 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowing What, How and Why: A Near Complete Solution for Aspect-based Sentiment Analysis
Nov 21, 2019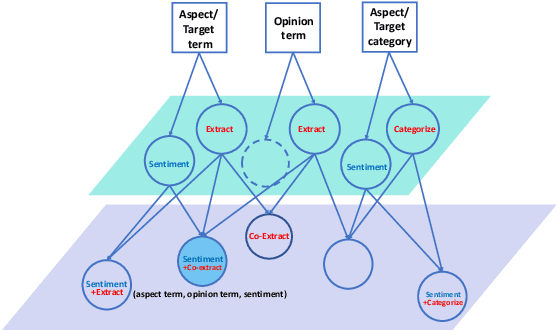

Target-based sentiment analysis or aspect-based sentiment analysis (ABSA) refers to addressing various sentiment analysis tasks at a fine-grained level, which includes but is not limited to aspect extraction, aspect sentiment classification, and opinion extraction. There exist many solvers of the above individual subtasks or a combination of two subtasks, and they can work together to tell a complete story, i.e. the discussed aspect, the sentiment on it, and the cause of the sentiment. However, no previous ABSA research tried to provide a complete solution in one shot. In this paper, we introduce a new subtask under ABSA, named aspect sentiment triplet extraction (ASTE). Particularly, a solver of this task needs to extract triplets (What, How, Why) from the inputs, which show WHAT the targeted aspects are, HOW their sentiment polarities are and WHY they have such polarities (i.e. opinion reasons). For instance, one triplet from "Waiters are very friendly and the pasta is simply average" could be ('Waiters', positive, 'friendly'). We propose a two-stage framework to address this task. The first stage predicts what, how and why in a unified model, and then the second stage pairs up the predicted what (how) and why from the first stage to output triplets. In the experiments, our framework has set a benchmark performance in this novel triplet extraction task. Meanwhile, it outperforms a few strong baselines adapted from state-of-the-art related methods.
Towards Scalable and Reliable Capsule Networks for Challenging NLP Applications
Jun 06, 2019
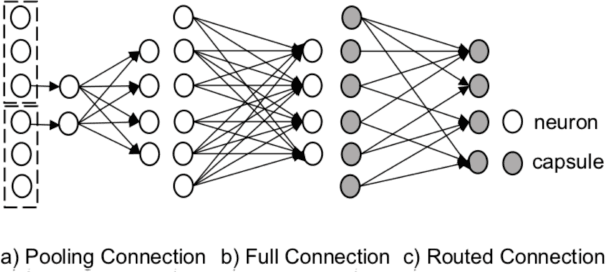
Obstacles hindering the development of capsule networks for challenging NLP applications include poor scalability to large output spaces and less reliable routing processes. In this paper, we introduce: 1) an agreement score to evaluate the performance of routing processes at instance level; 2) an adaptive optimizer to enhance the reliability of routing; 3) capsule compression and partial routing to improve the scalability of capsule networks. We validate our approach on two NLP tasks, namely: multi-label text classification and question answering. Experimental results show that our approach considerably improves over strong competitors on both tasks. In addition, we gain the best results in low-resource settings with few training instances.
Sentiment and Sarcasm Classification with Multitask Learning
Jan 23, 2019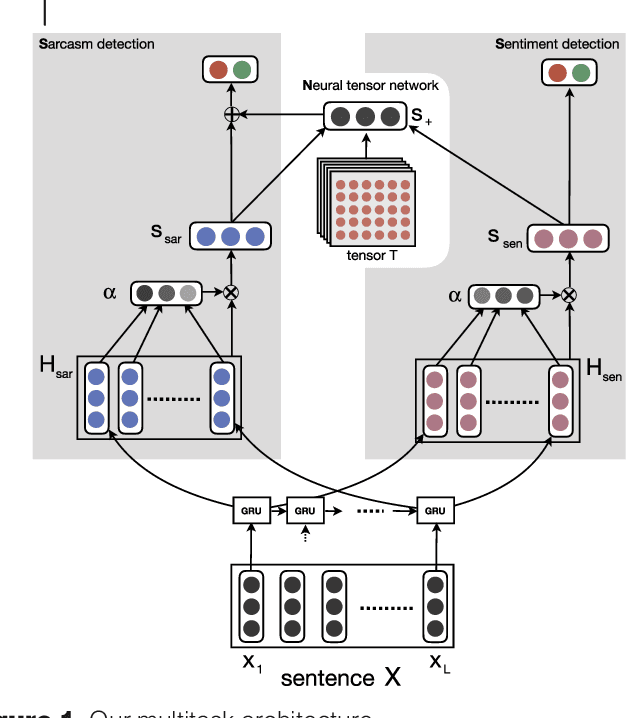
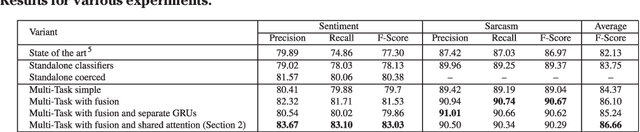
Sentiment classification and sarcasm detection are both important NLP tasks. We show that these two tasks are correlated, and present a multi-task learning-based framework using deep neural network that models this correlation to improve the performance of both tasks in a multi-task learning setting.
Phonetic-enriched Text Representation for Chinese Sentiment Analysis with Reinforcement Learning
Jan 23, 2019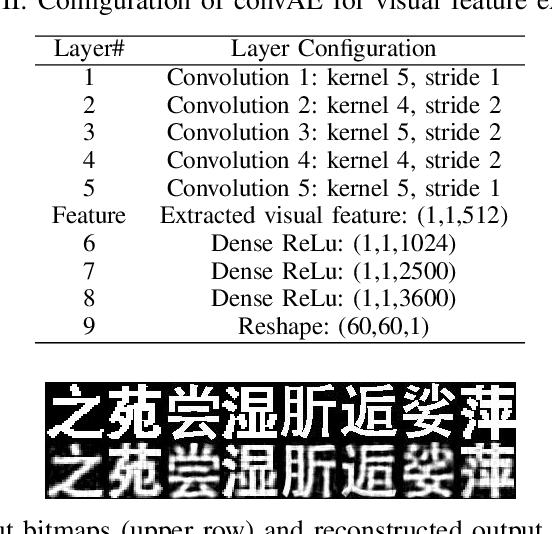
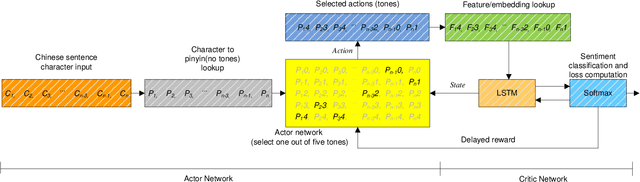
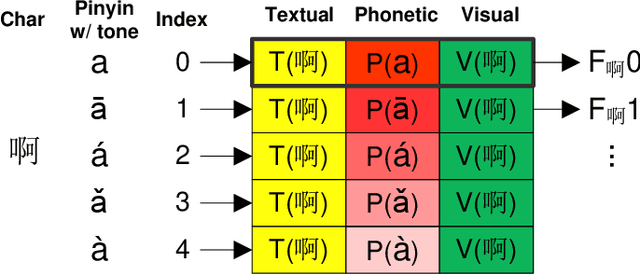
The Chinese pronunciation system offers two characteristics that distinguish it from other languages: deep phonemic orthography and intonation variations. We are the first to argue that these two important properties can play a major role in Chinese sentiment analysis. Particularly, we propose two effective features to encode phonetic information. Next, we develop a Disambiguate Intonation for Sentiment Analysis (DISA) network using a reinforcement network. It functions as disambiguating intonations for each Chinese character (pinyin). Thus, a precise phonetic representation of Chinese is learned. Furthermore, we also fuse phonetic features with textual and visual features in order to mimic the way humans read and understand Chinese text. Experimental results on five different Chinese sentiment analysis datasets show that the inclusion of phonetic features significantly and consistently improves the performance of textual and visual representations and outshines the state-of-the-art Chinese character level representations.
Disentangled Variational Auto-Encoder for Semi-supervised Learning
Sep 15, 2017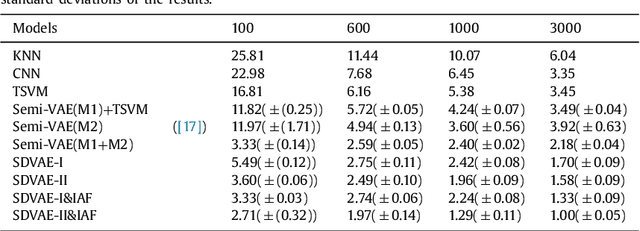
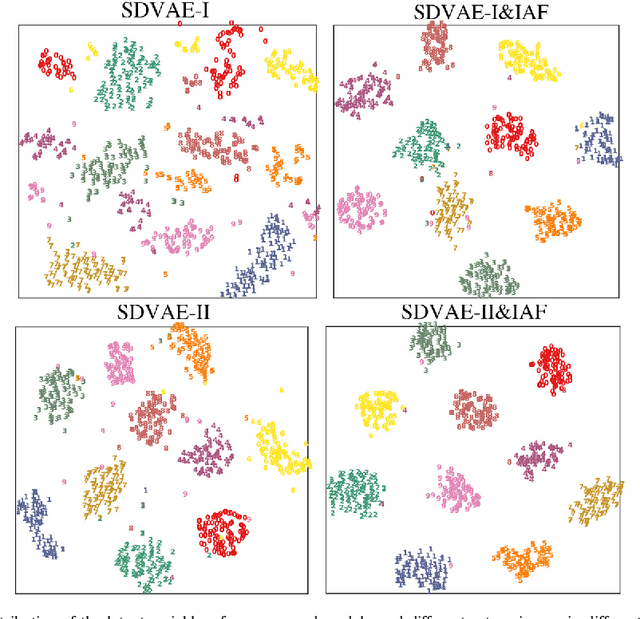
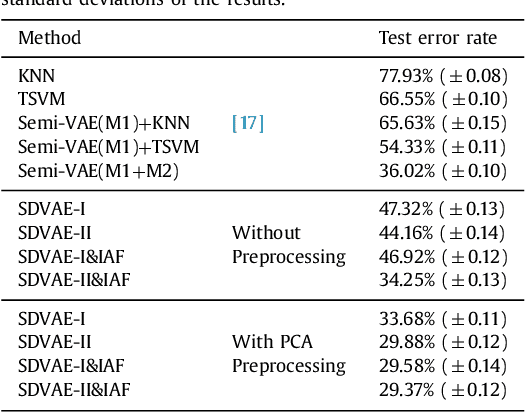
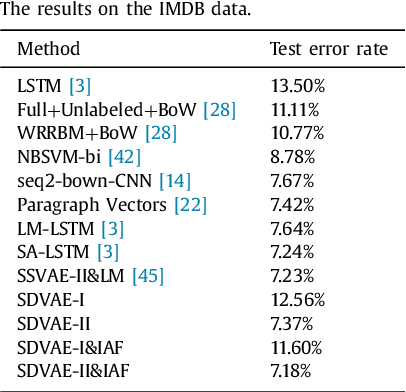
In this paper, we develop a novel approach for semi-supervised VAE without classifier. Specifically, we propose a new model called SDVAE, which encodes the input data into disentangled representation and non-interpretable representation, then the category information is directly utilized to regularize the disentangled representation via equation constraint. To further enhance the feature learning ability of the proposed VAE, we incorporate reinforcement learning to relieve the lack of data. The dynamic framework is capable of dealing with both image and text data with its corresponding encoder and decoder networks. Extensive experiments on image and text datasets demonstrate the effectiveness of the proposed framework.