 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIT Autonomous Vehicle Technology Study: Large-Scale Deep Learning Based Analysis of Driver Behavior and Interaction with Automation
Sep 30, 2018
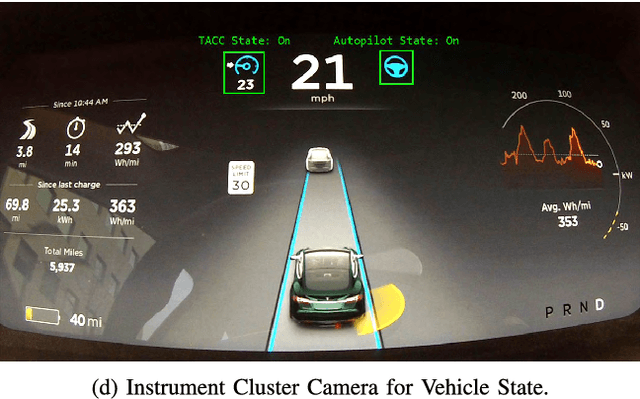
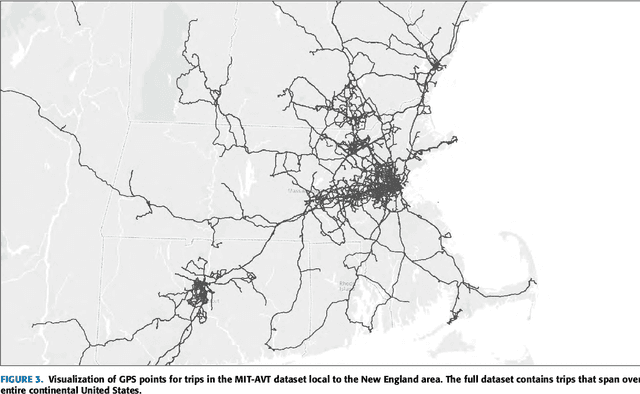
For the foreseeble future, human beings will likely remain an integral part of the driving task, monitoring the AI system as it performs anywhere from just over 0% to just under 100% of the driving. The governing objectives of the MIT Autonomous Vehicle Technology (MIT-AVT) study are to (1) undertake large-scale real-world driving data collection that includes high-definition video to fuel the development of deep learning based internal and external perception systems, (2) gain a holistic understanding of how human beings interact with vehicle automation technology by integrating video data with vehicle state data, driver characteristics, mental models, and self-reported experiences with technology, and (3) identify how technology and other factors related to automation adoption and use can be improved in ways that save lives. In pursuing these objectives, we have instrumented 21 Tesla Model S and Model X vehicles, 2 Volvo S90 vehicles, 2 Range Rover Evoque, and 2 Cadillac CT6 vehicles for both long-term (over a year per driver) and medium term (one month per driver) naturalistic driving data collection. Furthermore, we are continually developing new methods for analysis of the massive-scale dataset collected from the instrumented vehicle fleet. The recorded data streams include IMU, GPS, CAN messages, and high-definition video streams of the driver face, the driver cabin, the forward roadway, and the instrument cluster (on select vehicles). The study is on-going and growing. To date, we have 99 participants, 11,846 days of participation, 405,807 miles, and 5.5 billion video frames. This paper presents the design of the study, the data collection hardware, the processing of the data, and the computer vision algorithms currently being used to extract actionable knowledge from the data.
What Can Be Predicted from Six Seconds of Driver Glances?
Nov 26, 2016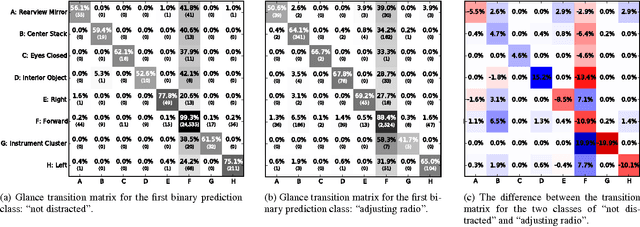
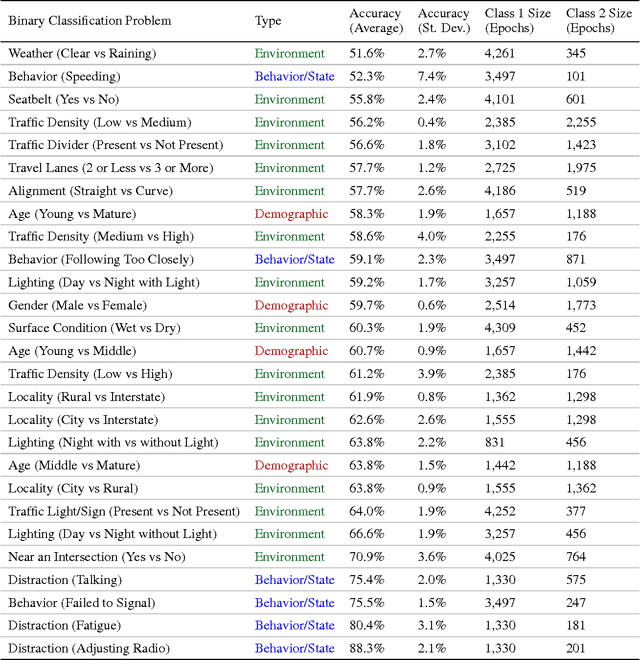

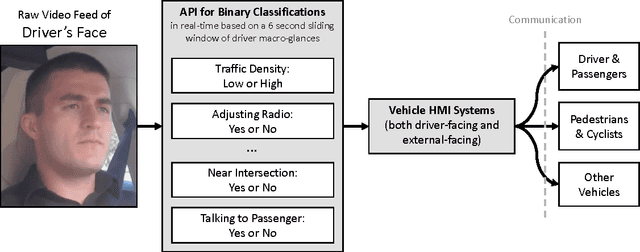
We consider a large dataset of real-world, on-road driving from a 100-car naturalistic study to explore the predictive power of driver glances and, specifically, to answer the following question: what can be predicted about the state of the driver and the state of the driving environment from a 6-second sequence of macro-glances? The context-based nature of such glances allows for application of supervised learning to the problem of vision-based gaze estimation, making it robust, accurate, and reliable in messy, real-world conditions. So, it's valuable to ask whether such macro-glances can be used to infer behavioral, environmental, and demographic variables? We analyze 27 binary classification problems based on these variables. The takeaway is that glance can be used as part of a multi-sensor real-time system to predict radio-tuning, fatigue state, failure to signal, talking, and several environment variables.