 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGen-NeRF: Efficient and Generalizable Neural Radiance Fields via Algorithm-Hardware Co-Design
Apr 25, 2023



Novel view synthesis is an essential functionality for enabling immersive experiences in various Augmented- and Virtual-Reality (AR/VR) applications, for which generalizable Neural Radiance Fields (NeRFs) have gained increasing popularity thanks to their cross-scene generalization capability. Despite their promise, the real-device deployment of generalizable NeRFs is bottlenecked by their prohibitive complexity due to the required massive memory accesses to acquire scene features, causing their ray marching process to be memory-bounded. To this end, we propose Gen-NeRF, an algorithm-hardware co-design framework dedicated to generalizable NeRF acceleration, which for the first time enables real-time generalizable NeRFs. On the algorithm side, Gen-NeRF integrates a coarse-then-focus sampling strategy, leveraging the fact that different regions of a 3D scene contribute differently to the rendered pixel, to enable sparse yet effective sampling. On the hardware side, Gen-NeRF highlights an accelerator micro-architecture to maximize the data reuse opportunities among different rays by making use of their epipolar geometric relationship. Furthermore, our Gen-NeRF accelerator features a customized dataflow to enhance data locality during point-to-hardware mapping and an optimized scene feature storage strategy to minimize memory bank conflicts. Extensive experiments validate the effectiveness of our proposed Gen-NeRF framework in enabling real-time and generalizable novel view synthesis.
Castling-ViT: Compressing Self-Attention via Switching Towards Linear-Angular Attention During Vision Transformer Inference
Nov 18, 2022



Vision Transformers (ViTs) have shown impressive performance but still require a high computation cost as compared to convolutional neural networks (CNNs), due to the global similarity measurements and thus a quadratic complexity with the input tokens. Existing efficient ViTs adopt local attention (e.g., Swin) or linear attention (e.g., Performer), which sacrifice ViTs' capabilities of capturing either global or local context. In this work, we ask an important research question: Can ViTs learn both global and local context while being more efficient during inference? To this end, we propose a framework called Castling-ViT, which trains ViTs using both linear-angular attention and masked softmax-based quadratic attention, but then switches to having only linear angular attention during ViT inference. Our Castling-ViT leverages angular kernels to measure the similarities between queries and keys via spectral angles. And we further simplify it with two techniques: (1) a novel linear-angular attention mechanism: we decompose the angular kernels into linear terms and high-order residuals, and only keep the linear terms; and (2) we adopt two parameterized modules to approximate high-order residuals: a depthwise convolution and an auxiliary masked softmax attention to help learn both global and local information, where the masks for softmax attention are regularized to gradually become zeros and thus incur no overhead during ViT inference. Extensive experiments and ablation studies on three tasks consistently validate the effectiveness of the proposed Castling-ViT, e.g., achieving up to a 1.8% higher accuracy or 40% MACs reduction on ImageNet classification and 1.2 higher mAP on COCO detection under comparable FLOPs, as compared to ViTs with vanilla softmax-based attentions.
NASA: Neural Architecture Search and Acceleration for Hardware Inspired Hybrid Networks
Oct 24, 2022



Multiplication is arguably the most cost-dominant operation in modern deep neural networks (DNNs), limiting their achievable efficiency and thus more extensive deployment in resource-constrained applications. To tackle this limitation, pioneering works have developed handcrafted multiplication-free DNNs, which require expert knowledge and time-consuming manual iteration, calling for fast development tools. To this end, we propose a Neural Architecture Search and Acceleration framework dubbed NASA, which enables automated multiplication-reduced DNN development and integrates a dedicated multiplication-reduced accelerator for boosting DNNs' achievable efficiency. Specifically, NASA adopts neural architecture search (NAS) spaces that augment the state-of-the-art one with hardware-inspired multiplication-free operators, such as shift and adder, armed with a novel progressive pretrain strategy (PGP) together with customized training recipes to automatically search for optimal multiplication-reduced DNNs; On top of that, NASA further develops a dedicated accelerator, which advocates a chunk-based template and auto-mapper dedicated for NASA-NAS resulting DNNs to better leverage their algorithmic properties for boosting hardware efficiency. Experimental results and ablation studies consistently validate the advantages of NASA's algorithm-hardware co-design framework in terms of achievable accuracy and efficiency tradeoffs. Codes are available at https://github.com/RICE-EIC/NASA.
ViTCoD: Vision Transformer Acceleration via Dedicated Algorithm and Accelerator Co-Design
Oct 18, 2022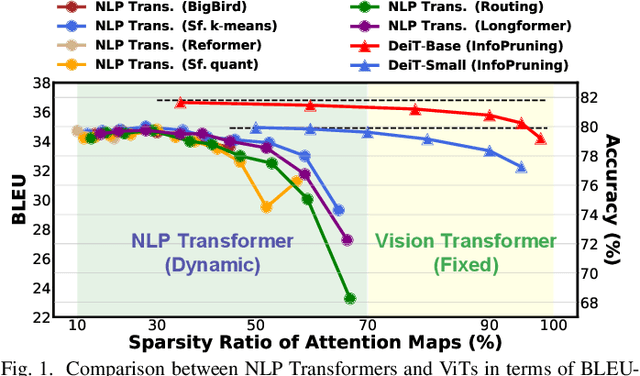
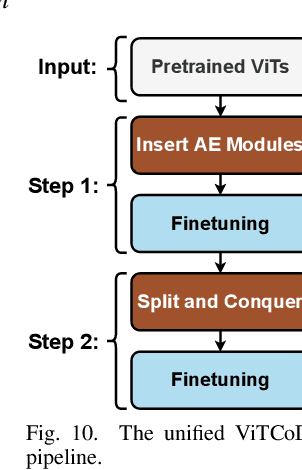
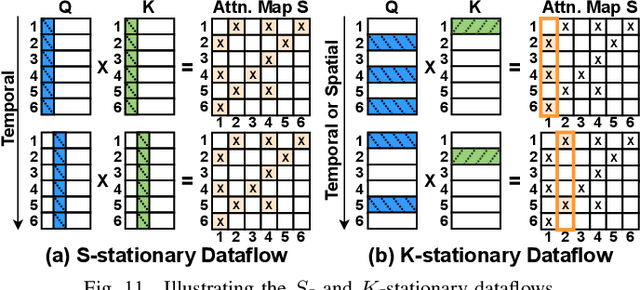
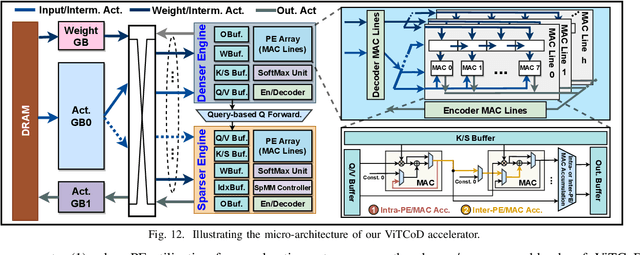
Vision Transformers (ViTs) have achieved state-of-the-art performance on various vision tasks. However, ViTs' self-attention module is still arguably a major bottleneck, limiting their achievable hardware efficiency. Meanwhile, existing accelerators dedicated to NLP Transformers are not optimal for ViTs. This is because there is a large difference between ViTs and NLP Transformers: ViTs have a relatively fixed number of input tokens, whose attention maps can be pruned by up to 90% even with fixed sparse patterns; while NLP Transformers need to handle input sequences of varying numbers of tokens and rely on on-the-fly predictions of dynamic sparse attention patterns for each input to achieve a decent sparsity (e.g., >=50%). To this end, we propose a dedicated algorithm and accelerator co-design framework dubbed ViTCoD for accelerating ViTs. Specifically, on the algorithm level, ViTCoD prunes and polarizes the attention maps to have either denser or sparser fixed patterns for regularizing two levels of workloads without hurting the accuracy, largely reducing the attention computations while leaving room for alleviating the remaining dominant data movements; on top of that, we further integrate a lightweight and learnable auto-encoder module to enable trading the dominant high-cost data movements for lower-cost computations. On the hardware level, we develop a dedicated accelerator to simultaneously coordinate the enforced denser/sparser workloads and encoder/decoder engines for boosted hardware utilization. Extensive experiments and ablation studies validate that ViTCoD largely reduces the dominant data movement costs, achieving speedups of up to 235.3x, 142.9x, 86.0x, 10.1x, and 6.8x over general computing platforms CPUs, EdgeGPUs, GPUs, and prior-art Transformer accelerators SpAtten and Sanger under an attention sparsity of 90%, respectively.
SuperTickets: Drawing Task-Agnostic Lottery Tickets from Supernets via Jointly Architecture Searching and Parameter Pruning
Jul 08, 2022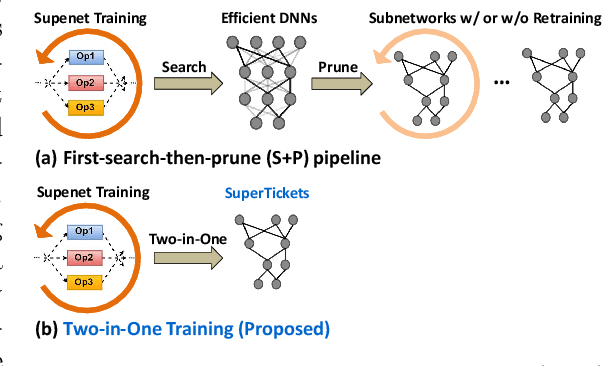
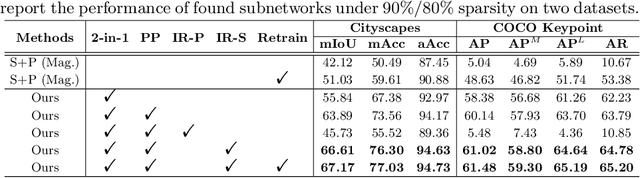
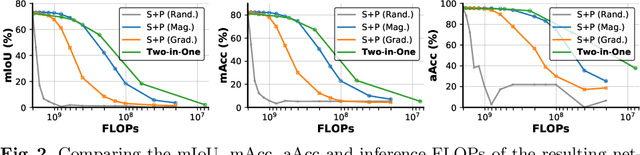
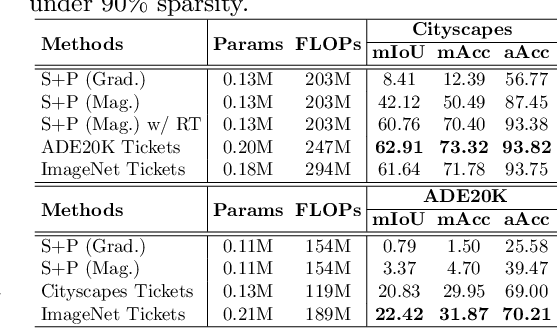
Neural architecture search (NAS) has demonstrated amazing success in searching for efficient deep neural networks (DNNs) from a given supernet. In parallel, the lottery ticket hypothesis has shown that DNNs contain small subnetworks that can be trained from scratch to achieve a comparable or higher accuracy than original DNNs. As such, it is currently a common practice to develop efficient DNNs via a pipeline of first search and then prune. Nevertheless, doing so often requires a search-train-prune-retrain process and thus prohibitive computational cost. In this paper, we discover for the first time that both efficient DNNs and their lottery subnetworks (i.e., lottery tickets) can be directly identified from a supernet, which we term as SuperTickets, via a two-in-one training scheme with jointly architecture searching and parameter pruning. Moreover, we develop a progressive and unified SuperTickets identification strategy that allows the connectivity of subnetworks to change during supernet training, achieving better accuracy and efficiency trade-offs than conventional sparse training. Finally, we evaluate whether such identified SuperTickets drawn from one task can transfer well to other tasks, validating their potential of handling multiple tasks simultaneously. Extensive experiments and ablation studies on three tasks and four benchmark datasets validate that our proposed SuperTickets achieve boosted accuracy and efficiency trade-offs than both typical NAS and pruning pipelines, regardless of having retraining or not. Codes and pretrained models are available at https://github.com/RICE-EIC/SuperTickets.
ShiftAddNAS: Hardware-Inspired Search for More Accurate and Efficient Neural Networks
May 17, 2022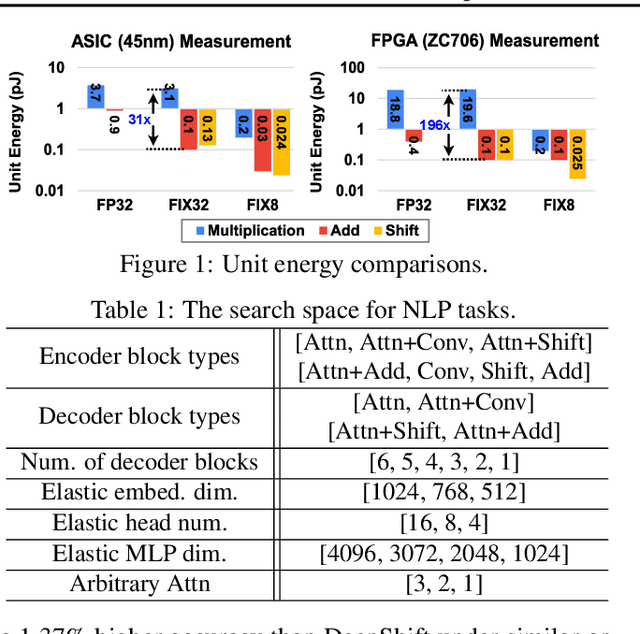
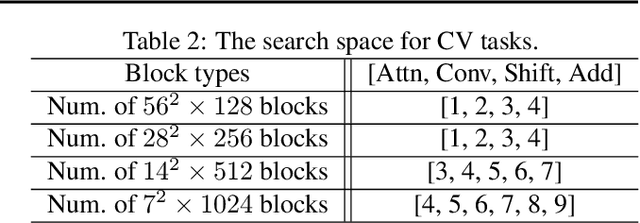
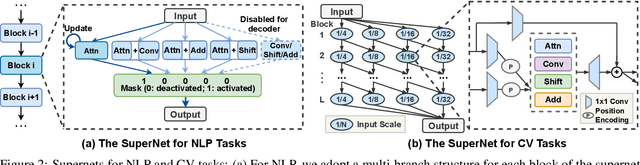
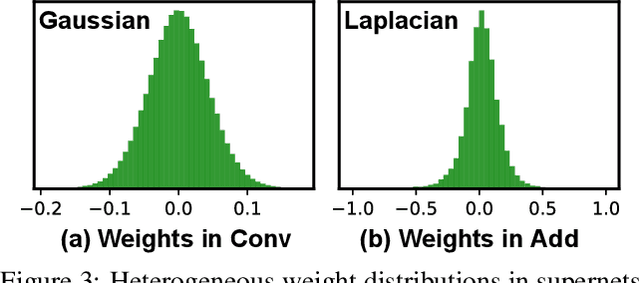
Neural networks (NNs) with intensive multiplications (e.g., convolutions and transformers) are capable yet power hungry, impeding their more extensive deployment into resource-constrained devices. As such, multiplication-free networks, which follow a common practice in energy-efficient hardware implementation to parameterize NNs with more efficient operators (e.g., bitwise shifts and additions), have gained growing attention. However, multiplication-free networks usually under-perform their vanilla counterparts in terms of the achieved accuracy. To this end, this work advocates hybrid NNs that consist of both powerful yet costly multiplications and efficient yet less powerful operators for marrying the best of both worlds, and proposes ShiftAddNAS, which can automatically search for more accurate and more efficient NNs. Our ShiftAddNAS highlights two enablers. Specifically, it integrates (1) the first hybrid search space that incorporates both multiplication-based and multiplication-free operators for facilitating the development of both accurate and efficient hybrid NNs; and (2) a novel weight sharing strategy that enables effective weight sharing among different operators that follow heterogeneous distributions (e.g., Gaussian for convolutions vs. Laplacian for add operators) and simultaneously leads to a largely reduced supernet size and much better searched networks. Extensive experiments and ablation studies on various models, datasets, and tasks consistently validate the efficacy of ShiftAddNAS, e.g., achieving up to a +7.7% higher accuracy or a +4.9 better BLEU score compared to state-of-the-art NN, while leading to up to 93% or 69% energy and latency savings, respectively. Codes and pretrained models are available at https://github.com/RICE-EIC/ShiftAddNAS.
LDP: Learnable Dynamic Precision for Efficient Deep Neural Network Training and Inference
Mar 15, 2022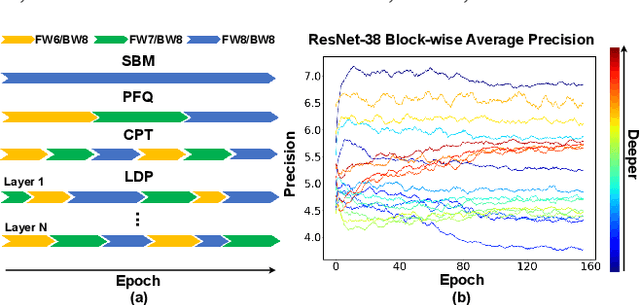

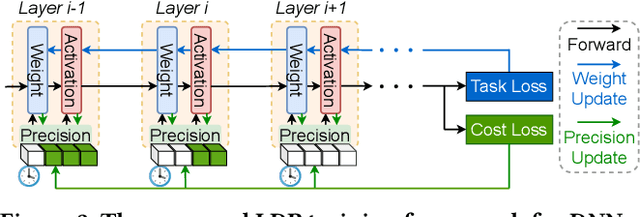

Low precision deep neural network (DNN) training is one of the most effective techniques for boosting DNNs' training efficiency, as it trims down the training cost from the finest bit level. While existing works mostly fix the model precision during the whole training process, a few pioneering works have shown that dynamic precision schedules help DNNs converge to a better accuracy while leading to a lower training cost than their static precision training counterparts. However, existing dynamic low precision training methods rely on manually designed precision schedules to achieve advantageous efficiency and accuracy trade-offs, limiting their more comprehensive practical applications and achievable performance. To this end, we propose LDP, a Learnable Dynamic Precision DNN training framework that can automatically learn a temporally and spatially dynamic precision schedule during training towards optimal accuracy and efficiency trade-offs. It is worth noting that LDP-trained DNNs are by nature efficient during inference. Furthermore, we visualize the resulting temporal and spatial precision schedule and distribution of LDP trained DNNs on different tasks to better understand the corresponding DNNs' characteristics at different training stages and DNN layers both during and after training, drawing insights for promoting further innovations. Extensive experiments and ablation studies (seven networks, five datasets, and three tasks) show that the proposed LDP consistently outperforms state-of-the-art (SOTA) low precision DNN training techniques in terms of training efficiency and achieved accuracy trade-offs. For example, in addition to having the advantage of being automated, our LDP achieves a 0.31\% higher accuracy with a 39.1\% lower computational cost when training ResNet-20 on CIFAR-10 as compared with the best SOTA method.
I-GCN: A Graph Convolutional Network Accelerator with Runtime Locality Enhancement through Islandization
Mar 07, 2022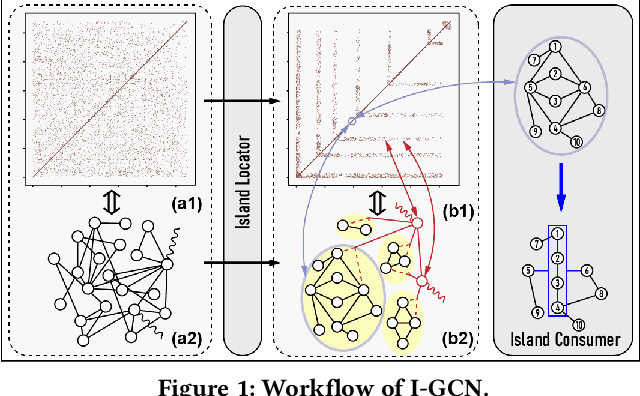
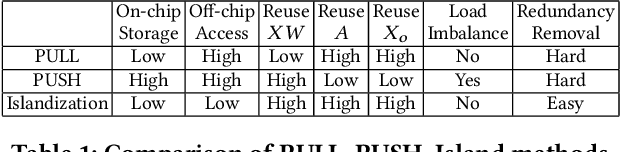

Graph Convolutional Networks (GCNs) have drawn tremendous attention in the past three years. Compared with other deep learning modalities, high-performance hardware acceleration of GCNs is as critical but even more challenging. The hurdles arise from the poor data locality and redundant computation due to the large size, high sparsity, and irregular non-zero distribution of real-world graphs. In this paper we propose a novel hardware accelerator for GCN inference, called I-GCN, that significantly improves data locality and reduces unnecessary computation. The mechanism is a new online graph restructuring algorithm we refer to as islandization. The proposed algorithm finds clusters of nodes with strong internal but weak external connections. The islandization process yields two major benefits. First, by processing islands rather than individual nodes, there is better on-chip data reuse and fewer off-chip memory accesses. Second, there is less redundant computation as aggregation for common/shared neighbors in an island can be reused. The parallel search, identification, and leverage of graph islands are all handled purely in hardware at runtime working in an incremental pipeline. This is done without any preprocessing of the graph data or adjustment of the GCN model structure. Experimental results show that I-GCN can significantly reduce off-chip accesses and prune 38% of aggregation operations, leading to performance speedups over CPUs, GPUs, the prior art GCN accelerators of 5549x, 403x, and 5.7x on average, respectively.
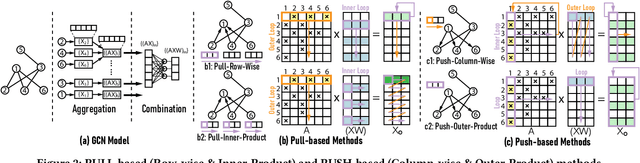
GCoD: Graph Convolutional Network Acceleration via Dedicated Algorithm and Accelerator Co-Design
Dec 22, 2021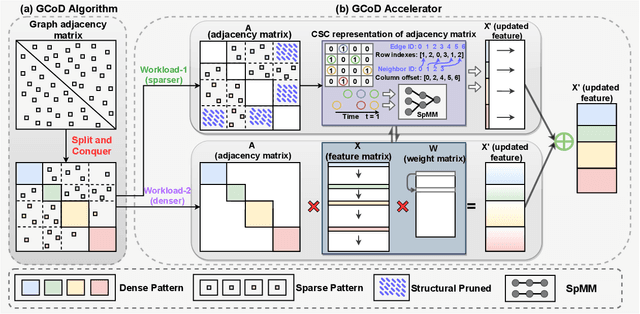
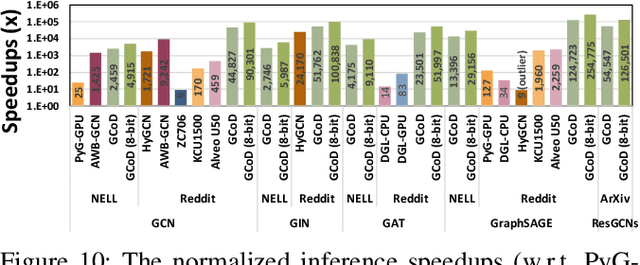

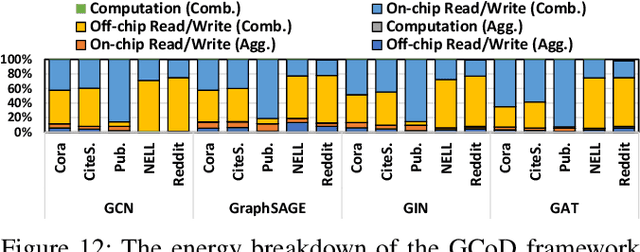
Graph Convolutional Networks (GCNs) have emerged as the state-of-the-art graph learning model. However, it can be notoriously challenging to inference GCNs over large graph datasets, limiting their application to large real-world graphs and hindering the exploration of deeper and more sophisticated GCN graphs. This is because real-world graphs can be extremely large and sparse. Furthermore, the node degree of GCNs tends to follow the power-law distribution and therefore have highly irregular adjacency matrices, resulting in prohibitive inefficiencies in both data processing and movement and thus substantially limiting the achievable GCN acceleration efficiency. To this end, this paper proposes a GCN algorithm and accelerator Co-Design framework dubbed GCoD which can largely alleviate the aforementioned GCN irregularity and boost GCNs' inference efficiency. Specifically, on the algorithm level, GCoD integrates a split and conquer GCN training strategy that polarizes the graphs to be either denser or sparser in local neighborhoods without compromising the model accuracy, resulting in graph adjacency matrices that (mostly) have merely two levels of workload and enjoys largely enhanced regularity and thus ease of acceleration. On the hardware level, we further develop a dedicated two-pronged accelerator with a separated engine to process each of the aforementioned denser and sparser workloads, further boosting the overall utilization and acceleration efficiency. Extensive experiments and ablation studies validate that our GCoD consistently reduces the number of off-chip accesses, leading to speedups of 15286x, 294x, 7.8x, and 2.5x as compared to CPUs, GPUs, and prior-art GCN accelerators including HyGCN and AWB-GCN, respectively, while maintaining or even improving the task accuracy.
G-CoS: GNN-Accelerator Co-Search Towards Both Better Accuracy and Efficiency
Sep 18, 2021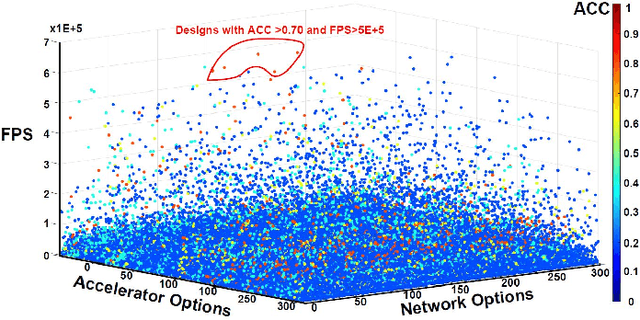
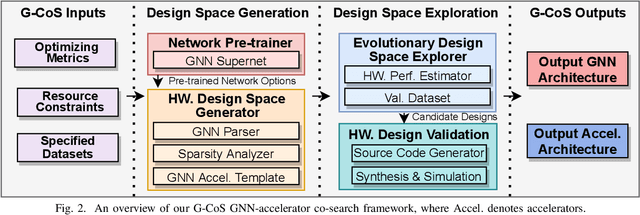
Graph Neural Networks (GNNs) have emerged as the state-of-the-art (SOTA) method for graph-based learning tasks. However, it still remains prohibitively challenging to inference GNNs over large graph datasets, limiting their application to large-scale real-world tasks. While end-to-end jointly optimizing GNNs and their accelerators is promising in boosting GNNs' inference efficiency and expediting the design process, it is still underexplored due to the vast and distinct design spaces of GNNs and their accelerators. In this work, we propose G-CoS, a GNN and accelerator co-search framework that can automatically search for matched GNN structures and accelerators to maximize both task accuracy and acceleration efficiency. Specifically, GCoS integrates two major enabling components: (1) a generic GNN accelerator search space which is applicable to various GNN structures and (2) a one-shot GNN and accelerator co-search algorithm that enables simultaneous and efficient search for optimal GNN structures and their matched accelerators. To the best of our knowledge, G-CoS is the first co-search framework for GNNs and their accelerators. Extensive experiments and ablation studies show that the GNNs and accelerators generated by G-CoS consistently outperform SOTA GNNs and GNN accelerators in terms of both task accuracy and hardware efficiency, while only requiring a few hours for the end-to-end generation of the best matched GNNs and their accelerators.