 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graph-Enhanced Large Language Models via Path Selection
Jun 19, 2024Large Language Models (LLMs) have shown unprecedented performance in various real-world applications. However, they are known to generate factually inaccurate outputs, a.k.a. the hallucination problem. In recent years, incorporating external knowledge extracted from Knowledge Graphs (KGs) has become a promising strategy to improve the factual accuracy of LLM-generated outputs. Nevertheless, most existing explorations rely on LLMs themselves to perform KG knowledge extraction, which is highly inflexible as LLMs can only provide binary judgment on whether a certain knowledge (e.g., a knowledge path in KG) should be used. In addition, LLMs tend to pick only knowledge with direct semantic relationship with the input text, while potentially useful knowledge with indirect semantics can be ignored. In this work, we propose a principled framework KELP with three stages to handle the above problems. Specifically, KELP is able to achieve finer granularity of flexible knowledge extraction by generating scores for knowledge paths with input texts via latent semantic matching. Meanwhile, knowledge paths with indirect semantic relationships with the input text can also be considered via trained encoding between the selected paths in KG and the input text. Experiments on real-world datasets validate the effectiveness of KELP.
Hybrid-Prediction Integrated Planning for Autonomous Driving
Feb 04, 2024Autonomous driving systems require the ability to fully understand and predict the surrounding environment to make informed decisions in complex scenarios. Recent advancements in learning-based systems have highlighted the importance of integrating prediction and planning modules. However, this integration has brought forth three major challenges: inherent trade-offs by sole prediction, consistency between prediction patterns, and social coherence in prediction and planning. To address these challenges, we introduce a hybrid-prediction integrated planning (HPP) system, which possesses three novelly designed modules. First, we introduce marginal-conditioned occupancy prediction to align joint occupancy with agent-wise perceptions. Our proposed MS-OccFormer module achieves multi-stage alignment per occupancy forecasting with consistent awareness from agent-wise motion predictions. Second, we propose a game-theoretic motion predictor, GTFormer, to model the interactive future among individual agents with their joint predictive awareness. Third, hybrid prediction patterns are concurrently integrated with Ego Planner and optimized by prediction guidance. HPP achieves state-of-the-art performance on the nuScenes dataset, demonstrating superior accuracy and consistency for end-to-end paradigms in prediction and planning. Moreover, we test the long-term open-loop and closed-loop performance of HPP on the Waymo Open Motion Dataset and CARLA benchmark, surpassing other integrated prediction and planning pipelines with enhanced accuracy and compatibility.
Towards End-to-End GPS Localization with Neural Pseudorange Correction
Jan 19, 2024Pseudorange errors are the root cause of localization inaccuracy in GPS. Previous data-driven methods regress and eliminate pseudorange errors using handcrafted intermediate labels. Unlike them, we propose an end-to-end GPS localization framework, E2E-PrNet, to train a neural network for pseudorange correction (PrNet) directly using the final task loss calculated with the ground truth of GPS receiver states. The gradients of the loss with respect to learnable parameters are backpropagated through a differentiable nonlinear least squares optimizer to PrNet. The feasibility is verified with GPS data collected by Android phones, showing that E2E-PrNet outperforms the state-of-the-art end-to-end GPS localization methods.
Knowledge Editing for Large Language Models: A Survey
Oct 26, 2023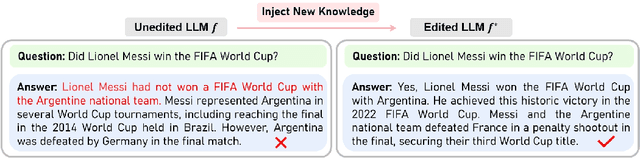
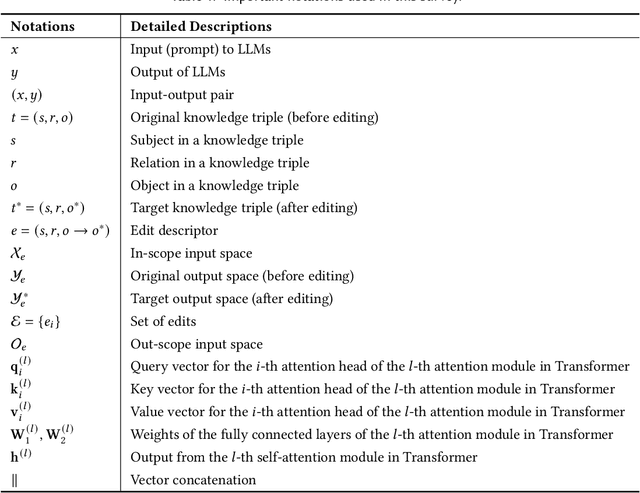
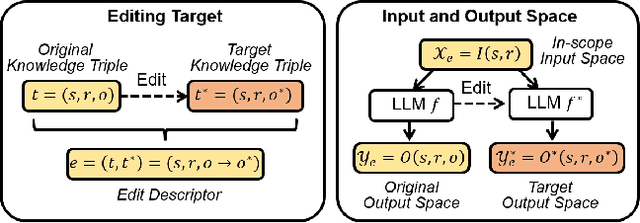

Large language models (LLMs) have recently transformed both the academic and industrial landscapes due to their remarkable capacity to understand, analyze, and generate texts based on their vast knowledge and reasoning ability. Nevertheless, one major drawback of LLMs is their substantial computational cost for pre-training due to their unprecedented amounts of parameters. The disadvantage is exacerbated when new knowledge frequently needs to be introduced into the pre-trained model. Therefore, it is imperative to develop effective and efficient techniques to update pre-trained LLMs. Traditional methods encode new knowledge in pre-trained LLMs through direct fine-tuning. However, naively re-training LLMs can be computationally intensive and risks degenerating valuable pre-trained knowledge irrelevant to the update in the model. Recently, Knowledge-based Model Editing (KME) has attracted increasing attention, which aims to precisely modify the LLMs to incorporate specific knowledge, without negatively influencing other irrelevant knowledge. In this survey, we aim to provide a comprehensive and in-depth overview of recent advances in the field of KME. We first introduce a general formulation of KME to encompass different KME strategies. Afterward, we provide an innovative taxonomy of KME techniques based on how the new knowledge is introduced into pre-trained LLMs, and investigate existing KME strategies while analyzing key insights, advantages, and limitations of methods from each category. Moreover, representative metrics, datasets, and applications of KME are introduced accordingly. Finally, we provide an in-depth analysis regarding the practicality and remaining challenges of KME and suggest promising research directions for further advancement in this field.
PrNet: A Neural Network for Correcting Pseudoranges to Improve Positioning with Android Raw GNSS Measurements
Sep 16, 2023



We present a neural network for mitigating pseudorange bias to improve localization performance with data collected from Android smartphones. We represent pseudorange bias using a pragmatic satellite-wise Multiple Layer Perceptron (MLP), the inputs of which are six satellite-receiver-context-related features derived from Android raw Global Navigation Satellite System (GNSS) measurements. To supervise the training process, we carefully calculate the target values of pseudorange bias using location ground truth and smoothing techniques and optimize a loss function containing the estimation residuals of smartphone clock bias. During the inference process, we employ model-based localization engines to compute locations with pseudoranges corrected by the neural network. Consequently, this hybrid pipeline can attend to both pseudorange bias and noise. We evaluate the framework on an open dataset and consider four application scenarios for investigating fingerprinting and cross-trace localization in rural and urban areas. Extensive experiments demonstrate that the proposed framework outperforms model-based and state-of-the-art data-driven approaches.
An Empirical Study on Instance Selection Strategies in Self-training for Sentiment Analysis
Sep 15, 2023



Sentiment analysis is a crucial task in natural language processing that involves identifying and extracting subjective sentiment from text. Self-training has recently emerged as an economical and efficient technique for developing sentiment analysis models by leveraging a small amount of labeled data and a larger amount of unlabeled data. However, the performance of a self-training procedure heavily relies on the choice of the instance selection strategy, which has not been studied thoroughly. This paper presents an empirical study on various instance selection strategies for self-training on two public sentiment datasets, and investigates the influence of the strategy and hyper-parameters on the performance of self-training in various few-shot settings.
Occupancy Prediction-Guided Neural Planner for Autonomous Driving
May 05, 2023Forecasting the scalable future states of surrounding traffic participants in complex traffic scenarios is a critical capability for autonomous vehicles, as it enables safe and feasible decision-making. Recent successes in learning-based prediction and planning have introduced two primary challenges: generating accurate joint predictions for the environment and integrating prediction guidance for planning purposes. To address these challenges, we propose a two-stage integrated neural planning framework, termed OPGP, that incorporates joint prediction guidance from occupancy forecasting. The preliminary planning phase simultaneously outputs the predicted occupancy for various types of traffic actors based on imitation learning objectives, taking into account shared interactions, scene context, and actor dynamics within a unified Transformer structure. Subsequently, the transformed occupancy prediction guides optimization to further inform safe and smooth planning under Frenet coordinates. We train our planner using a large-scale, real-world driving dataset and validate it in open-loop configurations. Our proposed planner outperforms strong learning-based methods, exhibiting improved performance due to occupancy prediction guidance.
GameFormer: Game-theoretic Modeling and Learning of Transformer-based Interactive Prediction and Planning for Autonomous Driving
Mar 10, 2023Autonomous vehicles operating in complex real-world environments require accurate predictions of interactive behaviors between traffic participants. While existing works focus on modeling agent interactions based on their past trajectories, their future interactions are often ignored. This paper addresses the interaction prediction problem by formulating it with hierarchical game theory and proposing the GameFormer framework to implement it. Specifically, we present a novel Transformer decoder structure that uses the prediction results from the previous level together with the common environment background to iteratively refine the interaction process. Moreover, we propose a learning process that regulates an agent's behavior at the current level to respond to other agents' behaviors from the last level. Through experiments on a large-scale real-world driving dataset, we demonstrate that our model can achieve state-of-the-art prediction accuracy on the interaction prediction task. We also validate the model's capability to jointly reason about the ego agent's motion plans and other agents' behaviors in both open-loop and closed-loop planning tests, outperforming a variety of baseline methods.
Fairly Adaptive Negative Sampling for Recommendations
Feb 16, 2023



Pairwise learning strategies are prevalent for optimizing recommendation models on implicit feedback data, which usually learns user preference by discriminating between positive (i.e., clicked by a user) and negative items (i.e., obtained by negative sampling). However, the size of different item groups (specified by item attribute) is usually unevenly distributed. We empirically find that the commonly used uniform negative sampling strategy for pairwise algorithms (e.g., BPR) can inherit such data bias and oversample the majority item group as negative instances, severely countering group fairness on the item side. In this paper, we propose a Fairly adaptive Negative sampling approach (FairNeg), which improves item group fairness via adaptively adjusting the group-level negative sampling distribution in the training process. In particular, it first perceives the model's unfairness status at each step and then adjusts the group-wise sampling distribution with an adaptive momentum update strategy for better facilitating fairness optimization. Moreover, a negative sampling distribution Mixup mechanism is proposed, which gracefully incorporates existing importance-aware sampling techniques intended for mining informative negative samples, thus allowing for achieving multiple optimization purposes. Extensive experiments on four public datasets show our proposed method's superiority in group fairness enhancement and fairness-utility tradeoff.
Learning Interaction-aware Motion Prediction Model for Decision-making in Autonomous Driving
Feb 08, 2023



Predicting the behaviors of other road users is crucial to safe and intelligent decision-making for autonomous vehicles (AVs). However, most motion prediction models ignore the influence of the AV's actions and the planning module has to treat other agents as unalterable moving obstacles. To address this problem, this paper proposes an interaction-aware motion prediction model that is able to predict other agents' future trajectories according to the ego agent's future plan, i.e., their reactions to the ego's actions. Specifically, we employ Transformers to effectively encode the driving scene and incorporate the AV's plan in decoding the predicted trajectories. To train the model to accurately predict the reactions of other agents, we develop an online learning framework, where the ego agent explores the environment and collects other agents' reactions to itself. We validate the decision-making and learning framework in three highly interactive simulated driving scenarios. The results reveal that our decision-making method significantly outperforms the reinforcement learning methods in terms of data efficiency and performance. We also find that using the interaction-aware model can bring better performance than the non-interaction-aware model and the exploration process helps improve the success rate in testing.