 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMessyTable: Instance Association in Multiple Camera Views
Jul 29, 2020
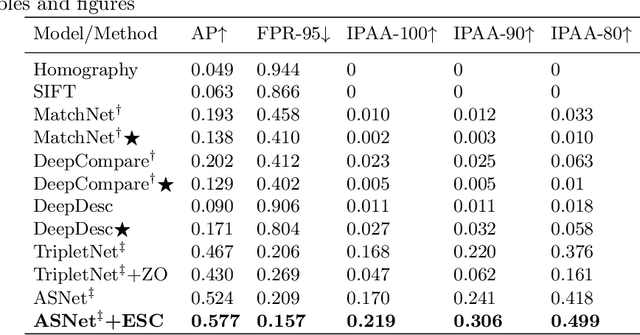
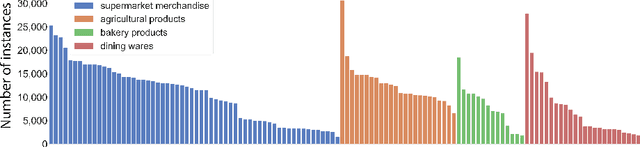
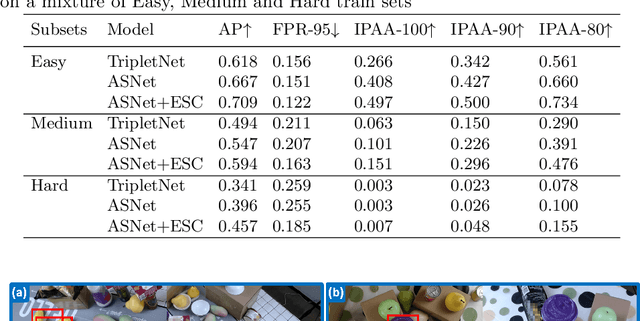
We present an interesting and challenging dataset that features a large number of scenes with messy tables captured from multiple camera views. Each scene in this dataset is highly complex, containing multiple object instances that could be identical, stacked and occluded by other instances. The key challenge is to associate all instances given the RGB image of all views. The seemingly simple task surprisingly fails many popular methods or heuristics that we assume good performance in object association. The dataset challenges existing methods in mining subtle appearance differences, reasoning based on contexts, and fusing appearance with geometric cues for establishing an association. We report interesting findings with some popular baselines, and discuss how this dataset could help inspire new problems and catalyse more robust formulations to tackle real-world instance association problems. Project page: $\href{https://caizhongang.github.io/projects/MessyTable/}{\text{MessyTable}}$
Balanced Meta-Softmax for Long-Tailed Visual Recognition
Jul 21, 2020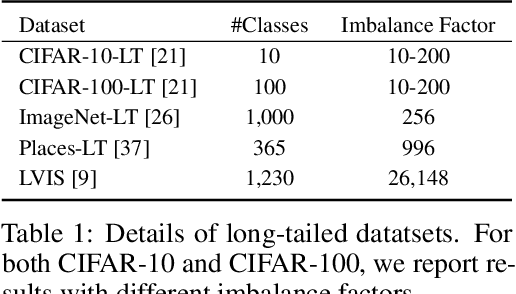
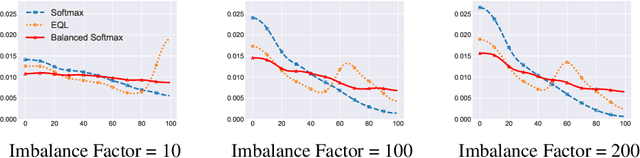
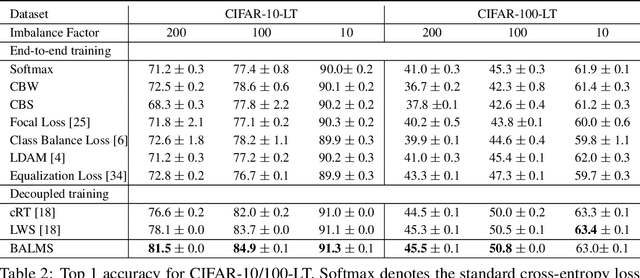
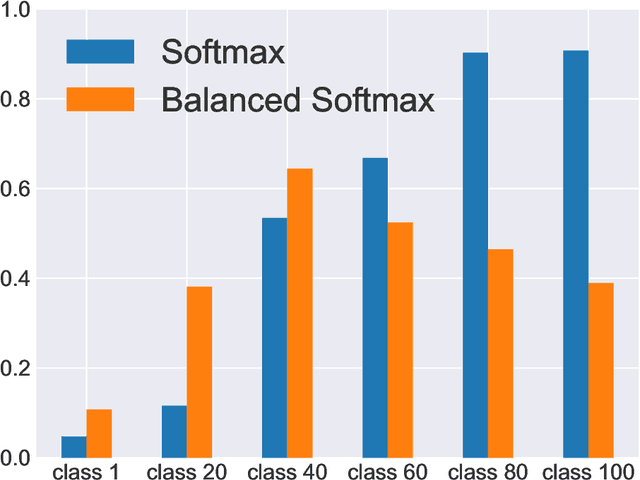
Deep classifiers have achieved great success in visual recognition. However, real-world data is long-tailed by nature, leading to the mismatch between training and testing distributions. In this paper, we show that Softmax function, though used in most classification tasks, gives a biased gradient estimation under the long-tailed setup. This paper presents Balanced Softmax, an elegant unbiased extension of Softmax, to accommodate the label distribution shift between training and testing. Theoretically, we derive the generalization bound for multiclass Softmax regression and show our loss minimizes the bound. In addition, we introduce Balanced Meta-Softmax, applying a complementary Meta Sampler to estimate the optimal class sample rate and further improve long-tailed learning. In our experiments, we demonstrate that Balanced Meta-Softmax outperforms state-of-the-art long-tailed classification solutions on both visual recognition and instance segmentation tasks.
Leveraging Temporal Information for 3D Detection and Domain Adaptation
Jun 30, 2020

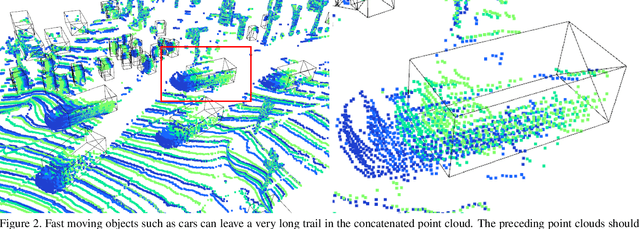
Ever since the prevalent use of the LiDARs in autonomous driving, tremendous improvements have been made to the learning on the point clouds. However, recent progress largely focuses on detecting objects in a single 360-degree sweep, without extensively exploring the temporal information. In this report, we describe a simple way to pass such information in the learning pipeline by adding timestamps to the point clouds, which shows consistent improvements across all three classes.
Spatio-Temporal Graph Transformer Networks for Pedestrian Trajectory Prediction
May 18, 2020
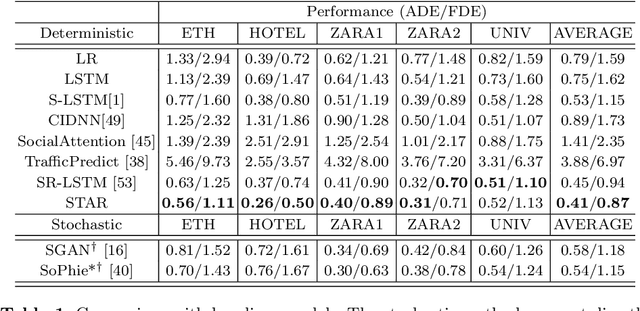
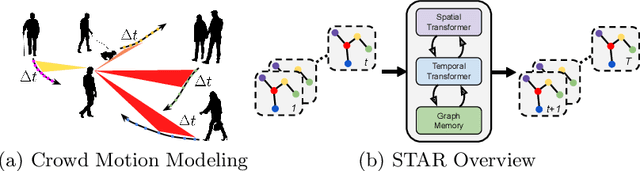
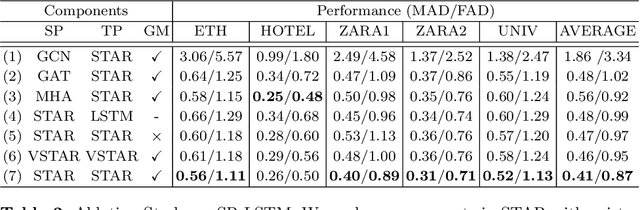
Understanding crowd motion dynamics is critical to real-world applications, e.g., surveillance systems and autonomous driving. This is challenging because it requires effectively modeling the socially aware crowd spatial interaction and complex temporal dependencies. We believe attention is the most important factor for trajectory prediction. In this paper, we present STAR, a Spatio-Temporal grAph tRansformer framework, which tackles trajectory prediction by only attention mechanisms. STAR models intra-graph crowd interaction by TGConv, a novel Transformer-based graph convolution mechanism. The inter-graph temporal dependencies are modeled by separate temporal Transformers. STAR captures complex spatio-temporal interactions by interleaving between spatial and temporal Transformers. To calibrate the temporal prediction for the long-lasting effect of disappeared pedestrians, we introduce a read-writable external memory module, consistently being updated by the temporal Transformer. We show STAR outperforms the state-of-the-art models on 4 out of 5 real-world pedestrian trajectory prediction datasets, and achieves comparable performance on the rest.
Factorized Attention: Self-Attention with Linear Complexities
Dec 04, 2018


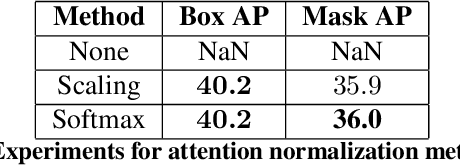
Recent works have been applying self-attention to various fields in computer vision and natural language processing. However, the memory and computational demands of existing self-attention operations grow quadratically with the spatiotemporal size of the input. This prohibits the application of self-attention on large inputs, e.g., long sequences, high-definition images, or large videos. To remedy this, this paper proposes a novel factorized attention (FA) module, which achieves the same expressive power as previous approaches with substantially less memory and computational consumption. The resource-efficiency allows more widespread and flexible application of it. Empirical evaluations on object recognition demonstrate the effectiveness of these advantages. FA-augmented models achieved state-of-the-art performance for object detection and instance segmentation on MS-COCO. Further, the resource-efficiency of FA democratizes self-attention to fields where the prohibitively high costs currently prevent its application. The state-of-the-art result for stereo depth estimation on the Scene Flow dataset exemplifies this.
HydraPlus-Net: Attentive Deep Features for Pedestrian Analysis
Sep 28, 2017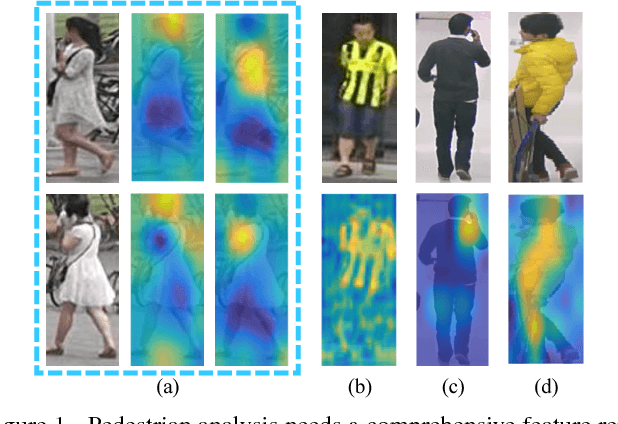
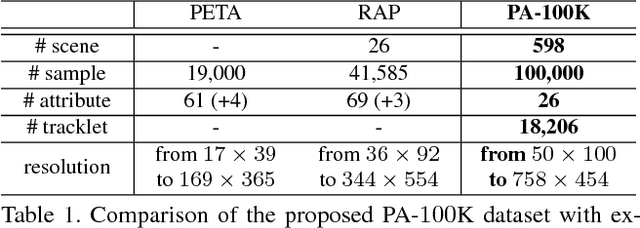
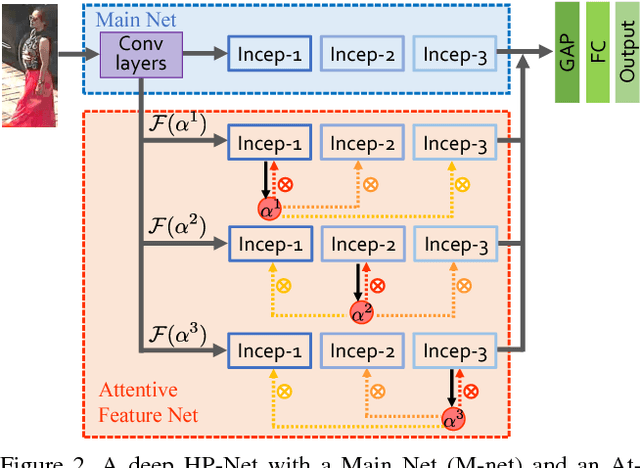

Pedestrian analysis plays a vital role in intelligent video surveillance and is a key component for security-centric computer vision systems. Despite that the convolutional neural networks are remarkable in learning discriminative features from images, the learning of comprehensive features of pedestrians for fine-grained tasks remains an open problem. In this study, we propose a new attention-based deep neural network, named as HydraPlus-Net (HP-net), that multi-directionally feeds the multi-level attention maps to different feature layers. The attentive deep features learned from the proposed HP-net bring unique advantages: (1) the model is capable of capturing multiple attentions from low-level to semantic-level, and (2) it explores the multi-scale selectiveness of attentive features to enrich the final feature representations for a pedestrian image. We demonstrate the effectiveness and generality of the proposed HP-net for pedestrian analysis on two tasks, i.e. pedestrian attribute recognition and person re-identification. Intensive experimental results have been provided to prove that the HP-net outperforms the state-of-the-art methods on various datasets.
Hierarchical Deep Recurrent Architecture for Video Understanding
Jul 11, 2017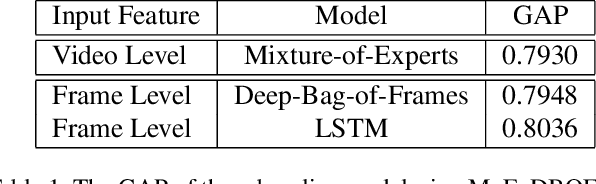
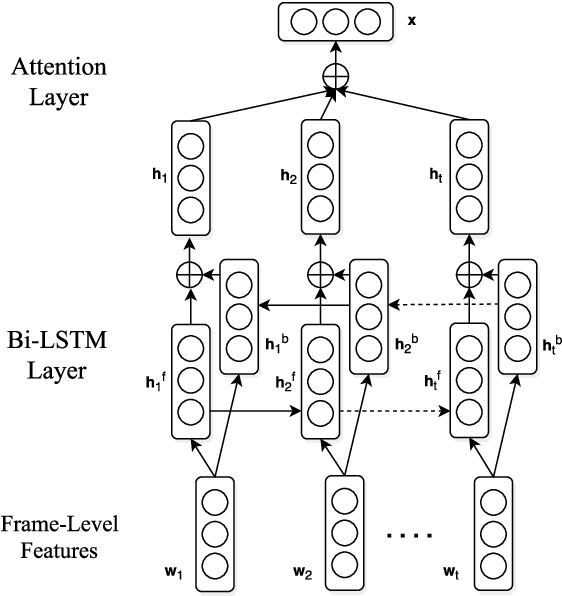

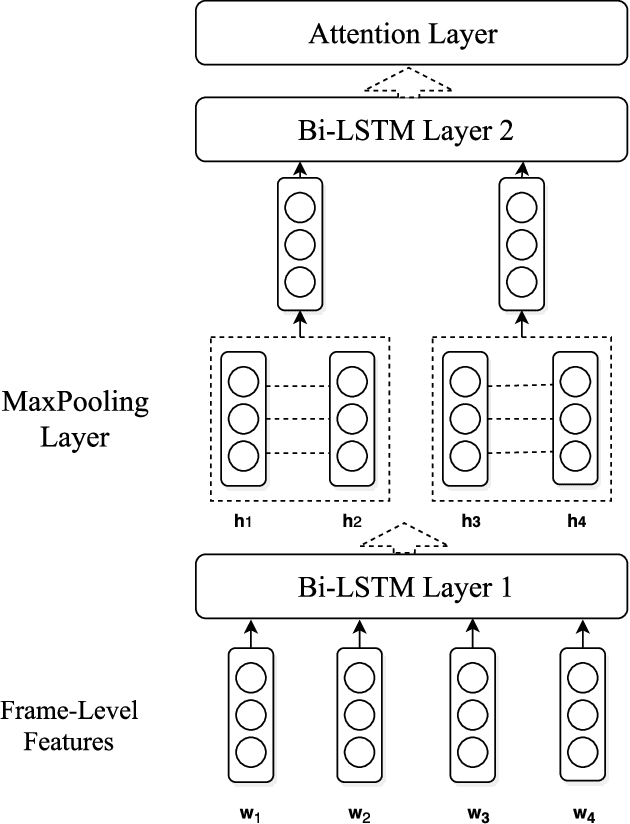
This paper introduces the system we developed for the Youtube-8M Video Understanding Challenge, in which a large-scale benchmark dataset was used for multi-label video classification. The proposed framework contains hierarchical deep architecture, including the frame-level sequence modeling part and the video-level classification part. In the frame-level sequence modelling part, we explore a set of methods including Pooling-LSTM (PLSTM), Hierarchical-LSTM (HLSTM), Random-LSTM (RLSTM) in order to address the problem of large amount of frames in a video. We also introduce two attention pooling methods, single attention pooling (ATT) and multiply attention pooling (Multi-ATT) so that we can pay more attention to the informative frames in a video and ignore the useless frames. In the video-level classification part, two methods are proposed to increase the classification performance, i.e. Hierarchical-Mixture-of-Experts (HMoE) and Classifier Chains (CC). Our final submission is an ensemble consisting of 18 sub-models. In terms of the official evaluation metric Global Average Precision (GAP) at 20, our best submission achieves 0.84346 on the public 50% of test dataset and 0.84333 on the private 50% of test data.