 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLERA: A Unified Model for Joint Cognitive Load and Eye Region Analysis in the Wild
Jun 26, 2023



Non-intrusive, real-time analysis of the dynamics of the eye region allows us to monitor humans' visual attention allocation and estimate their mental state during the performance of real-world tasks, which can potentially benefit a wide range of human-computer interaction (HCI) applications. While commercial eye-tracking devices have been frequently employed, the difficulty of customizing these devices places unnecessary constraints on the exploration of more efficient, end-to-end models of eye dynamics. In this work, we propose CLERA, a unified model for Cognitive Load and Eye Region Analysis, which achieves precise keypoint detection and spatiotemporal tracking in a joint-learning framework. Our method demonstrates significant efficiency and outperforms prior work on tasks including cognitive load estimation, eye landmark detection, and blink estimation. We also introduce a large-scale dataset of 30k human faces with joint pupil, eye-openness, and landmark annotation, which aims to support future HCI research on human factors and eye-related analysis.
Dynamics of Pedestrian Crossing Decisions Based on Vehicle Trajectories in Large-Scale Simulated and Real-World Data
Apr 08, 2019

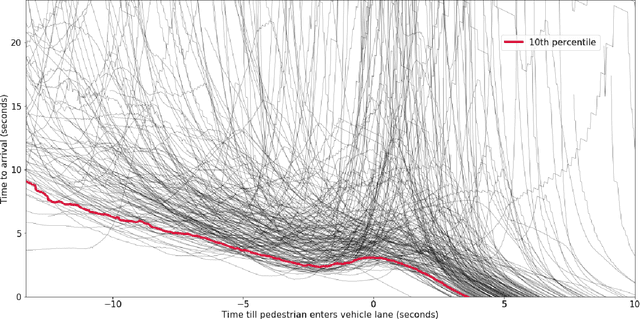
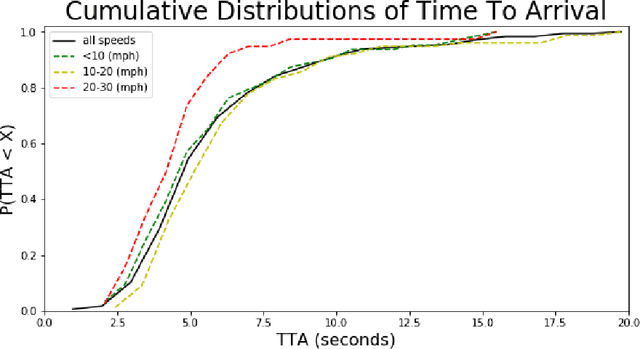
Humans, as both pedestrians and drivers, generally skillfully navigate traffic intersections. Despite the uncertainty, danger, and the non-verbal nature of communication commonly found in these interactions, there are surprisingly few collisions considering the total number of interactions. As the role of automation technology in vehicles grows, it becomes increasingly critical to understand the relationship between pedestrian and driver behavior: how pedestrians perceive the actions of a vehicle/driver and how pedestrians make crossing decisions. The relationship between time-to-arrival (TTA) and pedestrian gap acceptance (i.e., whether a pedestrian chooses to cross under a given window of time to cross) has been extensively investigated. However, the dynamic nature of vehicle trajectories in the context of non-verbal communication has not been systematically explored. Our work provides evidence that trajectory dynamics, such as changes in TTA, can be powerful signals in the non-verbal communication between drivers and pedestrians. Moreover, we investigate these effects in both simulated and real-world datasets, both larger than have previously been considered in literature to the best of our knowledge.
MIT Autonomous Vehicle Technology Study: Large-Scale Deep Learning Based Analysis of Driver Behavior and Interaction with Automation
Sep 30, 2018
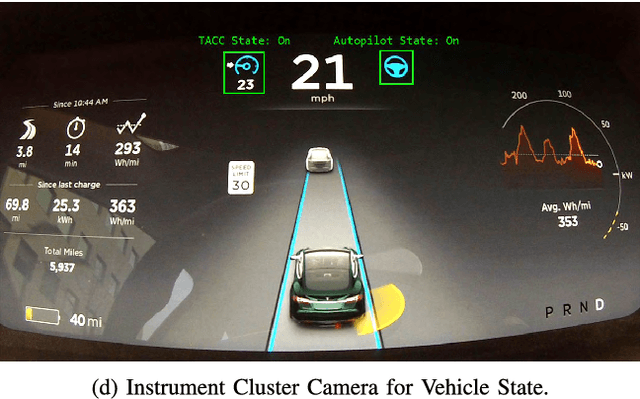
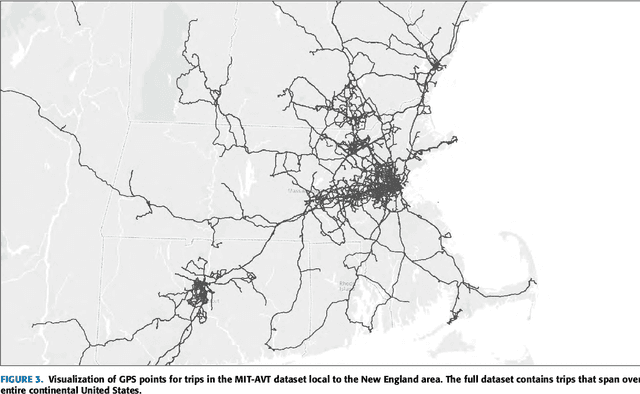
For the foreseeble future, human beings will likely remain an integral part of the driving task, monitoring the AI system as it performs anywhere from just over 0% to just under 100% of the driving. The governing objectives of the MIT Autonomous Vehicle Technology (MIT-AVT) study are to (1) undertake large-scale real-world driving data collection that includes high-definition video to fuel the development of deep learning based internal and external perception systems, (2) gain a holistic understanding of how human beings interact with vehicle automation technology by integrating video data with vehicle state data, driver characteristics, mental models, and self-reported experiences with technology, and (3) identify how technology and other factors related to automation adoption and use can be improved in ways that save lives. In pursuing these objectives, we have instrumented 21 Tesla Model S and Model X vehicles, 2 Volvo S90 vehicles, 2 Range Rover Evoque, and 2 Cadillac CT6 vehicles for both long-term (over a year per driver) and medium term (one month per driver) naturalistic driving data collection. Furthermore, we are continually developing new methods for analysis of the massive-scale dataset collected from the instrumented vehicle fleet. The recorded data streams include IMU, GPS, CAN messages, and high-definition video streams of the driver face, the driver cabin, the forward roadway, and the instrument cluster (on select vehicles). The study is on-going and growing. To date, we have 99 participants, 11,846 days of participation, 405,807 miles, and 5.5 billion video frames. This paper presents the design of the study, the data collection hardware, the processing of the data, and the computer vision algorithms currently being used to extract actionable knowledge from the data.
What Can Be Predicted from Six Seconds of Driver Glances?
Nov 26, 2016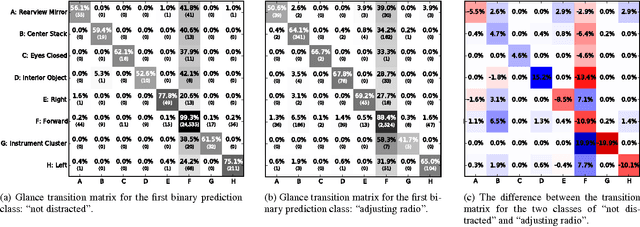
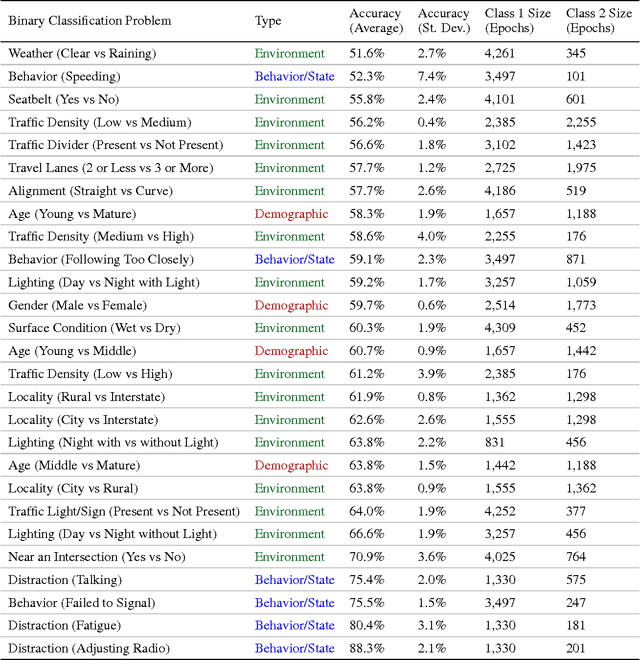

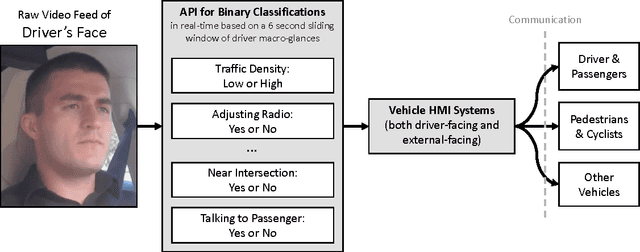
We consider a large dataset of real-world, on-road driving from a 100-car naturalistic study to explore the predictive power of driver glances and, specifically, to answer the following question: what can be predicted about the state of the driver and the state of the driving environment from a 6-second sequence of macro-glances? The context-based nature of such glances allows for application of supervised learning to the problem of vision-based gaze estimation, making it robust, accurate, and reliable in messy, real-world conditions. So, it's valuable to ask whether such macro-glances can be used to infer behavioral, environmental, and demographic variables? We analyze 27 binary classification problems based on these variables. The takeaway is that glance can be used as part of a multi-sensor real-time system to predict radio-tuning, fatigue state, failure to signal, talking, and several environment variables.