 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagicProp: Diffusion-based Video Editing via Motion-aware Appearance Propagation
Sep 02, 2023This paper addresses the issue of modifying the visual appearance of videos while preserving their motion. A novel framework, named MagicProp, is proposed, which disentangles the video editing process into two stages: appearance editing and motion-aware appearance propagation. In the first stage, MagicProp selects a single frame from the input video and applies image-editing techniques to modify the content and/or style of the frame. The flexibility of these techniques enables the editing of arbitrary regions within the frame. In the second stage, MagicProp employs the edited frame as an appearance reference and generates the remaining frames using an autoregressive rendering approach. To achieve this, a diffusion-based conditional generation model, called PropDPM, is developed, which synthesizes the target frame by conditioning on the reference appearance, the target motion, and its previous appearance. The autoregressive editing approach ensures temporal consistency in the resulting videos. Overall, MagicProp combines the flexibility of image-editing techniques with the superior temporal consistency of autoregressive modeling, enabling flexible editing of object types and aesthetic styles in arbitrary regions of input videos while maintaining good temporal consistency across frames. Extensive experiments in various video editing scenarios demonstrate the effectiveness of MagicProp.
MagicEdit: High-Fidelity and Temporally Coherent Video Editing
Aug 28, 2023In this report, we present MagicEdit, a surprisingly simple yet effective solution to the text-guided video editing task. We found that high-fidelity and temporally coherent video-to-video translation can be achieved by explicitly disentangling the learning of content, structure and motion signals during training. This is in contradict to most existing methods which attempt to jointly model both the appearance and temporal representation within a single framework, which we argue, would lead to degradation in per-frame quality. Despite its simplicity, we show that MagicEdit supports various downstream video editing tasks, including video stylization, local editing, video-MagicMix and video outpainting.
MagicAvatar: Multimodal Avatar Generation and Animation
Aug 28, 2023This report presents MagicAvatar, a framework for multimodal video generation and animation of human avatars. Unlike most existing methods that generate avatar-centric videos directly from multimodal inputs (e.g., text prompts), MagicAvatar explicitly disentangles avatar video generation into two stages: (1) multimodal-to-motion and (2) motion-to-video generation. The first stage translates the multimodal inputs into motion/ control signals (e.g., human pose, depth, DensePose); while the second stage generates avatar-centric video guided by these motion signals. Additionally, MagicAvatar supports avatar animation by simply providing a few images of the target person. This capability enables the animation of the provided human identity according to the specific motion derived from the first stage. We demonstrate the flexibility of MagicAvatar through various applications, including text-guided and video-guided avatar generation, as well as multimodal avatar animation.
AdjointDPM: Adjoint Sensitivity Method for Gradient Backpropagation of Diffusion Probabilistic Models
Jul 21, 2023



Existing customization methods require access to multiple reference examples to align pre-trained diffusion probabilistic models (DPMs) with user-provided concepts. This paper aims to address the challenge of DPM customization when the only available supervision is a differentiable metric defined on the generated contents. Since the sampling procedure of DPMs involves recursive calls to the denoising UNet, na\"ive gradient backpropagation requires storing the intermediate states of all iterations, resulting in extremely high memory consumption. To overcome this issue, we propose a novel method AdjointDPM, which first generates new samples from diffusion models by solving the corresponding probability-flow ODEs. It then uses the adjoint sensitivity method to backpropagate the gradients of the loss to the models' parameters (including conditioning signals, network weights, and initial noises) by solving another augmented ODE. To reduce numerical errors in both the forward generation and gradient backpropagation processes, we further reparameterize the probability-flow ODE and augmented ODE as simple non-stiff ODEs using exponential integration. Finally, we demonstrate the effectiveness of AdjointDPM on three interesting tasks: converting visual effects into identification text embeddings, finetuning DPMs for specific types of stylization, and optimizing initial noise to generate adversarial samples for security auditing.
Towards Better Time Series Contrastive Learning: A Dynamic Bad Pair Mining Approach
Feb 07, 2023Not all positive pairs are beneficial to time series contrastive learning. In this paper, we study two types of bad positive pairs that impair the quality of time series representation learned through contrastive learning ($i.e.$, noisy positive pair and faulty positive pair). We show that, with the presence of noisy positive pairs, the model tends to simply learn the pattern of noise (Noisy Alignment). Meanwhile, when faulty positive pairs arise, the model spends considerable efforts aligning non-representative patterns (Faulty Alignment). To address this problem, we propose a Dynamic Bad Pair Mining (DBPM) algorithm, which reliably identifies and suppresses bad positive pairs in time series contrastive learning. DBPM utilizes a memory module to track the training behavior of each positive pair along training process. This allows us to identify potential bad positive pairs at each epoch based on their historical training behaviors. The identified bad pairs are then down-weighted using a transformation module. Our experimental results show that DBPM effectively mitigates the negative impacts of bad pairs, and can be easily used as a plug-in to boost performance of state-of-the-art methods. Codes will be made publicly available.
Towards Adversarial Robustness of Deep Vision Algorithms
Nov 22, 2022Deep learning methods have achieved great success in solving computer vision tasks, and they have been widely utilized in artificially intelligent systems for image processing, analysis, and understanding. However, deep neural networks have been shown to be vulnerable to adversarial perturbations in input data. The security issues of deep neural networks have thus come to the fore. It is imperative to study the adversarial robustness of deep vision algorithms comprehensively. This talk focuses on the adversarial robustness of image classification models and image denoisers. We will discuss the robustness of deep vision algorithms from three perspectives: 1) robustness evaluation (we propose the ObsAtk to evaluate the robustness of denoisers), 2) robustness improvement (HAT, TisODE, and CIFS are developed to robustify vision models), and 3) the connection between adversarial robustness and generalization capability to new domains (we find that adversarially robust denoisers can deal with unseen types of real-world noise).
MagicVideo: Efficient Video Generation With Latent Diffusion Models
Nov 20, 2022



We present an efficient text-to-video generation framework based on latent diffusion models, termed MagicVideo. Given a text description, MagicVideo can generate photo-realistic video clips with high relevance to the text content. With the proposed efficient latent 3D U-Net design, MagicVideo can generate video clips with 256x256 spatial resolution on a single GPU card, which is 64x faster than the recent video diffusion model (VDM). Unlike previous works that train video generation from scratch in the RGB space, we propose to generate video clips in a low-dimensional latent space. We further utilize all the convolution operator weights of pre-trained text-to-image generative U-Net models for faster training. To achieve this, we introduce two new designs to adapt the U-Net decoder to video data: a framewise lightweight adaptor for the image-to-video distribution adjustment and a directed temporal attention module to capture frame temporal dependencies. The whole generation process is within the low-dimension latent space of a pre-trained variation auto-encoder. We demonstrate that MagicVideo can generate both realistic video content and imaginary content in a photo-realistic style with a trade-off in terms of quality and computational cost. Refer to https://magicvideo.github.io/# for more examples.
MagicMix: Semantic Mixing with Diffusion Models
Oct 28, 2022



Have you ever imagined what a corgi-alike coffee machine or a tiger-alike rabbit would look like? In this work, we attempt to answer these questions by exploring a new task called semantic mixing, aiming at blending two different semantics to create a new concept (e.g., corgi + coffee machine -- > corgi-alike coffee machine). Unlike style transfer, where an image is stylized according to the reference style without changing the image content, semantic blending mixes two different concepts in a semantic manner to synthesize a novel concept while preserving the spatial layout and geometry. To this end, we present MagicMix, a simple yet effective solution based on pre-trained text-conditioned diffusion models. Motivated by the progressive generation property of diffusion models where layout/shape emerges at early denoising steps while semantically meaningful details appear at later steps during the denoising process, our method first obtains a coarse layout (either by corrupting an image or denoising from a pure Gaussian noise given a text prompt), followed by injection of conditional prompt for semantic mixing. Our method does not require any spatial mask or re-training, yet is able to synthesize novel objects with high fidelity. To improve the mixing quality, we further devise two simple strategies to provide better control and flexibility over the synthesized content. With our method, we present our results over diverse downstream applications, including semantic style transfer, novel object synthesis, breed mixing, and concept removal, demonstrating the flexibility of our method. More results can be found on the project page https://magicmix.github.io
Towards Adversarially Robust Deep Image Denoising
Jan 13, 2022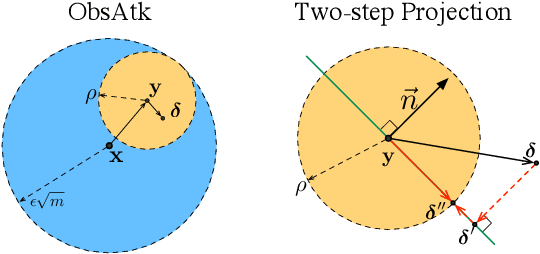
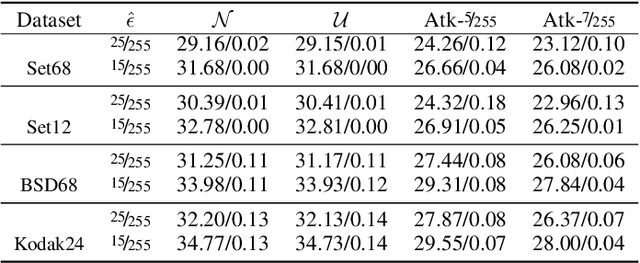

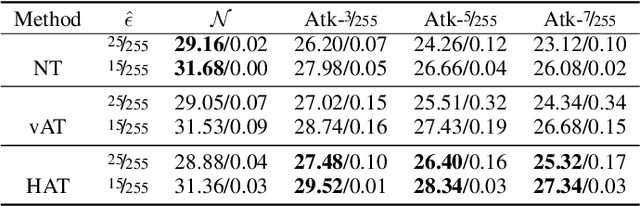
This work systematically investigates the adversarial robustness of deep image denoisers (DIDs), i.e, how well DIDs can recover the ground truth from noisy observations degraded by adversarial perturbations. Firstly, to evaluate DIDs' robustness, we propose a novel adversarial attack, namely Observation-based Zero-mean Attack ({\sc ObsAtk}), to craft adversarial zero-mean perturbations on given noisy images. We find that existing DIDs are vulnerable to the adversarial noise generated by {\sc ObsAtk}. Secondly, to robustify DIDs, we propose an adversarial training strategy, hybrid adversarial training ({\sc HAT}), that jointly trains DIDs with adversarial and non-adversarial noisy data to ensure that the reconstruction quality is high and the denoisers around non-adversarial data are locally smooth. The resultant DIDs can effectively remove various types of synthetic and adversarial noise. We also uncover that the robustness of DIDs benefits their generalization capability on unseen real-world noise. Indeed, {\sc HAT}-trained DIDs can recover high-quality clean images from real-world noise even without training on real noisy data. Extensive experiments on benchmark datasets, including Set68, PolyU, and SIDD, corroborate the effectiveness of {\sc ObsAtk} and {\sc HAT}.
Efficient Sharpness-aware Minimization for Improved Training of Neural Networks
Oct 07, 2021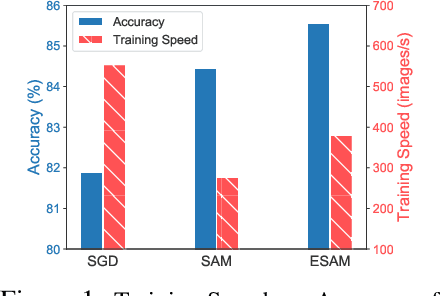
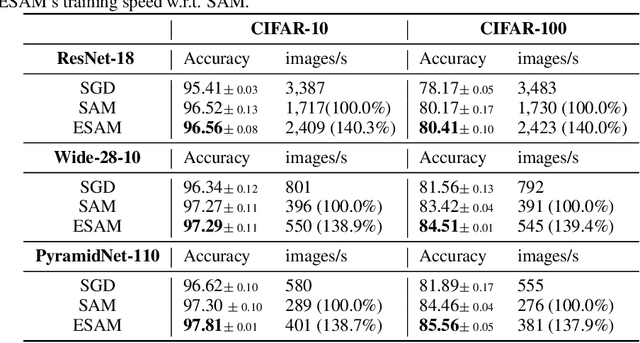
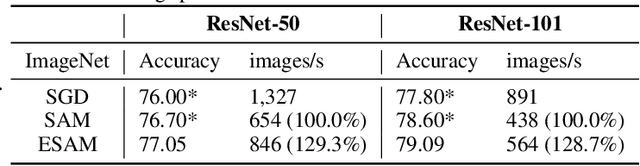
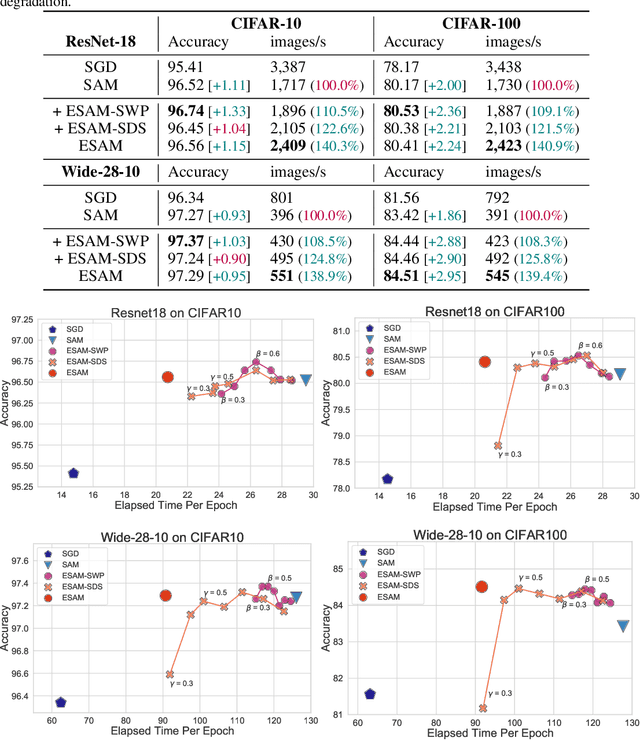
Overparametrized Deep Neural Networks (DNNs) often achieve astounding performances, but may potentially result in severe generalization error. Recently, the relation between the sharpness of the loss landscape and the generalization error has been established by Foret et al. (2020), in which the Sharpness Aware Minimizer (SAM) was proposed to mitigate the degradation of the generalization. Unfortunately, SAM s computational cost is roughly double that of base optimizers, such as Stochastic Gradient Descent (SGD). This paper thus proposes Efficient Sharpness Aware Minimizer (ESAM), which boosts SAM s efficiency at no cost to its generalization performance. ESAM includes two novel and efficient training strategies-StochasticWeight Perturbation and Sharpness-Sensitive Data Selection. In the former, the sharpness measure is approximated by perturbing a stochastically chosen set of weights in each iteration; in the latter, the SAM loss is optimized using only a judiciously selected subset of data that is sensitive to the sharpness. We provide theoretical explanations as to why these strategies perform well. We also show, via extensive experiments on the CIFAR and ImageNet datasets, that ESAM enhances the efficiency over SAM from requiring 100% extra computations to 40% vis-a-vis base optimizers, while test accuracies are preserved or even improved.