 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient Adam-Type Algorithms for Distributed Data Mining
Oct 14, 2022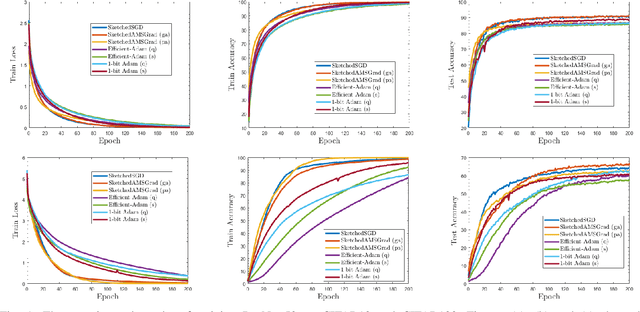
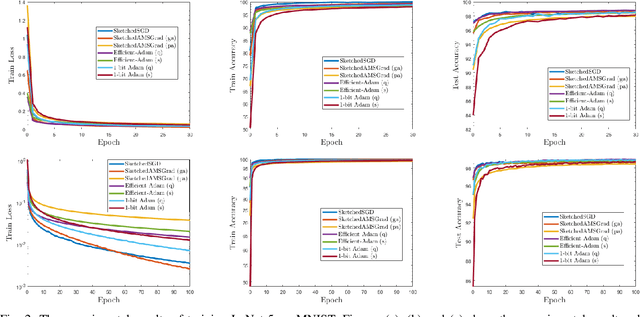

Distributed data mining is an emerging research topic to effectively and efficiently address hard data mining tasks using big data, which are partitioned and computed on different worker nodes, instead of one centralized server. Nevertheless, distributed learning methods often suffer from the communication bottleneck when the network bandwidth is limited or the size of model is large. To solve this critical issue, many gradient compression methods have been proposed recently to reduce the communication cost for multiple optimization algorithms. However, the current applications of gradient compression to adaptive gradient method, which is widely adopted because of its excellent performance to train DNNs, do not achieve the same ideal compression rate or convergence rate as Sketched-SGD. To address this limitation, in this paper, we propose a class of novel distributed Adam-type algorithms (\emph{i.e.}, SketchedAMSGrad) utilizing sketching, which is a promising compression technique that reduces the communication cost from $O(d)$ to $O(\log(d))$ where $d$ is the parameter dimension. In our theoretical analysis, we prove that our new algorithm achieves a fast convergence rate of $O(\frac{1}{\sqrt{nT}} + \frac{1}{(k/d)^2 T})$ with the communication cost of $O(k \log(d))$ at each iteration. Compared with single-machine AMSGrad, our algorithm can achieve the linear speedup with respect to the number of workers $n$. The experimental results on training various DNNs in distributed paradigm validate the efficiency of our algorithms.
Interpretations Steered Network Pruning via Amortized Inferred Saliency Maps
Sep 07, 2022
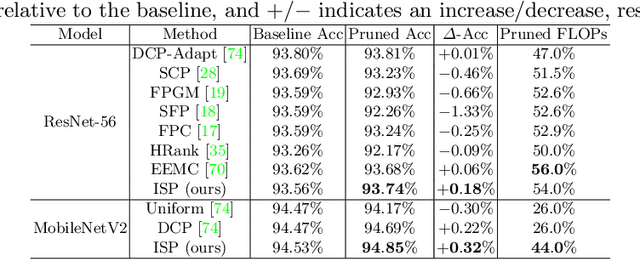
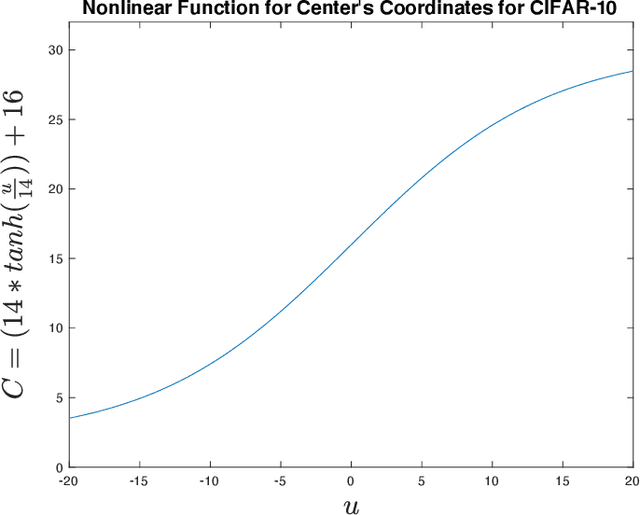
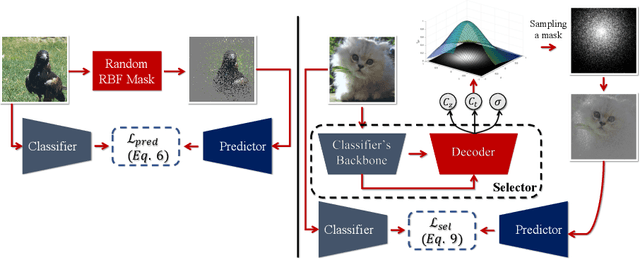
Convolutional Neural Networks (CNNs) compression is crucial to deploying these models in edge devices with limited resources. Existing channel pruning algorithms for CNNs have achieved plenty of success on complex models. They approach the pruning problem from various perspectives and use different metrics to guide the pruning process. However, these metrics mainly focus on the model's `outputs' or `weights' and neglect its `interpretations' information. To fill in this gap, we propose to address the channel pruning problem from a novel perspective by leveraging the interpretations of a model to steer the pruning process, thereby utilizing information from both inputs and outputs of the model. However, existing interpretation methods cannot get deployed to achieve our goal as either they are inefficient for pruning or may predict non-coherent explanations. We tackle this challenge by introducing a selector model that predicts real-time smooth saliency masks for pruned models. We parameterize the distribution of explanatory masks by Radial Basis Function (RBF)-like functions to incorporate geometric prior of natural images in our selector model's inductive bias. Thus, we can obtain compact representations of explanations to reduce the computational costs of our pruning method. We leverage our selector model to steer the network pruning by maximizing the similarity of explanatory representations for the pruned and original models. Extensive experiments on CIFAR-10 and ImageNet benchmark datasets demonstrate the efficacy of our proposed method. Our implementations are available at \url{https://github.com/Alii-Ganjj/InterpretationsSteeredPruning}
An Accelerated Doubly Stochastic Gradient Method with Faster Explicit Model Identification
Aug 11, 2022
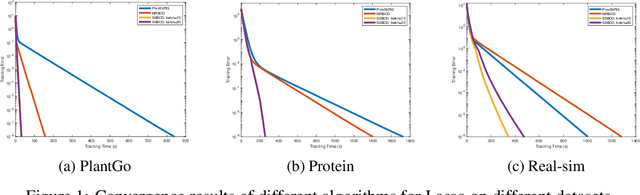
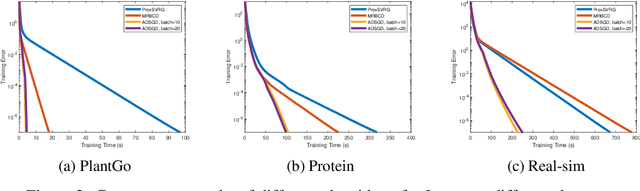
Sparsity regularized loss minimization problems play an important role in various fields including machine learning, data mining, and modern statistics. Proximal gradient descent method and coordinate descent method are the most popular approaches to solving the minimization problem. Although existing methods can achieve implicit model identification, aka support set identification, in a finite number of iterations, these methods still suffer from huge computational costs and memory burdens in high-dimensional scenarios. The reason is that the support set identification in these methods is implicit and thus cannot explicitly identify the low-complexity structure in practice, namely, they cannot discard useless coefficients of the associated features to achieve algorithmic acceleration via dimension reduction. To address this challenge, we propose a novel accelerated doubly stochastic gradient descent (ADSGD) method for sparsity regularized loss minimization problems, which can reduce the number of block iterations by eliminating inactive coefficients during the optimization process and eventually achieve faster explicit model identification and improve the algorithm efficiency. Theoretically, we first prove that ADSGD can achieve a linear convergence rate and lower overall computational complexity. More importantly, we prove that ADSGD can achieve a linear rate of explicit model identification. Numerically, experimental results on benchmark datasets confirm the efficiency of our proposed method.
Aesthetic Language Guidance Generation of Images Using Attribute Comparison
Aug 09, 2022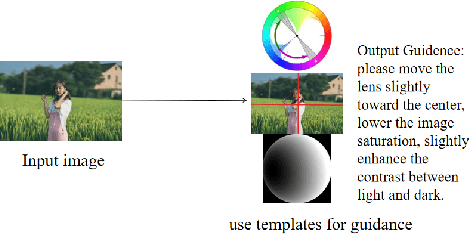

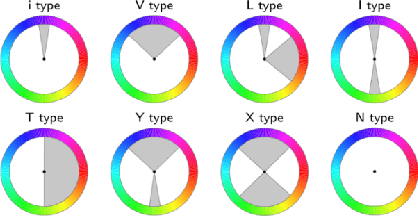
With the vigorous development of mobile photography technology, major mobile phone manufacturers are scrambling to improve the shooting ability of equipments and the photo beautification algorithm of software. However, the improvement of intelligent equipments and algorithms cannot replace human subjective photography technology. In this paper, we propose the aesthetic language guidance of image (ALG). We divide ALG into ALG-T and ALG-I according to whether the guiding rules are based on photography templates or guidance images. Whether it is ALG-T or ALG-I, we guide photography from three attributes of color, lighting and composition of the images. The differences of the three attributes between the input images and the photography templates or the guidance images are described in natural language, which is aesthetic natural language guidance (ALG). Also, because of the differences in lighting and composition between landscape images and portrait images, we divide the input images into landscape images and portrait images. Both ALG-T and ALG-I conduct aesthetic language guidance respectively for the two types of input images (landscape images and portrait images).
Aesthetic Attributes Assessment of Images with AMANv2 and DPC-CaptionsV2
Aug 09, 2022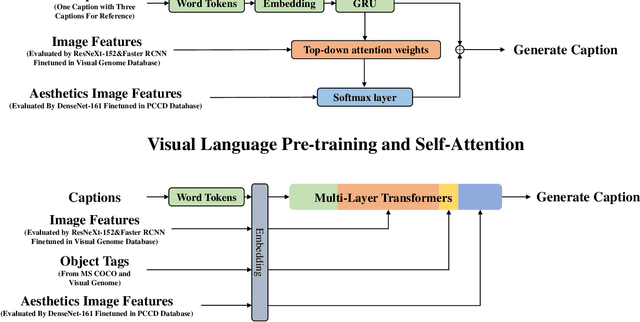

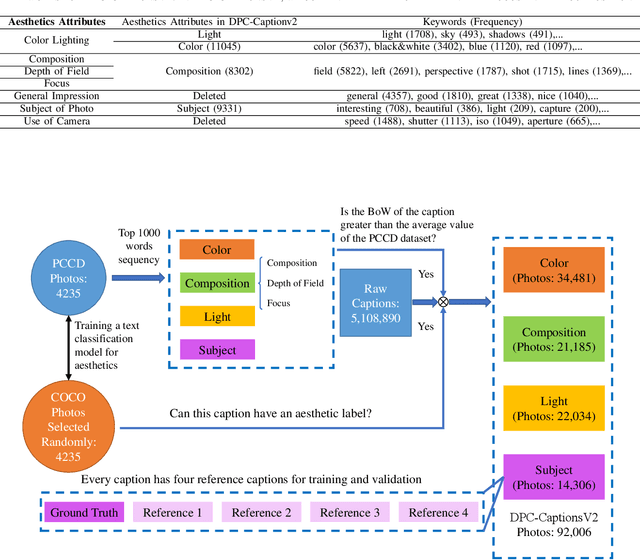

Image aesthetic quality assessment is popular during the last decade. Besides numerical assessment, nature language assessment (aesthetic captioning) has been proposed to describe the generally aesthetic impression of an image. In this paper, we propose aesthetic attribute assessment, which is the aesthetic attributes captioning, i.e., to assess the aesthetic attributes such as composition, lighting usage and color arrangement. It is a non-trivial task to label the comments of aesthetic attributes, which limit the scale of the corresponding datasets. We construct a novel dataset, named DPC-CaptionsV2, by a semi-automatic way. The knowledge is transferred from a small-scale dataset with full annotations to large-scale professional comments from a photography website. Images of DPC-CaptionsV2 contain comments up to 4 aesthetic attributes: composition, lighting, color, and subject. Then, we propose a new version of Aesthetic Multi-Attributes Networks (AMANv2) based on the BUTD model and the VLPSA model. AMANv2 fuses features of a mixture of small-scale PCCD dataset with full annotations and large-scale DPCCaptionsV2 dataset with full annotations. The experimental results of DPCCaptionsV2 show that our method can predict the comments on 4 aesthetic attributes, which are closer to aesthetic topics than those produced by the previous AMAN model. Through the evaluation criteria of image captioning, the specially designed AMANv2 model is better to the CNN-LSTM model and the AMAN model.
Contrastive Brain Network Learning via Hierarchical Signed Graph Pooling Model
Jul 14, 2022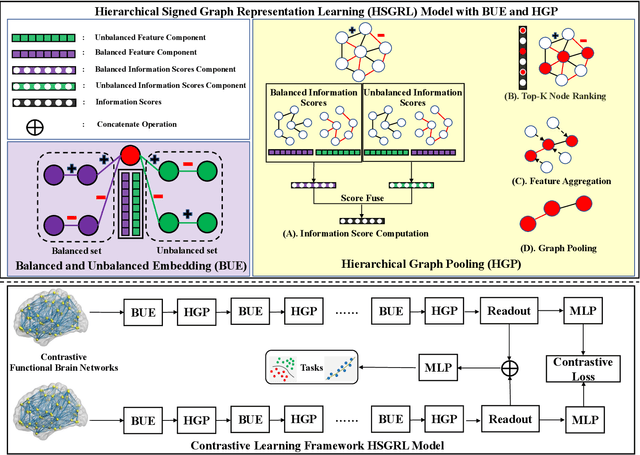
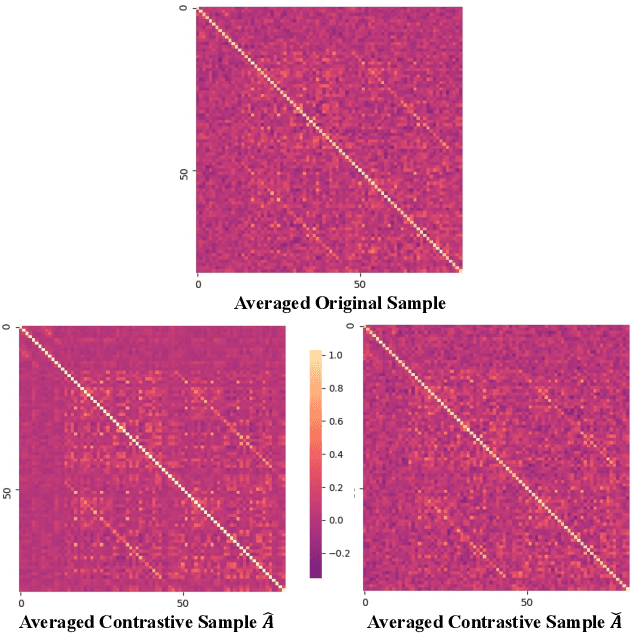
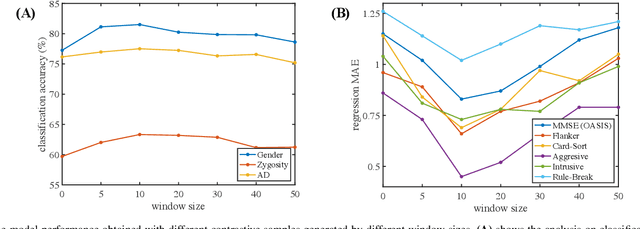
Recently brain networks have been widely adopted to study brain dynamics, brain development and brain diseases. Graph representation learning techniques on brain functional networks can facilitate the discovery of novel biomarkers for clinical phenotypes and neurodegenerative diseases. However, current graph learning techniques have several issues on brain network mining. Firstly, most current graph learning models are designed for unsigned graph, which hinders the analysis of many signed network data (e.g., brain functional networks). Meanwhile, the insufficiency of brain network data limits the model performance on clinical phenotypes predictions. Moreover, few of current graph learning model is interpretable, which may not be capable to provide biological insights for model outcomes. Here, we propose an interpretable hierarchical signed graph representation learning model to extract graph-level representations from brain functional networks, which can be used for different prediction tasks. In order to further improve the model performance, we also propose a new strategy to augment functional brain network data for contrastive learning. We evaluate this framework on different classification and regression tasks using the data from HCP and OASIS. Our results from extensive experiments demonstrate the superiority of the proposed model compared to several state-of-the-art techniques. Additionally, we use graph saliency maps, derived from these prediction tasks, to demonstrate detection and interpretation of phenotypic biomarkers.
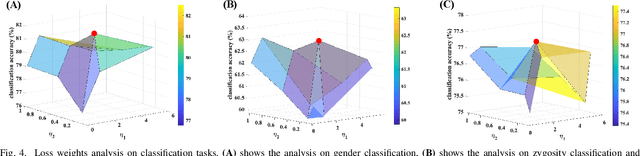
Balanced Self-Paced Learning for AUC Maximization
Jul 08, 2022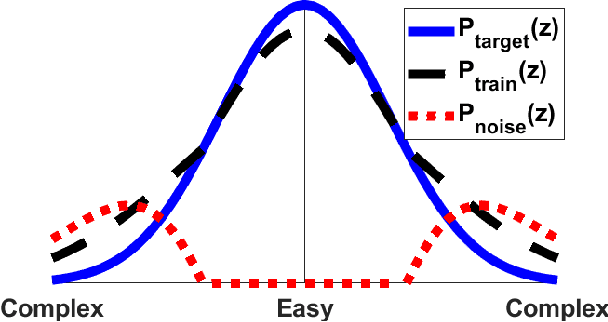
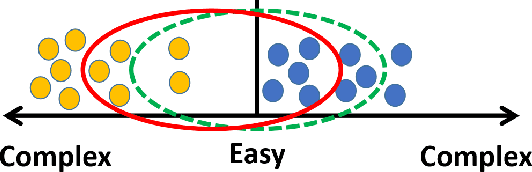
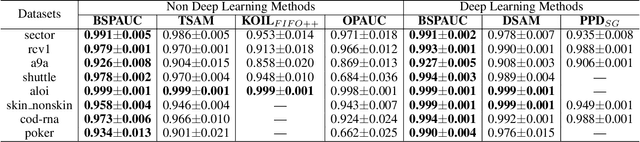
Learning to improve AUC performance is an important topic in machine learning. However, AUC maximization algorithms may decrease generalization performance due to the noisy data. Self-paced learning is an effective method for handling noisy data. However, existing self-paced learning methods are limited to pointwise learning, while AUC maximization is a pairwise learning problem. To solve this challenging problem, we innovatively propose a balanced self-paced AUC maximization algorithm (BSPAUC). Specifically, we first provide a statistical objective for self-paced AUC. Based on this, we propose our self-paced AUC maximization formulation, where a novel balanced self-paced regularization term is embedded to ensure that the selected positive and negative samples have proper proportions. Specially, the sub-problem with respect to all weight variables may be non-convex in our formulation, while the one is normally convex in existing self-paced problems. To address this, we propose a doubly cyclic block coordinate descent method. More importantly, we prove that the sub-problem with respect to all weight variables converges to a stationary point on the basis of closed-form solutions, and our BSPAUC converges to a stationary point of our fixed optimization objective under a mild assumption. Considering both the deep learning and kernel-based implementations, experimental results on several large-scale datasets demonstrate that our BSPAUC has a better generalization performance than existing state-of-the-art AUC maximization methods.
RetrievalGuard: Provably Robust 1-Nearest Neighbor Image Retrieval
Jun 17, 2022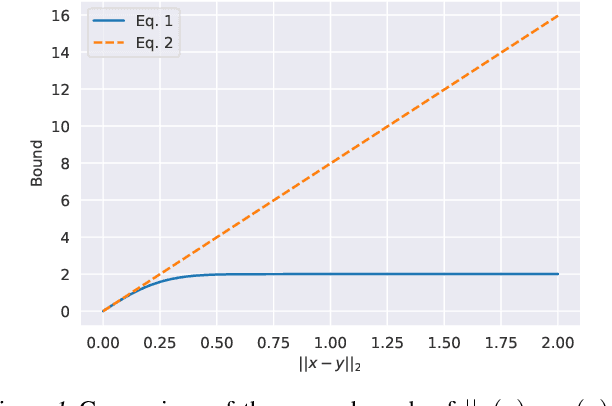
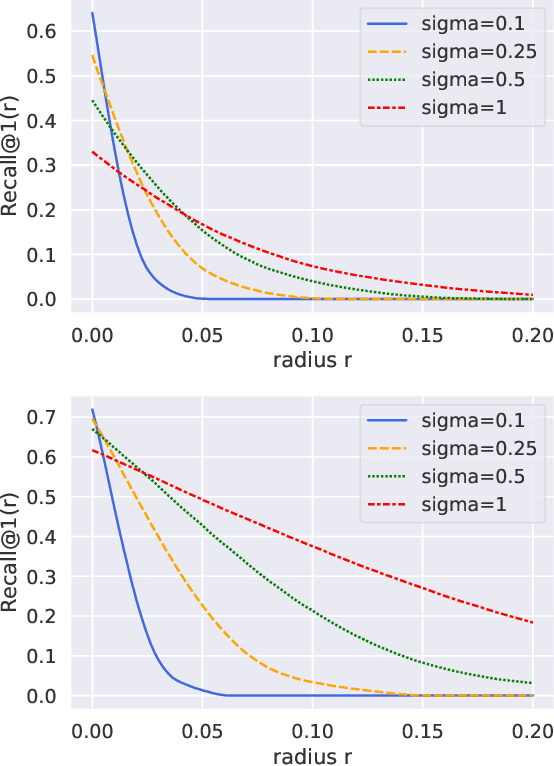
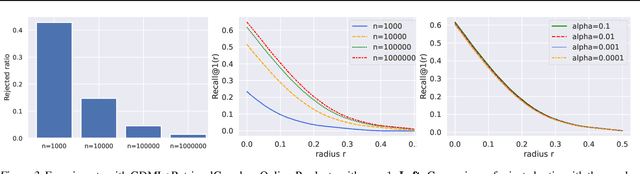
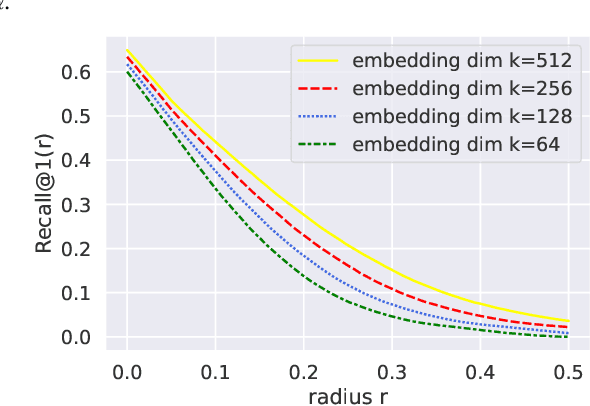
Recent research works have shown that image retrieval models are vulnerable to adversarial attacks, where slightly modified test inputs could lead to problematic retrieval results. In this paper, we aim to design a provably robust image retrieval model which keeps the most important evaluation metric Recall@1 invariant to adversarial perturbation. We propose the first 1-nearest neighbor (NN) image retrieval algorithm, RetrievalGuard, which is provably robust against adversarial perturbations within an $\ell_2$ ball of calculable radius. The challenge is to design a provably robust algorithm that takes into consideration the 1-NN search and the high-dimensional nature of the embedding space. Algorithmically, given a base retrieval model and a query sample, we build a smoothed retrieval model by carefully analyzing the 1-NN search procedure in the high-dimensional embedding space. We show that the smoothed retrieval model has bounded Lipschitz constant and thus the retrieval score is invariant to $\ell_2$ adversarial perturbations. Experiments on image retrieval tasks validate the robustness of our RetrievalGuard method.
Communication-Efficient Robust Federated Learning with Noisy Labels
Jun 11, 2022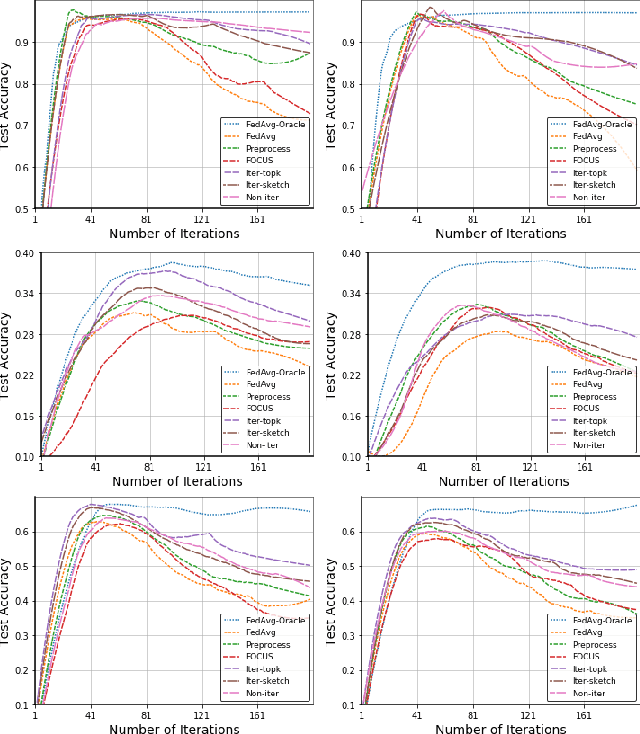
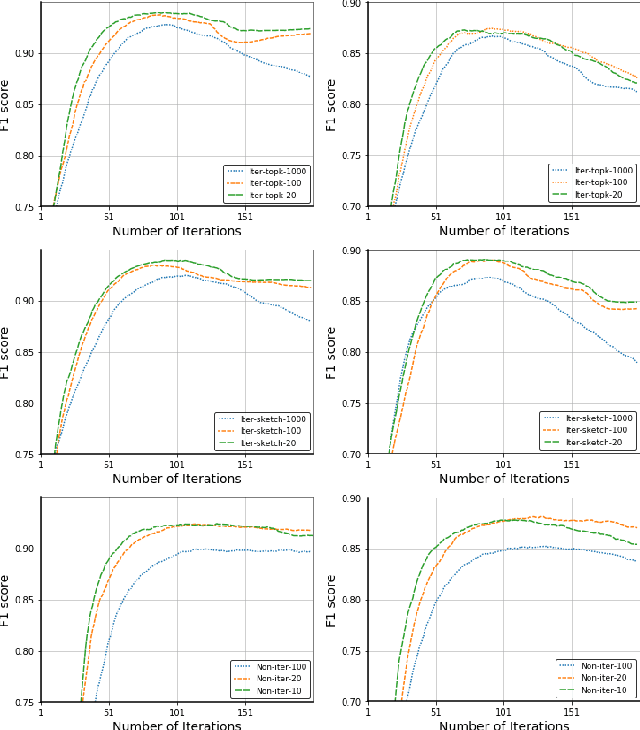
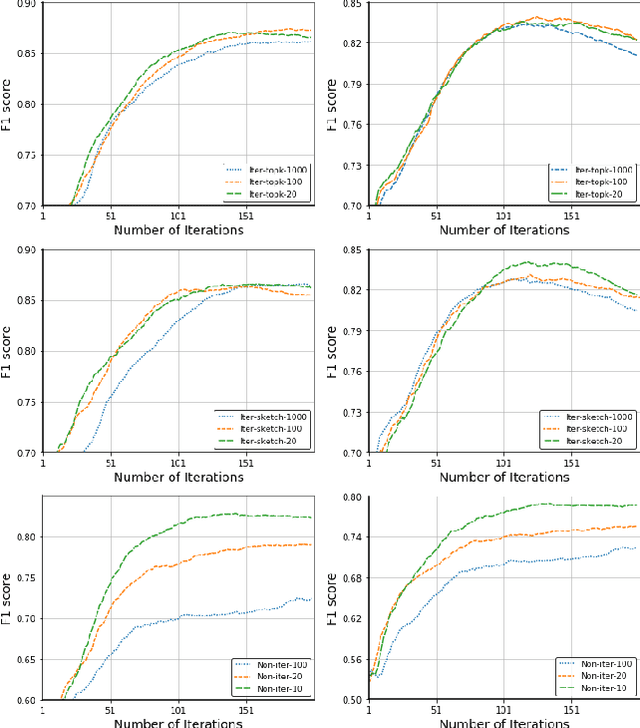
Federated learning (FL) is a promising privacy-preserving machine learning paradigm over distributed located data. In FL, the data is kept locally by each user. This protects the user privacy, but also makes the server difficult to verify data quality, especially if the data are correctly labeled. Training with corrupted labels is harmful to the federated learning task; however, little attention has been paid to FL in the case of label noise. In this paper, we focus on this problem and propose a learning-based reweighting approach to mitigate the effect of noisy labels in FL. More precisely, we tuned a weight for each training sample such that the learned model has optimal generalization performance over a validation set. More formally, the process can be formulated as a Federated Bilevel Optimization problem. Bilevel optimization problem is a type of optimization problem with two levels of entangled problems. The non-distributed bilevel problems have witnessed notable progress recently with new efficient algorithms. However, solving bilevel optimization problems under the Federated Learning setting is under-investigated. We identify that the high communication cost in hypergradient evaluation is the major bottleneck. So we propose \textit{Comm-FedBiO} to solve the general Federated Bilevel Optimization problems; more specifically, we propose two communication-efficient subroutines to estimate the hypergradient. Convergence analysis of the proposed algorithms is also provided. Finally, we apply the proposed algorithms to solve the noisy label problem. Our approach has shown superior performance on several real-world datasets compared to various baselines.
Functional2Structural: Cross-Modality Brain Networks Representation Learning
May 06, 2022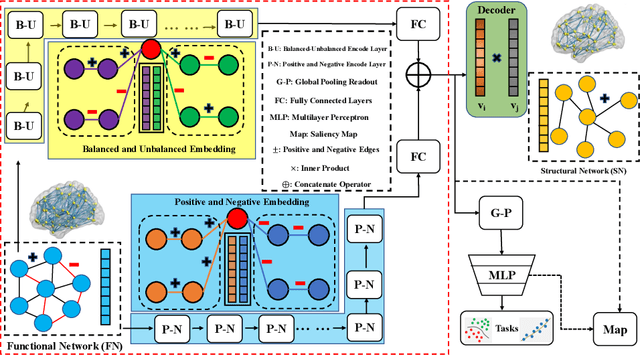
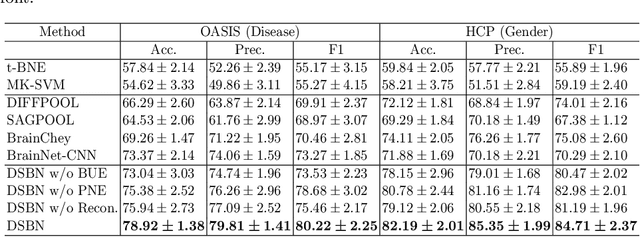
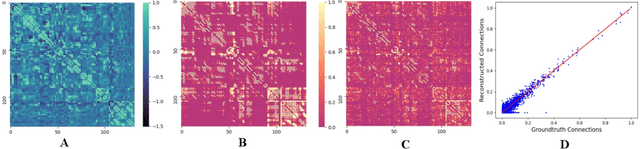
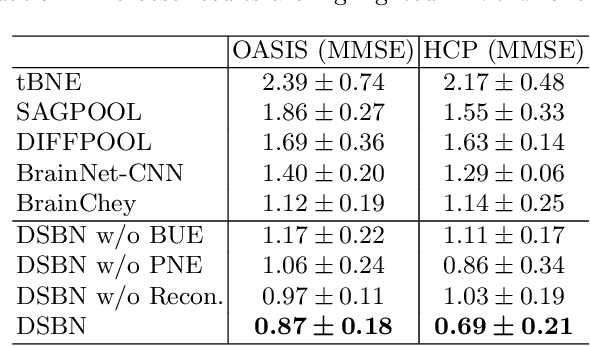
MRI-based modeling of brain networks has been widely used to understand functional and structural interactions and connections among brain regions, and factors that affect them, such as brain development and disease. Graph mining on brain networks may facilitate the discovery of novel biomarkers for clinical phenotypes and neurodegenerative diseases. Since brain networks derived from functional and structural MRI describe the brain topology from different perspectives, exploring a representation that combines these cross-modality brain networks is non-trivial. Most current studies aim to extract a fused representation of the two types of brain network by projecting the structural network to the functional counterpart. Since the functional network is dynamic and the structural network is static, mapping a static object to a dynamic object is suboptimal. However, mapping in the opposite direction is not feasible due to the non-negativity requirement of current graph learning techniques. Here, we propose a novel graph learning framework, known as Deep Signed Brain Networks (DSBN), with a signed graph encoder that, from an opposite perspective, learns the cross-modality representations by projecting the functional network to the structural counterpart. We validate our framework on clinical phenotype and neurodegenerative disease prediction tasks using two independent, publicly available datasets (HCP and OASIS). The experimental results clearly demonstrate the advantages of our model compared to several state-of-the-art methods.