 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Driven Universal Model Inversion Attack for Face Recognition
Paper and Code
Apr 25, 2025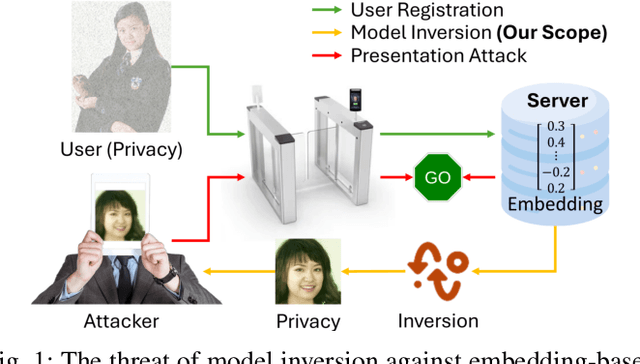
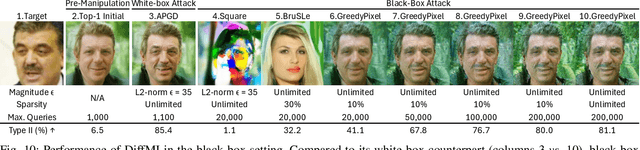
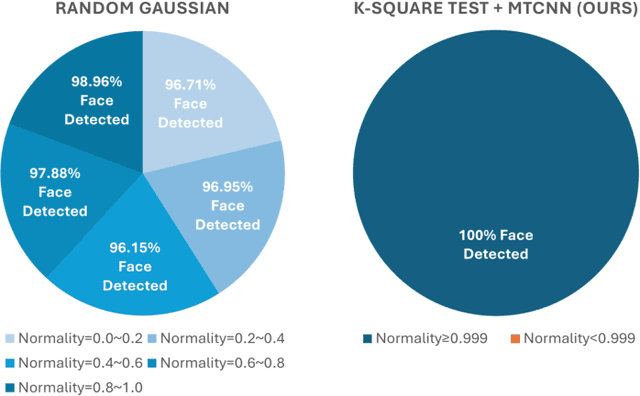
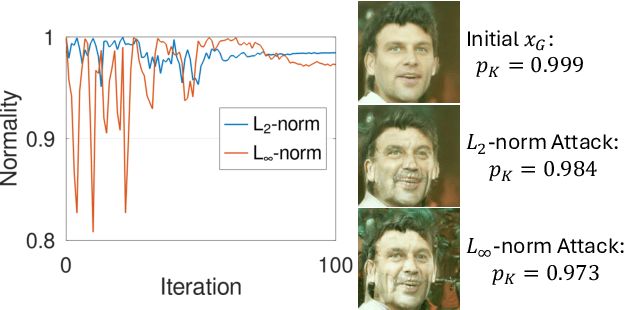
Facial recognition technology poses significant privacy risks, as it relies on biometric data that is inherently sensitive and immutable if compromised. To mitigate these concerns, face recognition systems convert raw images into embeddings, traditionally considered privacy-preserving. However, model inversion attacks pose a significant privacy threat by reconstructing these private facial images, making them a crucial tool for evaluating the privacy risks of face recognition systems. Existing methods usually require training individual generators for each target model, a computationally expensive process. In this paper, we propose DiffUMI, a training-free diffusion-driven universal model inversion attack for face recognition systems. DiffUMI is the first approach to apply a diffusion model for unconditional image generation in model inversion. Unlike other methods, DiffUMI is universal, eliminating the need for training target-specific generators. It operates within a fixed framework and pretrained diffusion model while seamlessly adapting to diverse target identities and models. DiffUMI breaches privacy-preserving face recognition systems with state-of-the-art success, demonstrating that an unconditional diffusion model, coupled with optimized adversarial search, enables efficient and high-fidelity facial reconstruction. Additionally, we introduce a novel application of out-of-domain detection (OODD), marking the first use of model inversion to distinguish non-face inputs from face inputs based solely on embeddings.