 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Sampling Policy for Faster Derivative Free Optimization
Apr 09, 2021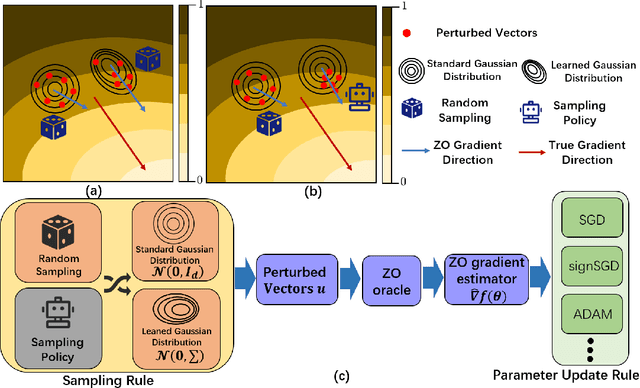
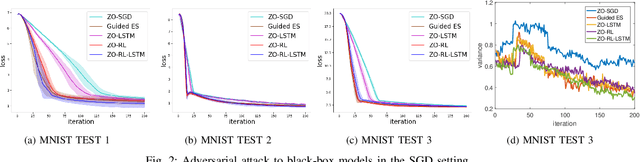
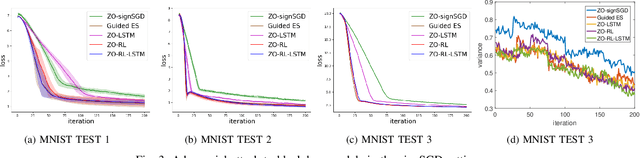
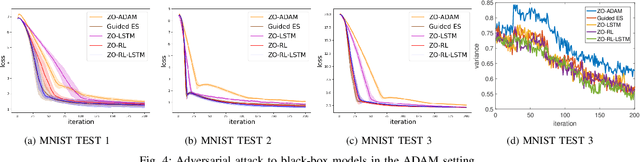
Zeroth-order (ZO, also known as derivative-free) methods, which estimate the gradient only by two function evaluations, have attracted much attention recently because of its broad applications in machine learning community. The two function evaluations are normally generated with random perturbations from standard Gaussian distribution. To speed up ZO methods, many methods, such as variance reduced stochastic ZO gradients and learning an adaptive Gaussian distribution, have recently been proposed to reduce the variances of ZO gradients. However, it is still an open problem whether there is a space to further improve the convergence of ZO methods. To explore this problem, in this paper, we propose a new reinforcement learning based ZO algorithm (ZO-RL) with learning the sampling policy for generating the perturbations in ZO optimization instead of using random sampling. To find the optimal policy, an actor-critic RL algorithm called deep deterministic policy gradient (DDPG) with two neural network function approximators is adopted. The learned sampling policy guides the perturbed points in the parameter space to estimate a more accurate ZO gradient. To the best of our knowledge, our ZO-RL is the first algorithm to learn the sampling policy using reinforcement learning for ZO optimization which is parallel to the existing methods. Especially, our ZO-RL can be combined with existing ZO algorithms that could further accelerate the algorithms. Experimental results for different ZO optimization problems show that our ZO-RL algorithm can effectively reduce the variances of ZO gradient by learning a sampling policy, and converge faster than existing ZO algorithms in different scenarios.
Safe Sample Screening for Robust Support Vector Machine
Dec 24, 2019
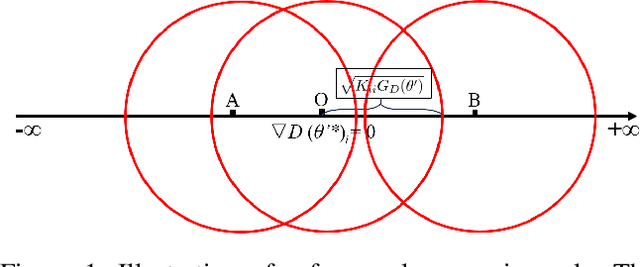
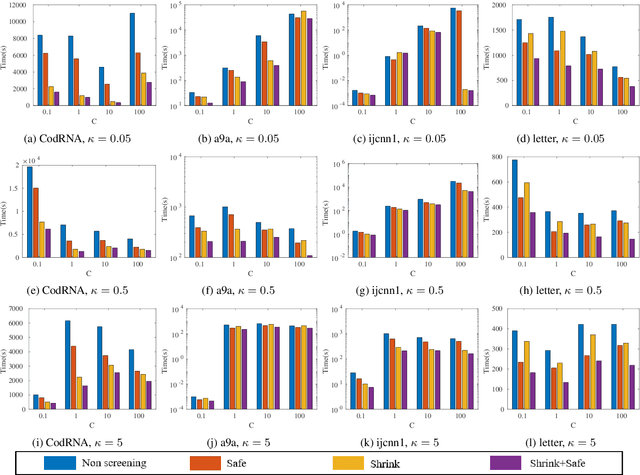
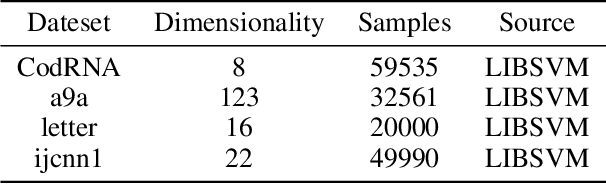
Robust support vector machine (RSVM) has been shown to perform remarkably well to improve the generalization performance of support vector machine under the noisy environment. Unfortunately, in order to handle the non-convexity induced by ramp loss in RSVM, existing RSVM solvers often adopt the DC programming framework which is computationally inefficient for running multiple outer loops. This hinders the application of RSVM to large-scale problems. Safe sample screening that allows for the exclusion of training samples prior to or early in the training process is an effective method to greatly reduce computational time. However, existing safe sample screening algorithms are limited to convex optimization problems while RSVM is a non-convex problem. To address this challenge, in this paper, we propose two safe sample screening rules for RSVM based on the framework of concave-convex procedure (CCCP). Specifically, we provide screening rule for the inner solver of CCCP and another rule for propagating screened samples between two successive solvers of CCCP. To the best of our knowledge, this is the first work of safe sample screening to a non-convex optimization problem. More importantly, we provide the security guarantee to our sample screening rules to RSVM. Experimental results on a variety of benchmark datasets verify that our safe sample screening rules can significantly reduce the computational time.