 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Video Representations from Correspondence Proposals
May 20, 2019Correspondences between frames encode rich information about dynamic content in videos. However, it is challenging to effectively capture and learn those due to their irregular structure and complex dynamics. In this paper, we propose a novel neural network that learns video representations by aggregating information from potential correspondences. This network, named $CPNet$, can learn evolving 2D fields with temporal consistency. In particular, it can effectively learn representations for videos by mixing appearance and long-range motion with an RGB-only input. We provide extensive ablation experiments to validate our model. CPNet shows stronger performance than existing methods on Kinetics and achieves the state-of-the-art performance on Something-Something and Jester. We provide analysis towards the behavior of our model and show its robustness to errors in proposals.
Creative Procedural-Knowledge Extraction From Web Design Tutorials
Apr 18, 2019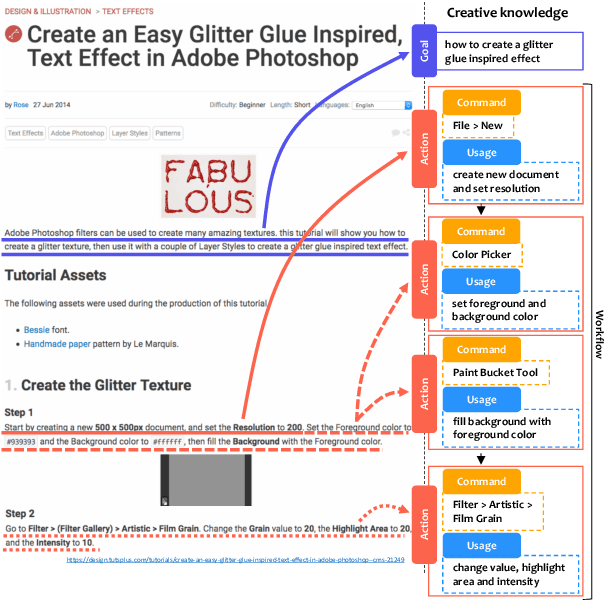

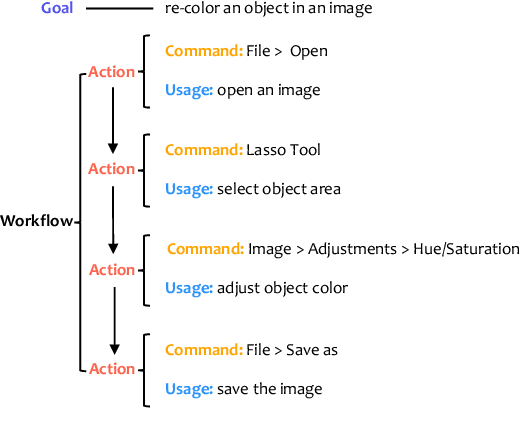
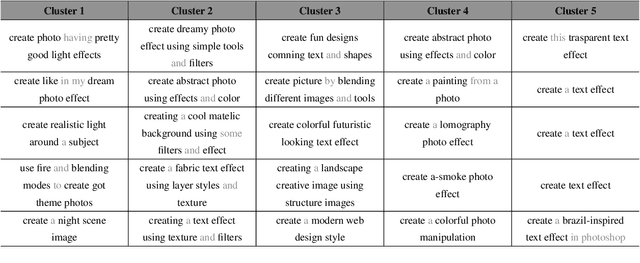
Complex design tasks often require performing diverse actions in a specific order. To (semi-)autonomously accomplish these tasks, applications need to understand and learn a wide range of design procedures, i.e., Creative Procedural-Knowledge (CPK). Prior knowledge base construction and mining have not typically addressed the creative fields, such as design and arts. In this paper, we formalize an ontology of CPK using five components: goal, workflow, action, command and usage; and extract components' values from online design tutorials. We scraped 19.6K tutorial-related webpages and built a web application for professional designers to identify and summarize CPK components. The annotated dataset consists of 819 unique commands, 47,491 actions, and 2,022 workflows and goals. Based on this dataset, we propose a general CPK extraction pipeline and demonstrate that existing text classification and sequence-to-sequence models are limited in identifying, predicting and summarizing complex operations described in heterogeneous styles. Through quantitative and qualitative error analysis, we discuss CPK extraction challenges that need to be addressed by future research.
LiveSketch: Query Perturbations for Guided Sketch-based Visual Search
Apr 14, 2019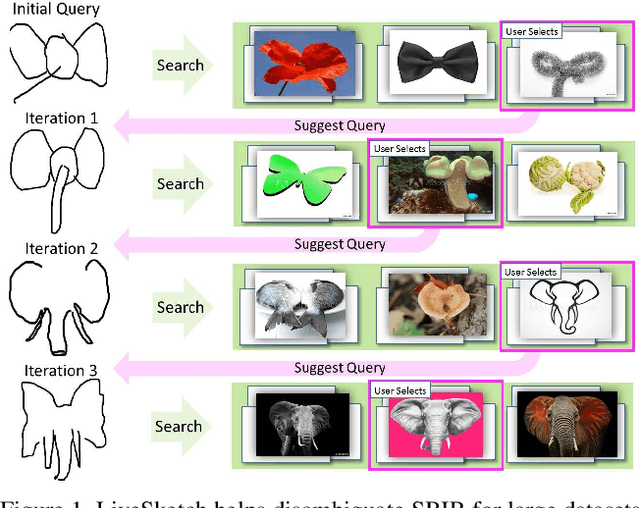

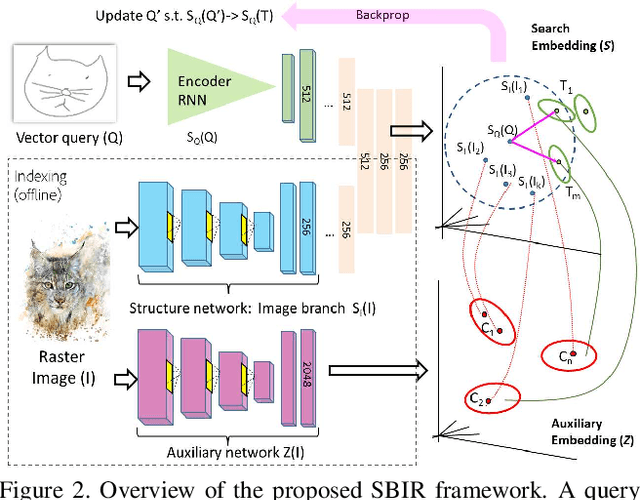
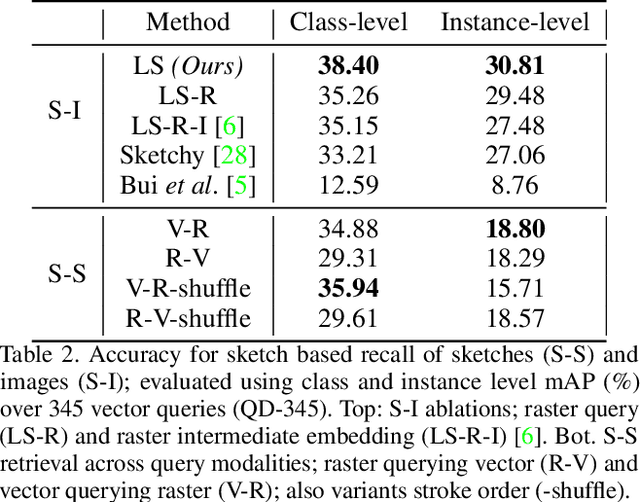
LiveSketch is a novel algorithm for searching large image collections using hand-sketched queries. LiveSketch tackles the inherent ambiguity of sketch search by creating visual suggestions that augment the query as it is drawn, making query specification an iterative rather than one-shot process that helps disambiguate users' search intent. Our technical contributions are: a triplet convnet architecture that incorporates an RNN based variational autoencoder to search for images using vector (stroke-based) queries; real-time clustering to identify likely search intents (and so, targets within the search embedding); and the use of backpropagation from those targets to perturb the input stroke sequence, so suggesting alterations to the query in order to guide the search. We show improvements in accuracy and time-to-task over contemporary baselines using a 67M image corpus.
Visual Font Pairing
Nov 19, 2018
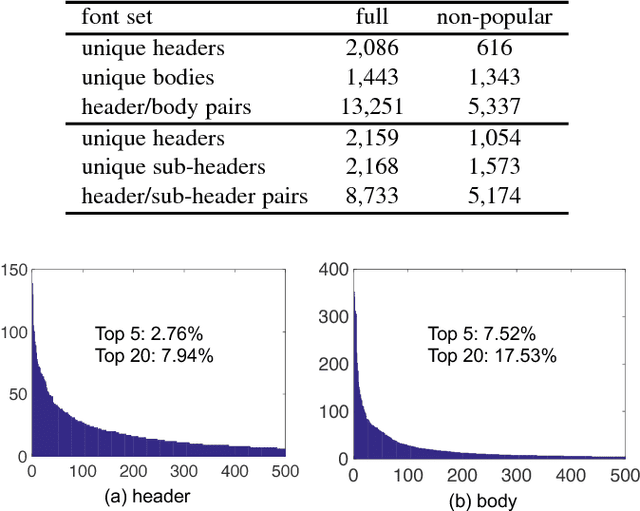

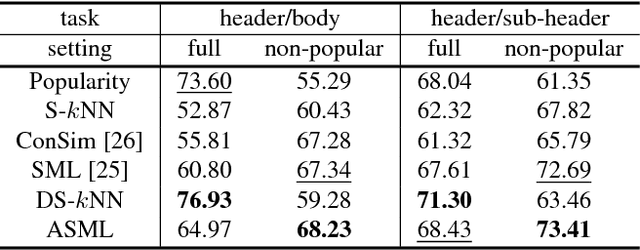
This paper introduces the problem of automatic font pairing. Font pairing is an important design task that is difficult for novices. Given a font selection for one part of a document (e.g., header), our goal is to recommend a font to be used in another part (e.g., body) such that the two fonts used together look visually pleasing. There are three main challenges in font pairing. First, this is a fine-grained problem, in which the subtle distinctions between fonts may be important. Second, rules and conventions of font pairing given by human experts are difficult to formalize. Third, font pairing is an asymmetric problem in that the roles played by header and body fonts are not interchangeable. To address these challenges, we propose automatic font pairing through learning visual relationships from large-scale human-generated font pairs. We introduce a new database for font pairing constructed from millions of PDF documents available on the Internet. We propose two font pairing algorithms: dual-space k-NN and asymmetric similarity metric learning (ASML). These two methods automatically learn fine-grained relationships from large-scale data. We also investigate several baseline methods based on the rules from professional designers. Experiments and user studies demonstrate the effectiveness of our proposed dataset and methods.
"Factual" or "Emotional": Stylized Image Captioning with Adaptive Learning and Attention
Jul 29, 2018
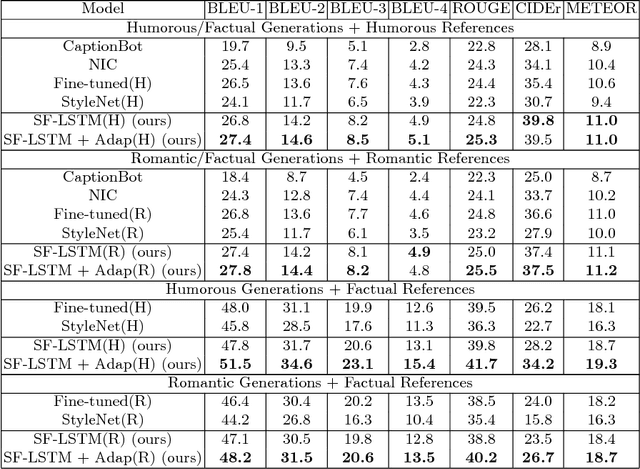
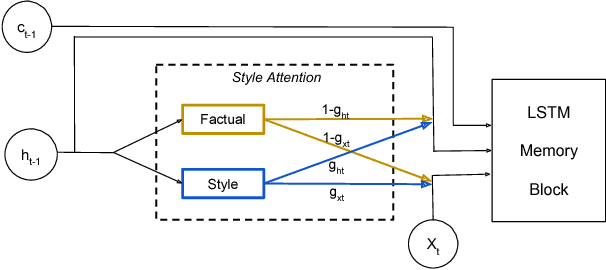
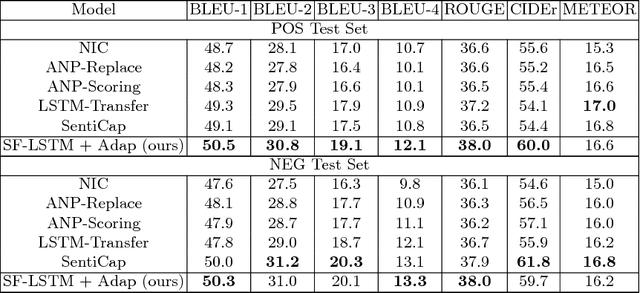
Generating stylized captions for an image is an emerging topic in image captioning. Given an image as input, it requires the system to generate a caption that has a specific style (e.g., humorous, romantic, positive, and negative) while describing the image content semantically accurately. In this paper, we propose a novel stylized image captioning model that effectively takes both requirements into consideration. To this end, we first devise a new variant of LSTM, named style-factual LSTM, as the building block of our model. It uses two groups of matrices to capture the factual and stylized knowledge, respectively, and automatically learns the word-level weights of the two groups based on previous context. In addition, when we train the model to capture stylized elements, we propose an adaptive learning approach based on a reference factual model, it provides factual knowledge to the model as the model learns from stylized caption labels, and can adaptively compute how much information to supply at each time step. We evaluate our model on two stylized image captioning datasets, which contain humorous/romantic captions and positive/negative captions, respectively. Experiments shows that our proposed model outperforms the state-of-the-art approaches, without using extra ground truth supervision.
Towards Privacy-Preserving Visual Recognition via Adversarial Training: A Pilot Study
Jul 22, 2018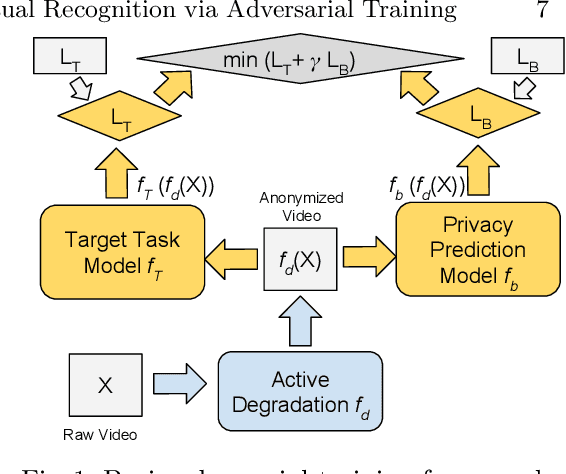
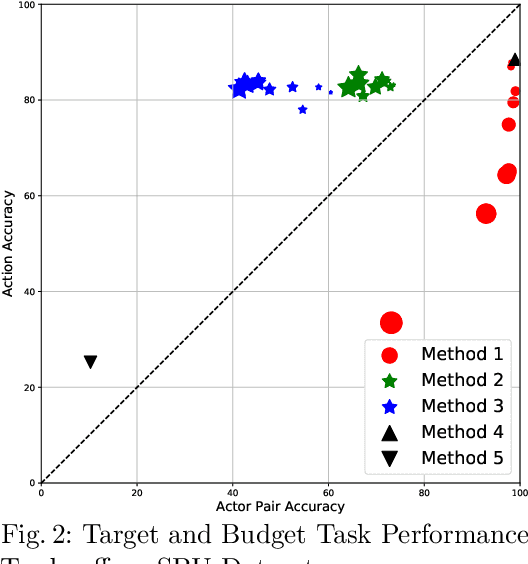
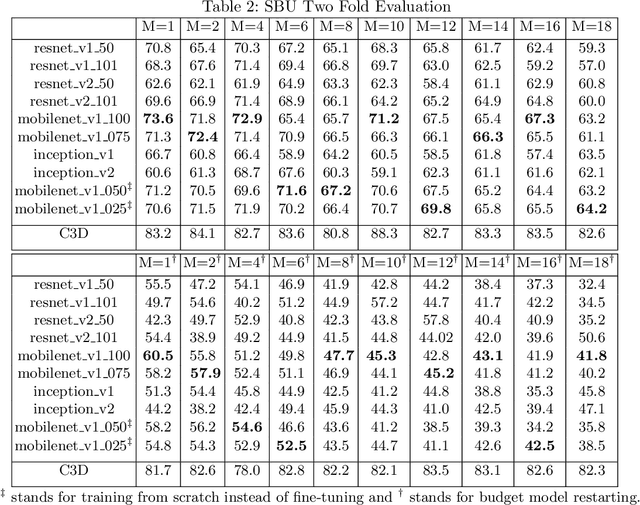
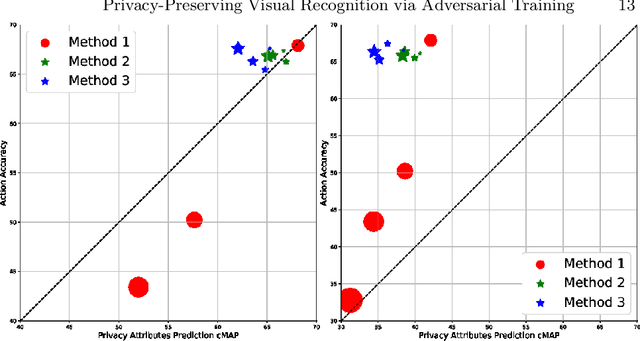
This paper aims to improve privacy-preserving visual recognition, an increasingly demanded feature in smart camera applications, by formulating a unique adversarial training framework. The proposed framework explicitly learns a degradation transform for the original video inputs, in order to optimize the trade-off between target task performance and the associated privacy budgets on the degraded video. A notable challenge is that the privacy budget, often defined and measured in task-driven contexts, cannot be reliably indicated using any single model performance, because a strong protection of privacy has to sustain against any possible model that tries to hack privacy information. Such an uncommon situation has motivated us to propose two strategies, i.e., budget model restarting and ensemble, to enhance the generalization of the learned degradation on protecting privacy against unseen hacker models. Novel training strategies, evaluation protocols, and result visualization methods have been designed accordingly. Two experiments on privacy-preserving action recognition, with privacy budgets defined in various ways, manifest the compelling effectiveness of the proposed framework in simultaneously maintaining high target task (action recognition) performance while suppressing the privacy breach risk.
Speeding up Context-based Sentence Representation Learning with Non-autoregressive Convolutional Decoding
Jun 01, 2018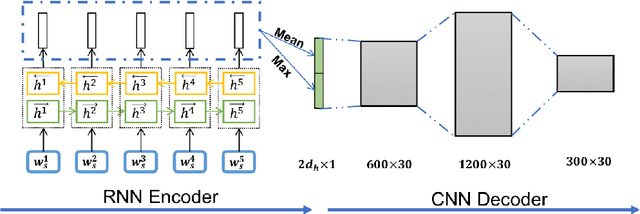
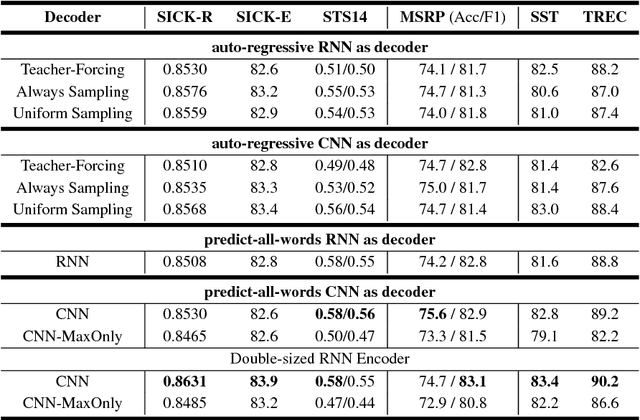
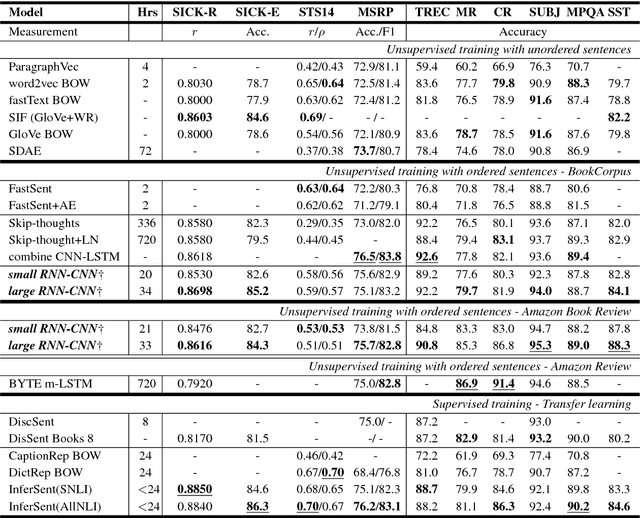
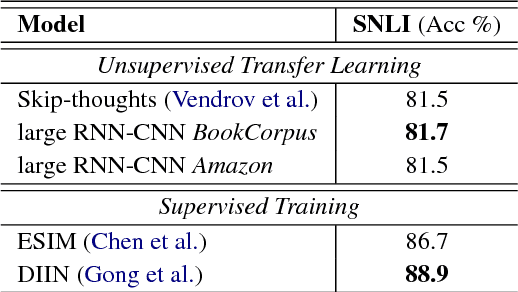
Context plays an important role in human language understanding, thus it may also be useful for machines learning vector representations of language. In this paper, we explore an asymmetric encoder-decoder structure for unsupervised context-based sentence representation learning. We carefully designed experiments to show that neither an autoregressive decoder nor an RNN decoder is required. After that, we designed a model which still keeps an RNN as the encoder, while using a non-autoregressive convolutional decoder. We further combine a suite of effective designs to significantly improve model efficiency while also achieving better performance. Our model is trained on two different large unlabelled corpora, and in both cases the transferability is evaluated on a set of downstream NLP tasks. We empirically show that our model is simple and fast while producing rich sentence representations that excel in downstream tasks.
Beyond Textures: Learning from Multi-domain Artistic Images for Arbitrary Style Transfer
May 25, 2018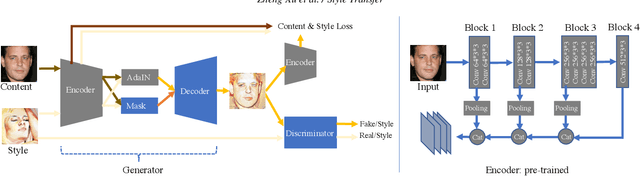



We propose a fast feed-forward network for arbitrary style transfer, which can generate stylized image for previously unseen content and style image pairs. Besides the traditional content and style representation based on deep features and statistics for textures, we use adversarial networks to regularize the generation of stylized images. Our adversarial network learns the intrinsic property of image styles from large-scale multi-domain artistic images. The adversarial training is challenging because both the input and output of our generator are diverse multi-domain images. We use a conditional generator that stylized content by shifting the statistics of deep features, and a conditional discriminator based on the coarse category of styles. Moreover, we propose a mask module to spatially decide the stylization level and stabilize adversarial training by avoiding mode collapse. As a side effect, our trained discriminator can be applied to rank and select representative stylized images. We qualitatively and quantitatively evaluate the proposed method, and compare with recent style transfer methods.
Image Captioning at Will: A Versatile Scheme for Effectively Injecting Sentiments into Image Descriptions
Jan 30, 2018
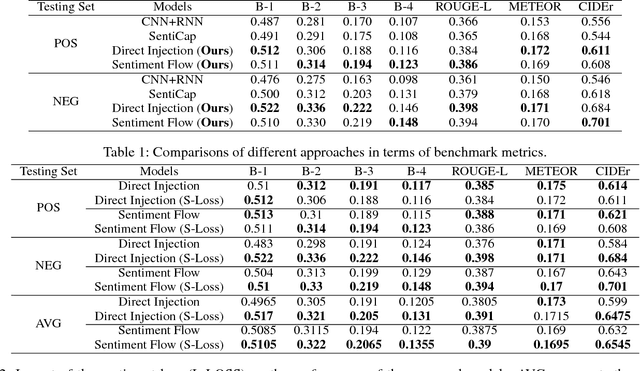
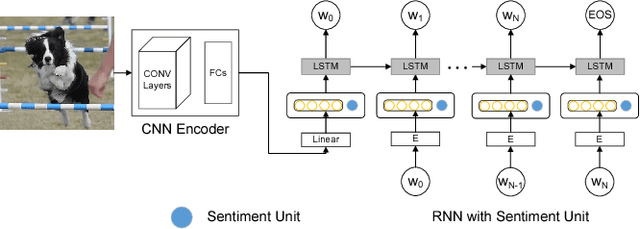
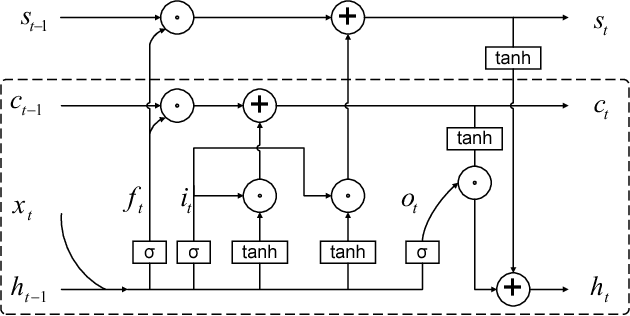
Automatic image captioning has recently approached human-level performance due to the latest advances in computer vision and natural language understanding. However, most of the current models can only generate plain factual descriptions about the content of a given image. However, for human beings, image caption writing is quite flexible and diverse, where additional language dimensions, such as emotion, humor and language styles, are often incorporated to produce diverse, emotional, or appealing captions. In particular, we are interested in generating sentiment-conveying image descriptions, which has received little attention. The main challenge is how to effectively inject sentiments into the generated captions without altering the semantic matching between the visual content and the generated descriptions. In this work, we propose two different models, which employ different schemes for injecting sentiments into image captions. Compared with the few existing approaches, the proposed models are much simpler and yet more effective. The experimental results show that our model outperform the state-of-the-art models in generating sentimental (i.e., sentiment-bearing) image captions. In addition, we can also easily manipulate the model by assigning different sentiments to the testing image to generate captions with the corresponding sentiments.
BAM! The Behance Artistic Media Dataset for Recognition Beyond Photography
Jul 09, 2017
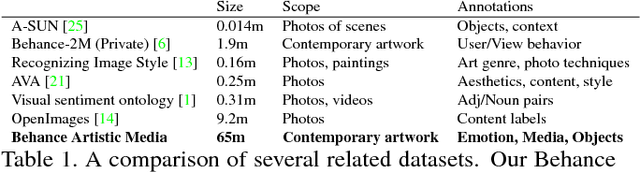

Computer vision systems are designed to work well within the context of everyday photography. However, artists often render the world around them in ways that do not resemble photographs. Artwork produced by people is not constrained to mimic the physical world, making it more challenging for machines to recognize. This work is a step toward teaching machines how to categorize images in ways that are valuable to humans. First, we collect a large-scale dataset of contemporary artwork from Behance, a website containing millions of portfolios from professional and commercial artists. We annotate Behance imagery with rich attribute labels for content, emotions, and artistic media. Furthermore, we carry out baseline experiments to show the value of this dataset for artistic style prediction, for improving the generality of existing object classifiers, and for the study of visual domain adaptation. We believe our Behance Artistic Media dataset will be a good starting point for researchers wishing to study artistic imagery and relevant problems.