 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Gradient Bias in Multi-objective Learning: A Provably Convergent Stochastic Approach
Oct 23, 2022Machine learning problems with multiple objective functions appear either in learning with multiple criteria where learning has to make a trade-off between multiple performance metrics such as fairness, safety and accuracy; or, in multi-task learning where multiple tasks are optimized jointly, sharing inductive bias between them. This problems are often tackled by the multi-objective optimization framework. However, existing stochastic multi-objective gradient methods and its variants (e.g., MGDA, PCGrad, CAGrad, etc.) all adopt a biased noisy gradient direction, which leads to degraded empirical performance. To this end, we develop a stochastic Multi-objective gradient Correction (MoCo) method for multi-objective optimization. The unique feature of our method is that it can guarantee convergence without increasing the batch size even in the non-convex setting. Simulations on multi-task supervised and reinforcement learning demonstrate the effectiveness of our method relative to state-of-the-art methods.
A Single-Timescale Analysis For Stochastic Approximation With Multiple Coupled Sequences
Jun 21, 2022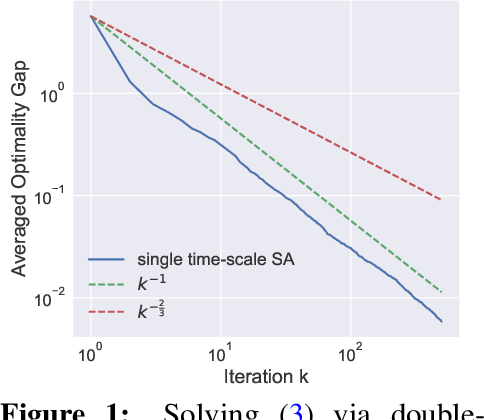

Stochastic approximation (SA) with multiple coupled sequences has found broad applications in machine learning such as bilevel learning and reinforcement learning (RL). In this paper, we study the finite-time convergence of nonlinear SA with multiple coupled sequences. Different from existing multi-timescale analysis, we seek for scenarios where a fine-grained analysis can provide the tight performance guarantee for multi-sequence single-timescale SA (STSA). At the heart of our analysis is the smoothness property of the fixed points in multi-sequence SA that holds in many applications. When all sequences have strongly monotone increments, we establish the iteration complexity of $\mathcal{O}(\epsilon^{-1})$ to achieve $\epsilon$-accuracy, which improves the existing $\mathcal{O}(\epsilon^{-1.5})$ complexity for two coupled sequences. When all but the main sequence have strongly monotone increments, we establish the iteration complexity of $\mathcal{O}(\epsilon^{-2})$. The merit of our results lies in that applying them to stochastic bilevel and compositional optimization problems, as well as RL problems leads to either relaxed assumptions or improvements over their existing performance guarantees.
Asynchronous Advantage Actor Critic: Non-asymptotic Analysis and Linear Speedup
Dec 31, 2020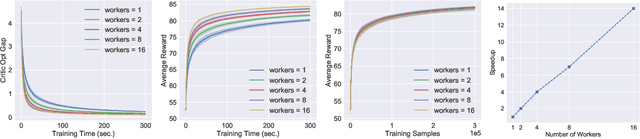
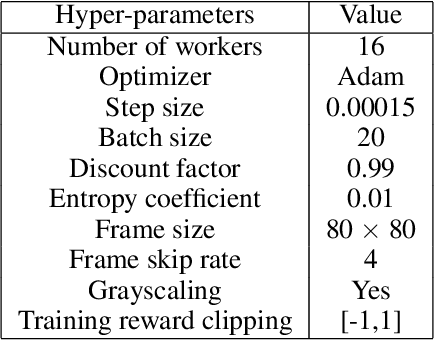
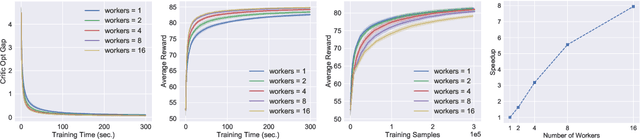
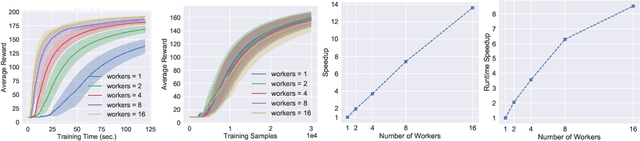
Asynchronous and parallel implementation of standard reinforcement learning (RL) algorithms is a key enabler of the tremendous success of modern RL. Among many asynchronous RL algorithms, arguably the most popular and effective one is the asynchronous advantage actor-critic (A3C) algorithm. Although A3C is becoming the workhorse of RL, its theoretical properties are still not well-understood, including the non-asymptotic analysis and the performance gain of parallelism (a.k.a. speedup). This paper revisits the A3C algorithm with TD(0) for the critic update, termed A3C-TD(0), with provable convergence guarantees. With linear value function approximation for the TD update, the convergence of A3C-TD(0) is established under both i.i.d. and Markovian sampling. Under i.i.d. sampling, A3C-TD(0) obtains sample complexity of $\mathcal{O}(\epsilon^{-2.5}/N)$ per worker to achieve $\epsilon$ accuracy, where $N$ is the number of workers. Compared to the best-known sample complexity of $\mathcal{O}(\epsilon^{-2.5})$ for two-timescale AC, A3C-TD(0) achieves \emph{linear speedup}, which justifies the advantage of parallelism and asynchrony in AC algorithms theoretically for the first time. Numerical tests on synthetically generated instances and OpenAI Gym environments have been provided to verify our theoretical analysis.
Multi-object Tracking via End-to-end Tracklet Searching and Ranking
Mar 04, 2020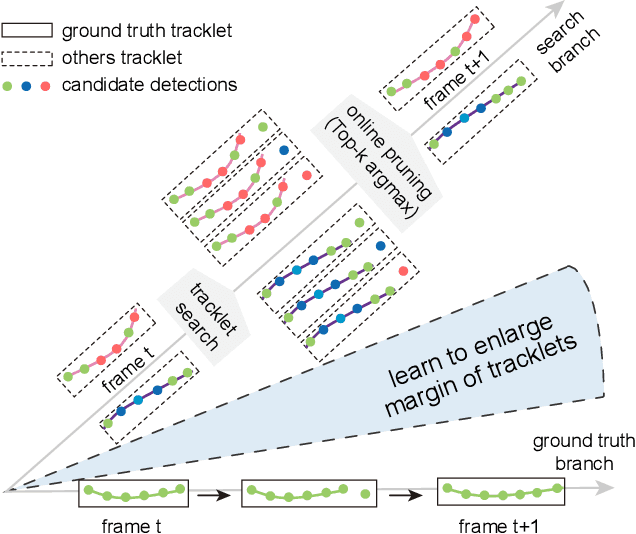

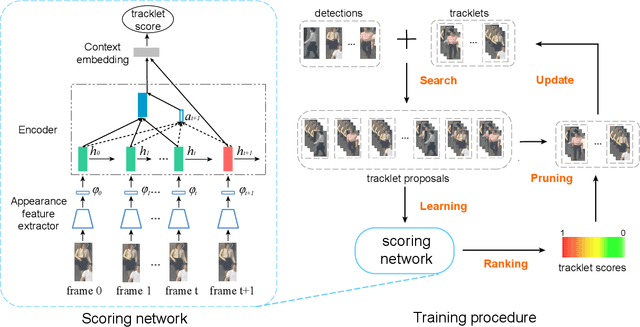
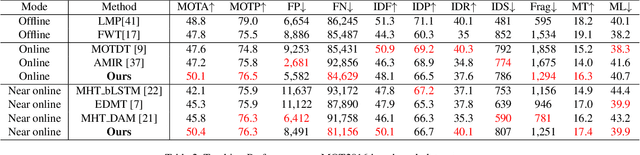
Recent works in multiple object tracking use sequence model to calculate the similarity score between the detections and the previous tracklets. However, the forced exposure to ground-truth in the training stage leads to the training-inference discrepancy problem, i.e., exposure bias, where association error could accumulate in the inference and make the trajectories drift. In this paper, we propose a novel method for optimizing tracklet consistency, which directly takes the prediction errors into account by introducing an online, end-to-end tracklet search training process. Notably, our methods directly optimize the whole tracklet score instead of pairwise affinity. With sequence model as appearance encoders of tracklet, our tracker achieves remarkable performance gain from conventional tracklet association baseline. Our methods have also achieved state-of-the-art in MOT15~17 challenge benchmarks using public detection and online settings.
Adaptive Temporal Difference Learning with Linear Function Approximation
Feb 20, 2020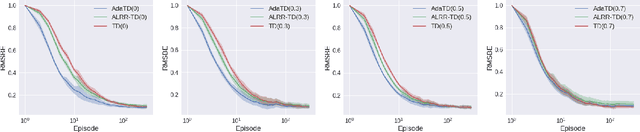
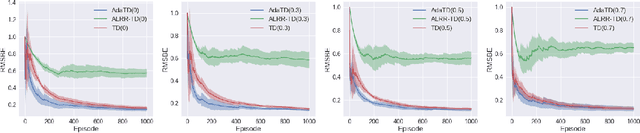
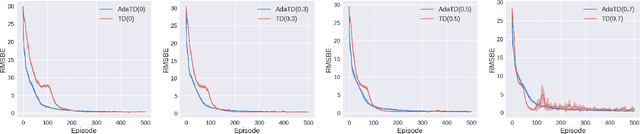
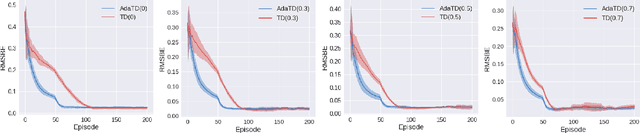
This paper revisits the celebrated temporal difference (TD) learning algorithm for the policy evaluation in reinforcement learning. Typically, the performance of the plain-vanilla TD algorithm is sensitive to the choice of stepsizes. Oftentimes, TD suffers from slow convergence. Motivated by the tight connection between the TD learning algorithm and the stochastic gradient methods, we develop the first adaptive variant of the TD learning algorithm with linear function approximation that we term AdaTD. In contrast to the original TD, AdaTD is robust or less sensitive to the choice of stepsizes. Analytically, we establish that to reach an $\epsilon$ accuracy, the number of iterations needed is $\tilde{O}(\epsilon^2\ln^4\frac{1}{\epsilon}/\ln^4\frac{1}{\rho})$, where $\rho$ represents the speed of the underlying Markov chain converges to the stationary distribution. This implies that the iteration complexity of AdaTD is no worse than that of TD in the worst case. Going beyond TD, we further develop an adaptive variant of TD($\lambda$), which is referred to as AdaTD($\lambda$). We evaluate the empirical performance of AdaTD and AdaTD($\lambda$) on several standard reinforcement learning tasks in OpenAI Gym on both linear and nonlinear function approximation, which demonstrate the effectiveness of our new approaches over existing ones.
Real Time Visual Tracking using Spatial-Aware Temporal Aggregation Network
Aug 02, 2019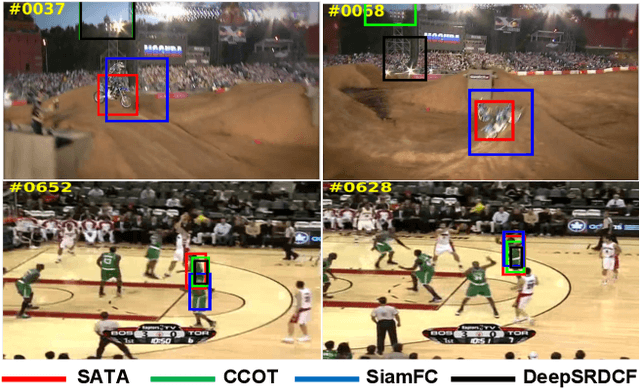
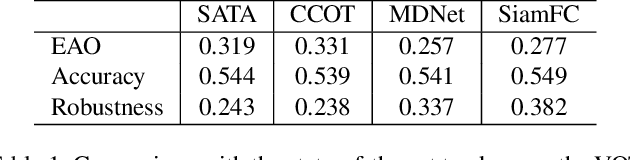
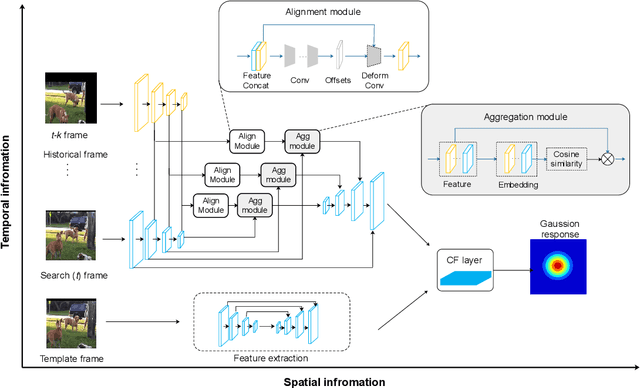

More powerful feature representations derived from deep neural networks benefit visual tracking algorithms widely. However, the lack of exploitation on temporal information prevents tracking algorithms from adapting to appearances changing or resisting to drift. This paper proposes a correlation filter based tracking method which aggregates historical features in a spatial-aligned and scale-aware paradigm. The features of historical frames are sampled and aggregated to search frame according to a pixel-level alignment module based on deformable convolutions. In addition, we also use a feature pyramid structure to handle motion estimation at different scales, and address the different demands on feature granularity between tracking losses and deformation offset learning. By this design, the tracker, named as Spatial-Aware Temporal Aggregation network (SATA), is able to assemble appearances and motion contexts of various scales in a time period, resulting in better performance compared to a single static image. Our tracker achieves leading performance in OTB2013, OTB2015, VOT2015, VOT2016 and LaSOT, and operates at a real-time speed of 26 FPS, which indicates our method is effective and practical. Our code will be made publicly available at \href{https://github.com/ecart18/SATA}{https://github.com/ecart18/SATA}.
Object Detection in Video with Spatial-temporal Context Aggregation
Jul 11, 2019

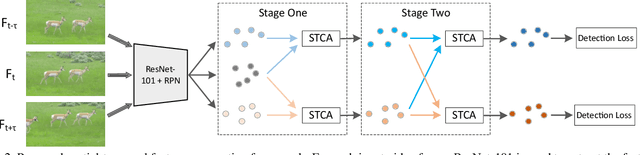

Recent cutting-edge feature aggregation paradigms for video object detection rely on inferring feature correspondence. The feature correspondence estimation problem is fundamentally difficult due to poor image quality, motion blur, etc, and the results of feature correspondence estimation are unstable. To avoid the problem, we propose a simple but effective feature aggregation framework which operates on the object proposal-level. It learns to enhance each proposal's feature via modeling semantic and spatio-temporal relationships among object proposals from both within a frame and across adjacent frames. Experiments are carried out on the ImageNet VID dataset. Without any bells and whistles, our method obtains 80.3\% mAP on the ImageNet VID dataset, which is superior over the previous state-of-the-arts. The proposed feature aggregation mechanism improves the single frame Faster RCNN baseline by 5.8% mAP. Besides, under the setting of no temporal post-processing, our method outperforms the previous state-of-the-art by 1.4% mAP.
Proposal, Tracking and Segmentation (PTS): A Cascaded Network for Video Object Segmentation
Jul 04, 2019
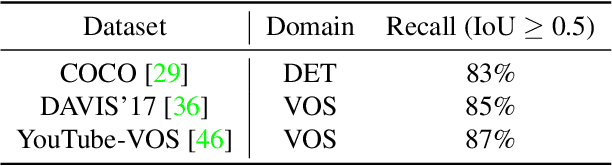
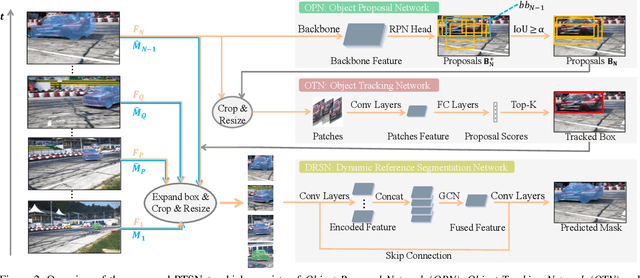
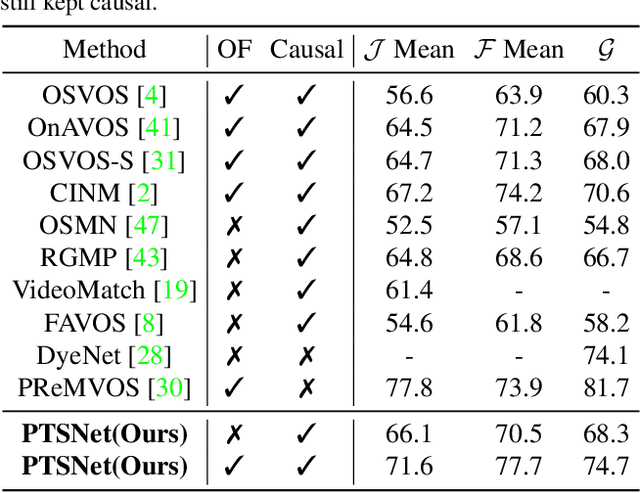
Video object segmentation (VOS) aims at pixel-level object tracking given only the annotations in the first frame. Due to the large visual variations of objects in video and the lack of training samples, it remains a difficult task despite the upsurging development of deep learning. Toward solving the VOS problem, we bring in several new insights by the proposed unified framework consisting of object proposal, tracking and segmentation components. The object proposal network transfers objectness information as generic knowledge into VOS; the tracking network identifies the target object from the proposals; and the segmentation network is performed based on the tracking results with a novel dynamic-reference based model adaptation scheme. Extensive experiments have been conducted on the DAVIS'17 dataset and the YouTube-VOS dataset, our method achieves the state-of-the-art performance on several video object segmentation benchmarks. We make the code publicly available at https://github.com/sydney0zq/PTSNet.
Tracklet Association Tracker: An End-to-End Learning-based Association Approach for Multi-Object Tracking
Aug 05, 2018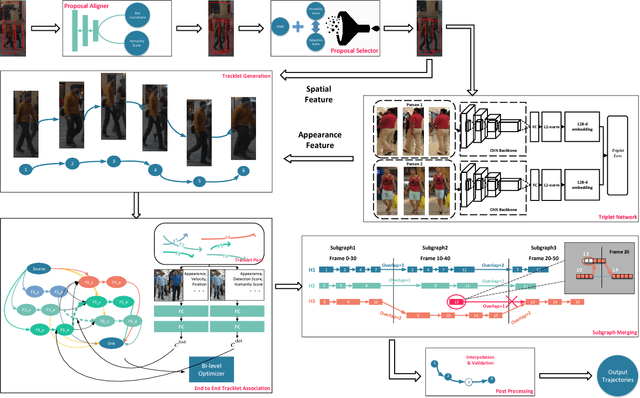
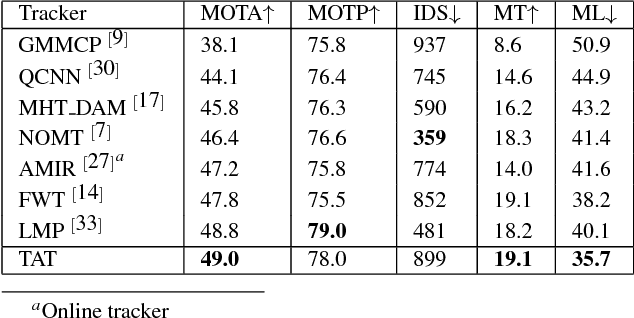

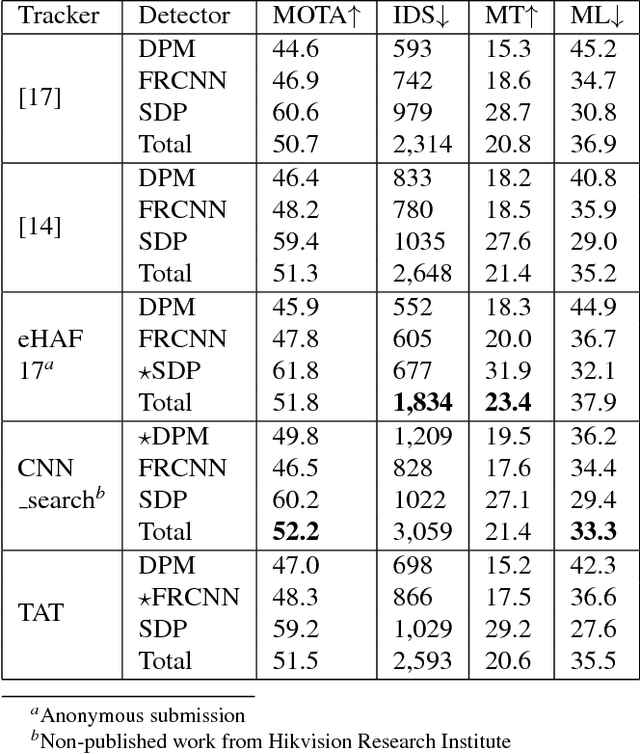
Traditional multiple object tracking methods divide the task into two parts: affinity learning and data association. The separation of the task requires to define a hand-crafted training goal in affinity learning stage and a hand-crafted cost function of data association stage, which prevents the tracking goals from learning directly from the feature. In this paper, we present a new multiple object tracking (MOT) framework with data-driven association method, named as Tracklet Association Tracker (TAT). The framework aims at gluing feature learning and data association into a unity by a bi-level optimization formulation so that the association results can be directly learned from features. To boost the performance, we also adopt the popular hierarchical association and perform the necessary alignment and selection of raw detection responses. Our model trains over 20X faster than a similar approach, and achieves the state-of-the-art performance on both MOT2016 and MOT2017 benchmarks.