 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinguistic Rules-Based Corpus Generation for Native Chinese Grammatical Error Correction
Oct 19, 2022
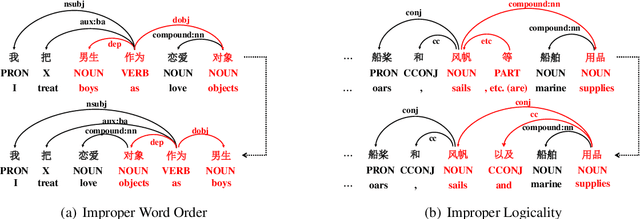
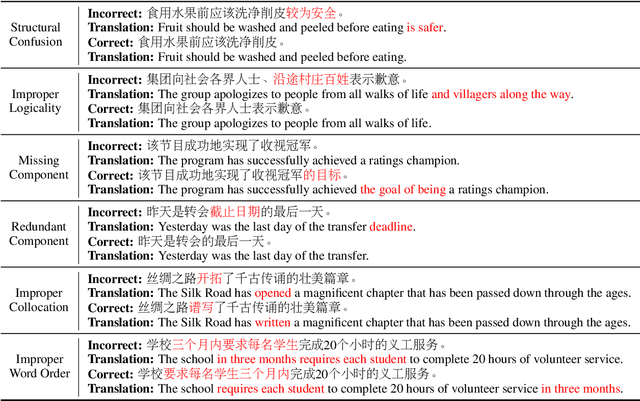
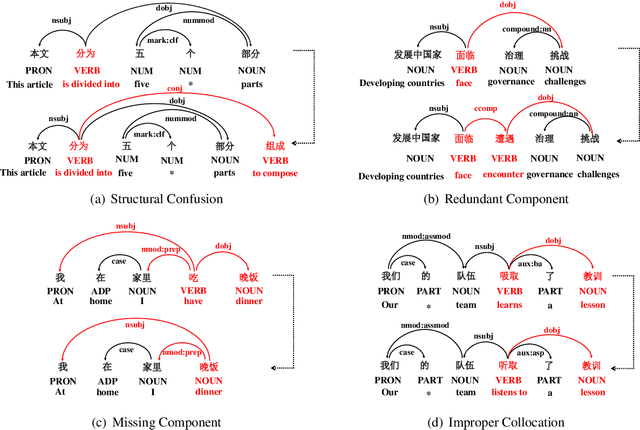
Chinese Grammatical Error Correction (CGEC) is both a challenging NLP task and a common application in human daily life. Recently, many data-driven approaches are proposed for the development of CGEC research. However, there are two major limitations in the CGEC field: First, the lack of high-quality annotated training corpora prevents the performance of existing CGEC models from being significantly improved. Second, the grammatical errors in widely used test sets are not made by native Chinese speakers, resulting in a significant gap between the CGEC models and the real application. In this paper, we propose a linguistic rules-based approach to construct large-scale CGEC training corpora with automatically generated grammatical errors. Additionally, we present a challenging CGEC benchmark derived entirely from errors made by native Chinese speakers in real-world scenarios. Extensive experiments and detailed analyses not only demonstrate that the training data constructed by our method effectively improves the performance of CGEC models, but also reflect that our benchmark is an excellent resource for further development of the CGEC field.
Natural Backdoor Datasets
Jun 21, 2022

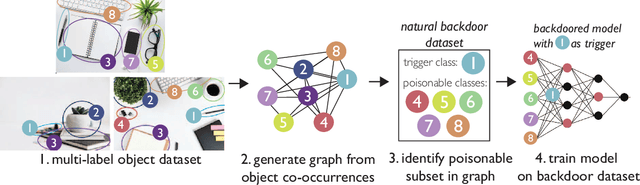
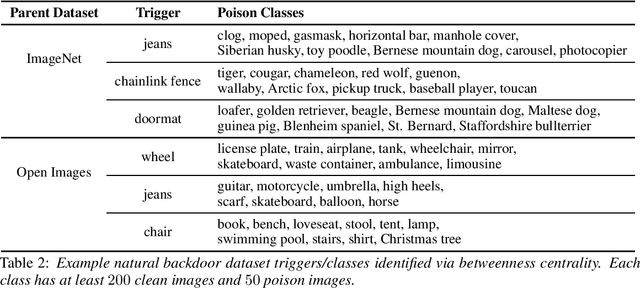
Extensive literature on backdoor poison attacks has studied attacks and defenses for backdoors using "digital trigger patterns." In contrast, "physical backdoors" use physical objects as triggers, have only recently been identified, and are qualitatively different enough to resist all defenses targeting digital trigger backdoors. Research on physical backdoors is limited by access to large datasets containing real images of physical objects co-located with targets of classification. Building these datasets is time- and labor-intensive. This works seeks to address the challenge of accessibility for research on physical backdoor attacks. We hypothesize that there may be naturally occurring physically co-located objects already present in popular datasets such as ImageNet. Once identified, a careful relabeling of these data can transform them into training samples for physical backdoor attacks. We propose a method to scalably identify these subsets of potential triggers in existing datasets, along with the specific classes they can poison. We call these naturally occurring trigger-class subsets natural backdoor datasets. Our techniques successfully identify natural backdoors in widely-available datasets, and produce models behaviorally equivalent to those trained on manually curated datasets. We release our code to allow the research community to create their own datasets for research on physical backdoor attacks.
Can Backdoor Attacks Survive Time-Varying Models?
Jun 08, 2022
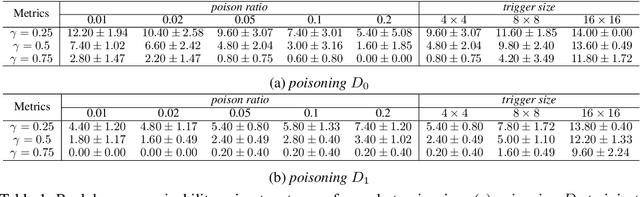
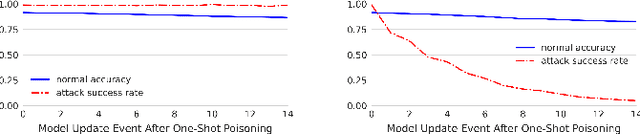

Backdoors are powerful attacks against deep neural networks (DNNs). By poisoning training data, attackers can inject hidden rules (backdoors) into DNNs, which only activate on inputs containing attack-specific triggers. While existing work has studied backdoor attacks on a variety of DNN models, they only consider static models, which remain unchanged after initial deployment. In this paper, we study the impact of backdoor attacks on a more realistic scenario of time-varying DNN models, where model weights are updated periodically to handle drifts in data distribution over time. Specifically, we empirically quantify the "survivability" of a backdoor against model updates, and examine how attack parameters, data drift behaviors, and model update strategies affect backdoor survivability. Our results show that one-shot backdoor attacks (i.e., only poisoning training data once) do not survive past a few model updates, even when attackers aggressively increase trigger size and poison ratio. To stay unaffected by model update, attackers must continuously introduce corrupted data into the training pipeline. Together, these results indicate that when models are updated to learn new data, they also "forget" backdoors as hidden, malicious features. The larger the distribution shift between old and new training data, the faster backdoors are forgotten. Leveraging these insights, we apply a smart learning rate scheduler to further accelerate backdoor forgetting during model updates, which prevents one-shot backdoors from surviving past a single model update.
Global Mixup: Eliminating Ambiguity with Clustering
Jun 06, 2022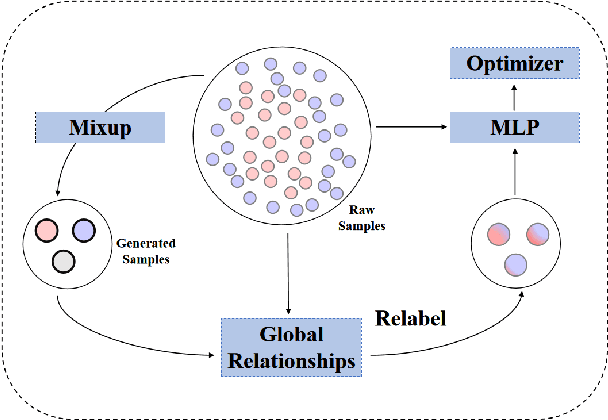
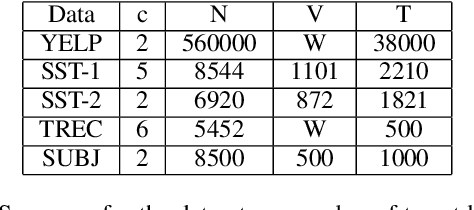
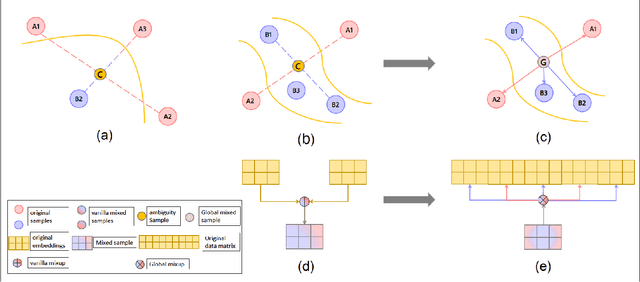
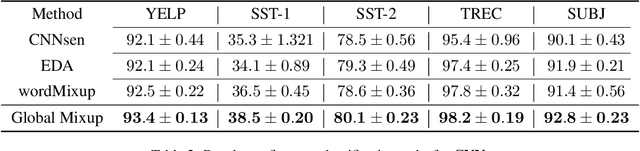
Data augmentation with \textbf{Mixup} has been proven an effective method to regularize the current deep neural networks. Mixup generates virtual samples and corresponding labels at once through linear interpolation. However, this one-stage generation paradigm and the use of linear interpolation have the following two defects: (1) The label of the generated sample is directly combined from the labels of the original sample pairs without reasonable judgment, which makes the labels likely to be ambiguous. (2) linear combination significantly limits the sampling space for generating samples. To tackle these problems, we propose a novel and effective augmentation method based on global clustering relationships named \textbf{Global Mixup}. Specifically, we transform the previous one-stage augmentation process into two-stage, decoupling the process of generating virtual samples from the labeling. And for the labels of the generated samples, relabeling is performed based on clustering by calculating the global relationships of the generated samples. In addition, we are no longer limited to linear relationships but generate more reliable virtual samples in a larger sampling space. Extensive experiments for \textbf{CNN}, \textbf{LSTM}, and \textbf{BERT} on five tasks show that Global Mixup significantly outperforms previous state-of-the-art baselines. Further experiments also demonstrate the advantage of Global Mixup in low-resource scenarios.
Assessing Privacy Risks from Feature Vector Reconstruction Attacks
Feb 11, 2022



In deep neural networks for facial recognition, feature vectors are numerical representations that capture the unique features of a given face. While it is known that a version of the original face can be recovered via "feature reconstruction," we lack an understanding of the end-to-end privacy risks produced by these attacks. In this work, we address this shortcoming by developing metrics that meaningfully capture the threat of reconstructed face images. Using end-to-end experiments and user studies, we show that reconstructed face images enable re-identification by both commercial facial recognition systems and humans, at a rate that is at worst, a factor of four times higher than randomized baselines. Our results confirm that feature vectors should be recognized as Personal Identifiable Information (PII) in order to protect user privacy.
SoK: Anti-Facial Recognition Technology
Dec 08, 2021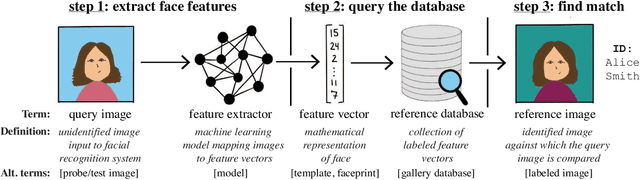
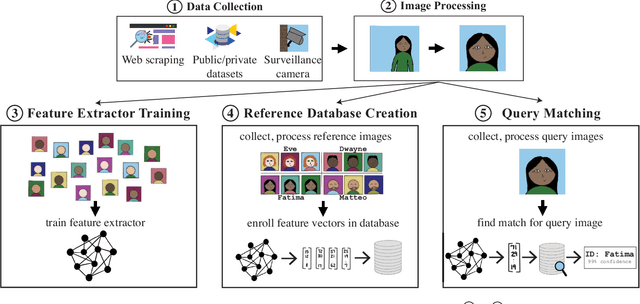

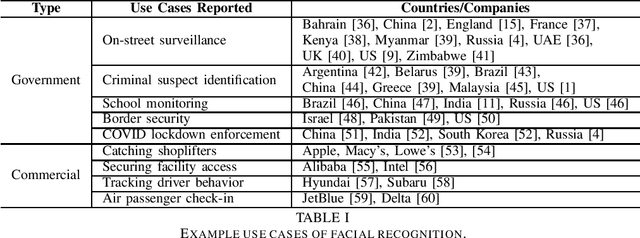
The rapid adoption of facial recognition (FR) technology by both government and commercial entities in recent years has raised concerns about civil liberties and privacy. In response, a broad suite of so-called "anti-facial recognition" (AFR) tools has been developed to help users avoid unwanted facial recognition. The set of AFR tools proposed in the last few years is wide-ranging and rapidly evolving, necessitating a step back to consider the broader design space of AFR systems and long-term challenges. This paper aims to fill that gap and provides the first comprehensive analysis of the AFR research landscape. Using the operational stages of FR systems as a starting point, we create a systematic framework for analyzing the benefits and tradeoffs of different AFR approaches. We then consider both technical and social challenges facing AFR tools and propose directions for future research in this field.
Traceback of Data Poisoning Attacks in Neural Networks
Oct 13, 2021

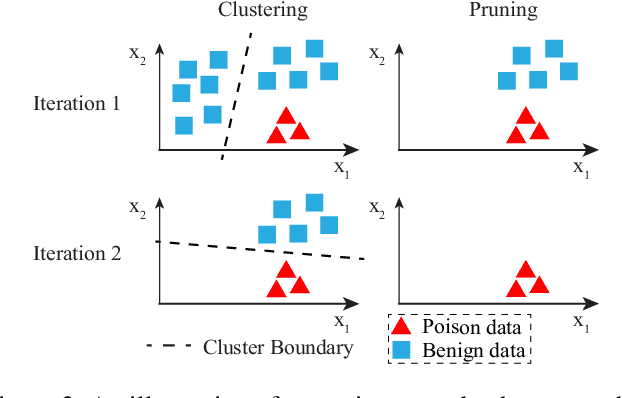
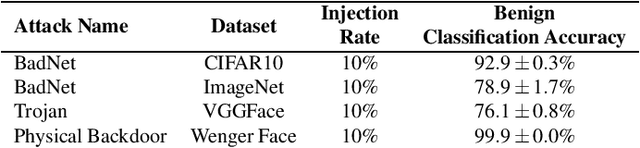
In adversarial machine learning, new defenses against attacks on deep learning systems are routinely broken soon after their release by more powerful attacks. In this context, forensic tools can offer a valuable complement to existing defenses, by tracing back a successful attack to its root cause, and offering a path forward for mitigation to prevent similar attacks in the future. In this paper, we describe our efforts in developing a forensic traceback tool for poison attacks on deep neural networks. We propose a novel iterative clustering and pruning solution that trims "innocent" training samples, until all that remains is the set of poisoned data responsible for the attack. Our method clusters training samples based on their impact on model parameters, then uses an efficient data unlearning method to prune innocent clusters. We empirically demonstrate the efficacy of our system on three types of dirty-label (backdoor) poison attacks and three types of clean-label poison attacks, across domains of computer vision and malware classification. Our system achieves over 98.4% precision and 96.8% recall across all attacks. We also show that our system is robust against four anti-forensics measures specifically designed to attack it.
"Hello, It's Me": Deep Learning-based Speech Synthesis Attacks in the Real World
Sep 20, 2021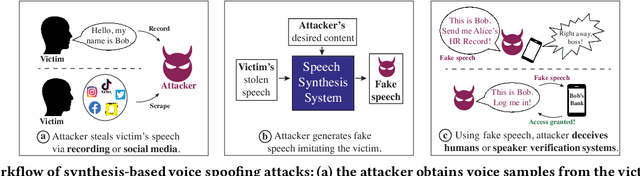
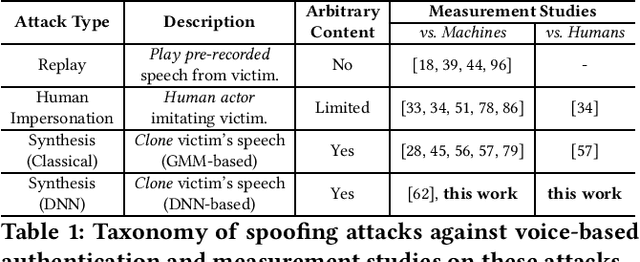

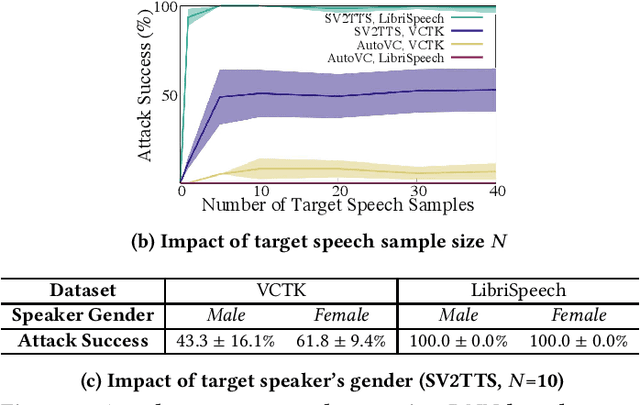
Advances in deep learning have introduced a new wave of voice synthesis tools, capable of producing audio that sounds as if spoken by a target speaker. If successful, such tools in the wrong hands will enable a range of powerful attacks against both humans and software systems (aka machines). This paper documents efforts and findings from a comprehensive experimental study on the impact of deep-learning based speech synthesis attacks on both human listeners and machines such as speaker recognition and voice-signin systems. We find that both humans and machines can be reliably fooled by synthetic speech and that existing defenses against synthesized speech fall short. These findings highlight the need to raise awareness and develop new protections against synthetic speech for both humans and machines.
ASR-GLUE: A New Multi-task Benchmark for ASR-Robust Natural Language Understanding
Aug 30, 2021
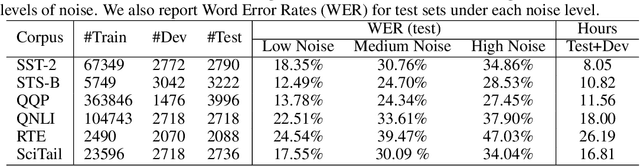
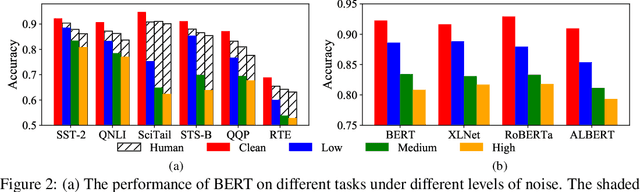

Language understanding in speech-based systems have attracted much attention in recent years with the growing demand for voice interface applications. However, the robustness of natural language understanding (NLU) systems to errors introduced by automatic speech recognition (ASR) is under-examined. %To facilitate the research on ASR-robust general language understanding, In this paper, we propose ASR-GLUE benchmark, a new collection of 6 different NLU tasks for evaluating the performance of models under ASR error across 3 different levels of background noise and 6 speakers with various voice characteristics. Based on the proposed benchmark, we systematically investigate the effect of ASR error on NLU tasks in terms of noise intensity, error type and speaker variants. We further purpose two ways, correction-based method and data augmentation-based method to improve robustness of the NLU systems. Extensive experimental results and analysises show that the proposed methods are effective to some extent, but still far from human performance, demonstrating that NLU under ASR error is still very challenging and requires further research.
Understanding the Effect of Bias in Deep Anomaly Detection
May 16, 2021
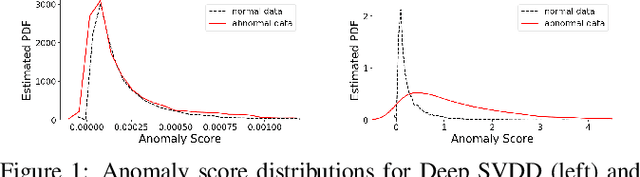

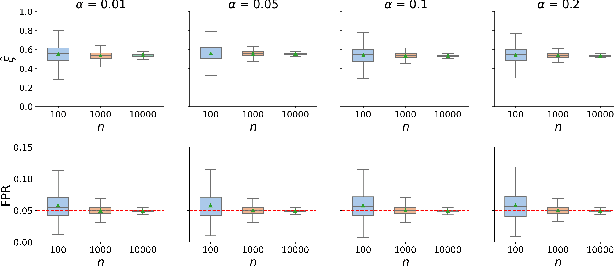
Anomaly detection presents a unique challenge in machine learning, due to the scarcity of labeled anomaly data. Recent work attempts to mitigate such problems by augmenting training of deep anomaly detection models with additional labeled anomaly samples. However, the labeled data often does not align with the target distribution and introduces harmful bias to the trained model. In this paper, we aim to understand the effect of a biased anomaly set on anomaly detection. Concretely, we view anomaly detection as a supervised learning task where the objective is to optimize the recall at a given false positive rate. We formally study the relative scoring bias of an anomaly detector, defined as the difference in performance with respect to a baseline anomaly detector. We establish the first finite sample rates for estimating the relative scoring bias for deep anomaly detection, and empirically validate our theoretical results on both synthetic and real-world datasets. We also provide an extensive empirical study on how a biased training anomaly set affects the anomaly score function and therefore the detection performance on different anomaly classes. Our study demonstrates scenarios in which the biased anomaly set can be useful or problematic, and provides a solid benchmark for future research.