 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifelong Pretraining: Continually Adapting Language Models to Emerging Corpora
Oct 16, 2021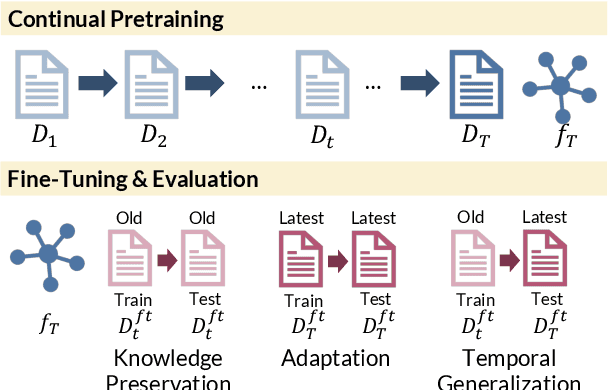
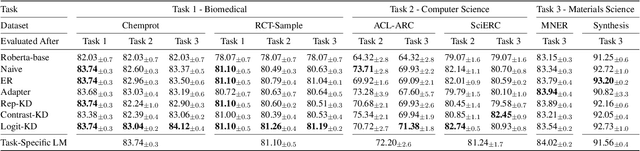
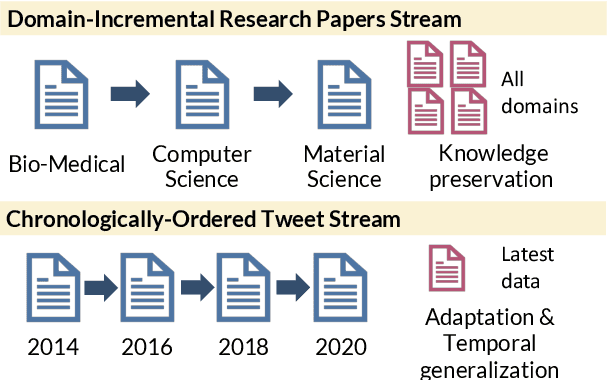
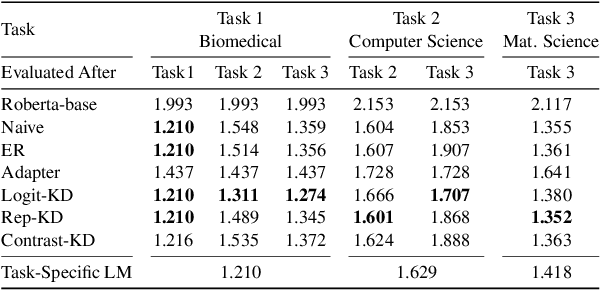
Pretrained language models (PTLMs) are typically learned over a large, static corpus and further fine-tuned for various downstream tasks. However, when deployed in the real world, a PTLM-based model must deal with data from a new domain that deviates from what the PTLM was initially trained on, or newly emerged data that contains out-of-distribution information. In this paper, we study a lifelong language model pretraining challenge where a PTLM is continually updated so as to adapt to emerging data. Over a domain-incremental research paper stream and a chronologically ordered tweet stream, we incrementally pretrain a PTLM with different continual learning algorithms, and keep track of the downstream task performance (after fine-tuning) to analyze its ability of acquiring new knowledge and preserving learned knowledge. Our experiments show continual learning algorithms improve knowledge preservation, with logit distillation being the most effective approach. We further show that continual pretraining improves generalization when training and testing data of downstream tasks are drawn from different time steps, but do not improve when they are from the same time steps. We believe our problem formulation, methods, and analysis will inspire future studies towards continual pretraining of language models.
Pairwise Supervised Contrastive Learning of Sentence Representations
Sep 12, 2021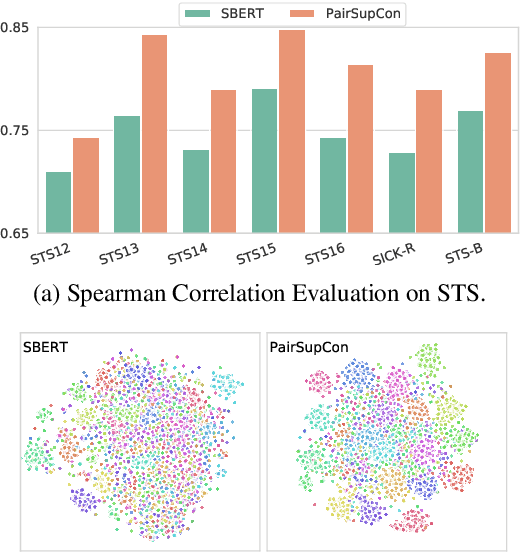
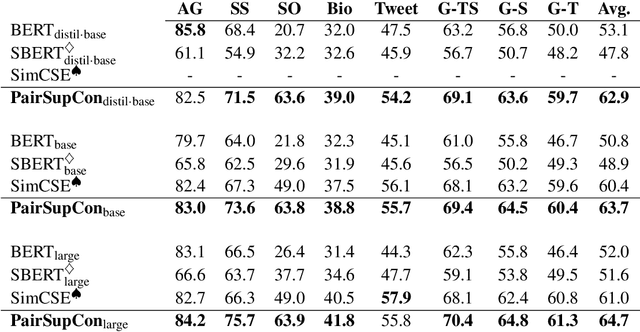
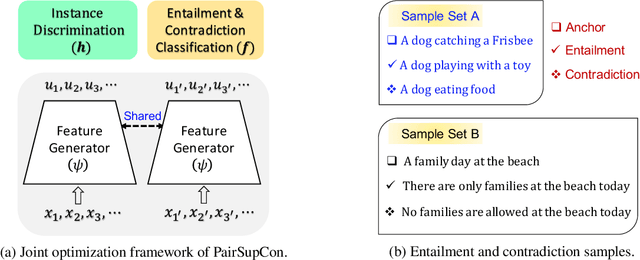
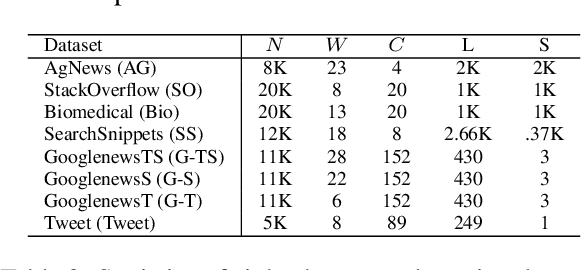
Many recent successes in sentence representation learning have been achieved by simply fine-tuning on the Natural Language Inference (NLI) datasets with triplet loss or siamese loss. Nevertheless, they share a common weakness: sentences in a contradiction pair are not necessarily from different semantic categories. Therefore, optimizing the semantic entailment and contradiction reasoning objective alone is inadequate to capture the high-level semantic structure. The drawback is compounded by the fact that the vanilla siamese or triplet losses only learn from individual sentence pairs or triplets, which often suffer from bad local optima. In this paper, we propose PairSupCon, an instance discrimination based approach aiming to bridge semantic entailment and contradiction understanding with high-level categorical concept encoding. We evaluate PairSupCon on various downstream tasks that involve understanding sentence semantics at different granularities. We outperform the previous state-of-the-art method with $10\%$--$13\%$ averaged improvement on eight clustering tasks, and $5\%$--$6\%$ averaged improvement on seven semantic textual similarity (STS) tasks.
Dual Reader-Parser on Hybrid Textual and Tabular Evidence for Open Domain Question Answering
Aug 05, 2021
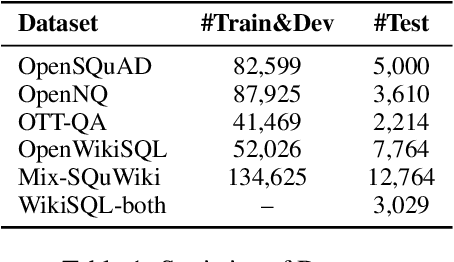
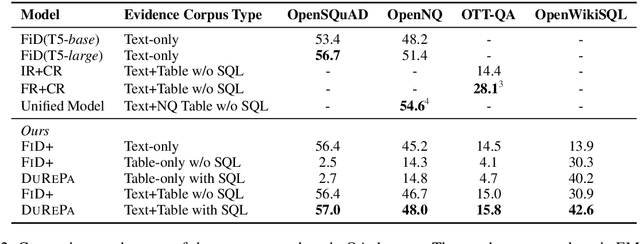
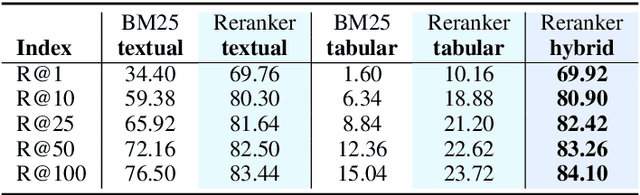
The current state-of-the-art generative models for open-domain question answering (ODQA) have focused on generating direct answers from unstructured textual information. However, a large amount of world's knowledge is stored in structured databases, and need to be accessed using query languages such as SQL. Furthermore, query languages can answer questions that require complex reasoning, as well as offering full explainability. In this paper, we propose a hybrid framework that takes both textual and tabular evidence as input and generates either direct answers or SQL queries depending on which form could better answer the question. The generated SQL queries can then be executed on the associated databases to obtain the final answers. To the best of our knowledge, this is the first paper that applies Text2SQL to ODQA tasks. Empirically, we demonstrate that on several ODQA datasets, the hybrid methods consistently outperforms the baseline models that only take homogeneous input by a large margin. Specifically we achieve state-of-the-art performance on OpenSQuAD dataset using a T5-base model. In a detailed analysis, we demonstrate that the being able to generate structural SQL queries can always bring gains, especially for those questions that requires complex reasoning.
Improving Factual Consistency of Abstractive Summarization via Question Answering
May 10, 2021
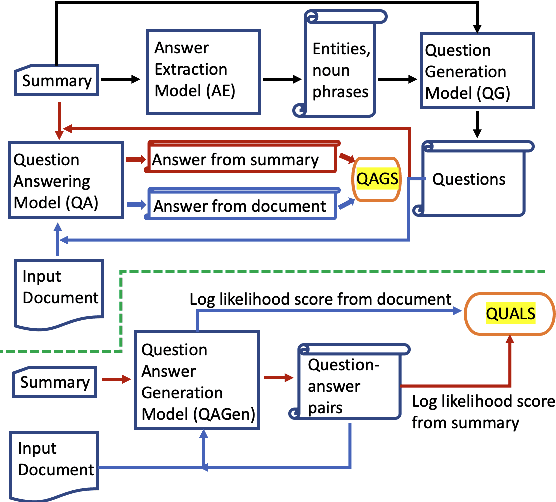
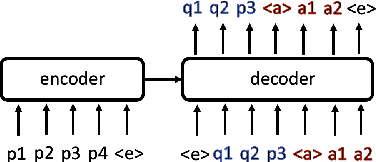
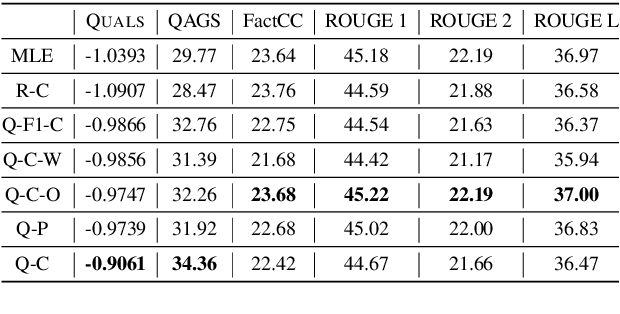
A commonly observed problem with the state-of-the art abstractive summarization models is that the generated summaries can be factually inconsistent with the input documents. The fact that automatic summarization may produce plausible-sounding yet inaccurate summaries is a major concern that limits its wide application. In this paper we present an approach to address factual consistency in summarization. We first propose an efficient automatic evaluation metric to measure factual consistency; next, we propose a novel learning algorithm that maximizes the proposed metric during model training. Through extensive experiments, we confirm that our method is effective in improving factual consistency and even overall quality of the summaries, as judged by both automatic metrics and human evaluation.
Supporting Clustering with Contrastive Learning
Mar 24, 2021
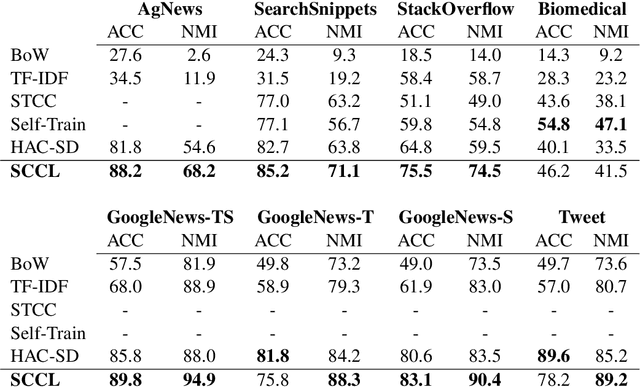
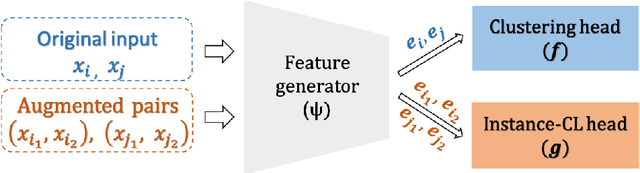
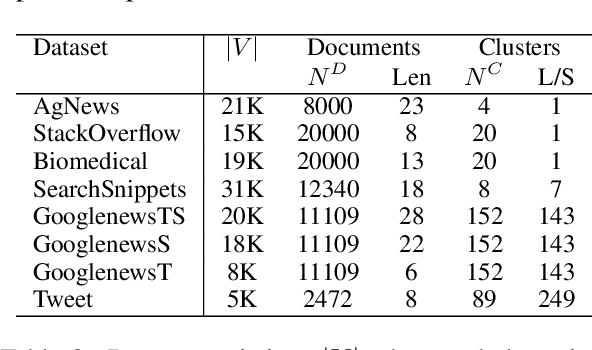
Unsupervised clustering aims at discovering the semantic categories of data according to some distance measured in the representation space. However, different categories often overlap with each other in the representation space at the beginning of the learning process, which poses a significant challenge for distance-based clustering in achieving good separation between different categories. To this end, we propose Supporting Clustering with Contrastive Learning (SCCL) -- a novel framework to leverage contrastive learning to promote better separation. We assess the performance of SCCL on short text clustering and show that SCCL significantly advances the state-of-the-art results on most benchmark datasets with 3%-11% improvement on Accuracy and 4%-15% improvement on Normalized Mutual Information. Furthermore, our quantitative analysis demonstrates the effectiveness of SCCL in leveraging the strengths of both bottom-up instance discrimination and top-down clustering to achieve better intra-cluster and inter-cluster distances when evaluated with the ground truth cluster labels
Entity-level Factual Consistency of Abstractive Text Summarization
Feb 18, 2021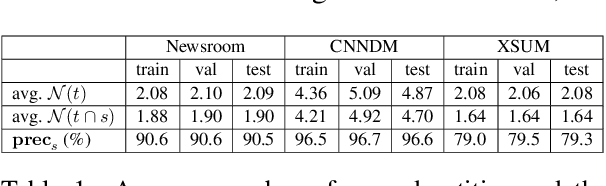

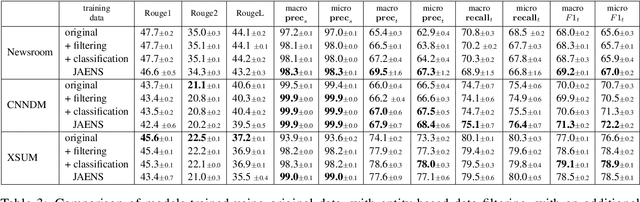

A key challenge for abstractive summarization is ensuring factual consistency of the generated summary with respect to the original document. For example, state-of-the-art models trained on existing datasets exhibit entity hallucination, generating names of entities that are not present in the source document. We propose a set of new metrics to quantify the entity-level factual consistency of generated summaries and we show that the entity hallucination problem can be alleviated by simply filtering the training data. In addition, we propose a summary-worthy entity classification task to the training process as well as a joint entity and summary generation approach, which yield further improvements in entity level metrics.
Zero-shot Generalization in Dialog State Tracking through Generative Question Answering
Jan 20, 2021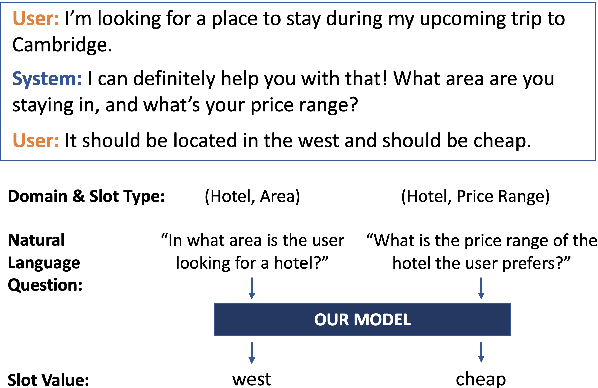
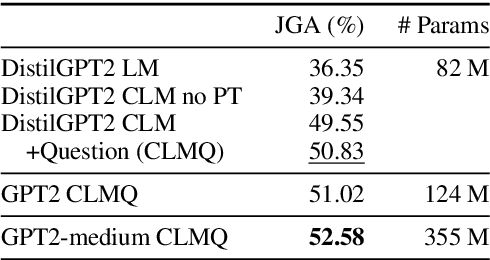
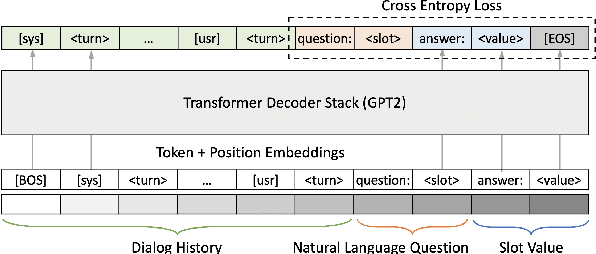
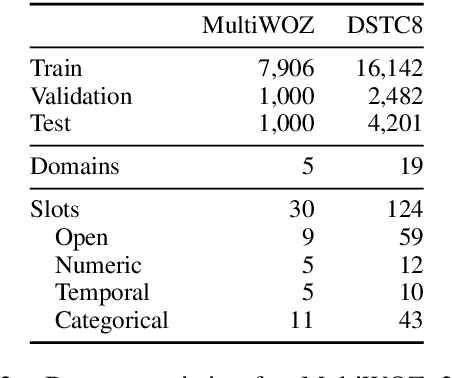
Dialog State Tracking (DST), an integral part of modern dialog systems, aims to track user preferences and constraints (slots) in task-oriented dialogs. In real-world settings with constantly changing services, DST systems must generalize to new domains and unseen slot types. Existing methods for DST do not generalize well to new slot names and many require known ontologies of slot types and values for inference. We introduce a novel ontology-free framework that supports natural language queries for unseen constraints and slots in multi-domain task-oriented dialogs. Our approach is based on generative question-answering using a conditional language model pre-trained on substantive English sentences. Our model improves joint goal accuracy in zero-shot domain adaptation settings by up to 9% (absolute) over the previous state-of-the-art on the MultiWOZ 2.1 dataset.
Learning Contextual Representations for Semantic Parsing with Generation-Augmented Pre-Training
Dec 18, 2020
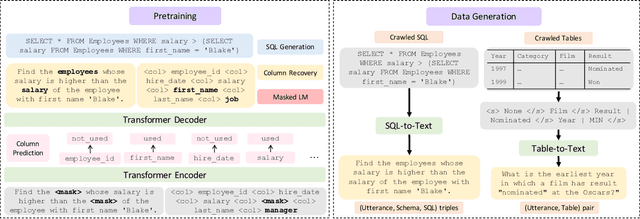
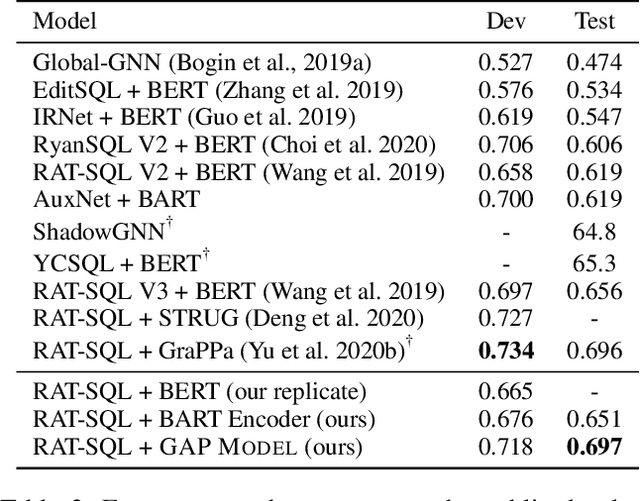
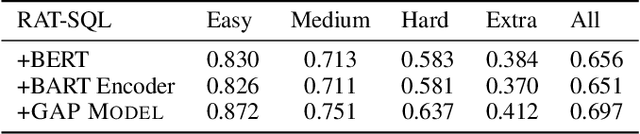
Most recently, there has been significant interest in learning contextual representations for various NLP tasks, by leveraging large scale text corpora to train large neural language models with self-supervised learning objectives, such as Masked Language Model (MLM). However, based on a pilot study, we observe three issues of existing general-purpose language models when they are applied to text-to-SQL semantic parsers: fail to detect column mentions in the utterances, fail to infer column mentions from cell values, and fail to compose complex SQL queries. To mitigate these issues, we present a model pre-training framework, Generation-Augmented Pre-training (GAP), that jointly learns representations of natural language utterances and table schemas by leveraging generation models to generate pre-train data. GAP MODEL is trained on 2M utterance-schema pairs and 30K utterance-schema-SQL triples, whose utterances are produced by generative models. Based on experimental results, neural semantic parsers that leverage GAP MODEL as a representation encoder obtain new state-of-the-art results on both SPIDER and CRITERIA-TO-SQL benchmarks.
Answering Ambiguous Questions through Generative Evidence Fusion and Round-Trip Prediction
Nov 26, 2020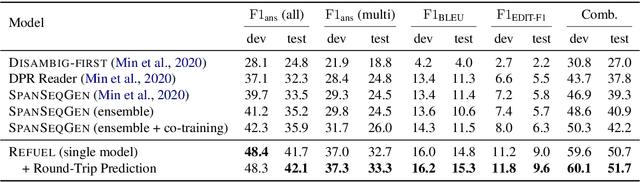
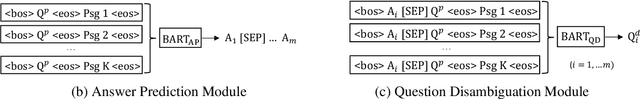
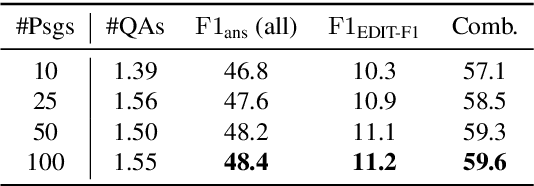

In open-domain question answering, questions are highly likely to be ambiguous because users may not know the scope of relevant topics when formulating them. Therefore, a system needs to find every possible interpretation of the question, and propose a set of disambiguated question-answer pairs. In this paper, we present a model that aggregates and combines evidence from multiple passages to generate question-answer pairs. Particularly, our model reads a large number of passages to find as many interpretations as possible. In addition, we propose a novel round-trip prediction approach to generate additional interpretations that our model fails to find in the first pass, and then verify and filter out the incorrect question-answer pairs to arrive at the final disambiguated output. On the recently introduced AmbigQA open-domain question answering dataset, our model, named Refuel, achieves a new state-of-the-art, outperforming the previous best model by a large margin. We also conduct comprehensive analyses to validate the effectiveness of our proposed round-trip prediction.
An Ensemble Approach for Automatic Structuring of Radiology Reports
Oct 11, 2020
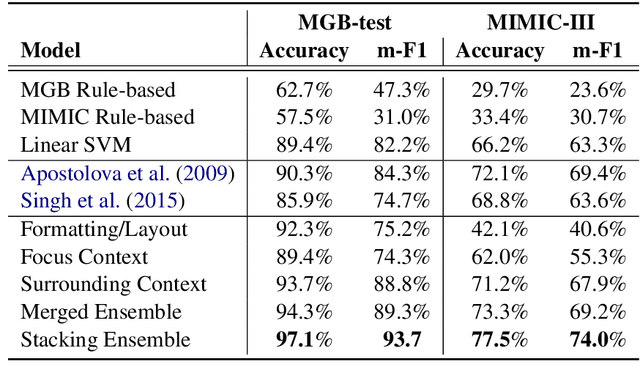
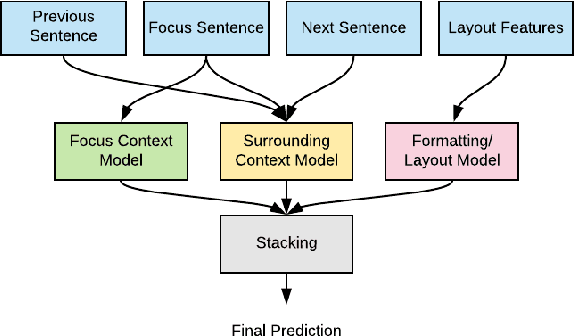

Automatic structuring of electronic medical records is of high demand for clinical workflow solutions to facilitate extraction, storage, and querying of patient care information. However, developing a scalable solution is extremely challenging, specifically for radiology reports, as most healthcare institutes use either no template or department/institute specific templates. Moreover, radiologists' reporting style varies from one to another as sentences are telegraphic and do not follow general English grammar rules. We present an ensemble method that consolidates the predictions of three models, capturing various attributes of textual information for automatic labeling of sentences with section labels. These three models are: 1) Focus Sentence model, capturing context of the target sentence; 2) Surrounding Context model, capturing the neighboring context of the target sentence; and finally, 3) Formatting/Layout model, aimed at learning report formatting cues. We utilize Bi-directional LSTMs, followed by sentence encoders, to acquire the context. Furthermore, we define several features that incorporate the structure of reports. We compare our proposed approach against multiple baselines and state-of-the-art approaches on a proprietary dataset as well as 100 manually annotated radiology notes from the MIMIC-III dataset, which we are making publicly available. Our proposed approach significantly outperforms other approaches by achieving 97.1% accuracy.