 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Greedy Dependency Parsing
Nov 20, 2019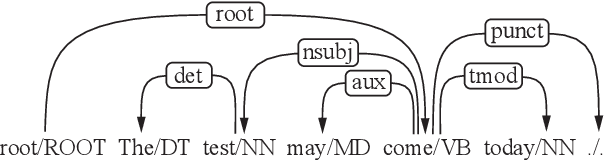
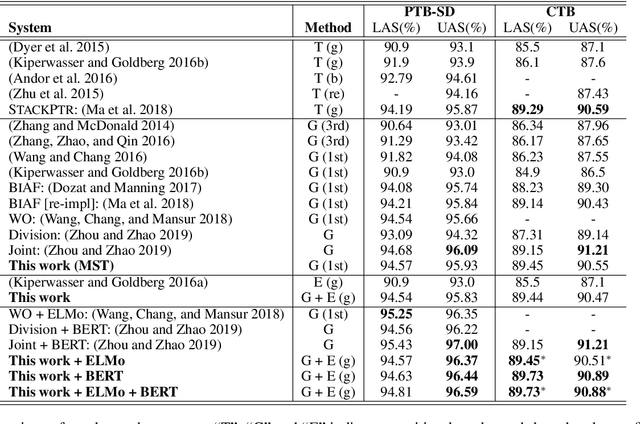
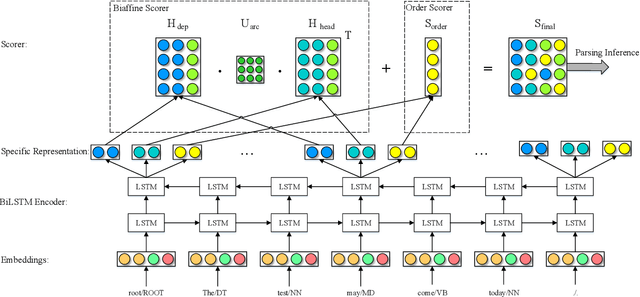
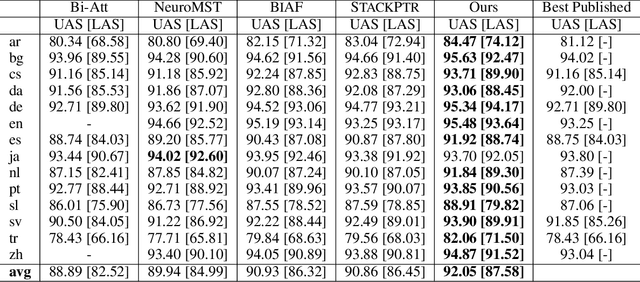
Most syntactic dependency parsing models may fall into one of two categories: transition- and graph-based models. The former models enjoy high inference efficiency with linear time complexity, but they rely on the stacking or re-ranking of partially-built parse trees to build a complete parse tree and are stuck with slower training for the necessity of dynamic oracle training. The latter, graph-based models, may boast better performance but are unfortunately marred by polynomial time inference. In this paper, we propose a novel parsing order objective, resulting in a novel dependency parsing model capable of both global (in sentence scope) feature extraction as in graph models and linear time inference as in transitional models. The proposed global greedy parser only uses two arc-building actions, left and right arcs, for projective parsing. When equipped with two extra non-projective arc-building actions, the proposed parser may also smoothly support non-projective parsing. Using multiple benchmark treebanks, including the Penn Treebank (PTB), the CoNLL-X treebanks, and the Universal Dependency Treebanks, we evaluate our parser and demonstrate that the proposed novel parser achieves good performance with faster training and decoding.
Hierarchical Contextualized Representation for Named Entity Recognition
Nov 19, 2019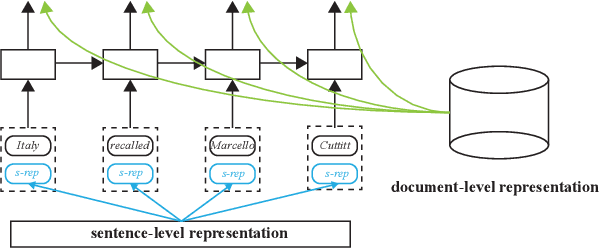

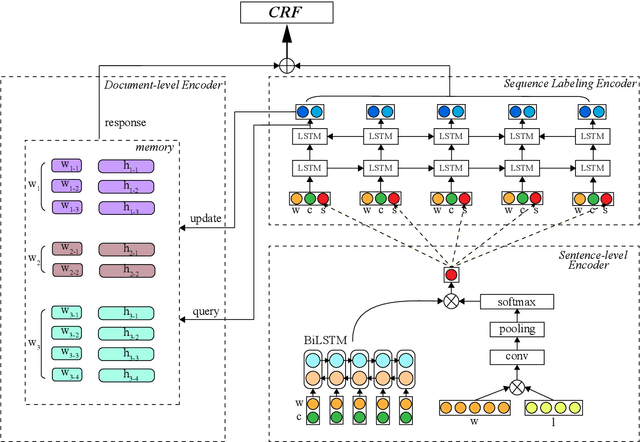
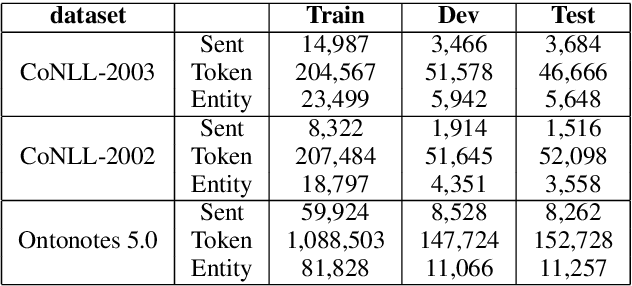
Named entity recognition (NER) models are typically based on the architecture of Bi-directional LSTM (BiLSTM). The constraints of sequential nature and the modeling of single input prevent the full utilization of global information from larger scope, not only in the entire sentence, but also in the entire document (dataset). In this paper, we address these two deficiencies and propose a model augmented with hierarchical contextualized representation: sentence-level representation and document-level representation. In sentence-level, we take different contributions of words in a single sentence into consideration to enhance the sentence representation learned from an independent BiLSTM via label embedding attention mechanism. In document-level, the key-value memory network is adopted to record the document-aware information for each unique word which is sensitive to similarity of context information. Our two-level hierarchical contextualized representations are fused with each input token embedding and corresponding hidden state of BiLSTM, respectively. The experimental results on three benchmark NER datasets (CoNLL-2003 and Ontonotes 5.0 English datasets, CoNLL-2002 Spanish dataset) show that we establish new state-of-the-art results.
Probing Contextualized Sentence Representations with Visual Awareness
Nov 07, 2019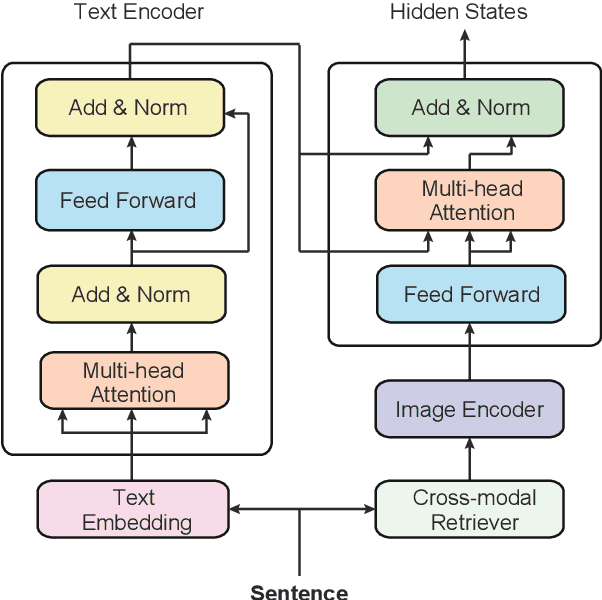
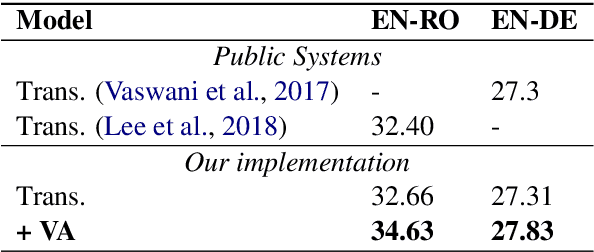
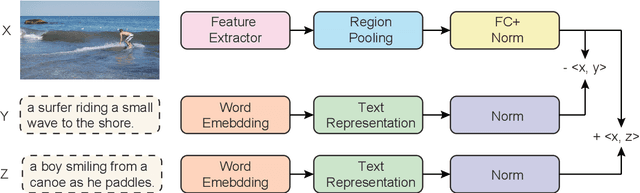
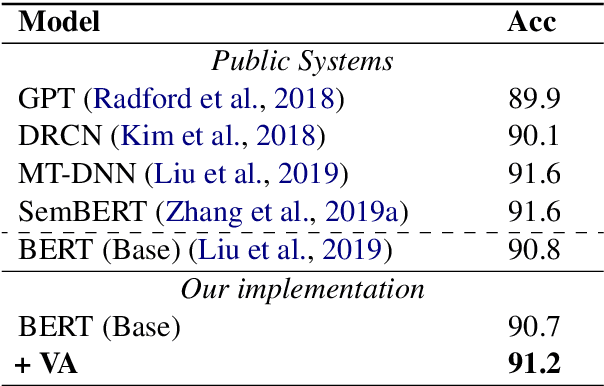
We present a universal framework to model contextualized sentence representations with visual awareness that is motivated to overcome the shortcomings of the multimodal parallel data with manual annotations. For each sentence, we first retrieve a diversity of images from a shared cross-modal embedding space, which is pre-trained on a large-scale of text-image pairs. Then, the texts and images are respectively encoded by transformer encoder and convolutional neural network. The two sequences of representations are further fused by a simple and effective attention layer. The architecture can be easily applied to text-only natural language processing tasks without manually annotating multimodal parallel corpora. We apply the proposed method on three tasks, including neural machine translation, natural language inference and sequence labeling and experimental results verify the effectiveness.
Dependency and Span, Cross-Style Semantic Role Labeling on PropBank and NomBank
Nov 07, 2019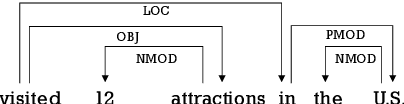
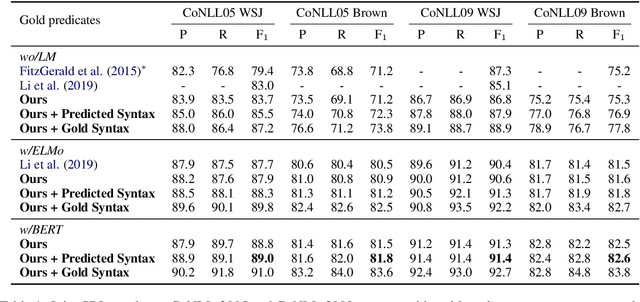
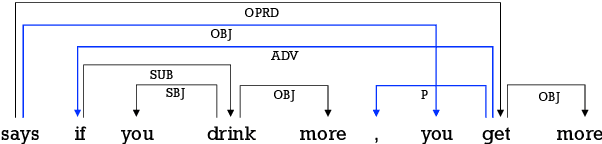
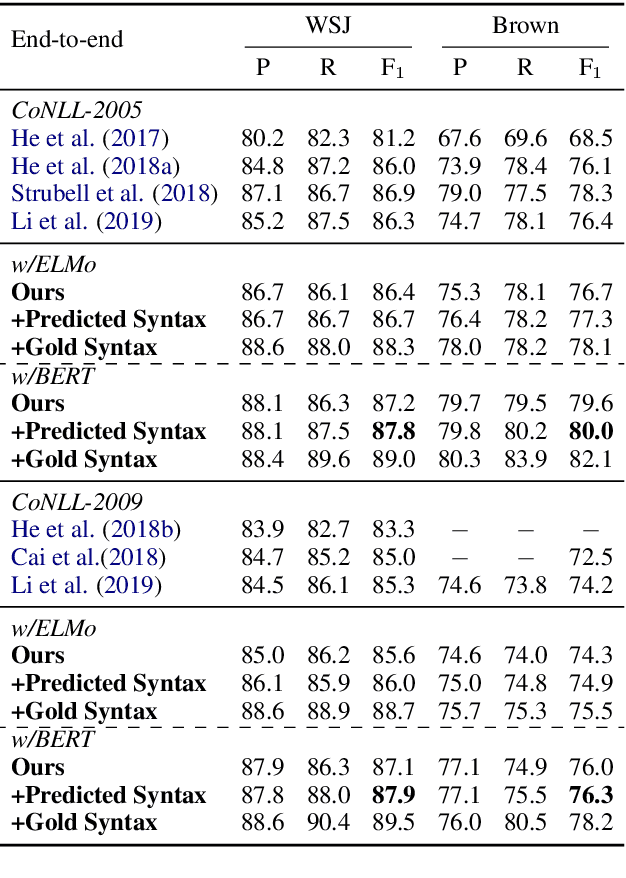
The latest developments in neural semantic role labeling (SRL), including both dependency and span representation formalisms, have shown great performance improvements. Although the two styles share many similarities in linguistic meaning and computation, most previous studies focus on a single style. In this paper, we define a new cross-style semantic role label convention and propose a new cross-style joint optimization model designed according to the linguistic meaning of semantic role, which provides an agreed way to make the results of two styles more comparable and let both types of SRL enjoy their natural connection on both linguistics and computation. Our model learns a general semantic argument structure and is capable of outputting optional style alone. Additionally, we propose a syntax aided method to enhance the learning of both dependency and span representations uniformly. Experiments show that the proposed methods are effective on both span (CoNLL-2005) and dependency (CoNLL-2009) SRL benchmarks.
Deepening Hidden Representations from Pre-trained Language Models for Natural Language Understanding
Nov 05, 2019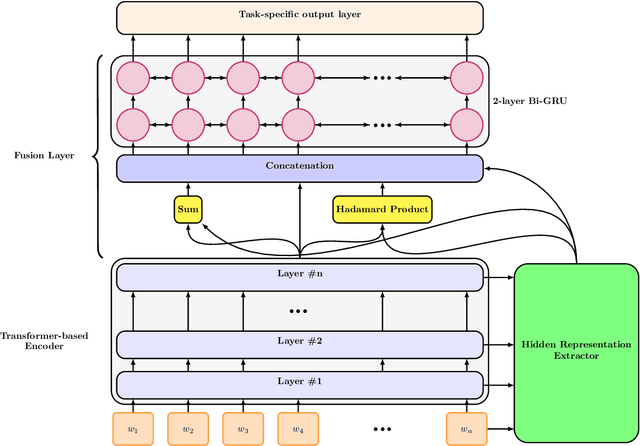
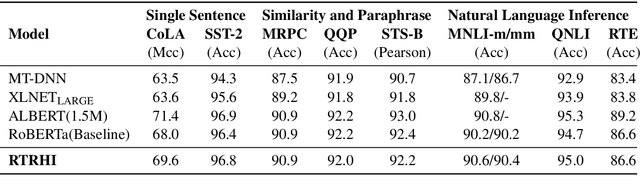
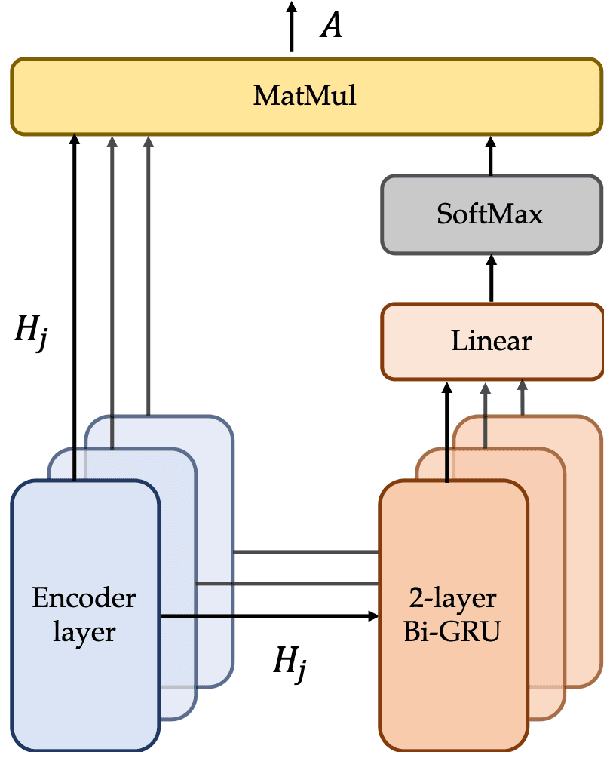
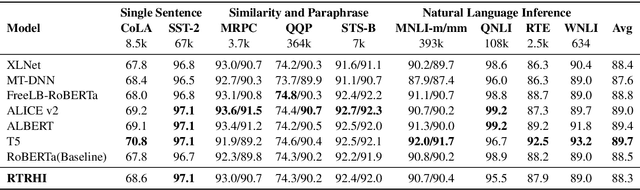
Transformer-based pre-trained language models have proven to be effective for learning contextualized language representation. However, current approaches only take advantage of the output of the encoder's final layer when fine-tuning the downstream tasks. We argue that only taking single layer's output restricts the power of pre-trained representation. Thus we deepen the representation learned by the model by fusing the hidden representation in terms of an explicit HIdden Representation Extractor (HIRE), which automatically absorbs the complementary representation with respect to the output from the final layer. Utilizing RoBERTa as the backbone encoder, our proposed improvement over the pre-trained models is shown effective on multiple natural language understanding tasks and help our model rival with the state-of-the-art models on the GLUE benchmark.
Attention Is All You Need for Chinese Word Segmentation
Oct 31, 2019
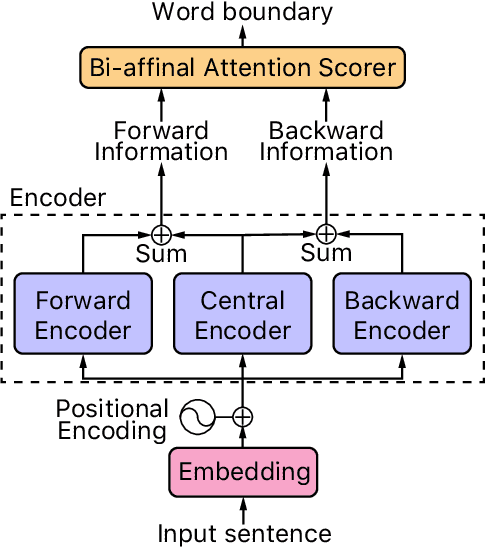
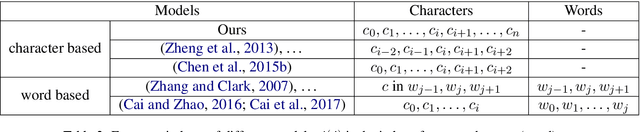
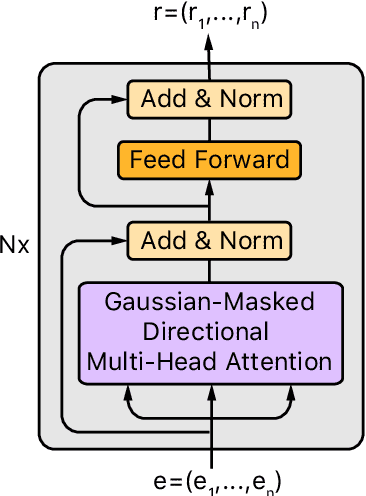
This paper presents a fast and accurate Chinese word segmentation (CWS) model with only unigram feature and greedy decoding algorithm. Our model uses only attention mechanism for network block building. In detail, we adopt a Transformer-based encoder empowered by self-attention mechanism as backbone to take input representation. Then we extend the Transformer encoder with our proposed Gaussian-masked directional multi-head attention, which is a variant of scaled dot-product attention. At last, a bi-affinal attention scorer is to make segmentation decision in a linear time. Our model is evaluated on SIGHAN Bakeoff benchmark dataset. The experimental results show that with the highest segmentation speed, the proposed attention-only model achieves new state-of-the-art or comparable performance against strong baselines in terms of closed test setting.
Document-level Neural Machine Translation with Inter-Sentence Attention
Oct 31, 2019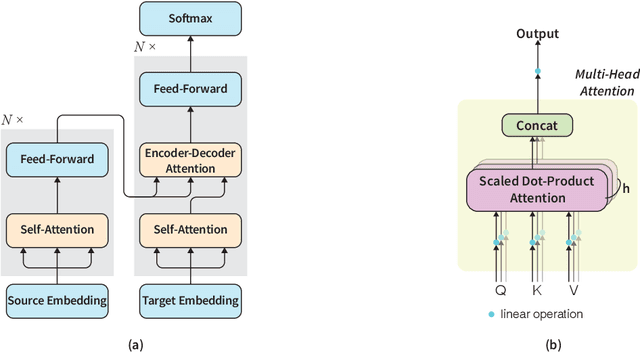
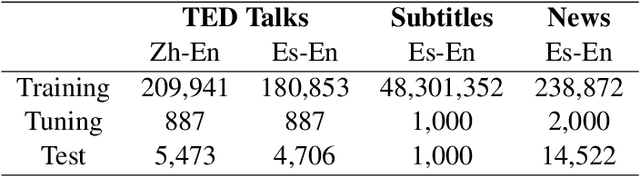
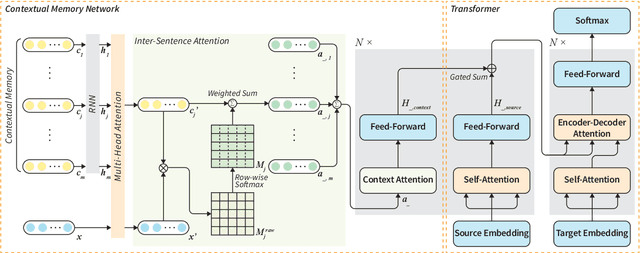
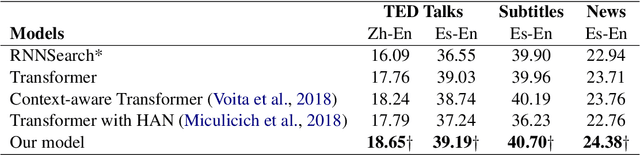
Standard neural machine translation (NMT) is on the assumption of document-level context independent. Most existing document-level NMT methods only focus on briefly introducing document-level information but fail to concern about selecting the most related part inside document context. The capacity of memory network for detecting the most relevant part of the current sentence from the memory provides a natural solution for the requirement of modeling document-level context by document-level NMT. In this work, we propose a Transformer NMT system with associated memory network (AMN) to both capture the document-level context and select the most salient part related to the concerned translation from the memory. Experiments on several tasks show that the proposed method significantly improves the NMT performance over strong Transformer baselines and other related studies.
LIMIT-BERT : Linguistic Informed Multi-Task BERT
Oct 31, 2019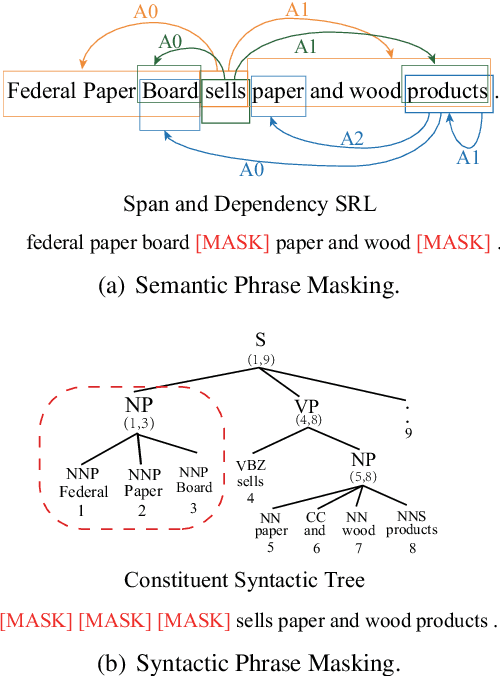

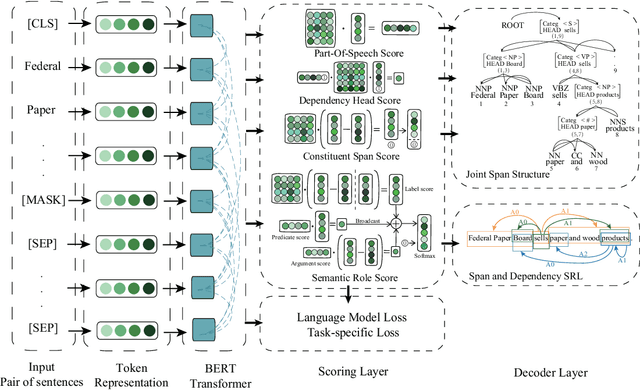
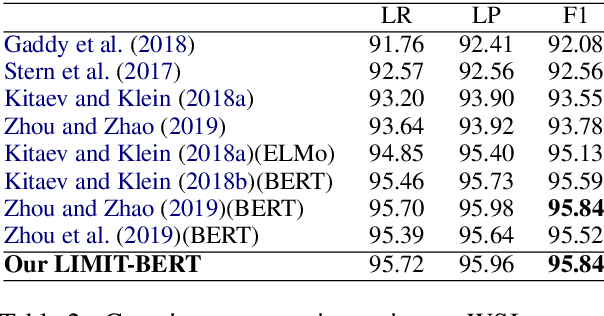
In this paper, we present a Linguistic Informed Multi-Task BERT (LIMIT-BERT) for learning language representations across multiple linguistic tasks by Multi-Task Learning (MTL). LIMIT-BERT includes five key linguistic syntax and semantics tasks: Part-Of-Speech (POS) tags, constituent and dependency syntactic parsing, span and dependency semantic role labeling (SRL). Besides, LIMIT-BERT adopts linguistics mask strategy: Syntactic and Semantic Phrase Masking which mask all of the tokens corresponding to a syntactic/semantic phrase. Different from recent Multi-Task Deep Neural Networks (MT-DNN) (Liu et al., 2019), our LIMIT-BERT is linguistically motivated and learning in a semi-supervised method which provides large amounts of linguistic-task data as same as BERT learning corpus. As a result, LIMIT-BERT not only improves linguistic tasks performance but also benefits from a regularization effect and linguistic information that leads to more general representations to help adapt to new tasks and domains. LIMIT-BERT obtains new state-of-the-art or competitive results on both span and dependency semantic parsing on Propbank benchmarks and both dependency and constituent syntactic parsing on Penn Treebank.
Subword ELMo
Sep 18, 2019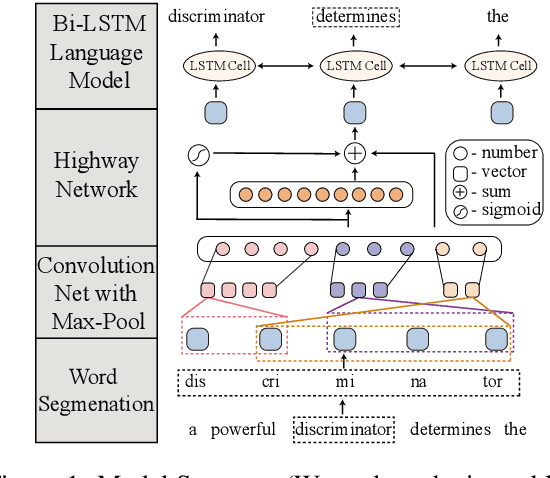
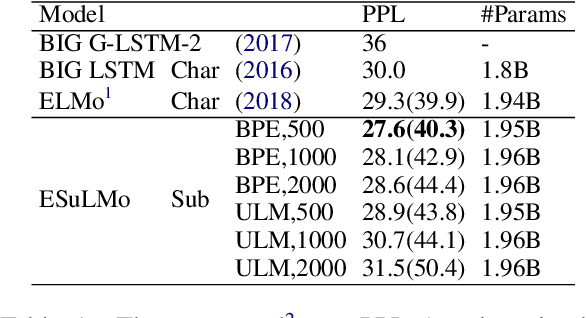
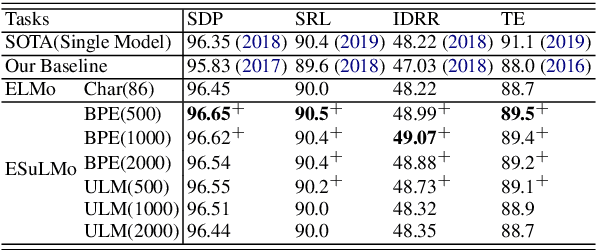
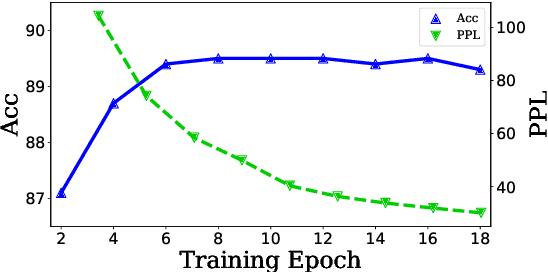
Embedding from Language Models (ELMo) has shown to be effective for improving many natural language processing (NLP) tasks, and ELMo takes character information to compose word representation to train language models.However, the character is an insufficient and unnatural linguistic unit for word representation.Thus we introduce Embedding from Subword-aware Language Models (ESuLMo) which learns word representation from subwords using unsupervised segmentation over words.We show that ESuLMo can enhance four benchmark NLP tasks more effectively than ELMo, including syntactic dependency parsing, semantic role labeling, implicit discourse relation recognition and textual entailment, which brings a meaningful improvement over ELMo.
A Smart Sliding Chinese Pinyin Input Method Editor on Touchscreen
Sep 11, 2019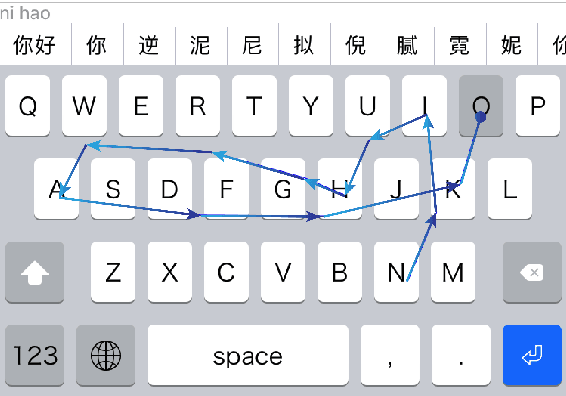

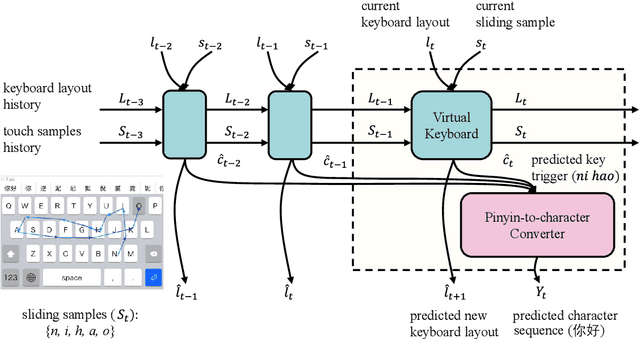

This paper presents a smart sliding Chinese pinyin Input Method Editor (IME) for touchscreen devices which allows user finger sliding from one key to another on the touchscreen instead of tapping keys one by one, while the target Chinese character sequence will be predicted during the sliding process to help user input Chinese characters efficiently. Moreover, the layout of the virtual keyboard of our IME adapts to user sliding for more efficient inputting. The layout adaption process is utilized with Recurrent Neural Networks (RNN) and deep reinforcement learning. The pinyin-to-character converter is implemented with a sequence-to-sequence (Seq2Seq) model to predict the target Chinese sequence. A sliding simulator is built to automatically produce sliding samples for model training and virtual keyboard test. The key advantage of our proposed IME is that nearly all its built-in tactics can be optimized automatically with deep learning algorithms only following user behavior. Empirical studies verify the effectiveness of the proposed model and show a better user input efficiency.