an unknown and uncalibrated monocular camera source using a modular approach. A working architecture and demonstration videos along with the open-source implementation are provided with the paper.
Assistive Relative Pose Estimation for On-orbit Assembly using Convolutional Neural Networks
Feb 19, 2020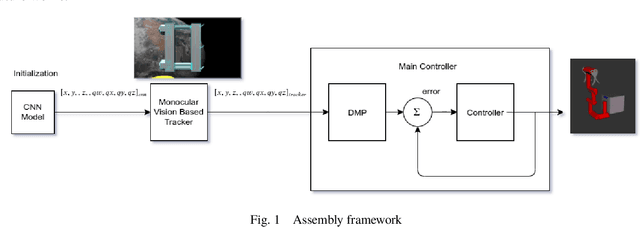
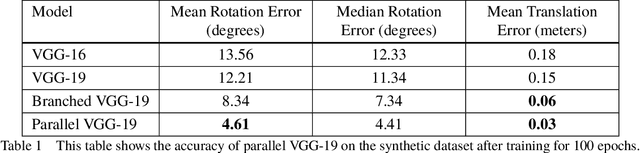


Accurate real-time pose estimation of spacecraft or object in space is a key capability necessary for on-orbit spacecraft servicing and assembly tasks. Pose estimation of objects in space is more challenging than for objects on Earth due to space images containing widely varying illumination conditions, high contrast, and poor resolution in addition to power and mass constraints. In this paper, a convolutional neural network is leveraged to uniquely determine the translation and rotation of an object of interest relative to the camera. The main idea of using CNN model is to assist object tracker used in on space assembly tasks where only feature based method is always not sufficient. The simulation framework designed for assembly task is used to generate dataset for training the modified CNN models and, then results of different models are compared with measure of how accurately models are predicting the pose. Unlike many current approaches for spacecraft or object in space pose estimation, the model does not rely on hand-crafted object-specific features which makes this model more robust and easier to apply to other types of spacecraft. It is shown that the model performs comparable to the current feature-selection methods and can therefore be used in conjunction with them to provide more reliable estimates.