 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Understanding of Scientific Experiments with End to End Symbolic Regression
Dec 07, 2021
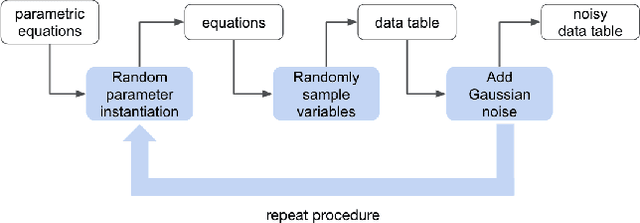
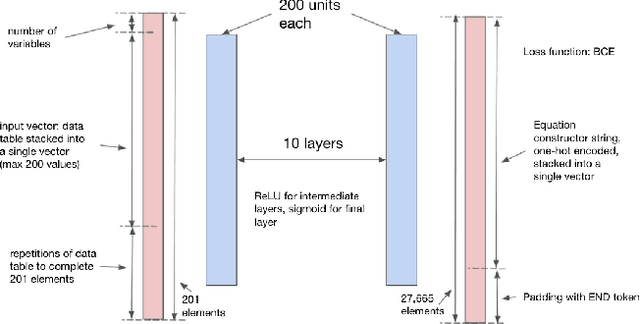
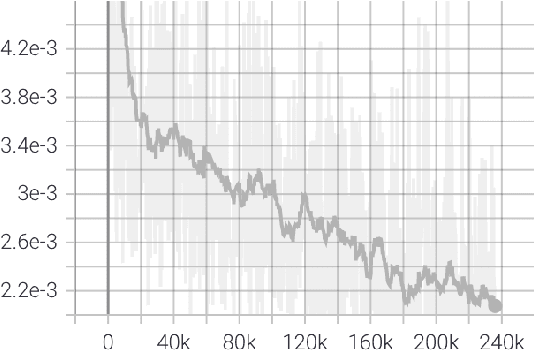
We consider the problem of learning free-form symbolic expressions from raw data, such as that produced by an experiment in any scientific domain. Accurate and interpretable models of scientific phenomena are the cornerstone of scientific research. Simple yet interpretable models, such as linear or logistic regression and decision trees often lack predictive accuracy. Alternatively, accurate blackbox models such as deep neural networks provide high predictive accuracy, but do not readily admit human understanding in a way that would enrich the scientific theory of the phenomenon. Many great breakthroughs in science revolve around the development of parsimonious equational models with high predictive accuracy, such as Newton's laws, universal gravitation, and Maxwell's equations. Previous work on automating the search of equational models from data combine domain-specific heuristics as well as computationally expensive techniques, such as genetic programming and Monte-Carlo search. We develop a deep neural network (MACSYMA) to address the symbolic regression problem as an end-to-end supervised learning problem. MACSYMA can generate symbolic expressions that describe a dataset. The computational complexity of the task is reduced to the feedforward computation of a neural network. We train our neural network on a synthetic dataset consisting of data tables of varying length and varying levels of noise, for which the neural network must learn to produce the correct symbolic expression token by token. Finally, we validate our technique by running on a public dataset from behavioral science.
PSI: A Pedestrian Behavior Dataset for Socially Intelligent Autonomous Car
Dec 05, 2021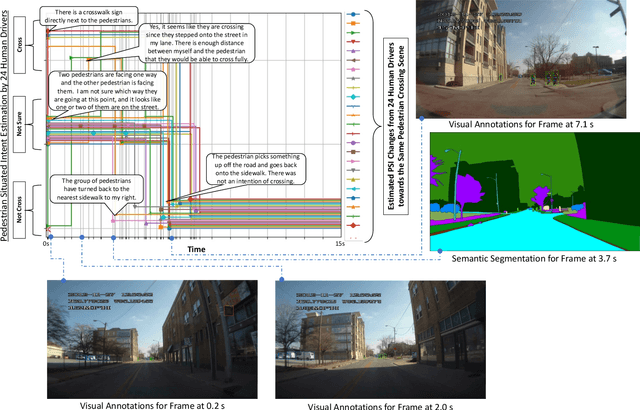
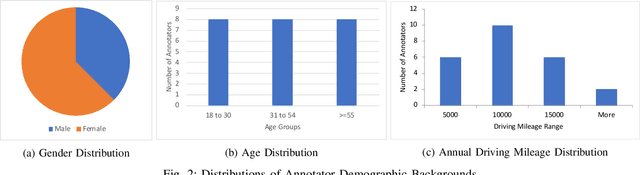


Prediction of pedestrian behavior is critical for fully autonomous vehicles to drive in busy city streets safely and efficiently. The future autonomous cars need to fit into mixed conditions with not only technical but also social capabilities. As more algorithms and datasets have been developed to predict pedestrian behaviors, these efforts lack the benchmark labels and the capability to estimate the temporal-dynamic intent changes of the pedestrians, provide explanations of the interaction scenes, and support algorithms with social intelligence. This paper proposes and shares another benchmark dataset called the IUPUI-CSRC Pedestrian Situated Intent (PSI) data with two innovative labels besides comprehensive computer vision labels. The first novel label is the dynamic intent changes for the pedestrians to cross in front of the ego-vehicle, achieved from 24 drivers with diverse backgrounds. The second one is the text-based explanations of the driver reasoning process when estimating pedestrian intents and predicting their behaviors during the interaction period. These innovative labels can enable several computer vision tasks, including pedestrian intent/behavior prediction, vehicle-pedestrian interaction segmentation, and video-to-language mapping for explainable algorithms. The released dataset can fundamentally improve the development of pedestrian behavior prediction models and develop socially intelligent autonomous cars to interact with pedestrians efficiently. The dataset has been evaluated with different tasks and is released to the public to access.
Dynamics of Pedestrian Crossing Decisions Based on Vehicle Trajectories in Large-Scale Simulated and Real-World Data
Apr 08, 2019

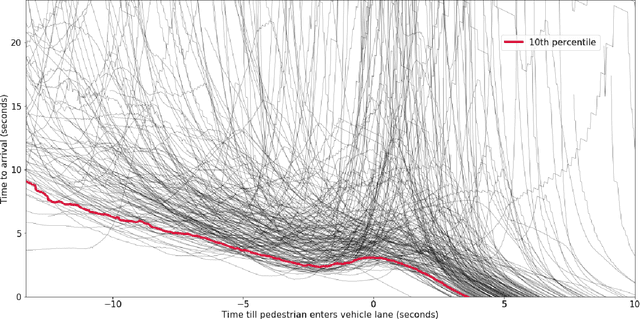
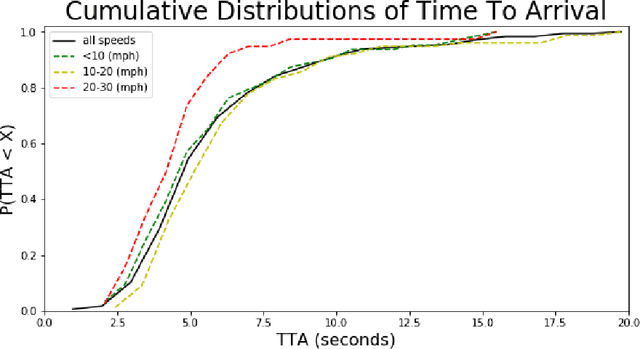
Humans, as both pedestrians and drivers, generally skillfully navigate traffic intersections. Despite the uncertainty, danger, and the non-verbal nature of communication commonly found in these interactions, there are surprisingly few collisions considering the total number of interactions. As the role of automation technology in vehicles grows, it becomes increasingly critical to understand the relationship between pedestrian and driver behavior: how pedestrians perceive the actions of a vehicle/driver and how pedestrians make crossing decisions. The relationship between time-to-arrival (TTA) and pedestrian gap acceptance (i.e., whether a pedestrian chooses to cross under a given window of time to cross) has been extensively investigated. However, the dynamic nature of vehicle trajectories in the context of non-verbal communication has not been systematically explored. Our work provides evidence that trajectory dynamics, such as changes in TTA, can be powerful signals in the non-verbal communication between drivers and pedestrians. Moreover, we investigate these effects in both simulated and real-world datasets, both larger than have previously been considered in literature to the best of our knowledge.
What Can Be Predicted from Six Seconds of Driver Glances?
Nov 26, 2016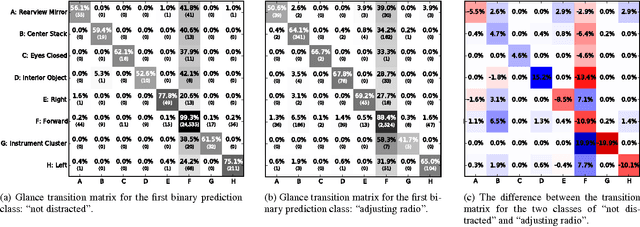
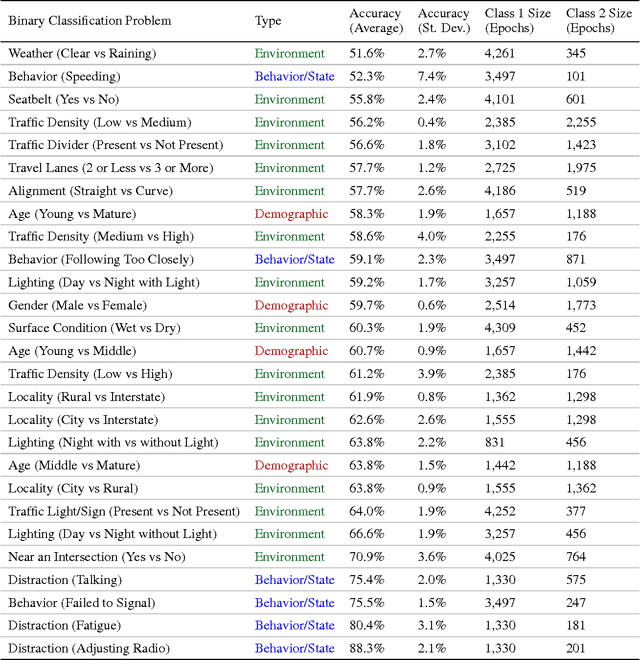

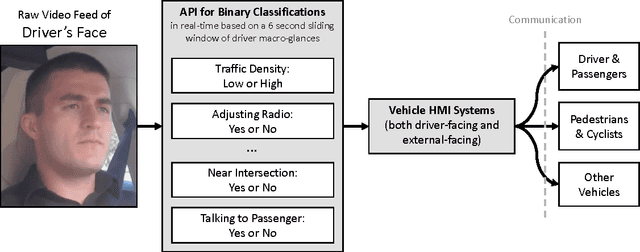
We consider a large dataset of real-world, on-road driving from a 100-car naturalistic study to explore the predictive power of driver glances and, specifically, to answer the following question: what can be predicted about the state of the driver and the state of the driving environment from a 6-second sequence of macro-glances? The context-based nature of such glances allows for application of supervised learning to the problem of vision-based gaze estimation, making it robust, accurate, and reliable in messy, real-world conditions. So, it's valuable to ask whether such macro-glances can be used to infer behavioral, environmental, and demographic variables? We analyze 27 binary classification problems based on these variables. The takeaway is that glance can be used as part of a multi-sensor real-time system to predict radio-tuning, fatigue state, failure to signal, talking, and several environment variables.