 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Continual Experience Internalization for Self-Evolving LLM Agents
Jun 03, 2026Experience internalization converts contextual experience from past interactions into reusable parametric capability, offering a promising path toward continual learning in large language models (LLMs). While prior work has predominantly focused on single-iteration transfer, we discover that under multi-iteration experience learning, existing methods suffer from a progressive capability collapse rather than compounding improvement. We systematically examine this failure through three vital dimensions of experience internalization: (1) Experience Granularity: We find that principle-level experience is more durable than instance-level experience, as it effectively abstracts transferable strategies away from trajectory-specific details. (2) Experience Injection Pattern: Our analysis reveals that step-wise injection significantly outperforms global injection by aligning experience with intermediate decision states, a property that is critical for long-horizon tool use. (3) Internalization Regime: We demonstrate that off-policy context-distillation on high-quality teacher trajectories provides a substantially more stable training signal than on-policy context-distillation, which is inherently limited by local corrections on student-induced flawed states. Together, these insights yield a simple yet robust recipe for stable and sustainable experience internalization, providing concrete guidance for engineering self-evolving and continually learning LLMs.
SIRI: Self-Internalizing Reinforcement Learning with Intrinsic Skills for LLM Agent Training
Jun 01, 2026Long-horizon LLM agents can benefit from reusable skills, yet existing skill-based methods often rely on external skill generators during training or persistent skill retrieval at inference, increasing engineering complexity, context length, and deployment latency. We propose Self-Internalizing Reinforcement learning with Intrinsic skills (SIRI), a three-phase framework that enables agents to discover, validate, and internalize skills without external skill generators or inference-time skill banks. SIRI first warms up the policy with GiGPO to acquire basic interaction ability and collect successful skill-free trajectories. It then performs self-skill mining, where the current policy summarizes compact skills from its own successful plain rollouts and validates them through paired skill-augmented and skill-free rollouts. Finally, SIRI distills only beneficial skill-guided action tokens into the plain policy using trajectory-level utility and action-level advantage. At inference, the agent runs with the original prompt only. On ALFWorld and WebShop with Qwen2.5-7B-Instruct, SIRI improves GiGPO from 0.908 to 0.930 on ALFWorld and from 0.728 to 0.813 on WebShop, outperforming prompt-based, RL-based, and memory-augmented baselines. Further analysis shows that our self-mining strategy can achieve performance comparable to distillation with closed-source large model. Our code is available at https://github.com/kirito618/SIRI.
Skill or Skip? Learning Selective Skill Invocation in Agentic Tasks via Dual-Granularity Preference Learning
May 30, 2026Agent skills are callable procedural modules that provide reusable knowledge and execution policies for complex agentic tasks. However, existing methods mainly focus on selecting relevant skills or improving the skills themselves, while overlooking whether a relevant skill should actually be invoked at the current decision point. Unhelpful invocations may introduce irrelevant context and disrupt an otherwise correct execution process. To address this issue, we propose SelSkill, a dual-granularity preference-learning framework for selective skill invocation. SelSkill formulates skill use as a skill-or-skip decision, uses predictive uncertainty to prioritize candidate decision points, and constructs controlled invoke-skip preference pairs from shared trajectory prefixes. It further combines episode-level outcome preferences with step-level invocation preferences to capture both overall trajectory quality and the local effectiveness of skill invocation. On ALFWorld with Qwen3-8B, SelSkill improves task success by 10.9 percentage points and execution precision by 29.1 percentage points. On BFCL, it improves task success by 5.7 percentage points and execution precision by 29.5 percentage points. Zero-shot results on Tau-bench and PopQA further suggest that the learned invocation policy transfers to new domains with previously unseen skills.
From $\boldsymbol{\logπ}$ to $\boldsymbolπ$: Taming Divergence in Soft Clipping via Bilateral Decoupled Decay of Probability Gradient Weight
Mar 15, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has catalyzed a leap in Large Language Model (LLM) reasoning, yet its optimization dynamics remain fragile. Standard algorithms like GRPO enforce stability via ``hard clipping'', which inadvertently stifles exploration by discarding gradients of tokens outside the trust region. While recent ``soft clipping'' methods attempt to recover these gradients, they suffer from a critical challenge: relying on log-probability gradient ($\nabla_θ\log π_θ$) yields divergent weights as probabilities vanish, destabilizing LLM training. We rethink this convention by establishing probability gradient ($\nabla_θπ_θ$) as the superior optimization primitive. Accordingly, we propose Decoupled Gradient Policy Optimization (DGPO), which employs a decoupled decay mechanism based on importance sampling ratios. By applying asymmetric, continuous decay to boundary tokens, DGPO resolves the conflict between stability and sustained exploration. Extensive experiments across DeepSeek-R1-Distill-Qwen series models (1.5B/7B/14B) demonstrate that DGPO consistently outperforms strong baselines on various mathematical benchmarks, offering a robust and scalable solution for RLVR. Our code and implementation are available at: https://github.com/VenomRose-Juri/DGPO-RL.
How to Allocate, How to Learn? Dynamic Rollout Allocation and Advantage Modulation for Policy Optimization
Feb 22, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has proven effective for Large Language Model (LLM) reasoning, yet current methods face key challenges in resource allocation and policy optimization dynamics: (i) uniform rollout allocation ignores gradient variance heterogeneity across problems, and (ii) the softmax policy structure causes gradient attenuation for high-confidence correct actions, while excessive gradient updates may destabilize training. Therefore, we propose DynaMO, a theoretically-grounded dual-pronged optimization framework. At the sequence level, we prove that uniform allocation is suboptimal and derive variance-minimizing allocation from the first principle, establishing Bernoulli variance as a computable proxy for gradient informativeness. At the token level, we develop gradient-aware advantage modulation grounded in theoretical analysis of gradient magnitude bounds. Our framework compensates for gradient attenuation of high-confidence correct actions while utilizing entropy changes as computable indicators to stabilize excessive update magnitudes. Extensive experiments conducted on a diverse range of mathematical reasoning benchmarks demonstrate consistent improvements over strong RLVR baselines. Our implementation is available at: \href{https://anonymous.4open.science/r/dynamo-680E/README.md}{https://anonymous.4open.science/r/dynamo}.
MASPO: Unifying Gradient Utilization, Probability Mass, and Signal Reliability for Robust and Sample-Efficient LLM Reasoning
Feb 19, 2026Existing Reinforcement Learning with Verifiable Rewards (RLVR) algorithms, such as GRPO, rely on rigid, uniform, and symmetric trust region mechanisms that are fundamentally misaligned with the complex optimization dynamics of Large Language Models (LLMs). In this paper, we identify three critical challenges in these methods: (1) inefficient gradient utilization caused by the binary cutoff of hard clipping, (2) insensitive probability mass arising from uniform ratio constraints that ignore the token distribution, and (3) asymmetric signal reliability stemming from the disparate credit assignment ambiguity between positive and negative samples. To bridge these gaps, we propose Mass-Adaptive Soft Policy Optimization (MASPO), a unified framework designed to harmonize these three dimensions. MASPO integrates a differentiable soft Gaussian gating to maximize gradient utility, a mass-adaptive limiter to balance exploration across the probability spectrum, and an asymmetric risk controller to align update magnitudes with signal confidence. Extensive evaluations demonstrate that MASPO serves as a robust, all-in-one RLVR solution, significantly outperforming strong baselines. Our code is available at: https://anonymous.4open.science/r/ma1/README.md.
Single Document Image Highlight Removal via A Large-Scale Real-World Dataset and A Location-Aware Network
Apr 19, 2025



Reflective documents often suffer from specular highlights under ambient lighting, severely hindering text readability and degrading overall visual quality. Although recent deep learning methods show promise in highlight removal, they remain suboptimal for document images, primarily due to the lack of dedicated datasets and tailored architectural designs. To tackle these challenges, we present DocHR14K, a large-scale real-world dataset comprising 14,902 high-resolution image pairs across six document categories and various lighting conditions. To the best of our knowledge, this is the first high-resolution dataset for document highlight removal that captures a wide range of real-world lighting conditions. Additionally, motivated by the observation that the residual map between highlighted and clean images naturally reveals the spatial structure of highlight regions, we propose a simple yet effective Highlight Location Prior (HLP) to estimate highlight masks without human annotations. Building on this prior, we present the Location-Aware Laplacian Pyramid Highlight Removal Network (L2HRNet), which effectively removes highlights by leveraging estimated priors and incorporates diffusion module to restore details. Extensive experiments demonstrate that DocHR14K improves highlight removal under diverse lighting conditions. Our L2HRNet achieves state-of-the-art performance across three benchmark datasets, including a 5.01\% increase in PSNR and a 13.17\% reduction in RMSE on DocHR14K.
Simple or Complex? Complexity-Controllable Question Generation with Soft Templates and Deep Mixture of Experts Model
Oct 13, 2021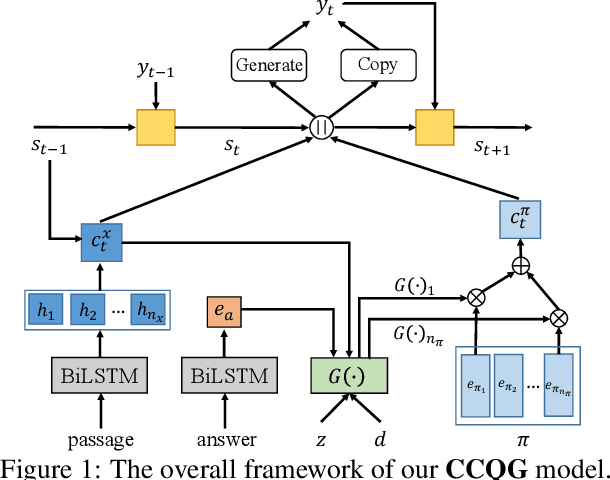
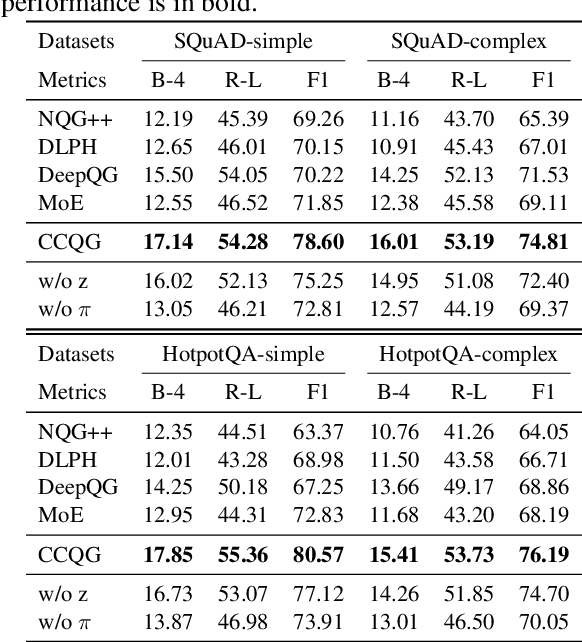
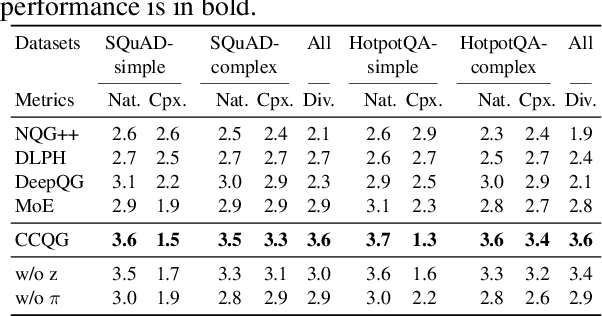
The ability to generate natural-language questions with controlled complexity levels is highly desirable as it further expands the applicability of question generation. In this paper, we propose an end-to-end neural complexity-controllable question generation model, which incorporates a mixture of experts (MoE) as the selector of soft templates to improve the accuracy of complexity control and the quality of generated questions. The soft templates capture question similarity while avoiding the expensive construction of actual templates. Our method introduces a novel, cross-domain complexity estimator to assess the complexity of a question, taking into account the passage, the question, the answer and their interactions. The experimental results on two benchmark QA datasets demonstrate that our QG model is superior to state-of-the-art methods in both automatic and manual evaluation. Moreover, our complexity estimator is significantly more accurate than the baselines in both in-domain and out-domain settings.
Generating Pertinent and Diversified Comments with Topic-aware Pointer-Generator Networks
May 09, 2020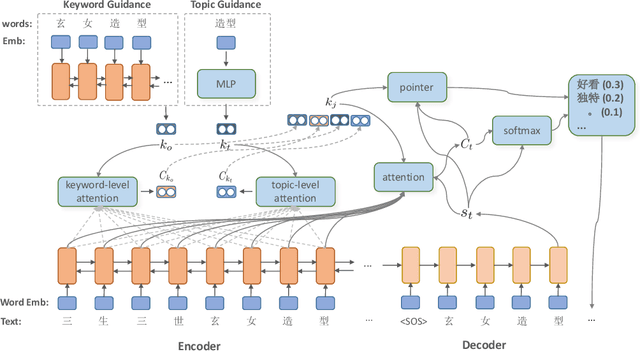
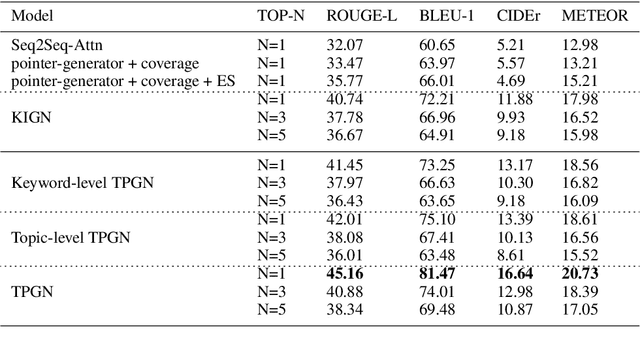
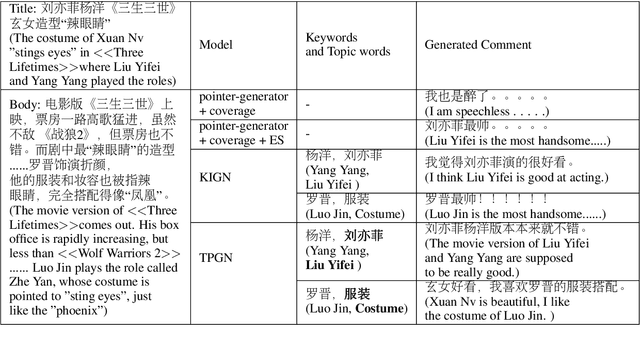
Comment generation, a new and challenging task in Natural Language Generation (NLG), attracts a lot of attention in recent years. However, comments generated by previous work tend to lack pertinence and diversity. In this paper, we propose a novel generation model based on Topic-aware Pointer-Generator Networks (TPGN), which can utilize the topic information hidden in the articles to guide the generation of pertinent and diversified comments. Firstly, we design a keyword-level and topic-level encoder attention mechanism to capture topic information in the articles. Next, we integrate the topic information into pointer-generator networks to guide comment generation. Experiments on a large scale of comment generation dataset show that our model produces the valuable comments and outperforms competitive baseline models significantly.