 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAFE-GAN: Arbitrary Face Attribute Editing with Complementary Attention Feature
Nov 24, 2020
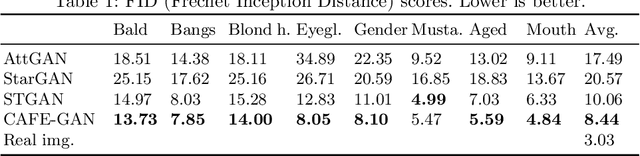

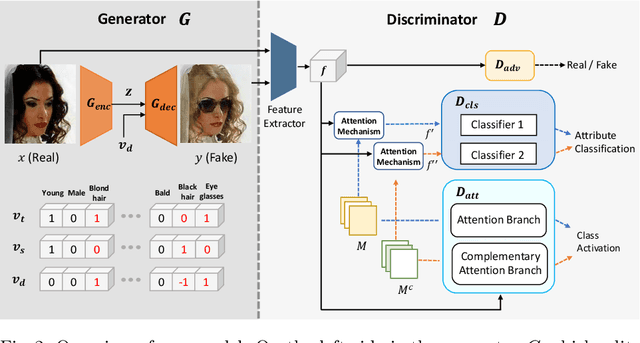
The goal of face attribute editing is altering a facial image according to given target attributes such as hair color, mustache, gender, etc. It belongs to the image-to-image domain transfer problem with a set of attributes considered as a distinctive domain. There have been some works in multi-domain transfer problem focusing on facial attribute editing employing Generative Adversarial Network (GAN). These methods have reported some successes but they also result in unintended changes in facial regions - meaning the generator alters regions unrelated to the specified attributes. To address this unintended altering problem, we propose a novel GAN model which is designed to edit only the parts of a face pertinent to the target attributes by the concept of Complementary Attention Feature (CAFE). CAFE identifies the facial regions to be transformed by considering both target attributes as well as complementary attributes, which we define as those attributes absent in the input facial image. In addition, we introduce a complementary feature matching to help in training the generator for utilizing the spatial information of attributes. Effectiveness of the proposed method is demonstrated by analysis and comparison study with state-of-the-art methods.
COVID-19 CT Image Synthesis with a Conditional Generative Adversarial Network
Jul 29, 2020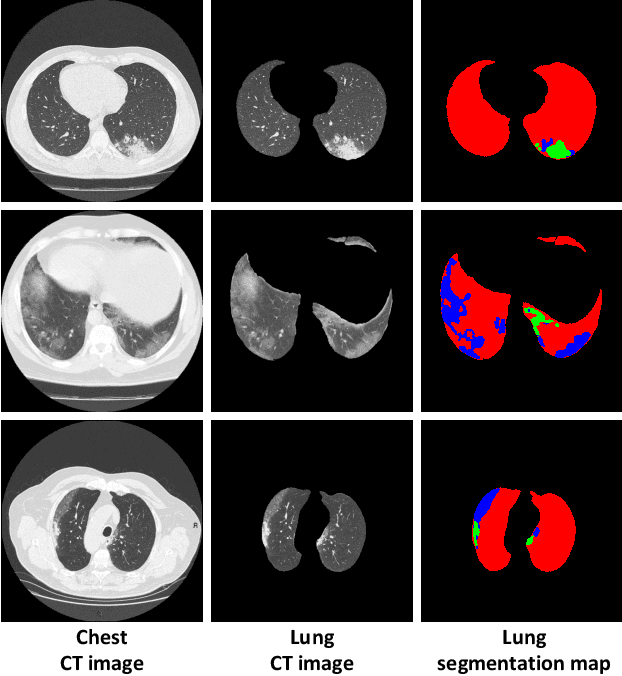
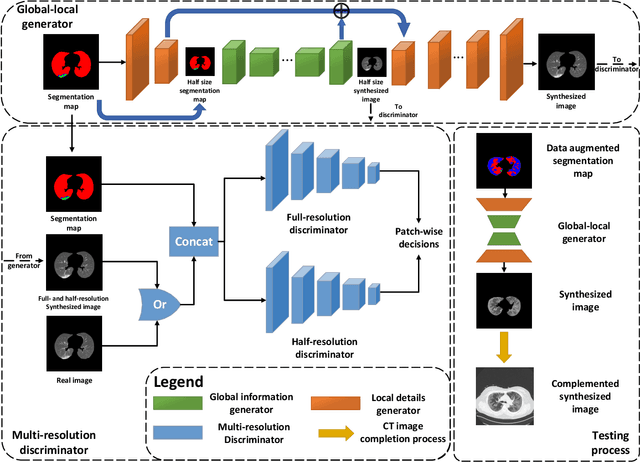
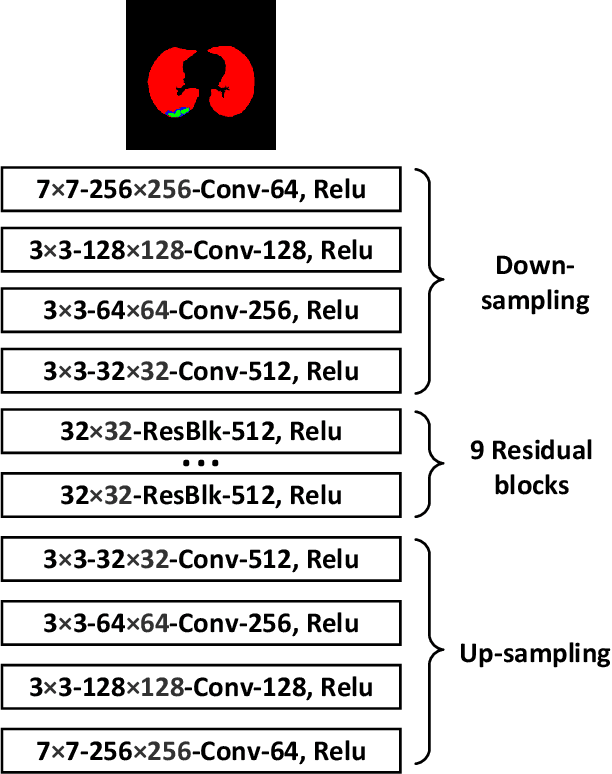
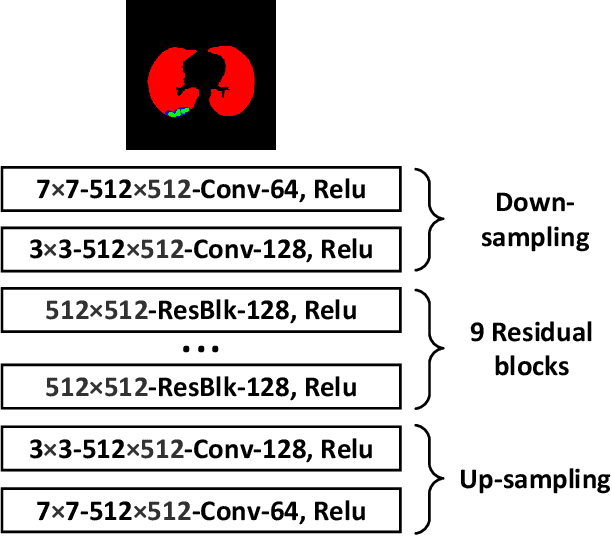
Coronavirus disease 2019 (COVID-19) is an ongoing global pandemic that has spread rapidly since December 2019. Real-time reverse transcription polymerase chain reaction (rRT-PCR) and chest computed tomography (CT) imaging both play an important role in COVID-19 diagnosis. Chest CT imaging offers the benefits of quick reporting, a low cost, and high sensitivity for the detection of pulmonary infection. Recently, deep-learning-based computer vision methods have demonstrated great promise for use in medical imaging applications, including X-rays, magnetic resonance imaging, and CT imaging. However, training a deep-learning model requires large volumes of data, and medical staff faces a high risk when collecting COVID-19 CT data due to the high infectivity of the disease. Another issue is the lack of experts available for data labeling. In order to meet the data requirements for COVID-19 CT imaging, we propose a CT image synthesis approach based on a conditional generative adversarial network that can effectively generate high-quality and realistic COVID-19 CT images for use in deep-learning-based medical imaging tasks. Experimental results show that the proposed method outperforms other state-of-the-art image synthesis methods with the generated COVID-19 CT images and indicates promising for various machine learning applications including semantic segmentation and classification.
Data Separability for Neural Network Classifiers and the Development of a Separability Index
May 29, 2020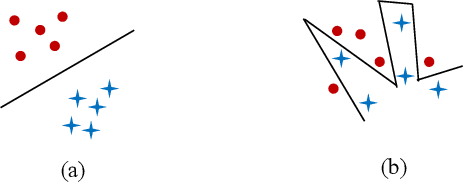
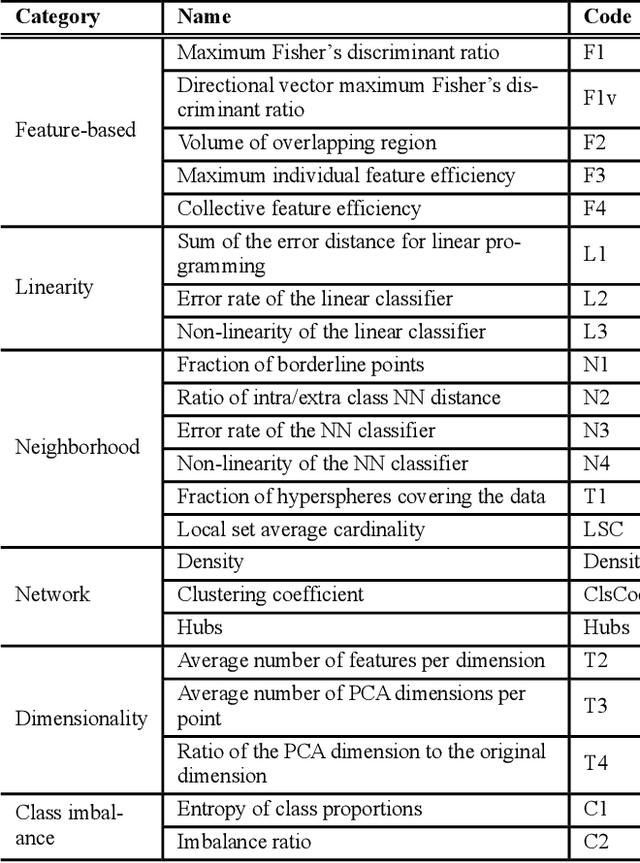
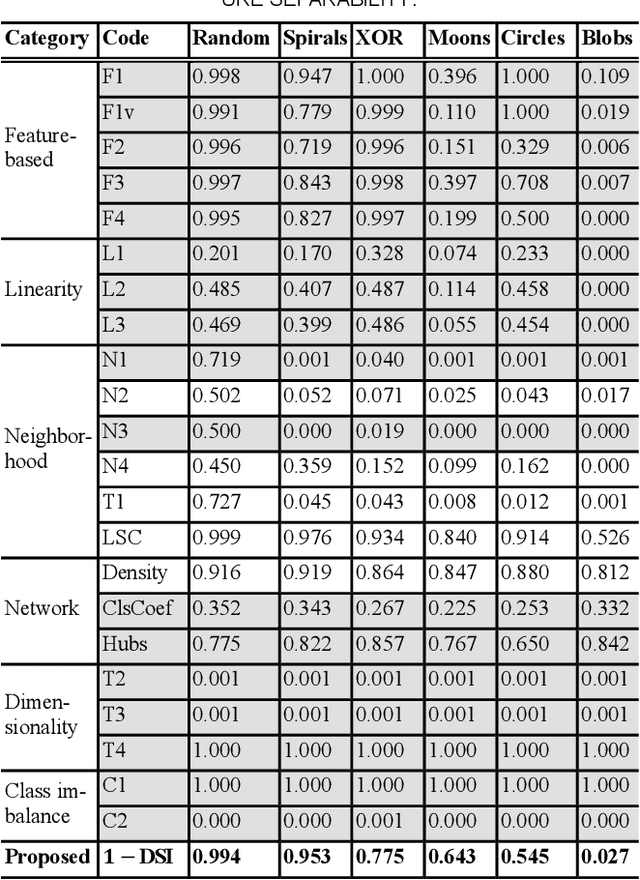
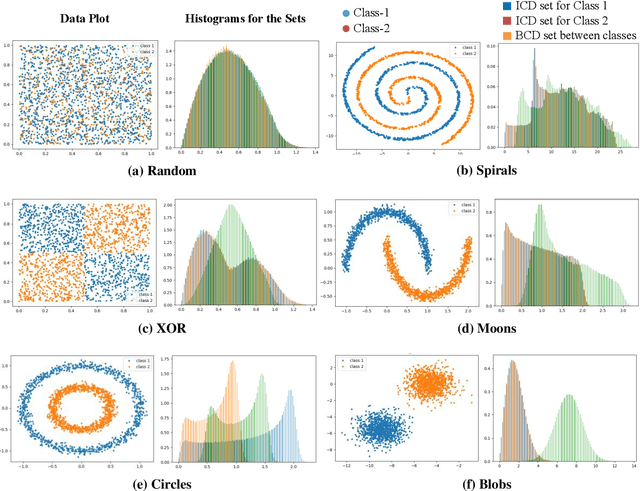
In machine learning, the performance of a classifier depends on both the classifier model and the dataset. For a specific neural network classifier, the training process varies with the training set used; some training data make training accuracy fast converged to high values, while some data may lead to slowly converged to lower accuracy. To quantify this phenomenon, we created the Distance-based Separability Index (DSI), which is independent of the classifier model, to measure the separability of datasets. In this paper, we consider the situation where different classes of data are mixed together in the same distribution is most difficult for classifiers to separate, and we show that the DSI can indicate whether data belonging to different classes have similar distributions. When comparing our proposed approach with several existing separability/complexity measures using synthetic and real datasets, the results show the DSI is an effective separability measure. We also discussed possible applications of the DSI in the fields of data science, machine learning, and deep learning.
NTIRE 2020 Challenge on Real-World Image Super-Resolution: Methods and Results
May 05, 2020
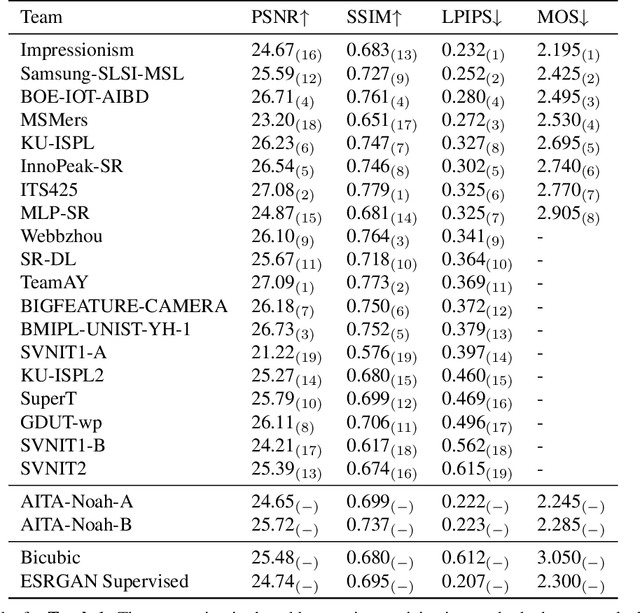
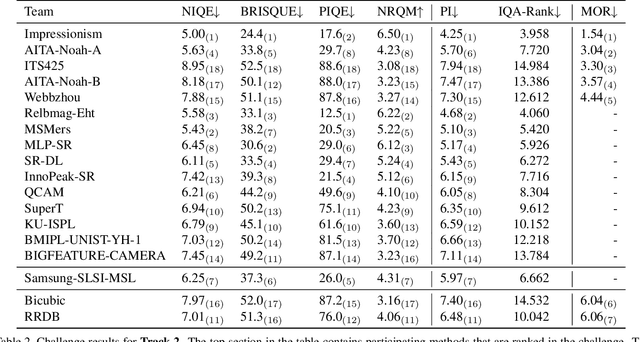

This paper reviews the NTIRE 2020 challenge on real world super-resolution. It focuses on the participating methods and final results. The challenge addresses the real world setting, where paired true high and low-resolution images are unavailable. For training, only one set of source input images is therefore provided along with a set of unpaired high-quality target images. In Track 1: Image Processing artifacts, the aim is to super-resolve images with synthetically generated image processing artifacts. This allows for quantitative benchmarking of the approaches \wrt a ground-truth image. In Track 2: Smartphone Images, real low-quality smart phone images have to be super-resolved. In both tracks, the ultimate goal is to achieve the best perceptual quality, evaluated using a human study. This is the second challenge on the subject, following AIM 2019, targeting to advance the state-of-the-art in super-resolution. To measure the performance we use the benchmark protocol from AIM 2019. In total 22 teams competed in the final testing phase, demonstrating new and innovative solutions to the problem.
Correlation Distance Skip Connection Denoising Autoencoder (CDSK-DAE) for Speech Feature Enhancement
Jul 26, 2019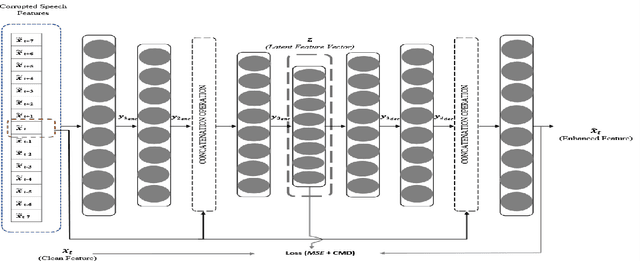

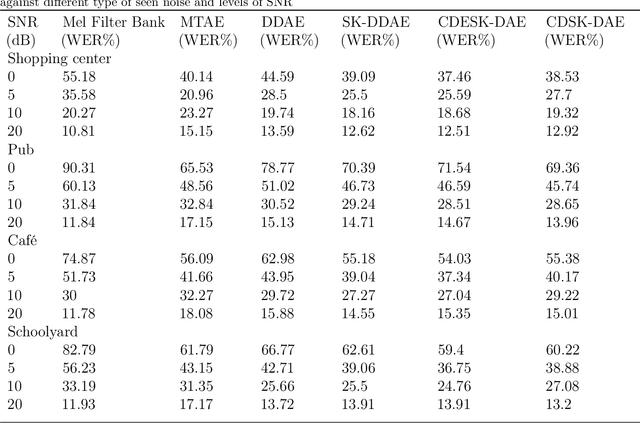
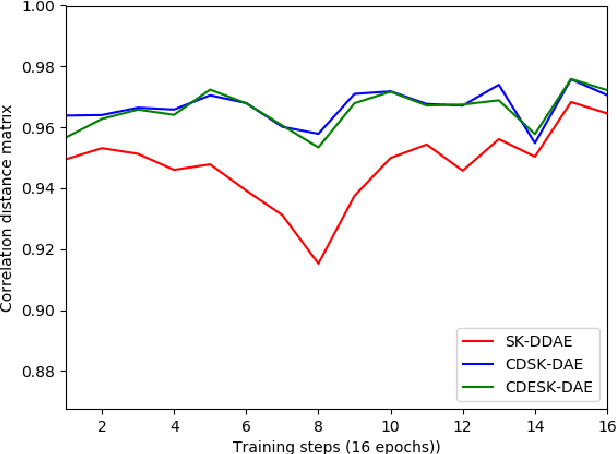
Performance of learning based Automatic Speech Recognition (ASR) is susceptible to noise, especially when it is introduced in the testing data while not presented in the training data. This work focuses on a feature enhancement for noise robust end-to-end ASR system by introducing a novel variant of denoising autoencoder (DAE). The proposed method uses skip connections in both encoder and decoder sides by passing speech information of the target frame from input to the model. It also uses a new objective function in training model that uses a correlation distance measure in penalty terms by measuring dependency of the latent target features and the model (latent features and enhanced features obtained from the DAE). Performance of the proposed method was compared against a conventional model and a state of the art model under both seen and unseen noisy environments of 7 different types of background noise with different SNR levels (0, 5, 10 and 20 dB). The proposed method also is tested using linear and non-linear penalty terms as well, where, they both show an improvement on the overall average WER under noisy conditions both seen and unseen in comparison to the state-of-the-art model.
Sinusoidal wave generating network based on adversarial learning and its application: synthesizing frog sounds for data augmentation
Jan 07, 2019
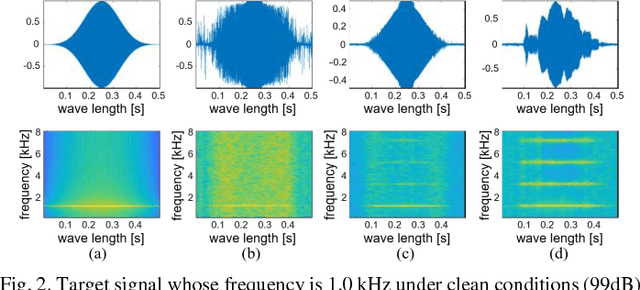
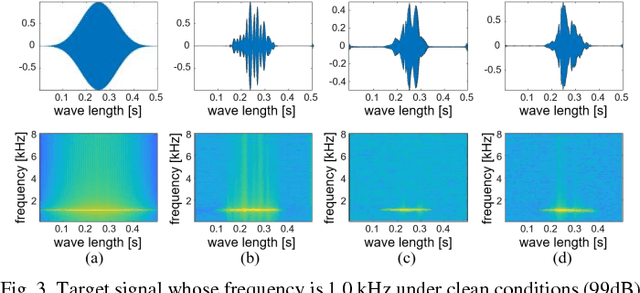
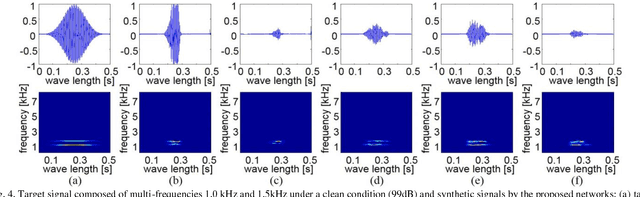
Simulators that generate observations based on theoretical models can be important tools for development, prediction, and assessment of signal processing algorithms. In order to design these simulators, painstaking effort is required to construct mathematical models according to their application. Complex models are sometimes necessary to represent a variety of real phenomena. In contrast, obtaining synthetic observations from generative models developed from real observations often require much less effort. This paper proposes a generative model based on adversarial learning. Given that observations are typically signals composed of a linear combination of sinusoidal waves and random noises, sinusoidal wave generating networks are first designed based on an adversarial network. Audio waveform generation can then be performed using the proposed network. Several approaches to designing the objective function of the proposed network using adversarial learning are investigated experimentally. In addition, amphibian sound classification is performed using a convolutional neural network trained with real and synthetic sounds. Both qualitative and quantitative results show that the proposed generative model makes realistic signals and is very helpful for data augmentation and data analysis.
KU-ISPL Speaker Recognition Systems under Language mismatch condition for NIST 2016 Speaker Recognition Evaluation
Feb 06, 2017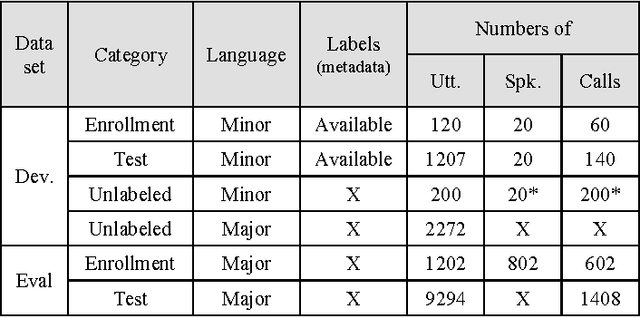
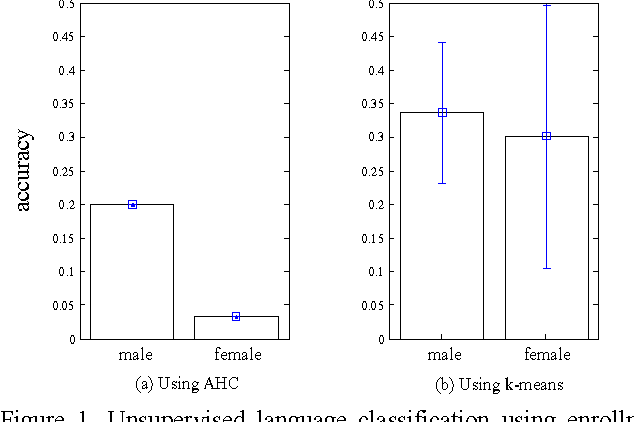
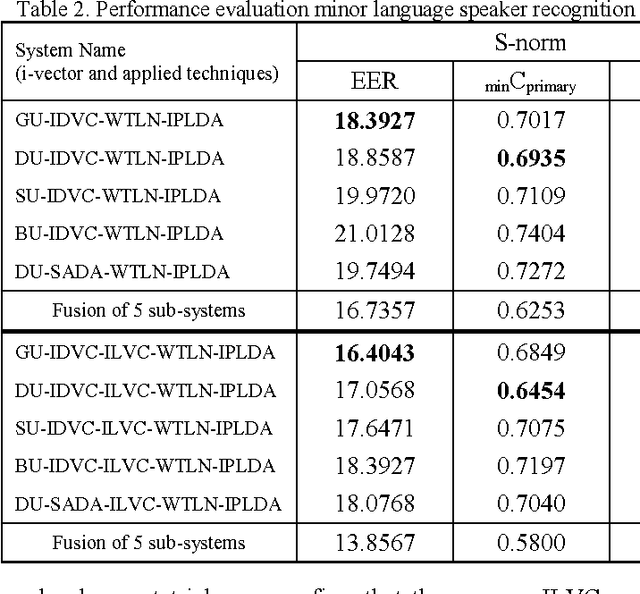
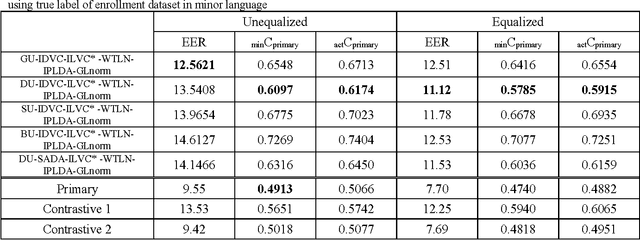
Korea University Intelligent Signal Processing Lab. (KU-ISPL) developed speaker recognition system for SRE16 fixed training condition. Data for evaluation trials are collected from outside North America, spoken in Tagalog and Cantonese while training data only is spoken English. Thus, main issue for SRE16 is compensating the discrepancy between different languages. As development dataset which is spoken in Cebuano and Mandarin, we could prepare the evaluation trials through preliminary experiments to compensate the language mismatched condition. Our team developed 4 different approaches to extract i-vectors and applied state-of-the-art techniques as backend. To compensate language mismatch, we investigated and endeavored unique method such as unsupervised language clustering, inter language variability compensation and gender/language dependent score normalization.
KU-ISPL Language Recognition System for NIST 2015 i-Vector Machine Learning Challenge
Sep 21, 2016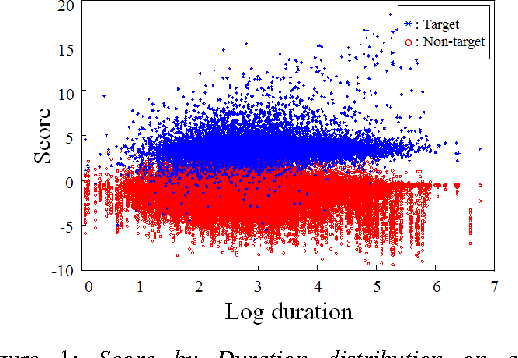

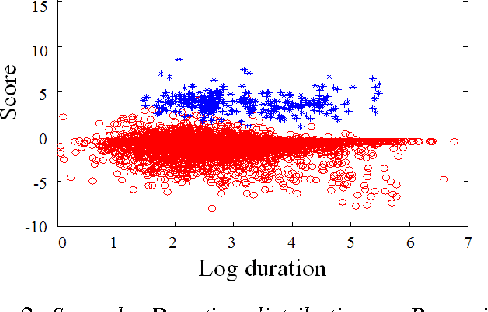
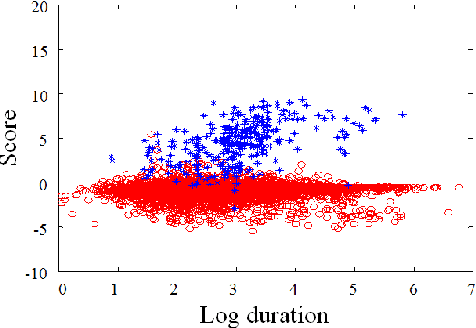
In language recognition, the task of rejecting/differentiating closely spaced versus acoustically far spaced languages remains a major challenge. For confusable closely spaced languages, the system needs longer input test duration material to obtain sufficient information to distinguish between languages. Alternatively, if languages are distinct and not acoustically/linguistically similar to others, duration is not a sufficient remedy. The solution proposed here is to explore duration distribution analysis for near/far languages based on the Language Recognition i-Vector Machine Learning Challenge 2015 (LRiMLC15) database. Using this knowledge, we propose a likelihood ratio based fusion approach that leveraged both score and duration information. The experimental results show that the use of duration and score fusion improves language recognition performance by 5% relative in LRiMLC15 cost.