 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustAnalog: Fast Variation-Aware Analog Circuit Design Via Multi-task RL
Jul 13, 2022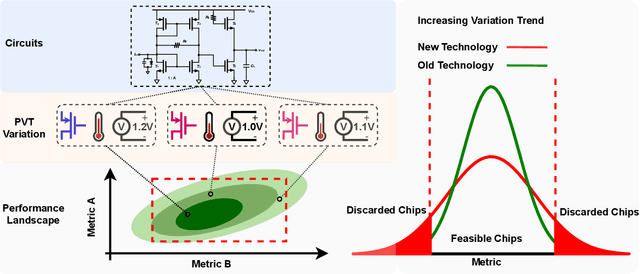
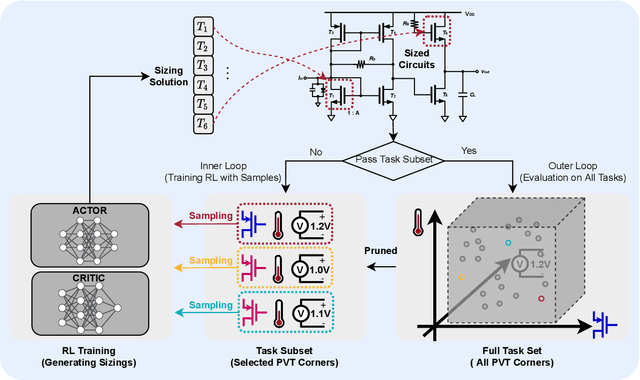
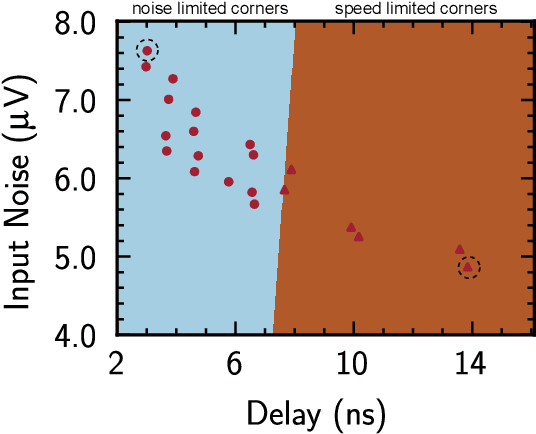
Analog/mixed-signal circuit design is one of the most complex and time-consuming stages in the whole chip design process. Due to various process, voltage, and temperature (PVT) variations from chip manufacturing, analog circuits inevitably suffer from performance degradation. Although there has been plenty of work on automating analog circuit design under the typical condition, limited research has been done on exploring robust designs under real and unpredictable silicon variations. Automatic analog design against variations requires prohibitive computation and time costs. To address the challenge, we present RobustAnalog, a robust circuit design framework that involves the variation information in the optimization process. Specifically, circuit optimizations under different variations are considered as a set of tasks. Similarities among tasks are leveraged and competitions are alleviated to realize a sample-efficient multi-task training. Moreover, RobustAnalog prunes the task space according to the current performance in each iteration, leading to a further simulation cost reduction. In this way, RobustAnalog can rapidly produce a set of circuit parameters that satisfies diverse constraints (e.g. gain, bandwidth, noise...) across variations. We compare RobustAnalog with Bayesian optimization, Evolutionary algorithm, and Deep Deterministic Policy Gradient (DDPG) and demonstrate that RobustAnalog can significantly reduce required optimization time by 14-30 times. Therefore, our study provides a feasible method to handle various real silicon conditions.
Enable Deep Learning on Mobile Devices: Methods, Systems, and Applications
Apr 25, 2022
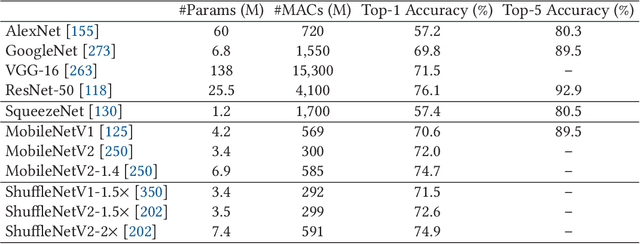
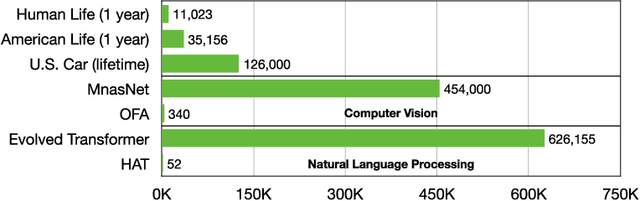
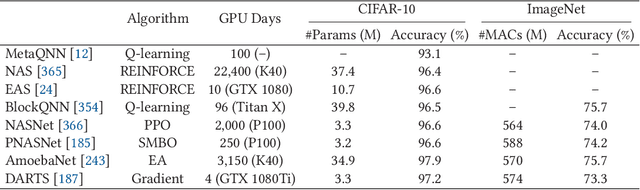
Deep neural networks (DNNs) have achieved unprecedented success in the field of artificial intelligence (AI), including computer vision, natural language processing and speech recognition. However, their superior performance comes at the considerable cost of computational complexity, which greatly hinders their applications in many resource-constrained devices, such as mobile phones and Internet of Things (IoT) devices. Therefore, methods and techniques that are able to lift the efficiency bottleneck while preserving the high accuracy of DNNs are in great demand in order to enable numerous edge AI applications. This paper provides an overview of efficient deep learning methods, systems and applications. We start from introducing popular model compression methods, including pruning, factorization, quantization as well as compact model design. To reduce the large design cost of these manual solutions, we discuss the AutoML framework for each of them, such as neural architecture search (NAS) and automated pruning and quantization. We then cover efficient on-device training to enable user customization based on the local data on mobile devices. Apart from general acceleration techniques, we also showcase several task-specific accelerations for point cloud, video and natural language processing by exploiting their spatial sparsity and temporal/token redundancy. Finally, to support all these algorithmic advancements, we introduce the efficient deep learning system design from both software and hardware perspectives.
* Journal preprint (ACM TODAES, 2021). The first seven authors contributed equally to this work and are listed in the alphabetical order
On-chip QNN: Towards Efficient On-Chip Training of Quantum Neural Networks
Feb 26, 2022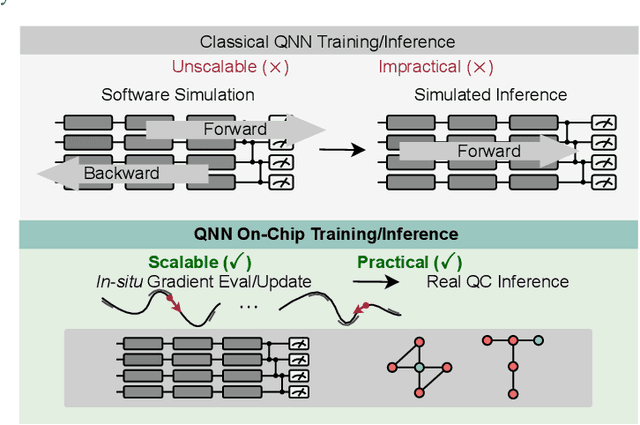
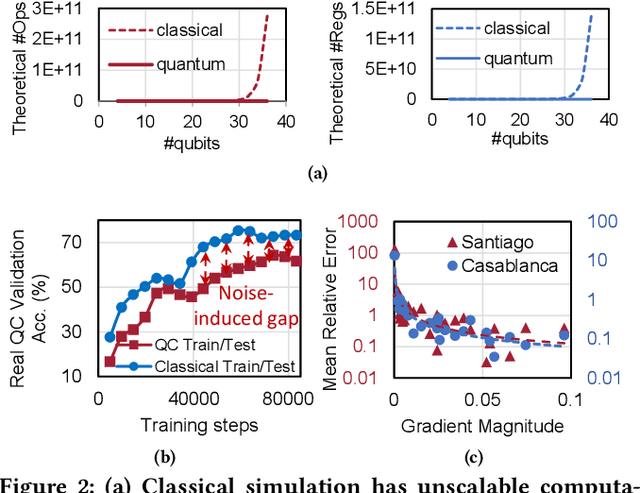

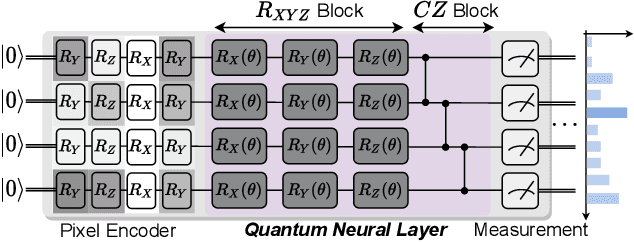
Quantum Neural Network (QNN) is drawing increasing research interest thanks to its potential to achieve quantum advantage on near-term Noisy Intermediate Scale Quantum (NISQ) hardware. In order to achieve scalable QNN learning, the training process needs to be offloaded to real quantum machines instead of using exponential-cost classical simulators. One common approach to obtain QNN gradients is parameter shift whose cost scales linearly with the number of qubits. We present On-chip QNN, the first experimental demonstration of practical on-chip QNN training with parameter shift. Nevertheless, we find that due to the significant quantum errors (noises) on real machines, gradients obtained from naive parameter shift have low fidelity and thus degrade the training accuracy. To this end, we further propose probabilistic gradient pruning to firstly identify gradients with potentially large errors and then remove them. Specifically, small gradients have larger relative errors than large ones, thus having a higher probability to be pruned. We perform extensive experiments on 5 classification tasks with 5 real quantum machines. The results demonstrate that our on-chip training achieves over 90% and 60% accuracy for 2-class and 4-class image classification tasks. The probabilistic gradient pruning brings up to 7% QNN accuracy improvements over no pruning. Overall, we successfully obtain similar on-chip training accuracy compared with noise-free simulation but have much better training scalability. The code for parameter shift on-chip training is available in the TorchQuantum library.
Similarity-based Gray-box Adversarial Attack Against Deep Face Recognition
Jan 12, 2022



The majority of adversarial attack techniques perform well against deep face recognition when the full knowledge of the system is revealed (\emph{white-box}). However, such techniques act unsuccessfully in the gray-box setting where the face templates are unknown to the attackers. In this work, we propose a similarity-based gray-box adversarial attack (SGADV) technique with a newly developed objective function. SGADV utilizes the dissimilarity score to produce the optimized adversarial example, i.e., similarity-based adversarial attack. This technique applies to both white-box and gray-box attacks against authentication systems that determine genuine or imposter users using the dissimilarity score. To validate the effectiveness of SGADV, we conduct extensive experiments on face datasets of LFW, CelebA, and CelebA-HQ against deep face recognition models of FaceNet and InsightFace in both white-box and gray-box settings. The results suggest that the proposed method significantly outperforms the existing adversarial attack techniques in the gray-box setting. We hence summarize that the similarity-base approaches to develop the adversarial example could satisfactorily cater to the gray-box attack scenarios for de-authentication.
RoQNN: Noise-Aware Training for Robust Quantum Neural Networks
Oct 21, 2021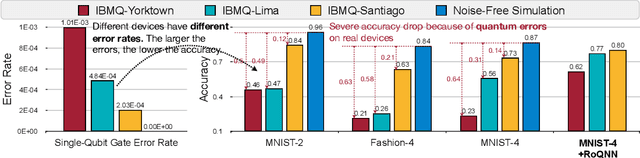
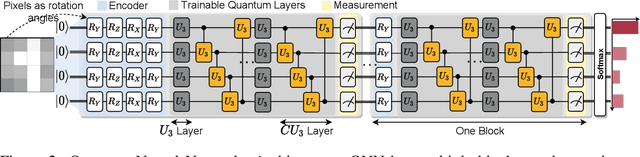
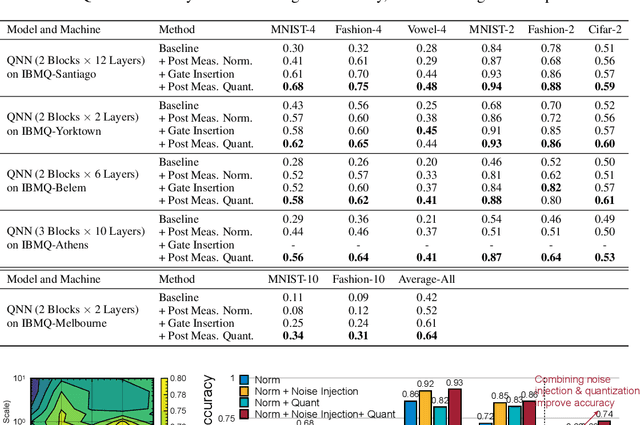

Quantum Neural Network (QNN) is a promising application towards quantum advantage on near-term quantum hardware. However, due to the large quantum noises (errors), the performance of QNN models has a severe degradation on real quantum devices. For example, the accuracy gap between noise-free simulation and noisy results on IBMQ-Yorktown for MNIST-4 classification is over 60%. Existing noise mitigation methods are general ones without leveraging unique characteristics of QNN and are only applicable to inference; on the other hand, existing QNN work does not consider noise effect. To this end, we present RoQNN, a QNN-specific framework to perform noise-aware optimizations in both training and inference stages to improve robustness. We analytically deduct and experimentally observe that the effect of quantum noise to QNN measurement outcome is a linear map from noise-free outcome with a scaling and a shift factor. Motivated by that, we propose post-measurement normalization to mitigate the feature distribution differences between noise-free and noisy scenarios. Furthermore, to improve the robustness against noise, we propose noise injection to the training process by inserting quantum error gates to QNN according to realistic noise models of quantum hardware. Finally, post-measurement quantization is introduced to quantize the measurement outcomes to discrete values, achieving the denoising effect. Extensive experiments on 8 classification tasks using 6 quantum devices demonstrate that RoQNN improves accuracy by up to 43%, and achieves over 94% 2-class, 80% 4-class, and 34% 10-class MNIST classification accuracy measured on real quantum computers. We also open-source our PyTorch library for construction and noise-aware training of QNN at https://github.com/mit-han-lab/pytorch-quantum .
QuantumNAS: Noise-Adaptive Search for Robust Quantum Circuits
Aug 02, 2021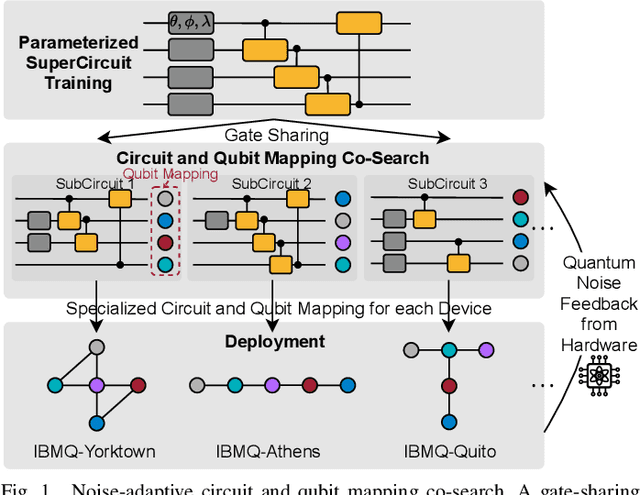
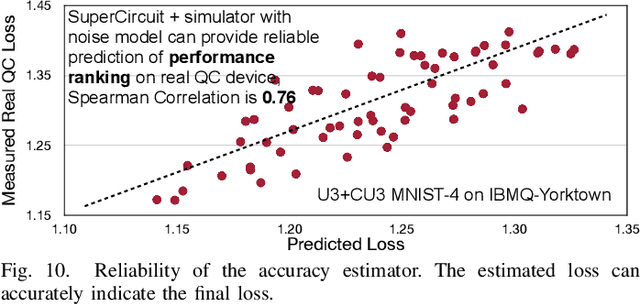
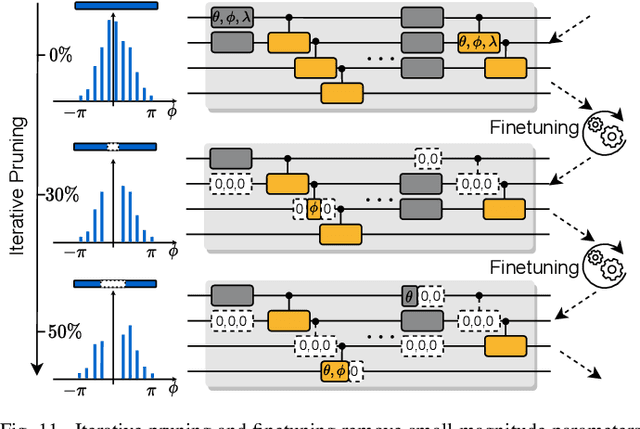
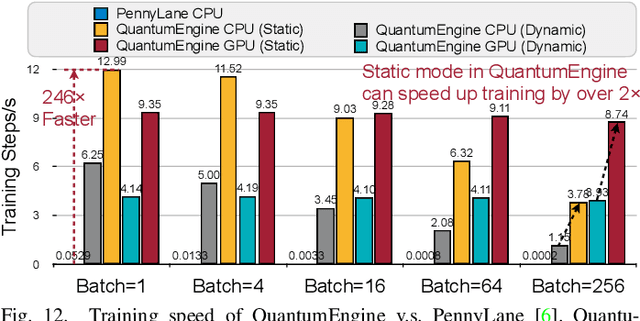
Quantum noise is the key challenge in Noisy Intermediate-Scale Quantum (NISQ) computers. Previous work for mitigating noise has primarily focused on gate-level or pulse-level noise-adaptive compilation. However, limited research efforts have explored a higher level of optimization by making the quantum circuits themselves resilient to noise. We propose QuantumNAS, a comprehensive framework for noise-adaptive co-search of the variational circuit and qubit mapping. Variational quantum circuits are a promising approach for constructing QML and quantum simulation. However, finding the best variational circuit and its optimal parameters is challenging due to the large design space and parameter training cost. We propose to decouple the circuit search and parameter training by introducing a novel SuperCircuit. The SuperCircuit is constructed with multiple layers of pre-defined parameterized gates and trained by iteratively sampling and updating the parameter subsets (SubCircuits) of it. It provides an accurate estimation of SubCircuits performance trained from scratch. Then we perform an evolutionary co-search of SubCircuit and its qubit mapping. The SubCircuit performance is estimated with parameters inherited from SuperCircuit and simulated with real device noise models. Finally, we perform iterative gate pruning and finetuning to remove redundant gates. Extensively evaluated with 12 QML and VQE benchmarks on 10 quantum comput, QuantumNAS significantly outperforms baselines. For QML, QuantumNAS is the first to demonstrate over 95% 2-class, 85% 4-class, and 32% 10-class classification accuracy on real QC. It also achieves the lowest eigenvalue for VQE tasks on H2, H2O, LiH, CH4, BeH2 compared with UCCSD. We also open-source QuantumEngine (https://github.com/mit-han-lab/pytorch-quantum) for fast training of parameterized quantum circuits to facilitate future research.
SpAtten: Efficient Sparse Attention Architecture with Cascade Token and Head Pruning
Jan 04, 2021

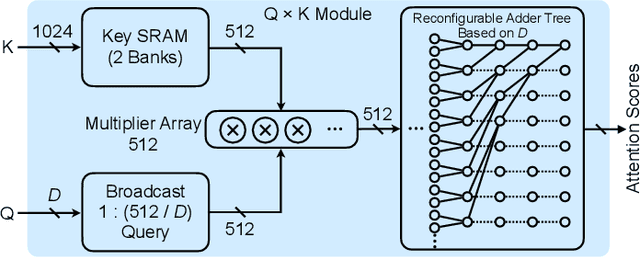
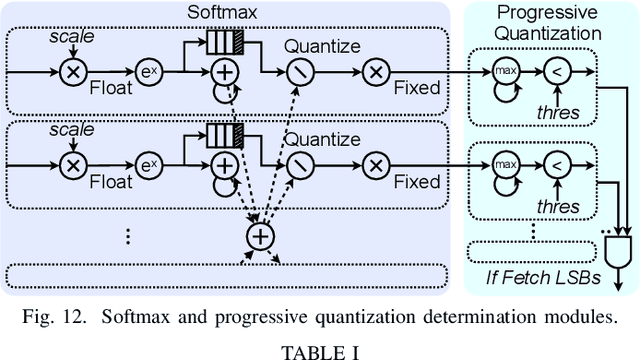
The attention mechanism is becoming increasingly popular in Natural Language Processing (NLP) applications, showing superior performance than convolutional and recurrent architectures. However, general-purpose platforms such as CPUs and GPUs are inefficient when performing attention inference due to complicated data movement and low arithmetic intensity. Moreover, existing NN accelerators mainly focus on optimizing convolutional or recurrent models, and cannot efficiently support attention. In this paper, we present SpAtten, an efficient algorithm-architecture co-design that leverages token sparsity, head sparsity, and quantization opportunities to reduce the attention computation and memory access. Inspired by the high redundancy of human languages, we propose the novel cascade token pruning to prune away unimportant tokens in the sentence. We also propose cascade head pruning to remove unessential heads. Cascade pruning is fundamentally different from weight pruning since there is no trainable weight in the attention mechanism, and the pruned tokens and heads are selected on the fly. To efficiently support them on hardware, we design a novel top-k engine to rank token and head importance scores with high throughput. Furthermore, we propose progressive quantization that first fetches MSBs only and performs the computation; if the confidence is low, it fetches LSBs and recomputes the attention outputs, trading computation for memory reduction. Extensive experiments on 30 benchmarks show that, on average, SpAtten reduces DRAM access by 10.0x with no accuracy loss, and achieves 1.6x, 3.0x, 162x, 347x speedup, and 1,4x, 3.2x, 1193x, 4059x energy savings over A3 accelerator, MNNFast accelerator, TITAN Xp GPU, Xeon CPU, respectively.
Searching Efficient 3D Architectures with Sparse Point-Voxel Convolution
Aug 13, 2020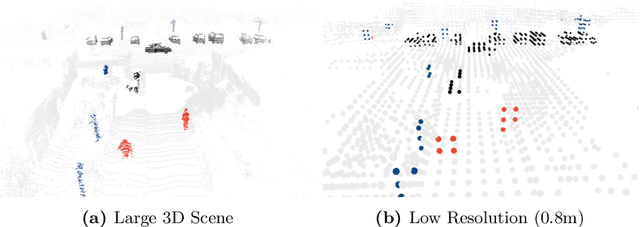
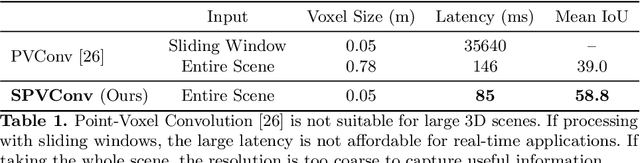
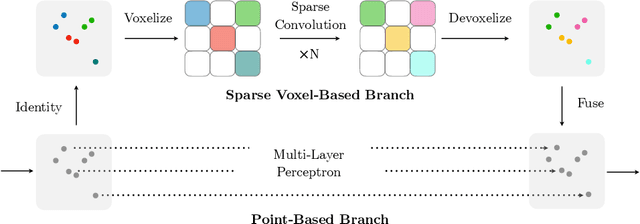
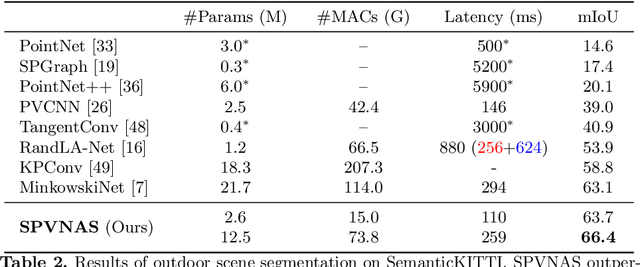
Self-driving cars need to understand 3D scenes efficiently and accurately in order to drive safely. Given the limited hardware resources, existing 3D perception models are not able to recognize small instances (e.g., pedestrians, cyclists) very well due to the low-resolution voxelization and aggressive downsampling. To this end, we propose Sparse Point-Voxel Convolution (SPVConv), a lightweight 3D module that equips the vanilla Sparse Convolution with the high-resolution point-based branch. With negligible overhead, this point-based branch is able to preserve the fine details even from large outdoor scenes. To explore the spectrum of efficient 3D models, we first define a flexible architecture design space based on SPVConv, and we then present 3D Neural Architecture Search (3D-NAS) to search the optimal network architecture over this diverse design space efficiently and effectively. Experimental results validate that the resulting SPVNAS model is fast and accurate: it outperforms the state-of-the-art MinkowskiNet by 3.3%, ranking 1st on the competitive SemanticKITTI leaderboard. It also achieves 8x computation reduction and 3x measured speedup over MinkowskiNet with higher accuracy. Finally, we transfer our method to 3D object detection, and it achieves consistent improvements over the one-stage detection baseline on KITTI.
HAT: Hardware-Aware Transformers for Efficient Natural Language Processing
May 28, 2020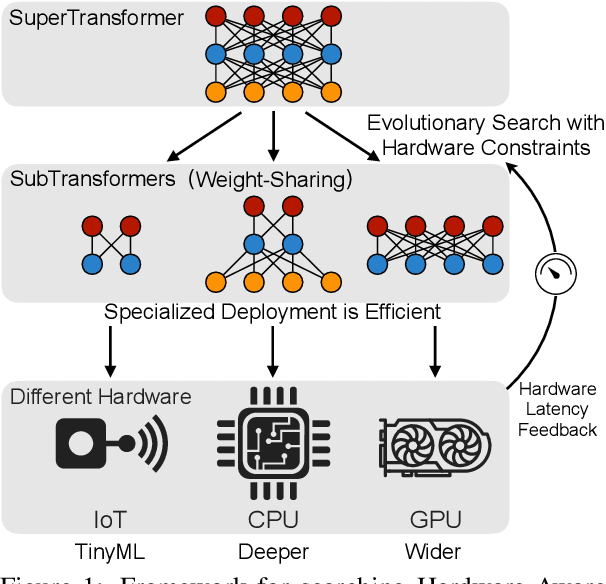
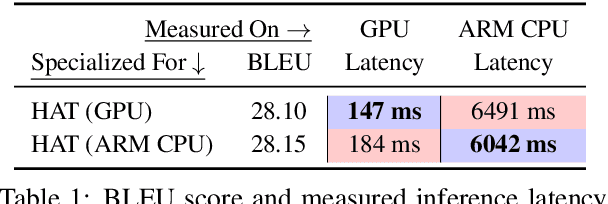
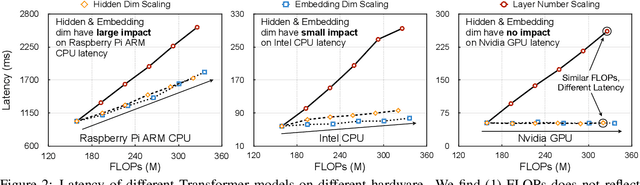
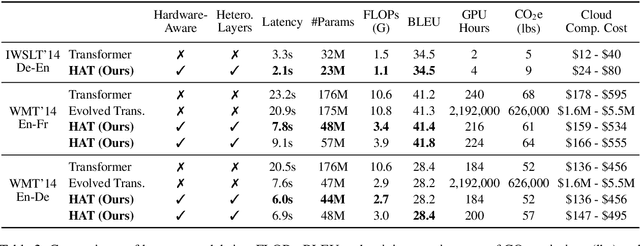
Transformers are ubiquitous in Natural Language Processing (NLP) tasks, but they are difficult to be deployed on hardware due to the intensive computation. To enable low-latency inference on resource-constrained hardware platforms, we propose to design Hardware-Aware Transformers (HAT) with neural architecture search. We first construct a large design space with $\textit{arbitrary encoder-decoder attention}$ and $\textit{heterogeneous layers}$. Then we train a $\textit{SuperTransformer}$ that covers all candidates in the design space, and efficiently produces many $\textit{SubTransformers}$ with weight sharing. Finally, we perform an evolutionary search with a hardware latency constraint to find a specialized $\textit{SubTransformer}$ dedicated to run fast on the target hardware. Extensive experiments on four machine translation tasks demonstrate that HAT can discover efficient models for different hardware (CPU, GPU, IoT device). When running WMT'14 translation task on Raspberry Pi-4, HAT can achieve $\textbf{3}\times$ speedup, $\textbf{3.7}\times$ smaller size over baseline Transformer; $\textbf{2.7}\times$ speedup, $\textbf{3.6}\times$ smaller size over Evolved Transformer with $\textbf{12,041}\times$ less search cost and no performance loss. HAT code is https://github.com/mit-han-lab/hardware-aware-transformers.git
MicroNet for Efficient Language Modeling
May 16, 2020
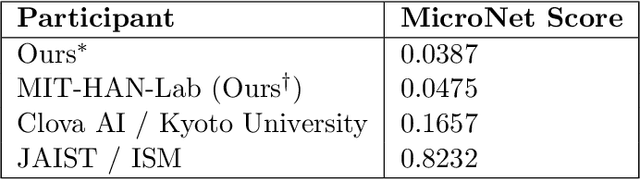

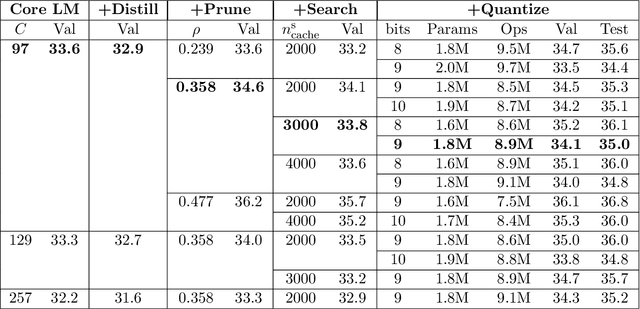
It is important to design compact language models for efficient deployment. We improve upon recent advances in both the language modeling domain and the model-compression domain to construct parameter and computation efficient language models. We use an efficient transformer-based architecture with adaptive embedding and softmax, differentiable non-parametric cache, Hebbian softmax, knowledge distillation, network pruning, and low-bit quantization. In this paper, we provide the winning solution to the NeurIPS 2019 MicroNet Challenge in the language modeling track. Compared to the baseline language model provided by the MicroNet Challenge, our model is 90 times more parameter-efficient and 36 times more computation-efficient while achieving the required test perplexity of 35 on the Wikitext-103 dataset. We hope that this work will aid future research into efficient language models, and we have released our full source code at https://github.com/mit-han-lab/neurips-micronet.