 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Allocate, How to Learn? Dynamic Rollout Allocation and Advantage Modulation for Policy Optimization
Feb 22, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has proven effective for Large Language Model (LLM) reasoning, yet current methods face key challenges in resource allocation and policy optimization dynamics: (i) uniform rollout allocation ignores gradient variance heterogeneity across problems, and (ii) the softmax policy structure causes gradient attenuation for high-confidence correct actions, while excessive gradient updates may destabilize training. Therefore, we propose DynaMO, a theoretically-grounded dual-pronged optimization framework. At the sequence level, we prove that uniform allocation is suboptimal and derive variance-minimizing allocation from the first principle, establishing Bernoulli variance as a computable proxy for gradient informativeness. At the token level, we develop gradient-aware advantage modulation grounded in theoretical analysis of gradient magnitude bounds. Our framework compensates for gradient attenuation of high-confidence correct actions while utilizing entropy changes as computable indicators to stabilize excessive update magnitudes. Extensive experiments conducted on a diverse range of mathematical reasoning benchmarks demonstrate consistent improvements over strong RLVR baselines. Our implementation is available at: \href{https://anonymous.4open.science/r/dynamo-680E/README.md}{https://anonymous.4open.science/r/dynamo}.
Proximity-Based Multi-Turn Optimization: Practical Credit Assignment for LLM Agent Training
Feb 22, 2026Multi-turn LLM agents are becoming pivotal to production systems, spanning customer service automation, e-commerce assistance, and interactive task management, where accurately distinguishing high-value informative signals from stochastic noise is critical for sample-efficient training. In real-world scenarios, a failure in a trivial task may reflect random instability, whereas success in a high-difficulty task signifies a genuine capability breakthrough. Yet, existing group-based policy optimization methods rigidly rely on statistical deviation within discrete batches, frequently misallocating credit when task difficulty fluctuates. To address this issue, we propose Proximity-based Multi-turn Optimization (ProxMO), a practical and robust framework engineered specifically for the constraints of real-world deployment. ProxMO integrates global context via two lightweight mechanisms: success-rate-aware modulation dynamically adapts gradient intensity based on episode-level difficulty, while proximity-based soft aggregation derives baselines through continuous semantic weighting at the step level. Extensive evaluations on ALFWorld and WebShop benchmarks demonstrate that ProxMO yields substantial performance gains over existing baselines with negligible computational cost. Ablation studies further validate the independent and synergistic efficacy of both mechanisms. Crucially, ProxMO offers plug-and-play compatibility with standard GRPO frameworks, facilitating immediate, low-friction adoption in existing industrial training pipelines. Our implementation is available at: \href{https://anonymous.4open.science/r/proxmo-B7E7/README.md}{https://anonymous.4open.science/r/proxmo}.
DreamScene: 3D Gaussian-based Text-to-3D Scene Generation via Formation Pattern Sampling
Apr 04, 2024
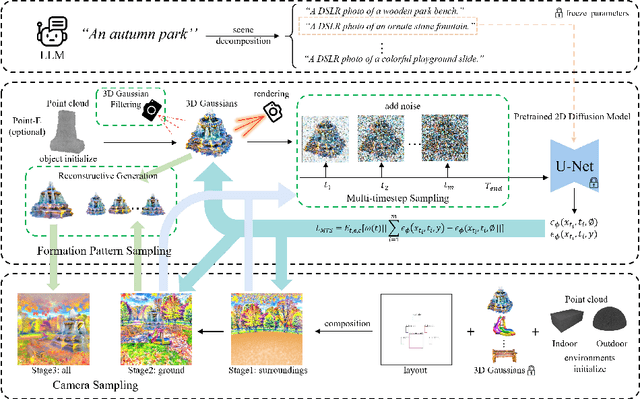
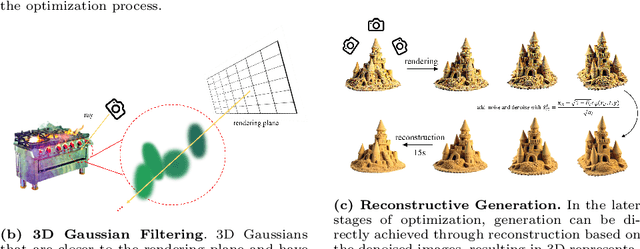
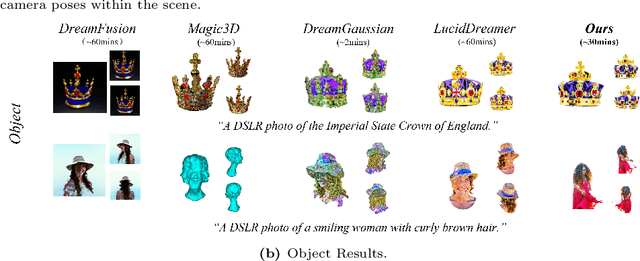
Text-to-3D scene generation holds immense potential for the gaming, film, and architecture sectors. Despite significant progress, existing methods struggle with maintaining high quality, consistency, and editing flexibility. In this paper, we propose DreamScene, a 3D Gaussian-based novel text-to-3D scene generation framework, to tackle the aforementioned three challenges mainly via two strategies. First, DreamScene employs Formation Pattern Sampling (FPS), a multi-timestep sampling strategy guided by the formation patterns of 3D objects, to form fast, semantically rich, and high-quality representations. FPS uses 3D Gaussian filtering for optimization stability, and leverages reconstruction techniques to generate plausible textures. Second, DreamScene employs a progressive three-stage camera sampling strategy, specifically designed for both indoor and outdoor settings, to effectively ensure object-environment integration and scene-wide 3D consistency. Last, DreamScene enhances scene editing flexibility by integrating objects and environments, enabling targeted adjustments. Extensive experiments validate DreamScene's superiority over current state-of-the-art techniques, heralding its wide-ranging potential for diverse applications. Code and demos will be released at https://dreamscene-project.github.io .
2D-Guided 3D Gaussian Segmentation
Dec 26, 2023Recently, 3D Gaussian, as an explicit 3D representation method, has demonstrated strong competitiveness over NeRF (Neural Radiance Fields) in terms of expressing complex scenes and training duration. These advantages signal a wide range of applications for 3D Gaussians in 3D understanding and editing. Meanwhile, the segmentation of 3D Gaussians is still in its infancy. The existing segmentation methods are not only cumbersome but also incapable of segmenting multiple objects simultaneously in a short amount of time. In response, this paper introduces a 3D Gaussian segmentation method implemented with 2D segmentation as supervision. This approach uses input 2D segmentation maps to guide the learning of the added 3D Gaussian semantic information, while nearest neighbor clustering and statistical filtering refine the segmentation results. Experiments show that our concise method can achieve comparable performances on mIOU and mAcc for multi-object segmentation as previous single-object segmentation methods.