 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyntax-aware Data Augmentation for Neural Machine Translation
Apr 29, 2020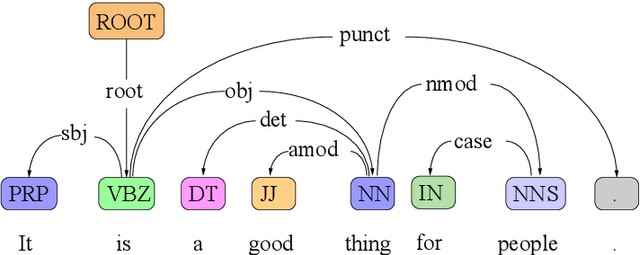
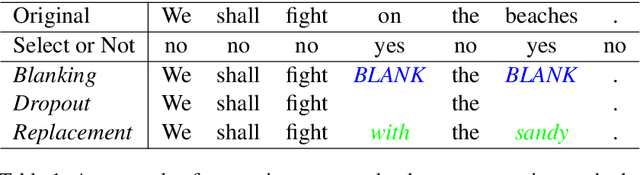
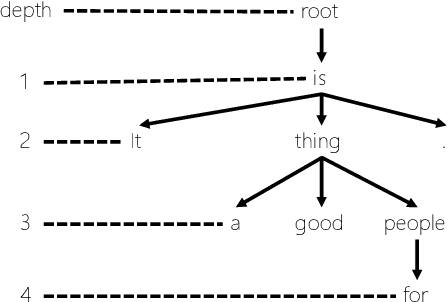
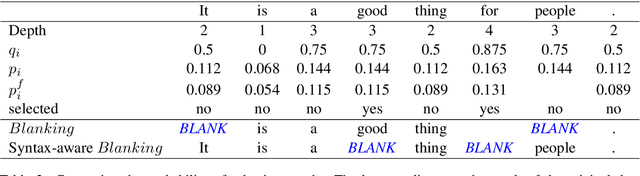
Data augmentation is an effective performance enhancement in neural machine translation (NMT) by generating additional bilingual data. In this paper, we propose a novel data augmentation enhancement strategy for neural machine translation. Different from existing data augmentation methods which simply choose words with the same probability across different sentences for modification, we set sentence-specific probability for word selection by considering their roles in sentence. We use dependency parse tree of input sentence as an effective clue to determine selecting probability for every words in each sentence. Our proposed method is evaluated on WMT14 English-to-German dataset and IWSLT14 German-to-English dataset. The result of extensive experiments show our proposed syntax-aware data augmentation method may effectively boost existing sentence-independent methods for significant translation performance improvement.
Multi-choice Dialogue-Based Reading Comprehension with Knowledge and Key Turns
Apr 29, 2020
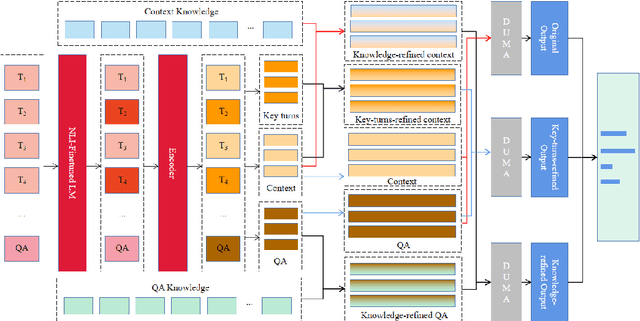

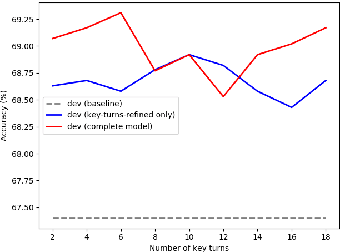
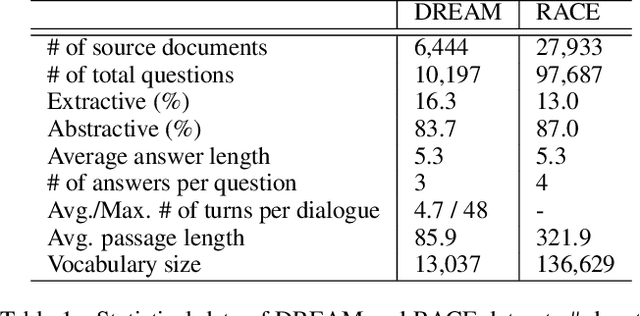
Multi-choice machine reading comprehension (MRC) requires models to choose the correct answer from candidate options given a passage and a question. Our research focuses dialogue-based MRC, where the passages are multi-turn dialogues. It suffers from two challenges, the answer selection decision is made without support of latently helpful commonsense, and the multi-turn context may hide considerable irrelevant information. This work thus makes the first attempt to tackle those two challenges by extracting substantially important turns and utilizing external knowledge to enhance the representation of context. In this paper, the relevance of each turn to the question are calculated to choose key turns. Besides, terms related to the context and the question in a knowledge graph are extracted as external knowledge. The original context, question and external knowledge are encoded with the pre-trained language model, then the language representation and key turns are combined together with a will-designed mechanism to predict the answer. Experimental results on a DREAM dataset show that our proposed model achieves great improvements on baselines.
Learning Better Universal Representations from Pre-trained Contextualized Language Models
Apr 29, 2020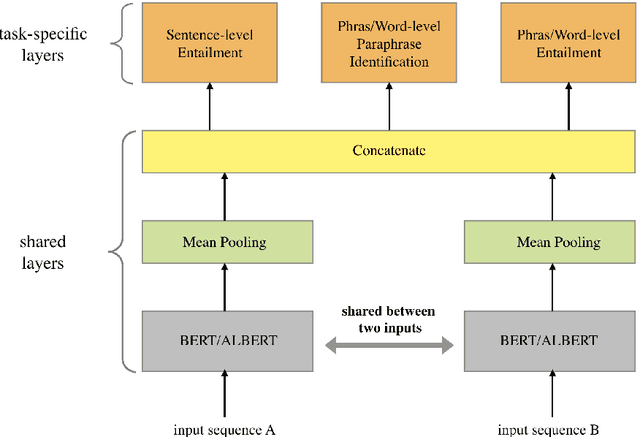
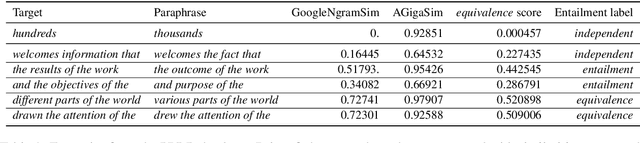
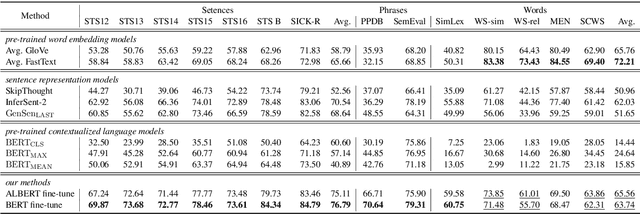
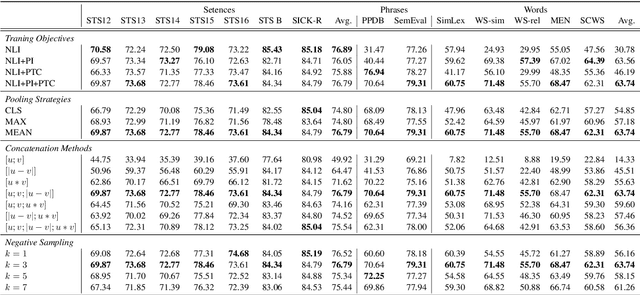
Pre-trained contextualized language models such as BERT have shown great effectiveness in a wide range of downstream natural language processing (NLP) tasks. However, the effective representations offered by the models target at each token inside a sequence rather than each sequence and the fine-tuning step involves the input of both sequences at one time, leading to unsatisfying representation of each individual sequence. Besides, as sentence-level representations taken as the full training context in these models, there comes inferior performance on lower-level linguistic units (phrases and words). In this work, we present a novel framework on BERT that is capable of generating universal, fixed-size representations for input sequences of any lengths, i.e., words, phrases, and sentences, using a large scale of natural language inference and paraphrase data with multiple training objectives. Our proposed framework adopts the Siamese network, learning sentence-level representations from natural language inference dataset and phrase and word-level representations from paraphrasing dataset, respectively. We evaluate our model across different granularity of text similarity tasks, including STS tasks, SemEval2013 Task 5(a) and some commonly used word similarity tasks, where our model substantially outperforms other representation models on sentence-level datasets and achieves significant improvements in word-level and phrase-level representation.
Semantics-Aware Inferential Network for Natural Language Understanding
Apr 28, 2020
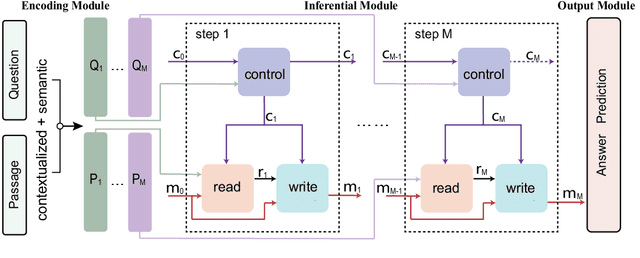
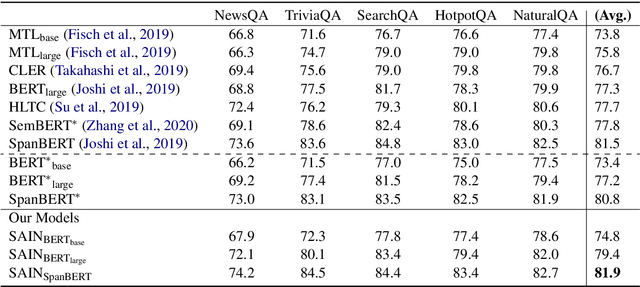
For natural language understanding tasks, either machine reading comprehension or natural language inference, both semantics-aware and inference are favorable features of the concerned modeling for better understanding performance. Thus we propose a Semantics-Aware Inferential Network (SAIN) to meet such a motivation. Taking explicit contextualized semantics as a complementary input, the inferential module of SAIN enables a series of reasoning steps over semantic clues through an attention mechanism. By stringing these steps, the inferential network effectively learns to perform iterative reasoning which incorporates both explicit semantics and contextualized representations. In terms of well pre-trained language models as front-end encoder, our model achieves significant improvement on 11 tasks including machine reading comprehension and natural language inference.
Unsupervised Neural Machine Translation with Indirect Supervision
Apr 07, 2020



Neural machine translation~(NMT) is ineffective for zero-resource languages. Recent works exploring the possibility of unsupervised neural machine translation (UNMT) with only monolingual data can achieve promising results. However, there are still big gaps between UNMT and NMT with parallel supervision. In this work, we introduce a multilingual unsupervised NMT (\method) framework to leverage weakly supervised signals from high-resource language pairs to zero-resource translation directions. More specifically, for unsupervised language pairs \texttt{En-De}, we can make full use of the information from parallel dataset \texttt{En-Fr} to jointly train the unsupervised translation directions all in one model. \method is based on multilingual models which require no changes to the standard unsupervised NMT. Empirical results demonstrate that \method significantly improves the translation quality by more than 3 BLEU score on six benchmark unsupervised translation directions.
Reference Language based Unsupervised Neural Machine Translation
Apr 05, 2020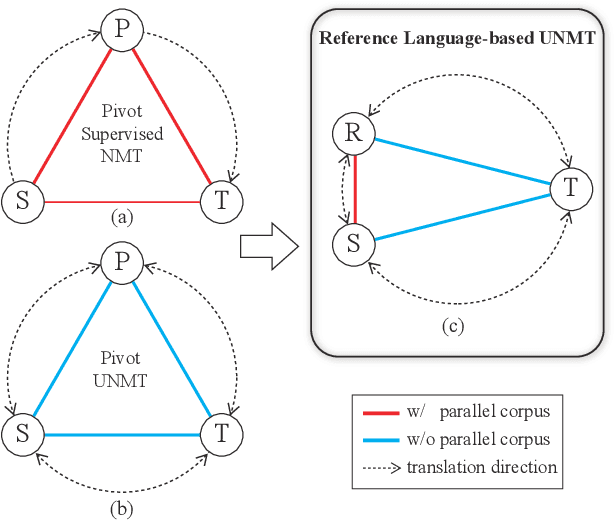
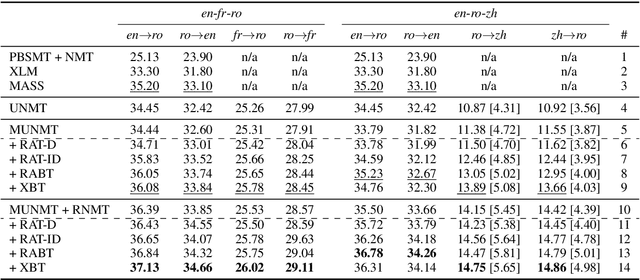
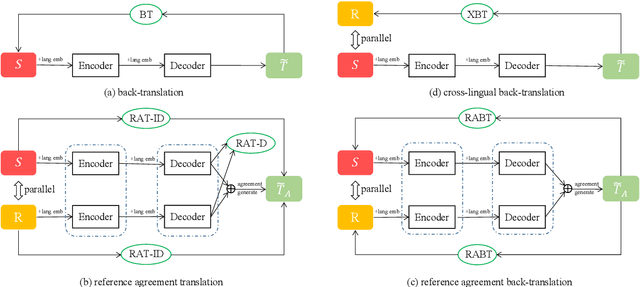
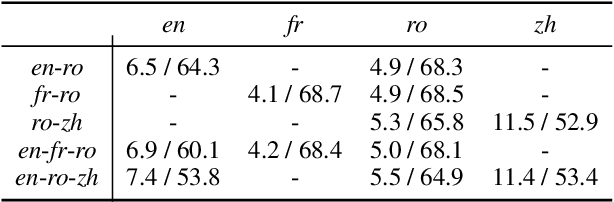
Exploiting common language as an auxiliary for better translation has a long tradition in machine translation, which lets supervised learning based machine translation enjoy the enhancement delivered by the well-used pivot language, in case that the prerequisite of parallel corpus from source language to target language cannot be fully satisfied. The rising of unsupervised neural machine translation (UNMT) seems completely relieving the parallel corpus curse, though still subject to unsatisfactory performance so far due to vague clues available used for its core back-translation training. Further enriching the idea of pivot translation by freeing the use of parallel corpus other than its specified source and target, we propose a new reference language based UNMT framework, in which the reference language only shares parallel corpus with the source, indicating clear enough signal to help the reconstruction training of UNMT through a proposed reference agreement mechanism. Experimental results show that our methods improve the quality of UNMT over that of a strong baseline in terms of only one auxiliary language, demonstrating the usefulness of the proposed reference language based UNMT with a good start.
Dual Multi-head Co-attention for Multi-choice Reading Comprehension
Feb 08, 2020
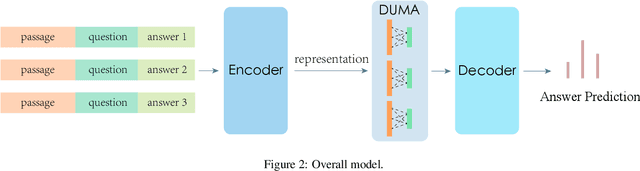

Multi-choice Machine Reading Comprehension (MRC) requires model to decide the correct answer from a set of answer options when given a passage and a question. Thus in addition to a powerful pre-trained Language Model as encoder, multi-choice MRC especially relies on a matching network design which is supposed to effectively capture the relationship among the triplet of passage, question and answers. While the latest pre-trained Language Models have shown powerful enough even without the support from a matching network, and the latest matching network has been complicated enough, we thus propose a novel going-back-to-the-basic solution which straightforwardly models the MRC relationship as attention mechanism inside network. The proposed DUal Multi-head Co-Attention (DUMA) has been shown simple but effective and is capable of generally promoting pre-trained Language Models. Our proposed method is evaluated on two benchmark multi-choice MRC tasks, DREAM and RACE, showing that in terms of strong Language Models, DUMA may still boost the model to reach new state-of-the-art performance.
Retrospective Reader for Machine Reading Comprehension
Jan 27, 2020
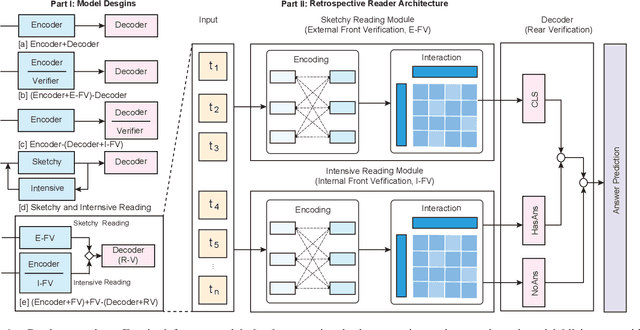
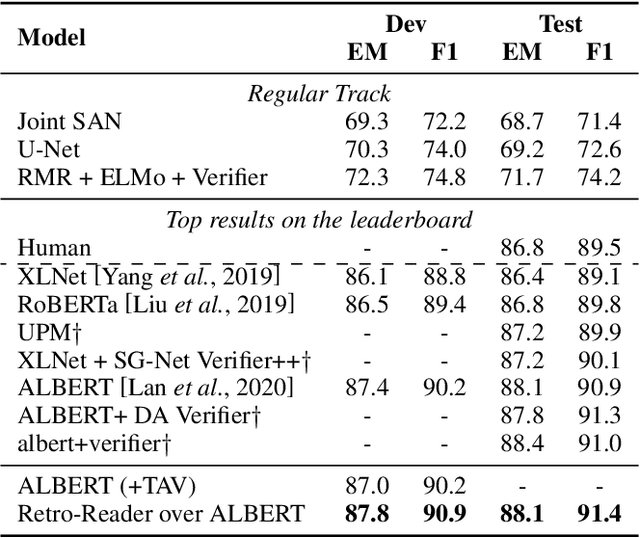
Machine reading comprehension (MRC) is an AI challenge that requires machine to determine the correct answers to questions based on a given passage. MRC systems must not only answer question when necessary but also distinguish when no answer is available according to the given passage and then tactfully abstain from answering. When unanswerable questions are involved in the MRC task, an essential verification module called verifier is especially required in addition to the encoder, though the latest practice on MRC modeling still most benefits from adopting well pre-trained language models as the encoder block by only focusing on the "reading". This paper devotes itself to exploring better verifier design for the MRC task with unanswerable questions. Inspired by how humans solve reading comprehension questions, we proposed a retrospective reader (Retro-Reader) that integrates two stages of reading and verification strategies: 1) sketchy reading that briefly investigates the overall interactions of passage and question, and yield an initial judgment; 2) intensive reading that verifies the answer and gives the final prediction. The proposed reader is evaluated on two benchmark MRC challenge datasets SQuAD2.0 and NewsQA, achieving new state-of-the-art results. Significance tests show that our model is significantly better than the strong ALBERT baseline. A series of analysis is also conducted to interpret the effectiveness of the proposed reader.
Explicit Sentence Compression for Neural Machine Translation
Dec 27, 2019
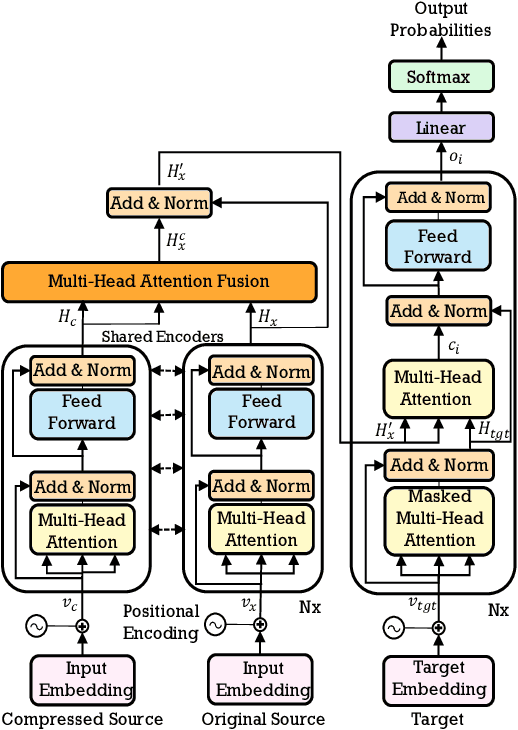
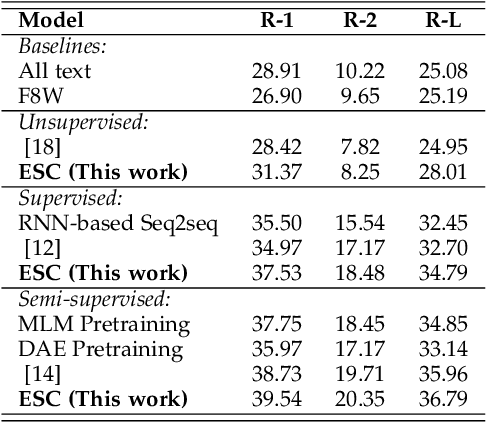
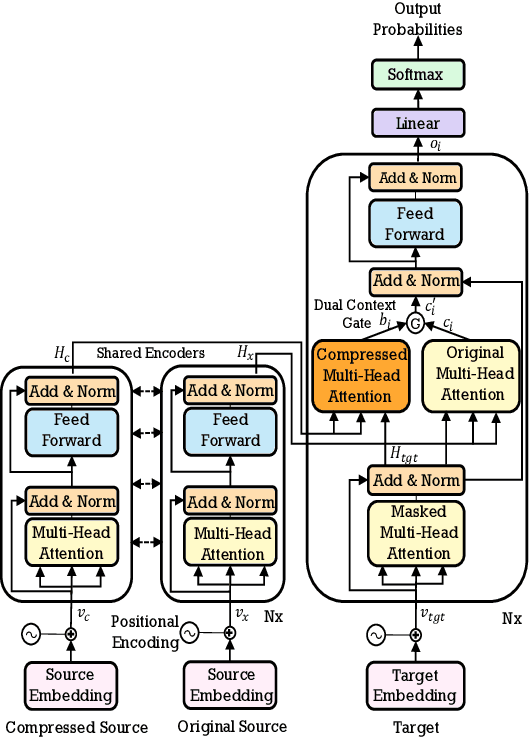
State-of-the-art Transformer-based neural machine translation (NMT) systems still follow a standard encoder-decoder framework, in which source sentence representation can be well done by an encoder with self-attention mechanism. Though Transformer-based encoder may effectively capture general information in its resulting source sentence representation, the backbone information, which stands for the gist of a sentence, is not specifically focused on. In this paper, we propose an explicit sentence compression method to enhance the source sentence representation for NMT. In practice, an explicit sentence compression goal used to learn the backbone information in a sentence. We propose three ways, including backbone source-side fusion, target-side fusion, and both-side fusion, to integrate the compressed sentence into NMT. Our empirical tests on the WMT English-to-French and English-to-German translation tasks show that the proposed sentence compression method significantly improves the translation performances over strong baselines.
Korean-to-Chinese Machine Translation using Chinese Character as Pivot Clue
Nov 25, 2019
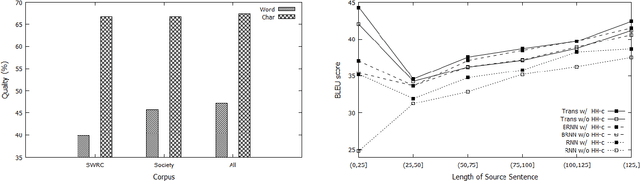

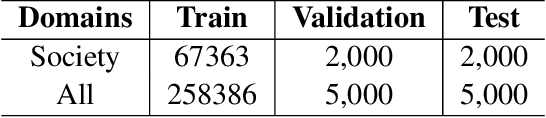
Korean-Chinese is a low resource language pair, but Korean and Chinese have a lot in common in terms of vocabulary. Sino-Korean words, which can be converted into corresponding Chinese characters, account for more than fifty of the entire Korean vocabulary. Motivated by this, we propose a simple linguistically motivated solution to improve the performance of the Korean-to-Chinese neural machine translation model by using their common vocabulary. We adopt Chinese characters as a translation pivot by converting Sino-Korean words in Korean sentences to Chinese characters and then train the machine translation model with the converted Korean sentences as source sentences. The experimental results on Korean-to-Chinese translation demonstrate that the models with the proposed method improve translation quality up to 1.5 BLEU points in comparison to the baseline models.
* 9 pages