 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-training with Demonstration Retrieval for Efficient Few-shot Learning
Jun 30, 2023



Large language models show impressive results on few-shot NLP tasks. However, these models are memory and computation-intensive. Meta-training allows one to leverage smaller models for few-shot generalization in a domain-general and task-agnostic manner; however, these methods alone results in models that may not have sufficient parameterization or knowledge to adapt quickly to a large variety of tasks. To overcome this issue, we propose meta-training with demonstration retrieval, where we use a dense passage retriever to retrieve semantically similar labeled demonstrations to each example for more varied supervision. By separating external knowledge from model parameters, we can use meta-training to train parameter-efficient models that generalize well on a larger variety of tasks. We construct a meta-training set from UnifiedQA and CrossFit, and propose a demonstration bank based on UnifiedQA tasks. To our knowledge, our work is the first to combine retrieval with meta-training, to use DPR models to retrieve demonstrations, and to leverage demonstrations from many tasks simultaneously, rather than randomly sampling demonstrations from the training set of the target task. Our approach outperforms a variety of targeted parameter-efficient and retrieval-augmented few-shot methods on QA, NLI, and text classification tasks (including SQuAD, QNLI, and TREC). Our approach can be meta-trained and fine-tuned quickly on a single GPU.
Defending Against Patch-based Backdoor Attacks on Self-Supervised Learning
Apr 04, 2023



Recently, self-supervised learning (SSL) was shown to be vulnerable to patch-based data poisoning backdoor attacks. It was shown that an adversary can poison a small part of the unlabeled data so that when a victim trains an SSL model on it, the final model will have a backdoor that the adversary can exploit. This work aims to defend self-supervised learning against such attacks. We use a three-step defense pipeline, where we first train a model on the poisoned data. In the second step, our proposed defense algorithm (PatchSearch) uses the trained model to search the training data for poisoned samples and removes them from the training set. In the third step, a final model is trained on the cleaned-up training set. Our results show that PatchSearch is an effective defense. As an example, it improves a model's accuracy on images containing the trigger from 38.2% to 63.7% which is very close to the clean model's accuracy, 64.6%. Moreover, we show that PatchSearch outperforms baselines and state-of-the-art defense approaches including those using additional clean, trusted data. Our code is available at https://github.com/UCDvision/PatchSearch
FRAME: Evaluating Simulatability Metrics for Free-Text Rationales
Jul 02, 2022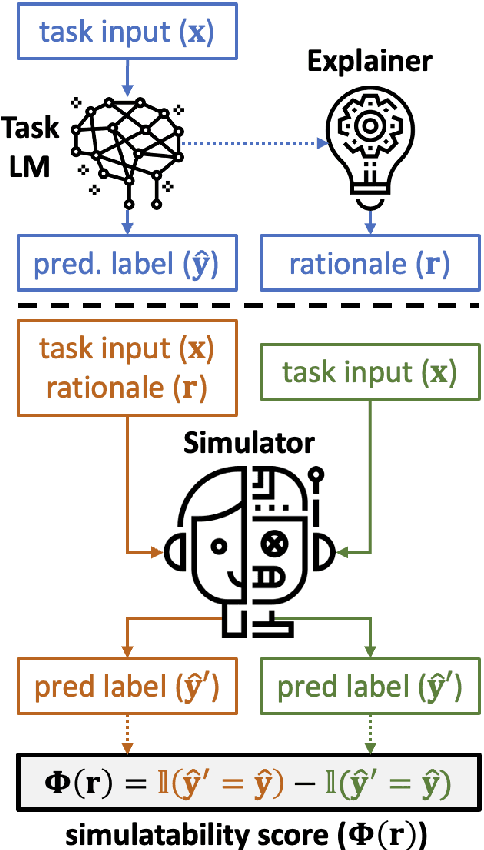
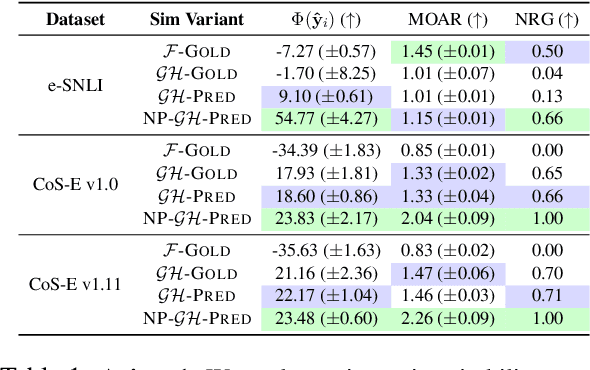

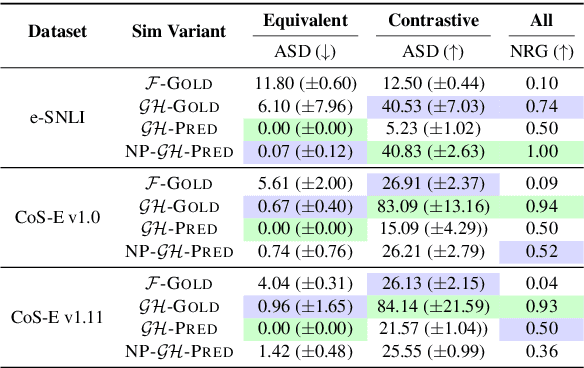
Free-text rationales aim to explain neural language model (LM) behavior more flexibly and intuitively via natural language. To ensure rationale quality, it is important to have metrics for measuring rationales' faithfulness (reflects LM's actual behavior) and plausibility (convincing to humans). All existing free-text rationale metrics are based on simulatability (association between rationale and LM's predicted label), but there is no protocol for assessing such metrics' reliability. To investigate this, we propose FRAME, a framework for evaluating free-text rationale simulatability metrics. FRAME is based on three axioms: (1) good metrics should yield highest scores for reference rationales, which maximize rationale-label association by construction; (2) good metrics should be appropriately sensitive to semantic perturbation of rationales; and (3) good metrics should be robust to variation in the LM's task performance. Across three text classification datasets, we show that existing simulatability metrics cannot satisfy all three FRAME axioms, since they are implemented via model pretraining which muddles the metric's signal. We introduce a non-pretraining simulatability variant that improves performance on (1) and (3) by an average of 41.7% and 42.9%, respectively, while performing competitively on (2).
ER-TEST: Evaluating Explanation Regularization Methods for NLP Models
May 25, 2022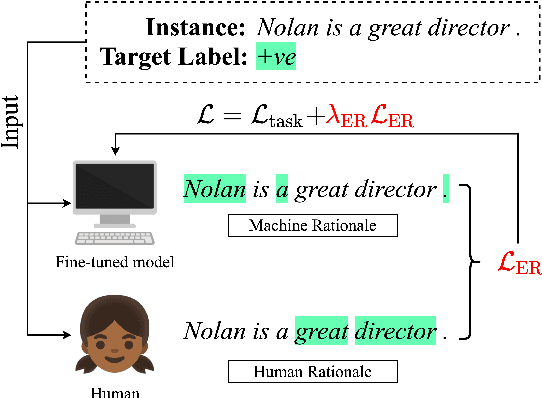
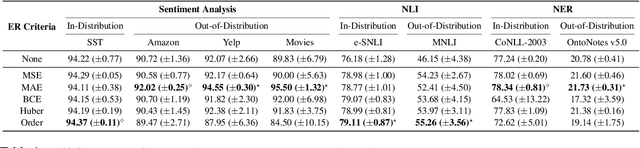
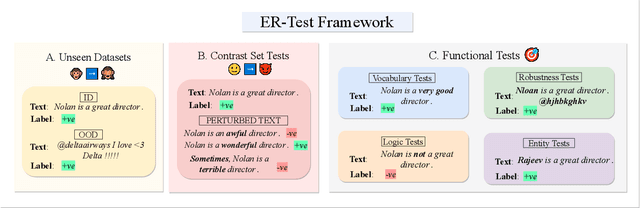
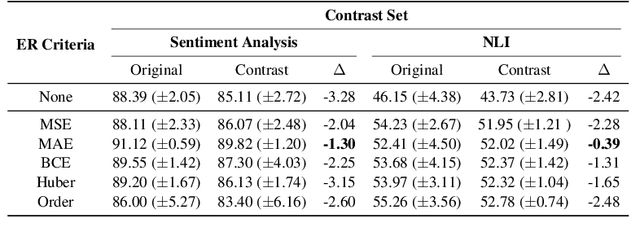
Neural language models' (NLMs') reasoning processes are notoriously hard to explain. Recently, there has been much progress in automatically generating machine rationales of NLM behavior, but less in utilizing the rationales to improve NLM behavior. For the latter, explanation regularization (ER) aims to improve NLM generalization by pushing the machine rationales to align with human rationales. Whereas prior works primarily evaluate such ER models via in-distribution (ID) generalization, ER's impact on out-of-distribution (OOD) is largely underexplored. Plus, little is understood about how ER model performance is affected by the choice of ER criteria or by the number/choice of training instances with human rationales. In light of this, we propose ER-TEST, a protocol for evaluating ER models' OOD generalization along three dimensions: (1) unseen datasets, (2) contrast set tests, and (3) functional tests. Using ER-TEST, we study three key questions: (A) Which ER criteria are most effective for the given OOD setting? (B) How is ER affected by the number/choice of training instances with human rationales? (C) Is ER effective with distantly supervised human rationales? ER-TEST enables comprehensive analysis of these questions by considering a diverse range of tasks and datasets. Through ER-TEST, we show that ER has little impact on ID performance, but can yield large gains on OOD performance w.r.t. (1)-(3). Also, we find that the best ER criterion is task-dependent, while ER can improve OOD performance even with limited and distantly-supervised human rationales.
Detecting and Understanding Harmful Memes: A Survey
May 09, 2022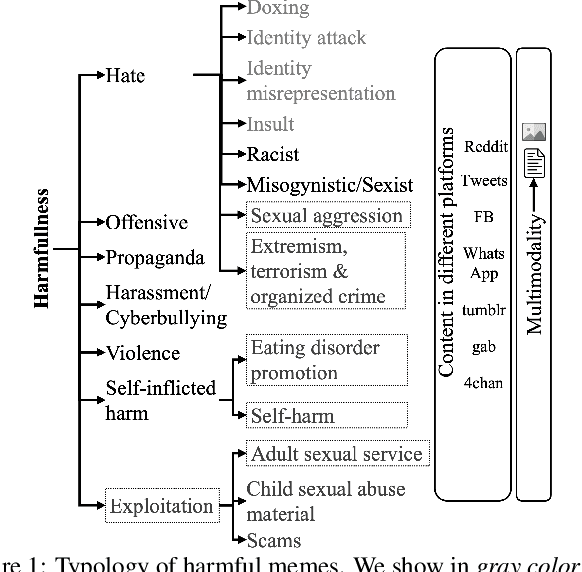
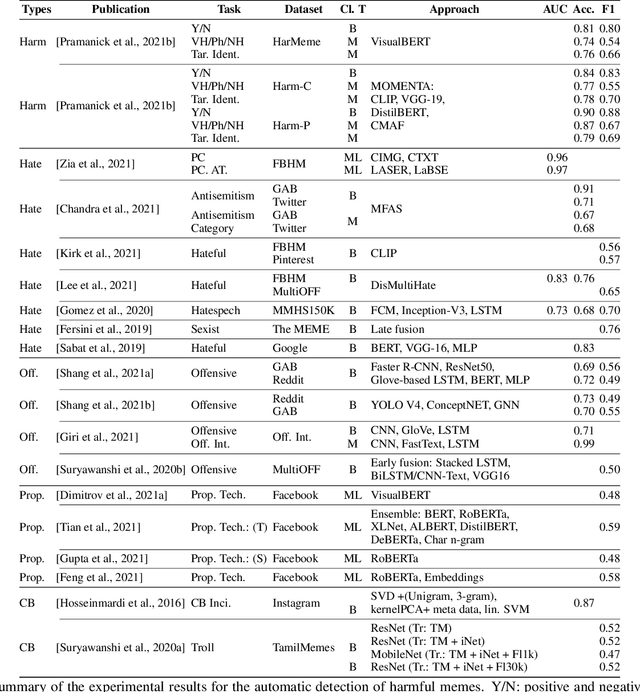

The automatic identification of harmful content online is of major concern for social media platforms, policymakers, and society. Researchers have studied textual, visual, and audio content, but typically in isolation. Yet, harmful content often combines multiple modalities, as in the case of memes, which are of particular interest due to their viral nature. With this in mind, here we offer a comprehensive survey with a focus on harmful memes. Based on a systematic analysis of recent literature, we first propose a new typology of harmful memes, and then we highlight and summarize the relevant state of the art. One interesting finding is that many types of harmful memes are not really studied, e.g., such featuring self-harm and extremism, partly due to the lack of suitable datasets. We further find that existing datasets mostly capture multi-class scenarios, which are not inclusive of the affective spectrum that memes can represent. Another observation is that memes can propagate globally through repackaging in different languages and that they can also be multilingual, blending different cultures. We conclude by highlighting several challenges related to multimodal semiotics, technological constraints and non-trivial social engagement, and we present several open-ended aspects such as delineating online harm and empirically examining related frameworks and assistive interventions, which we believe will motivate and drive future research.
Detection, Disambiguation, Re-ranking: Autoregressive Entity Linking as a Multi-Task Problem
Apr 12, 2022
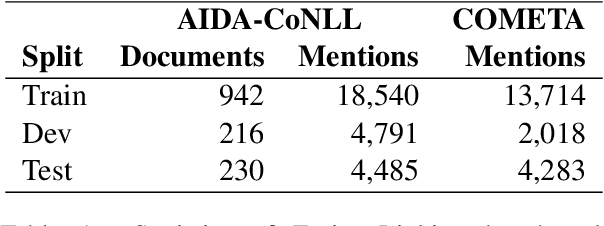
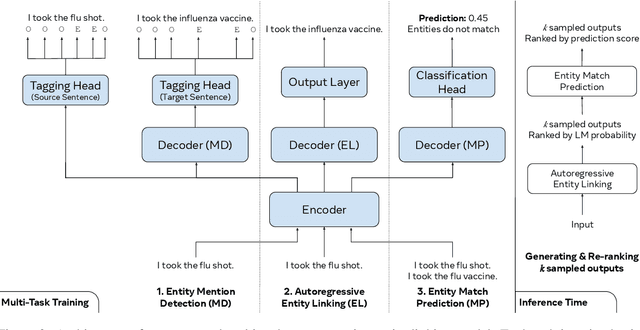
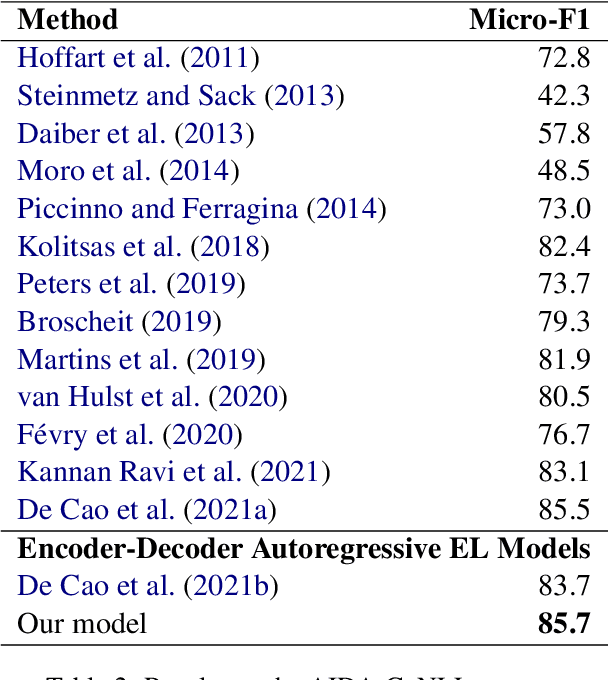
We propose an autoregressive entity linking model, that is trained with two auxiliary tasks, and learns to re-rank generated samples at inference time. Our proposed novelties address two weaknesses in the literature. First, a recent method proposes to learn mention detection and then entity candidate selection, but relies on predefined sets of candidates. We use encoder-decoder autoregressive entity linking in order to bypass this need, and propose to train mention detection as an auxiliary task instead. Second, previous work suggests that re-ranking could help correct prediction errors. We add a new, auxiliary task, match prediction, to learn re-ranking. Without the use of a knowledge base or candidate sets, our model sets a new state of the art in two benchmark datasets of entity linking: COMETA in the biomedical domain, and AIDA-CoNLL in the news domain. We show through ablation studies that each of the two auxiliary tasks increases performance, and that re-ranking is an important factor to the increase. Finally, our low-resource experimental results suggest that performance on the main task benefits from the knowledge learned by the auxiliary tasks, and not just from the additional training data.
Understanding Failure Modes of Self-Supervised Learning
Mar 03, 2022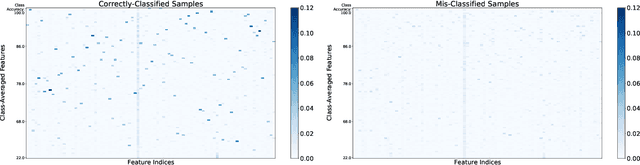
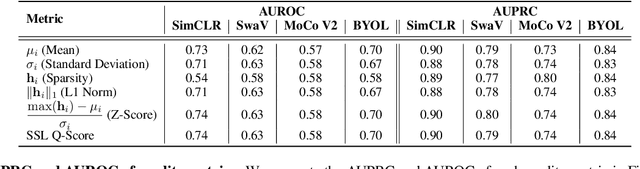
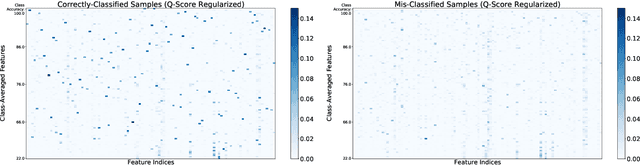
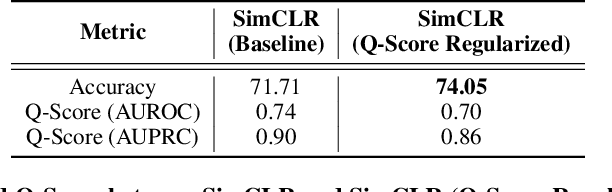
Self-supervised learning methods have shown impressive results in downstream classification tasks. However, there is limited work in understanding their failure models and interpreting the learned representations of these models. In this paper, we tackle these issues and study the representation space of self-supervised models by understanding the underlying reasons for misclassifications in a downstream task. Over several state-of-the-art self-supervised models including SimCLR, SwaV, MoCo V2 and BYOL, we observe that representations of correctly classified samples have few discriminative features with highly deviated values compared to other features. This is in a clear contrast with representations of misclassified samples. We also observe that noisy features in the representation space often correspond to spurious attributes in images making the models less interpretable. Building on these observations, we propose a sample-wise Self-Supervised Representation Quality Score (or, Q-Score) that, without access to any label information, is able to predict if a given sample is likely to be misclassified in the downstream task, achieving an AUPRC of up to 0.90. Q-Score can also be used as a regularization to remedy low-quality representations leading to 3.26% relative improvement in accuracy of SimCLR on ImageNet-100. Moreover, we show that Q-Score regularization increases representation sparsity, thus reducing noise and improving interpretability through gradient heatmaps.
A Fistful of Words: Learning Transferable Visual Models from Bag-of-Words Supervision
Jan 06, 2022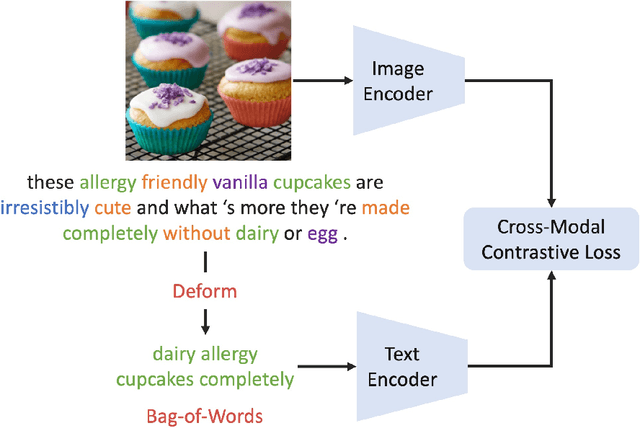
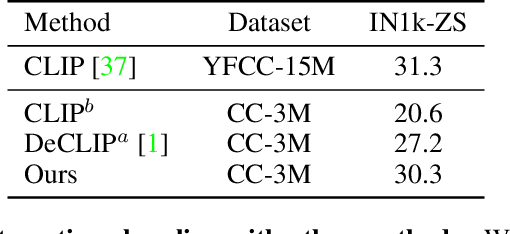

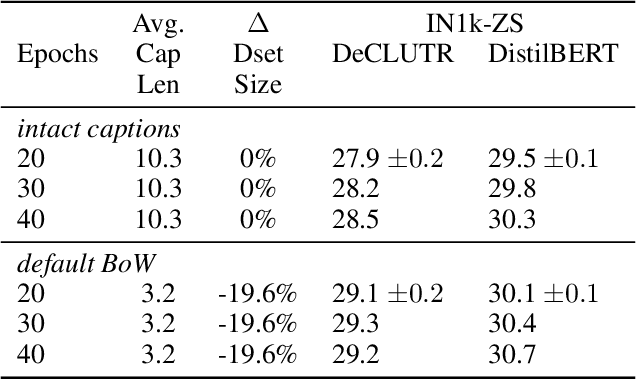
Using natural language as a supervision for training visual recognition models holds great promise. Recent works have shown that if such supervision is used in the form of alignment between images and captions in large training datasets, then the resulting aligned models perform well on zero-shot classification as downstream tasks2. In this paper, we focus on teasing out what parts of the language supervision are essential for training zero-shot image classification models. Through extensive and careful experiments, we show that: 1) A simple Bag-of-Words (BoW) caption could be used as a replacement for most of the image captions in the dataset. Surprisingly, we observe that this approach improves the zero-shot classification performance when combined with word balancing. 2) Using a BoW pretrained model, we can obtain more training data by generating pseudo-BoW captions on images that do not have a caption. Models trained on images with real and pseudo-BoW captions achieve stronger zero-shot performance. On ImageNet-1k zero-shot evaluation, our best model, that uses only 3M image-caption pairs, performs on-par with a CLIP model trained on 15M image-caption pairs (31.5% vs 31.3%).
BARACK: Partially Supervised Group Robustness With Guarantees
Dec 31, 2021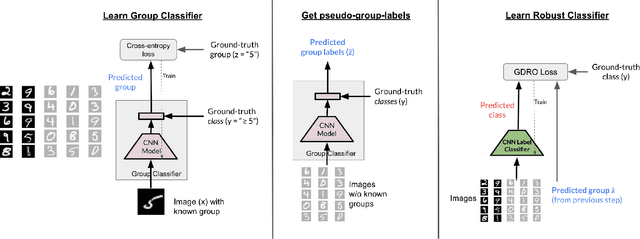



While neural networks have shown remarkable success on classification tasks in terms of average-case performance, they often fail to perform well on certain groups of the data. Such group information may be expensive to obtain; thus, recent works in robustness and fairness have proposed ways to improve worst-group performance even when group labels are unavailable for the training data. However, these methods generally underperform methods that utilize group information at training time. In this work, we assume access to a small number of group labels alongside a larger dataset without group labels. We propose BARACK, a simple two-step framework to utilize this partial group information to improve worst-group performance: train a model to predict the missing group labels for the training data, and then use these predicted group labels in a robust optimization objective. Theoretically, we provide generalization bounds for our approach in terms of the worst-group performance, showing how the generalization error scales with respect to both the total number of training points and the number of training points with group labels. Empirically, our method outperforms the baselines that do not use group information, even when only 1-33% of points have group labels. We provide ablation studies to support the robustness and extensibility of our framework.
UniREx: A Unified Learning Framework for Language Model Rationale Extraction
Dec 16, 2021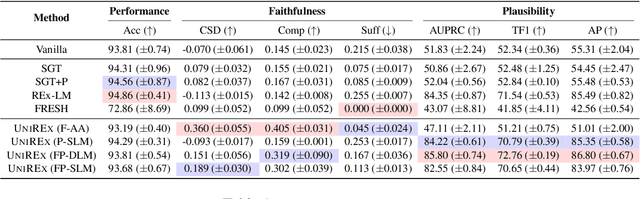
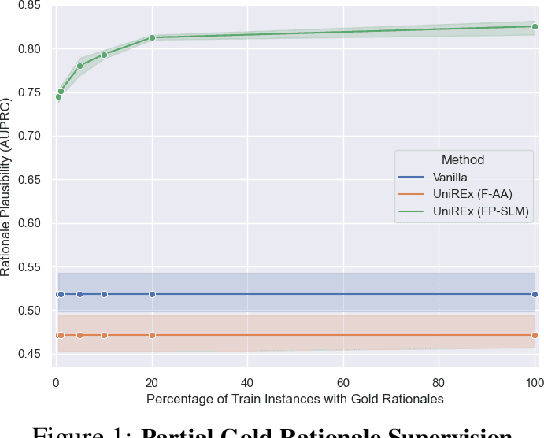
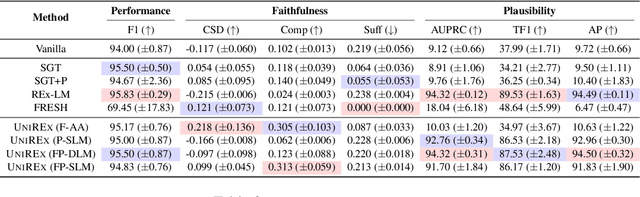
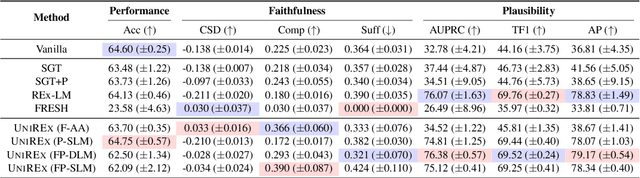
An extractive rationale explains a language model's (LM's) prediction on a given task instance by highlighting the text inputs that most influenced the output. Ideally, rationale extraction should be faithful (reflects LM's behavior), plausible (makes sense to humans), data-efficient, and fast, without sacrificing the LM's task performance. Prior rationale extraction works consist of specialized approaches for addressing various subsets of these desiderata -- but never all five. Narrowly focusing on certain desiderata typically comes at the expense of ignored ones, so existing rationale extractors are often impractical in real-world applications. To tackle this challenge, we propose UniREx, a unified and highly flexible learning framework for rationale extraction, which allows users to easily account for all five factors. UniREx enables end-to-end customization of the rationale extractor training process, supporting arbitrary: (1) heuristic/learned rationale extractors, (2) combinations of faithfulness and/or plausibility objectives, and (3) amounts of gold rationale supervision. Across three text classification datasets, our best UniREx configurations achieve a superior balance of the five desiderata, when compared to strong baselines. Furthermore, UniREx-trained rationale extractors can even generalize to unseen datasets and tasks.