 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Multi-Modal Necessarily Better? Robustness Evaluation of Multi-modal Fake News Detection
Jun 17, 2022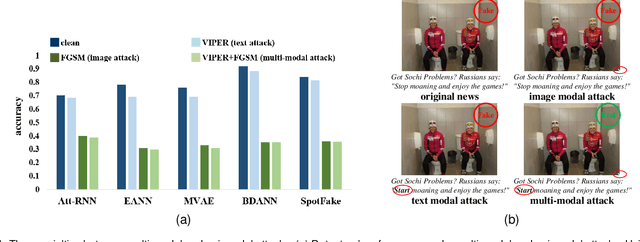

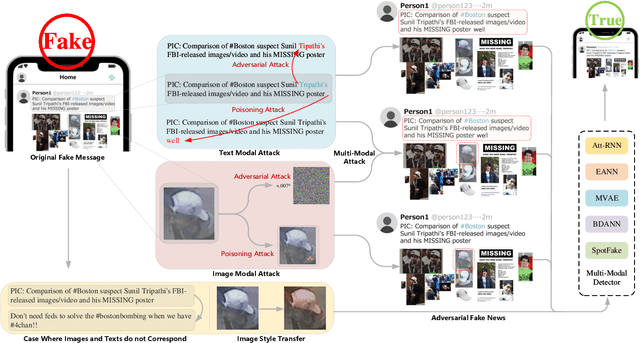

The proliferation of fake news and its serious negative social influence push fake news detection methods to become necessary tools for web managers. Meanwhile, the multi-media nature of social media makes multi-modal fake news detection popular for its ability to capture more modal features than uni-modal detection methods. However, current literature on multi-modal detection is more likely to pursue the detection accuracy but ignore the robustness of the detector. To address this problem, we propose a comprehensive robustness evaluation of multi-modal fake news detectors. In this work, we simulate the attack methods of malicious users and developers, i.e., posting fake news and injecting backdoors. Specifically, we evaluate multi-modal detectors with five adversarial and two backdoor attack methods. Experiment results imply that: (1) The detection performance of the state-of-the-art detectors degrades significantly under adversarial attacks, even worse than general detectors; (2) Most multi-modal detectors are more vulnerable when subjected to attacks on visual modality than textual modality; (3) Popular events' images will cause significant degradation to the detectors when they are subjected to backdoor attacks; (4) The performance of these detectors under multi-modal attacks is worse than under uni-modal attacks; (5) Defensive methods will improve the robustness of the multi-modal detectors.
Rethinking the Defense Against Free-rider Attack From the Perspective of Model Weight Evolving Frequency
Jun 11, 2022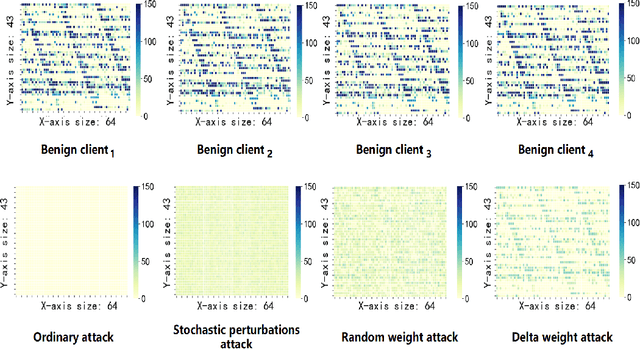
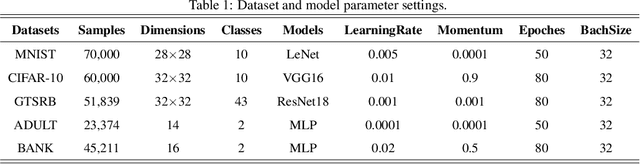
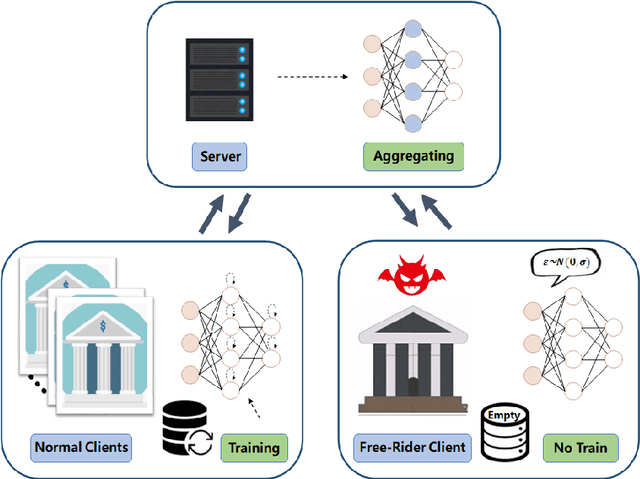
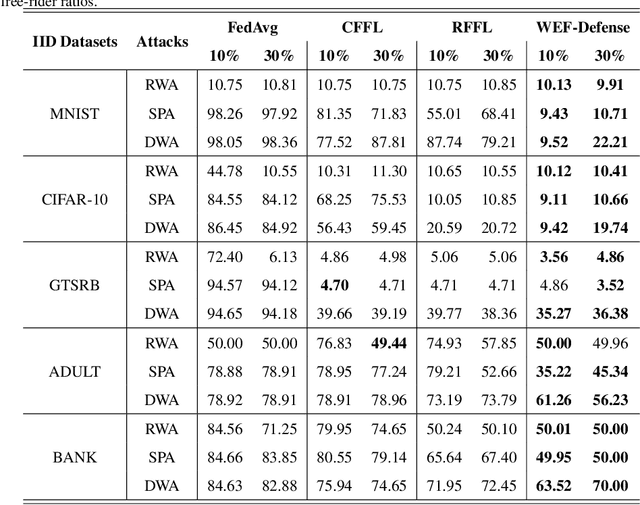
Federated learning (FL) is a distributed machine learning approach where multiple clients collaboratively train a joint model without exchanging their data. Despite FL's unprecedented success in data privacy-preserving, its vulnerability to free-rider attacks has attracted increasing attention. Existing defenses may be ineffective against highly camouflaged or high percentages of free riders. To address these challenges, we reconsider the defense from a novel perspective, i.e., model weight evolving frequency.Empirically, we gain a novel insight that during the FL's training, the model weight evolving frequency of free-riders and that of benign clients are significantly different. Inspired by this insight, we propose a novel defense method based on the model Weight Evolving Frequency, referred to as WEF-Defense.Specifically, we first collect the weight evolving frequency (defined as WEF-Matrix) during local training. For each client, it uploads the local model's WEF-Matrix to the server together with its model weight for each iteration. The server then separates free-riders from benign clients based on the difference in the WEF-Matrix. Finally, the server uses a personalized approach to provide different global models for corresponding clients. Comprehensive experiments conducted on five datasets and five models demonstrate that WEF-Defense achieves better defense effectiveness than the state-of-the-art baselines.
GAIL-PT: A Generic Intelligent Penetration Testing Framework with Generative Adversarial Imitation Learning
Apr 05, 2022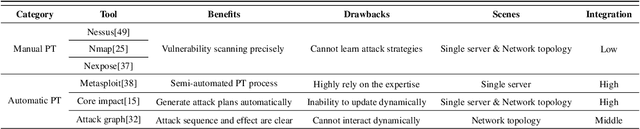
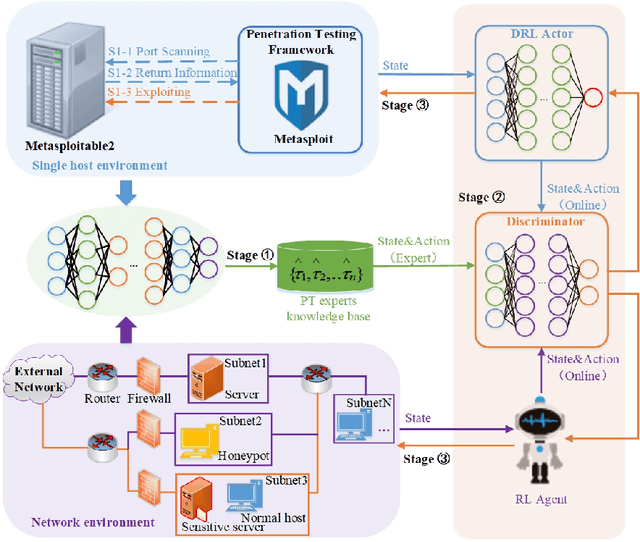

Penetration testing (PT) is an efficient network testing and vulnerability mining tool by simulating a hacker's attack for valuable information applied in some areas. Compared with manual PT, intelligent PT has become a dominating mainstream due to less time-consuming and lower labor costs. Unfortunately, RL-based PT is still challenged in real exploitation scenarios because the agent's action space is usually high-dimensional discrete, thus leading to algorithm convergence difficulty. Besides, most PT methods still rely on the decisions of security experts. Addressing the challenges, for the first time, we introduce expert knowledge to guide the agent to make better decisions in RL-based PT and propose a Generative Adversarial Imitation Learning-based generic intelligent Penetration testing framework, denoted as GAIL-PT, to solve the problems of higher labor costs due to the involvement of security experts and high-dimensional discrete action space. Specifically, first, we manually collect the state-action pairs to construct an expert knowledge base when the pre-trained RL / DRL model executes successful penetration testings. Second, we input the expert knowledge and the state-action pairs generated online by the different RL / DRL models into the discriminator of GAIL for training. At last, we apply the output reward of the discriminator to guide the agent to perform the action with a higher penetration success rate to improve PT's performance. Extensive experiments conducted on the real target host and simulated network scenarios show that GAIL-PT achieves the SOTA penetration performance against DeepExploit in exploiting actual target Metasploitable2 and Q-learning in optimizing penetration path, not only in small-scale with or without honey-pot network environments but also in the large-scale virtual network environment.
DeepSensor: Deep Learning Testing Framework Based on Neuron Sensitivity
Feb 12, 2022



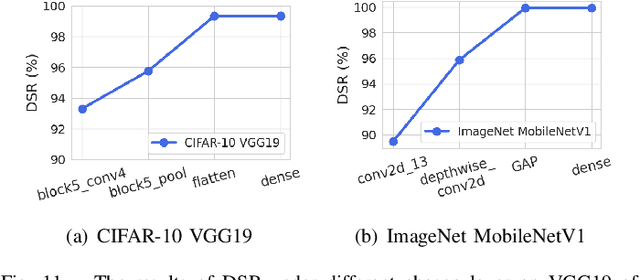
Despite impressive capabilities and outstanding performance, deep neural network(DNN) has captured increasing public concern for its security problem, due to frequent occurrence of erroneous behaviors. Therefore, it is necessary to conduct systematically testing before its deployment to real-world applications. Existing testing methods have provided fine-grained criteria based on neuron coverage and reached high exploratory degree of testing. But there is still a gap between the neuron coverage and model's robustness evaluation. To bridge the gap, we observed that neurons which change the activation value dramatically due to minor perturbation are prone to trigger incorrect corner cases. Motivated by it, we propose neuron sensitivity and develop a novel white-box testing framework for DNN, donated as DeepSensor. The number of sensitive neurons is maximized by particle swarm optimization, thus diverse corner cases could be triggered and neuron coverage be further improved when compared with baselines. Besides, considerable robustness enhancement can be reached when adopting testing examples based on neuron sensitivity for retraining. Extensive experiments implemented on scalable datasets and models can well demonstrate the testing effectiveness and robustness improvement of DeepSensor.
NeuronFair: Interpretable White-Box Fairness Testing through Biased Neuron Identification
Dec 25, 2021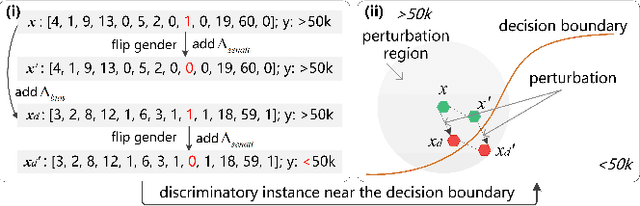
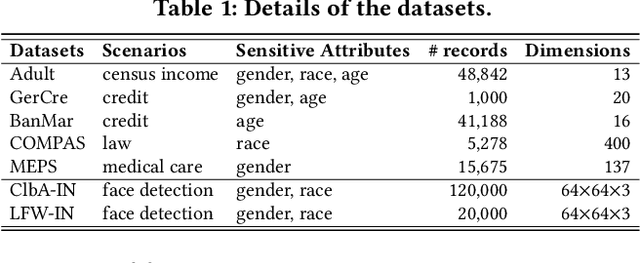
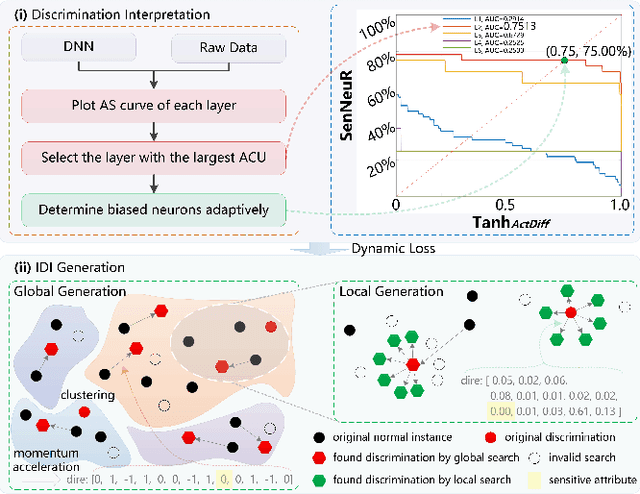
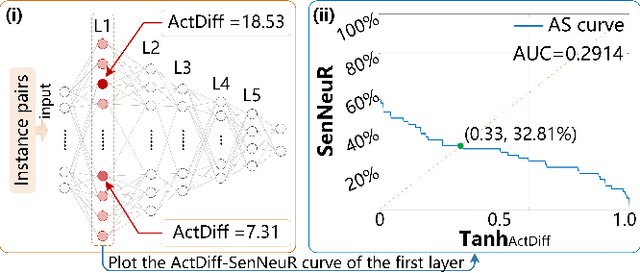
Deep neural networks (DNNs) have demonstrated their outperformance in various domains. However, it raises a social concern whether DNNs can produce reliable and fair decisions especially when they are applied to sensitive domains involving valuable resource allocation, such as education, loan, and employment. It is crucial to conduct fairness testing before DNNs are reliably deployed to such sensitive domains, i.e., generating as many instances as possible to uncover fairness violations. However, the existing testing methods are still limited from three aspects: interpretability, performance, and generalizability. To overcome the challenges, we propose NeuronFair, a new DNN fairness testing framework that differs from previous work in several key aspects: (1) interpretable - it quantitatively interprets DNNs' fairness violations for the biased decision; (2) effective - it uses the interpretation results to guide the generation of more diverse instances in less time; (3) generic - it can handle both structured and unstructured data. Extensive evaluations across 7 datasets and the corresponding DNNs demonstrate NeuronFair's superior performance. For instance, on structured datasets, it generates much more instances (~x5.84) and saves more time (with an average speedup of 534.56%) compared with the state-of-the-art methods. Besides, the instances of NeuronFair can also be leveraged to improve the fairness of the biased DNNs, which helps build more fair and trustworthy deep learning systems.
NIP: Neuron-level Inverse Perturbation Against Adversarial Attacks
Dec 24, 2021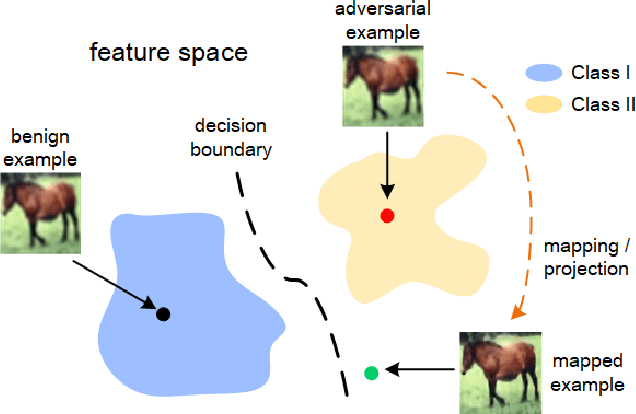

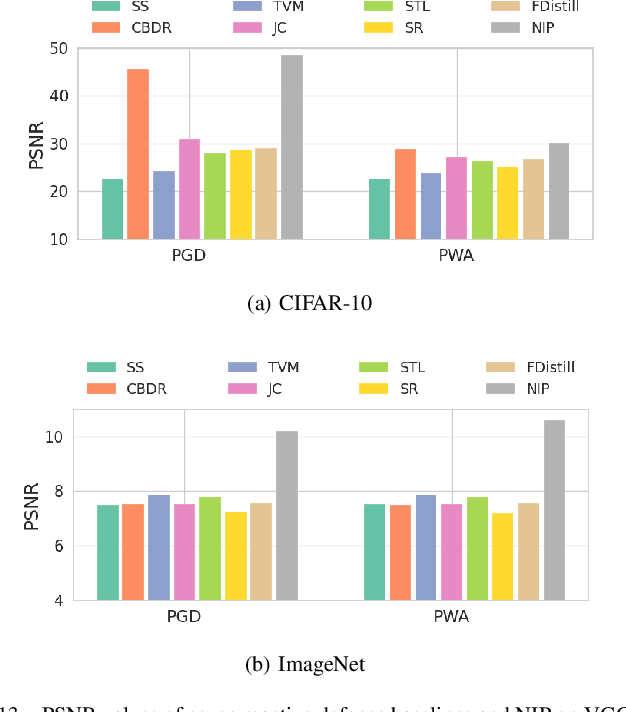
Although deep learning models have achieved unprecedented success, their vulnerabilities towards adversarial attacks have attracted increasing attention, especially when deployed in security-critical domains. To address the challenge, numerous defense strategies, including reactive and proactive ones, have been proposed for robustness improvement. From the perspective of image feature space, some of them cannot reach satisfying results due to the shift of features. Besides, features learned by models are not directly related to classification results. Different from them, We consider defense method essentially from model inside and investigated the neuron behaviors before and after attacks. We observed that attacks mislead the model by dramatically changing the neurons that contribute most and least to the correct label. Motivated by it, we introduce the concept of neuron influence and further divide neurons into front, middle and tail part. Based on it, we propose neuron-level inverse perturbation(NIP), the first neuron-level reactive defense method against adversarial attacks. By strengthening front neurons and weakening those in the tail part, NIP can eliminate nearly all adversarial perturbations while still maintaining high benign accuracy. Besides, it can cope with different sizes of perturbations via adaptivity, especially larger ones. Comprehensive experiments conducted on three datasets and six models show that NIP outperforms the state-of-the-art baselines against eleven adversarial attacks. We further provide interpretable proofs via neuron activation and visualization for better understanding.
Dyn-Backdoor: Backdoor Attack on Dynamic Link Prediction
Oct 08, 2021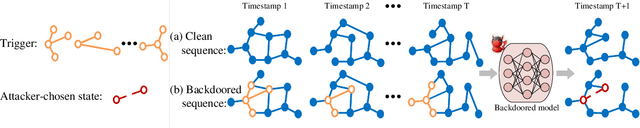
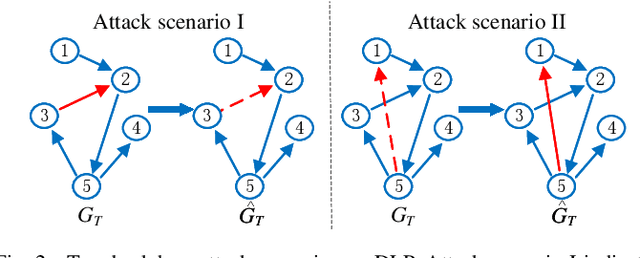
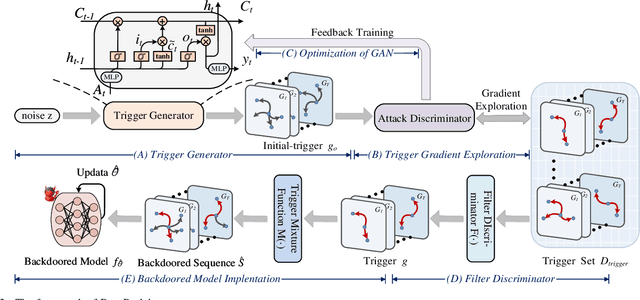
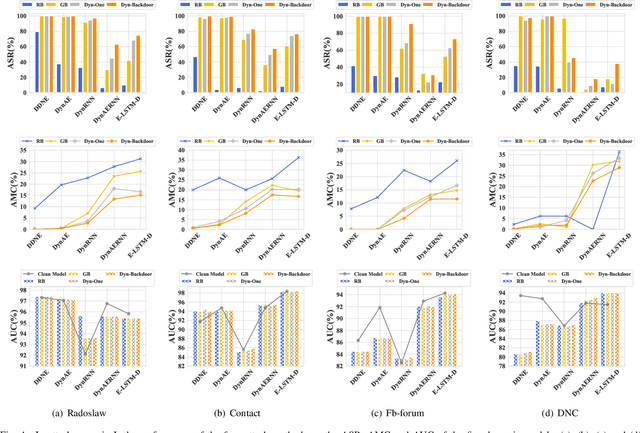
Dynamic link prediction (DLP) makes graph prediction based on historical information. Since most DLP methods are highly dependent on the training data to achieve satisfying prediction performance, the quality of the training data is crucial. Backdoor attacks induce the DLP methods to make wrong prediction by the malicious training data, i.e., generating a subgraph sequence as the trigger and embedding it to the training data. However, the vulnerability of DLP toward backdoor attacks has not been studied yet. To address the issue, we propose a novel backdoor attack framework on DLP, denoted as Dyn-Backdoor. Specifically, Dyn-Backdoor generates diverse initial-triggers by a generative adversarial network (GAN). Then partial links of the initial-triggers are selected to form a trigger set, according to the gradient information of the attack discriminator in the GAN, so as to reduce the size of triggers and improve the concealment of the attack. Experimental results show that Dyn-Backdoor launches successful backdoor attacks on the state-of-the-art DLP models with success rate more than 90%. Additionally, we conduct a possible defense against Dyn-Backdoor to testify its resistance in defensive settings, highlighting the needs of defenses for backdoor attacks on DLP.
Salient Feature Extractor for Adversarial Defense on Deep Neural Networks
May 14, 2021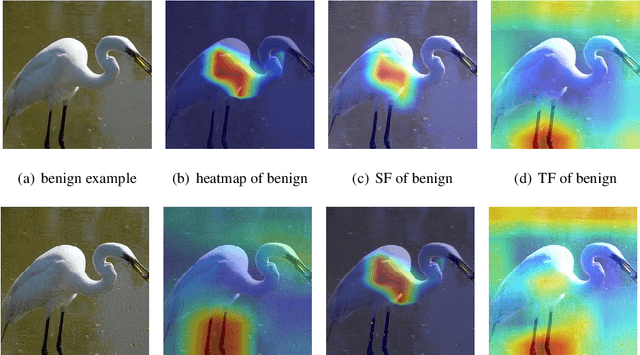

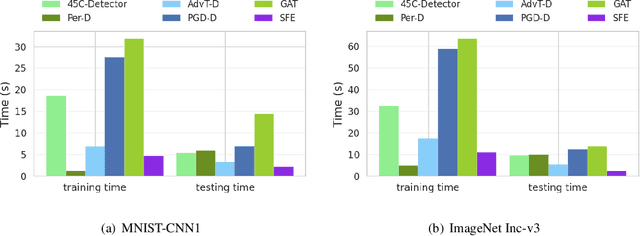
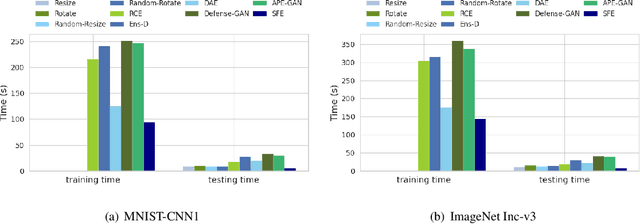
Recent years have witnessed unprecedented success achieved by deep learning models in the field of computer vision. However, their vulnerability towards carefully crafted adversarial examples has also attracted the increasing attention of researchers. Motivated by the observation that adversarial examples are due to the non-robust feature learned from the original dataset by models, we propose the concepts of salient feature(SF) and trivial feature(TF). The former represents the class-related feature, while the latter is usually adopted to mislead the model. We extract these two features with coupled generative adversarial network model and put forward a novel detection and defense method named salient feature extractor (SFE) to defend against adversarial attacks. Concretely, detection is realized by separating and comparing the difference between SF and TF of the input. At the same time, correct labels are obtained by re-identifying SF to reach the purpose of defense. Extensive experiments are carried out on MNIST, CIFAR-10, and ImageNet datasets where SFE shows state-of-the-art results in effectiveness and efficiency compared with baselines. Furthermore, we provide an interpretable understanding of the defense and detection process.
DeepPoison: Feature Transfer Based Stealthy Poisoning Attack
Jan 08, 2021
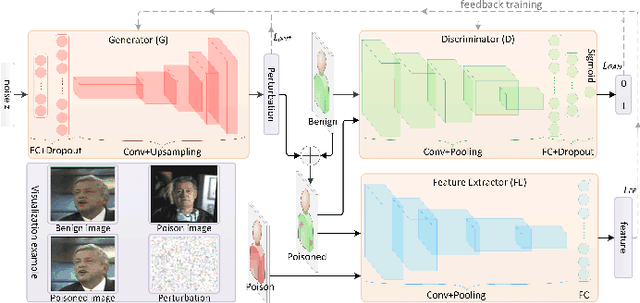
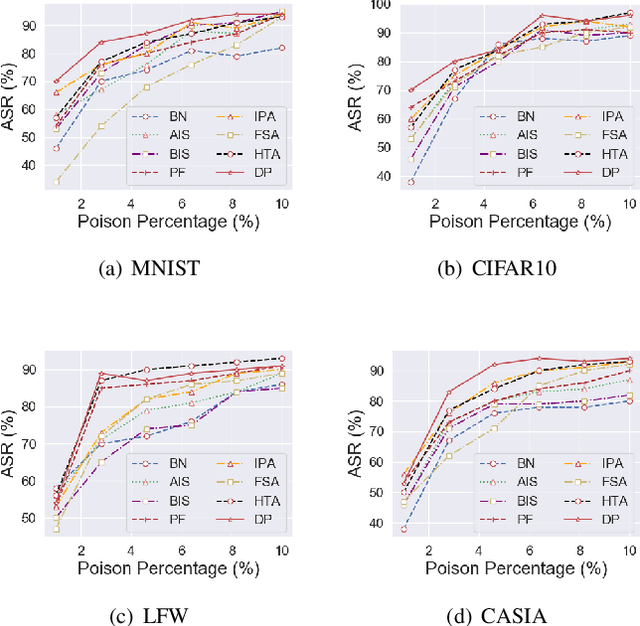
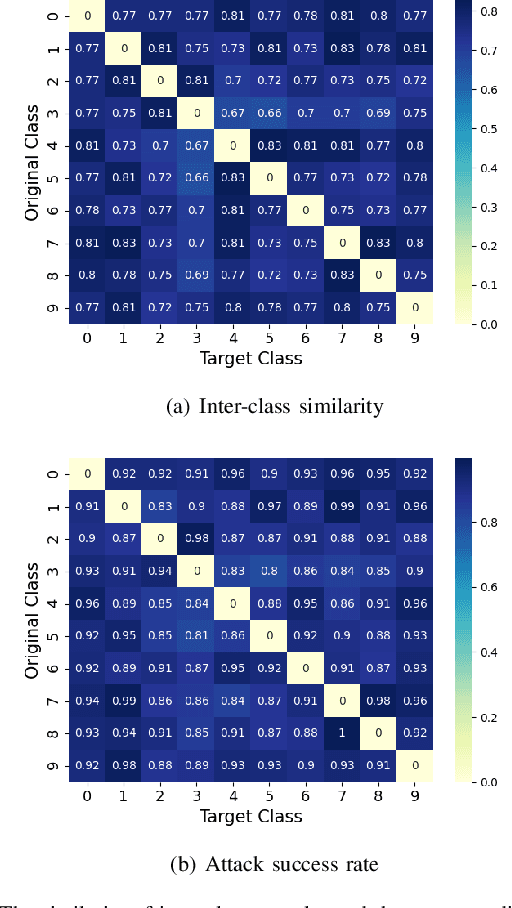
Deep neural networks are susceptible to poisoning attacks by purposely polluted training data with specific triggers. As existing episodes mainly focused on attack success rate with patch-based samples, defense algorithms can easily detect these poisoning samples. We propose DeepPoison, a novel adversarial network of one generator and two discriminators, to address this problem. Specifically, the generator automatically extracts the target class' hidden features and embeds them into benign training samples. One discriminator controls the ratio of the poisoning perturbation. The other discriminator works as the target model to testify the poisoning effects. The novelty of DeepPoison lies in that the generated poisoned training samples are indistinguishable from the benign ones by both defensive methods and manual visual inspection, and even benign test samples can achieve the attack. Extensive experiments have shown that DeepPoison can achieve a state-of-the-art attack success rate, as high as 91.74%, with only 7% poisoned samples on publicly available datasets LFW and CASIA. Furthermore, we have experimented with high-performance defense algorithms such as autodecoder defense and DBSCAN cluster detection and showed the resilience of DeepPoison.
ROBY: Evaluating the Robustness of a Deep Model by its Decision Boundaries
Dec 18, 2020
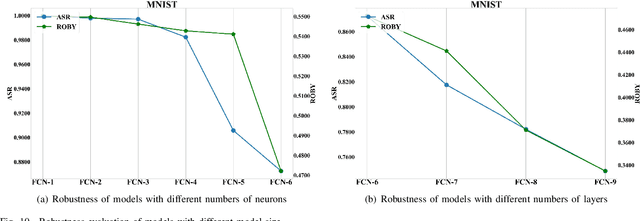
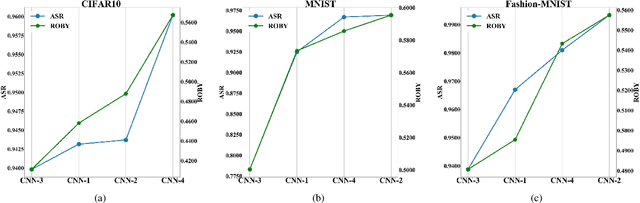
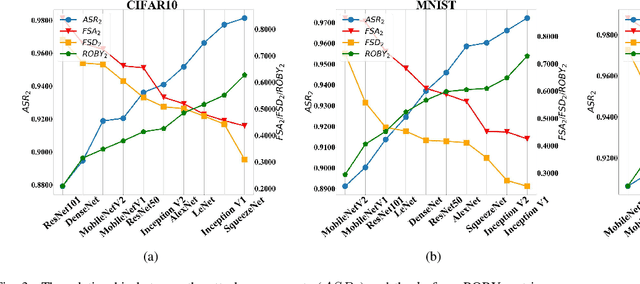
With the successful application of deep learning models in many real-world tasks, the model robustness becomes more and more critical. Often, we evaluate the robustness of the deep models by attacking them with purposely generated adversarial samples, which is computationally costly and dependent on the specific attackers and the model types. This work proposes a generic evaluation metric ROBY, a novel attack-independent robustness measure based on the model's decision boundaries. Independent of adversarial samples, ROBY uses the inter-class and intra-class statistic features to capture the features of the model's decision boundaries. We experimented on ten state-of-the-art deep models and showed that ROBY matches the robustness gold standard of attack success rate (ASR) by a strong first-order generic attacker. with only 1% of time cost. To the best of our knowledge, ROBY is the first lightweight attack-independent robustness evaluation metric that can be applied to a wide range of deep models. The code of ROBY is open sourced at https://github.com/baaaad/ROBY-Evaluating-the-Robustness-of-a-Deep-Model-by-its-Decision-Boundaries.