 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToMPC: Task-oriented Model Predictive Control via ADMM for Safe Robotic Manipulation
Mar 14, 2026This paper proposes a task-oriented model predictive control (ToMPC) framework for safe and efficient robotic manipulation in open workspaces. The framework unifies collision-free motion and robot-environment interaction to address diverse scenarios. Additionally, it introduces task-oriented obstacle avoidance that leverages kinematic redundancy to enhance manipulation efficiency in obstructed environments. This complex optimization problem is solved by the alternating direction method of multipliers (ADMM), which decomposes the problem into two subproblems tackled by differential dynamic programming (DDP) and quadratic programming (QP), respectively. The effectiveness of this approach is validated in simulation and hardware experiments on a Franka Panda robotic manipulator. Results demonstrate that the framework can plan motion and/or force trajectories in real time, maximize the manipulation range while avoiding obstacles, and strictly adhere to safety-related hard constraints.
Computer Vision-based Adaptive Control for Back Exoskeleton Performance Optimization
Aug 08, 2025Back exoskeletons can reduce musculoskeletal strain, but their effectiveness depends on support modulation and adaptive control. This study addresses two challenges: defining optimal support strategies and developing adaptive control based on payload estimation. We introduce an optimization space based on muscle activity reduction, perceived discomfort, and user preference, constructing functions to identify optimal strategies. Experiments with 12 subjects revealed optimal operating regions, highlighting the need for dynamic modulation. Based on these insights, we developed a vision-based adaptive control pipeline that estimates payloads in real-time by enhancing exoskeleton contextual understanding, minimising latency and enabling support adaptation within the defined optimisation space. Validation with 12 more subjects showed over 80% accuracy and improvements across all metrics. Compared to static control, adaptive modulation reduced peak back muscle activation by up to 23% while preserving user preference and minimising discomfort. These findings validate the proposed framework and highlight the potential of intelligent, context-aware control in industrial exoskeletons.
YOLO-CCA: A Context-Based Approach for Traffic Sign Detection
Dec 05, 2024Traffic sign detection is crucial for improving road safety and advancing autonomous driving technologies. Due to the complexity of driving environments, traffic sign detection frequently encounters a range of challenges, including low resolution, limited feature information, and small object sizes. These challenges significantly hinder the effective extraction of features from traffic signs, resulting in false positives and false negatives in object detection. To address these challenges, it is essential to explore more efficient and accurate approaches for traffic sign detection. This paper proposes a context-based algorithm for traffic sign detection, which utilizes YOLOv7 as the baseline model. Firstly, we propose an adaptive local context feature enhancement (LCFE) module using multi-scale dilation convolution to capture potential relationships between the object and surrounding areas. This module supplements the network with additional local context information. Secondly, we propose a global context feature collection (GCFC) module to extract key location features from the entire image scene as global context information. Finally, we build a Transformer-based context collection augmentation (CCA) module to process the collected local context and global context, which achieves superior multi-level feature fusion results for YOLOv7 without bringing in additional complexity. Extensive experimental studies performed on the Tsinghua-Tencent 100K dataset show that the mAP of our method is 92.1\%. Compared with YOLOv7, our approach improves 3.9\% in mAP, while the amount of parameters is reduced by 2.7M. On the CCTSDB2021 dataset the mAP is improved by 0.9\%. These results show that our approach achieves higher detection accuracy with fewer parameters. The source code is available at \url{https://github.com/zippiest/yolo-cca}.
Multi-Layered Safety of Redundant Robot Manipulators via Task-Oriented Planning and Control
Oct 23, 2024Ensuring safety is crucial to promote the application of robot manipulators in open workspace. Factors such as sensor errors or unpredictable collisions make the environment full of uncertainties. In this work, we investigate these potential safety challenges on redundant robot manipulators, and propose a task-oriented planning and control framework to achieve multi-layered safety while maintaining efficient task execution. Our approach consists of two main parts: a task-oriented trajectory planner based on multiple-shooting model predictive control method, and a torque controller that allows safe and efficient collision reaction using only proprioceptive data. Through extensive simulations and real-hardware experiments, we demonstrate that the proposed framework can effectively handle uncertain static or dynamic obstacles, and perform disturbance resistance in manipulation tasks when unforeseen contacts occur. All code will be open-sourced to benefit the community.
Beyond Gait: Learning Knee Angle for Seamless Prosthesis Control in Multiple Scenarios
Apr 10, 2024



Deep learning models have become a powerful tool in knee angle estimation for lower limb prostheses, owing to their adaptability across various gait phases and locomotion modes. Current methods utilize Multi-Layer Perceptrons (MLP), Long-Short Term Memory Networks (LSTM), and Convolutional Neural Networks (CNN), predominantly analyzing motion information from the thigh. Contrary to these approaches, our study introduces a holistic perspective by integrating whole-body movements as inputs. We propose a transformer-based probabilistic framework, termed the Angle Estimation Probabilistic Model (AEPM), that offers precise angle estimations across extensive scenarios beyond walking. AEPM achieves an overall RMSE of 6.70 degrees, with an RMSE of 3.45 degrees in walking scenarios. Compared to the state of the art, AEPM has improved the prediction accuracy for walking by 11.31%. Our method can achieve seamless adaptation between different locomotion modes. Also, this model can be utilized to analyze the synergy between the knee and other joints. We reveal that the whole body movement has valuable information for knee movement, which can provide insights into designing sensors for prostheses. The code is available at https://github.com/penway/Beyond-Gait-AEPM.
Learning Task-adaptive Quasi-stiffness Control for A Powered Transfemoral Prosthesis
Nov 25, 2023While significant advancements have been made in the mechanical and task-specific controller designs of powered transfemoral prostheses, developing a task-adaptive control framework that generalizes across various locomotion modes and terrain conditions remains an open problem. This study proposes a task-adaptive learning quasi-stiffness control framework for powered prostheses that generalizes across tasks, including the torque-angle relationship reconstruction part and the quasi-stiffness controller design part. Quasi-stiffness is defined as the slope of the human joint's torque-angle relationship. To accurately obtain the torque-angle relationship in a new task, a Gaussian Process Regression (GPR) model is introduced to predict the target features of the human joint's angle and torque in the task. Then a Kernelized Movement Primitives (KMP) is employed to reconstruct the torque-angle relationship of a new task from multiple human demonstrations and estimated target features. Based on the torque-angle relationship of the new task, a quasi-stiffness control approach is designed for a powered prosthesis. Finally, the proposed framework is validated through practical examples, including varying speed and incline walking tasks. The proposed framework has the potential to expand to variable walking tasks in daily life for the transfemoral amputees.
TeachingBot: Robot Teacher for Human Handwriting
Sep 21, 2023Teaching physical skills to humans requires one-on-one interaction between the teacher and the learner. With a shortage of human teachers, such a teaching mode faces the challenge of scaling up. Robots, with their replicable nature and physical capabilities, offer a solution. In this work, we present TeachingBot, a robotic system designed for teaching handwriting to human learners. We tackle two primary challenges in this teaching task: the adaptation to each learner's unique style and the creation of an engaging learning experience. TeachingBot captures the learner's style using a probabilistic learning approach based on the learner's handwriting. Then, based on the learned style, it provides physical guidance to human learners with variable impedance to make the learning experience engaging. Results from human-subject experiments based on 15 human subjects support the effectiveness of TeachingBot, demonstrating improved human learning outcomes compared to baseline methods. Additionally, we illustrate how TeachingBot customizes its teaching approach for individual learners, leading to enhanced overall engagement and effectiveness.
Motion Control based on Disturbance Estimation and Time-Varying Gain for Robotic Manipulators
Jun 05, 2023



To achieve high-accuracy manipulation in the presence of unknown dynamics and external disturbance, we propose an efficient and robust motion controller (named TvUDE) for robotic manipulators. The controller incorporates a disturbance estimation mechanism that utilizes reformulated robot dynamics and filtering operations to obtain uncertainty and disturbance without requiring measurement of acceleration. Furthermore, we design a time-varying control input gain to enhance the control system's robustness. Finally, we analyze the boundness of the control signal and the stability of the closed-loop system, and conduct a set of experiments on a six-DOF robotic manipulator. The experimental results verify the effectiveness of TvUDE in handling internal uncertainty and external static or transient disturbance.
Design, Modelling, and Control of a Reconfigurable Rotary Series Elastic Actuator with Nonlinear Stiffness for Assistive Robots
May 28, 2022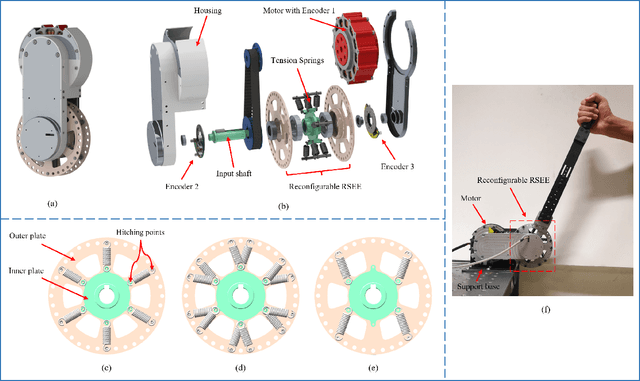
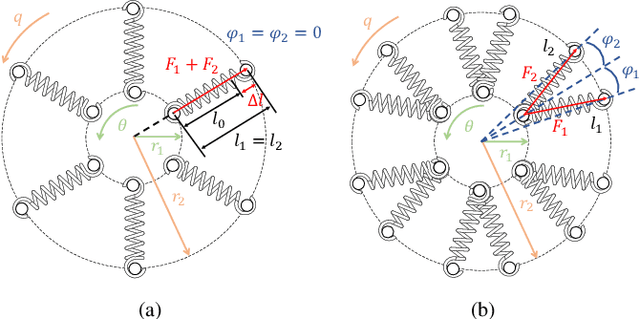
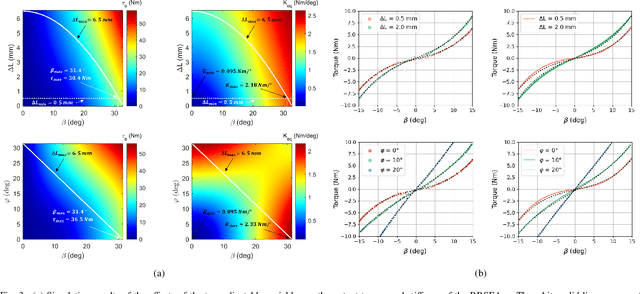
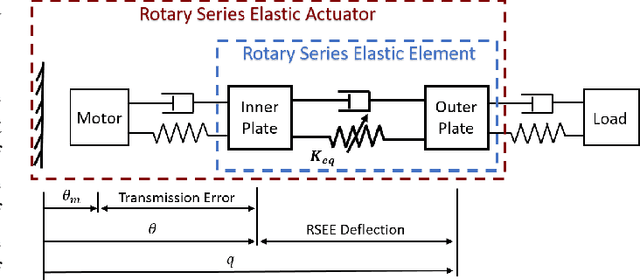
In assistive robots, compliant actuator is a key component in establishing safe and satisfactory physical human-robot interaction (pHRI). The performance of compliant actuators largely depends on the stiffness of the elastic element. Generally, low stiffness is desirable to achieve low impedance, high fidelity of force control and safe pHRI, while high stiffness is required to ensure sufficient force bandwidth and output force. These requirements, however, are contradictory and often vary according to different tasks and conditions. In order to address the contradiction of stiffness selection and improve adaptability to different applications, we develop a reconfigurable rotary series elastic actuator with nonlinear stiffness (RRSEAns) for assistive robots. In this paper, an accurate model of the reconfigurable rotary series elastic element (RSEE) is presented and the adjusting principles are investigated, followed by detailed analysis and experimental validation. The RRSEAns can provide a wide range of stiffness from 0.095 Nm/deg to 2.33 Nm/deg, and different stiffness profiles can be yielded with respect to different configuration of the reconfigurable RSEE. The overall performance of the RRSEAns is verified by experiments on frequency response, torque control and pHRI, which is adequate for most applications in assistive robots. Specifically, the root-mean-square (RMS) error of the interaction torque results as low as 0.07 Nm in transparent/human-in-charge mode, demonstrating the advantages of the RRSEAns in pHRI.
GTac: A Biomimetic Tactile Sensor with Skin-like Heterogeneous Force Feedback for Robots
Jan 28, 2022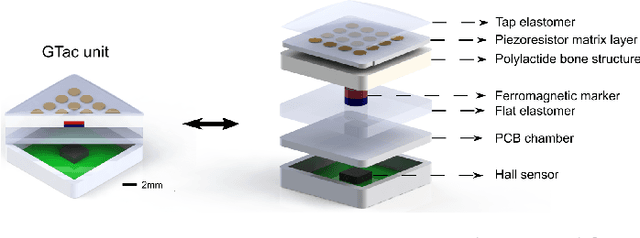
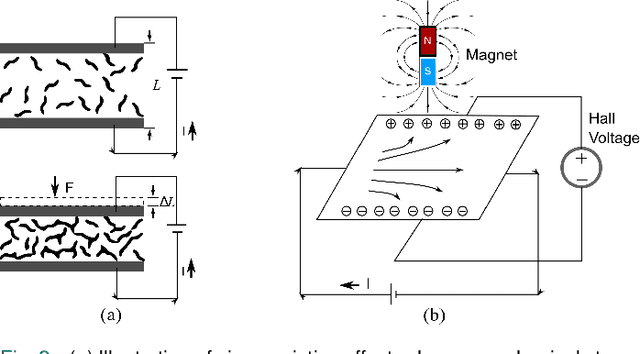

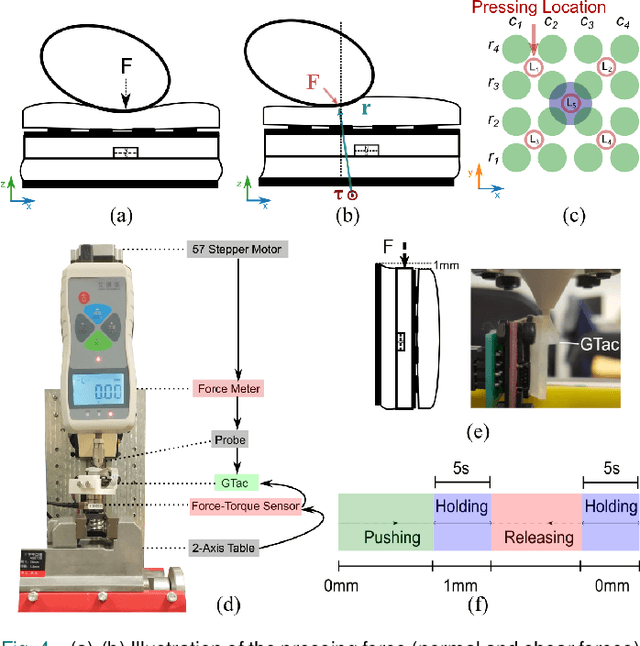
The tactile sensing capabilities of human hands are essential in performing daily activities. Simultaneously perceiving normal and shear forces via the mechanoreceptors integrated into the hands enables humans to achieve daily tasks like grasping delicate objects. In this paper, we design and fabricate a novel biomimetic tactile sensor with skin-like heterogeneity that perceives normal and shear contact forces simultaneously. It mimics the multilayers of mechanoreceptors by combining an extrinsic layer (piezoresistive sensors) and an intrinsic layer (a Hall sensor) so that it can perform estimation of contact force directions, locations, and joint-level torque. By integrating our sensors, a robotic gripper can obtain contact force feedback at fingertips; accordingly, robots can perform challenging tasks, such as tweezers usage, and egg grasping. This insightful sensor design can be customized and applied in different areas of robots and provide them with heterogeneous force sensing, potentially supporting robotics in acquiring skin-like tactile feedback.