 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNexus: Inferring Join Graphs from Metadata Alone via Iterative Low-Rank Matrix Completion
Feb 09, 2026Automatically inferring join relationships is a critical task for effective data discovery, integration, querying and reuse. However, accurately and efficiently identifying these relationships in large and complex schemas can be challenging, especially in enterprise settings where access to data values is constrained. In this paper, we introduce the problem of join graph inference when only metadata is available. We conduct an empirical study on a large number of real-world schemas and observe that join graphs when represented as adjacency matrices exhibit two key properties: high sparsity and low-rank structure. Based on these novel observations, we formulate join graph inference as a low-rank matrix completion problem and propose Nexus, an end-to-end solution using only metadata. To further enhance accuracy, we propose a novel Expectation-Maximization algorithm that alternates between low-rank matrix completion and refining join candidate probabilities by leveraging Large Language Models. Our extensive experiments demonstrate that Nexus outperforms existing methods by a significant margin on four datasets including a real-world production dataset. Additionally, Nexus can operate in a fast mode, providing comparable results with up to 6x speedup, offering a practical and efficient solution for real-world deployments.
MMTU: A Massive Multi-Task Table Understanding and Reasoning Benchmark
Jun 05, 2025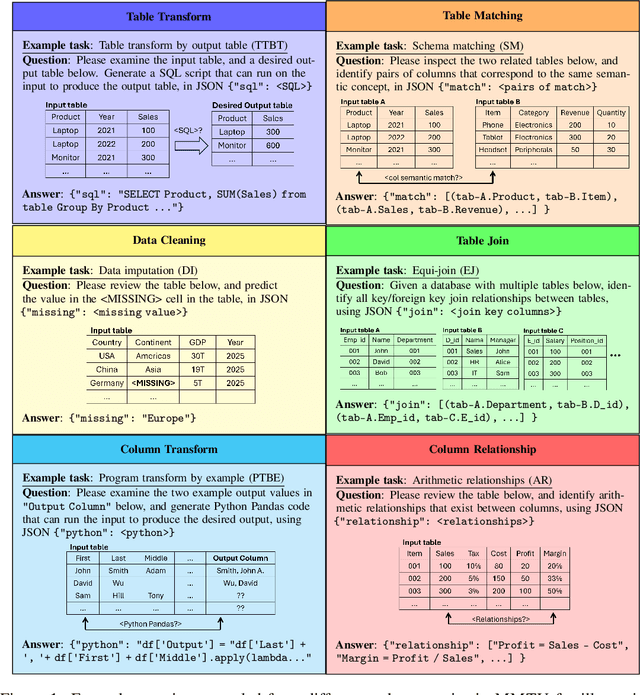


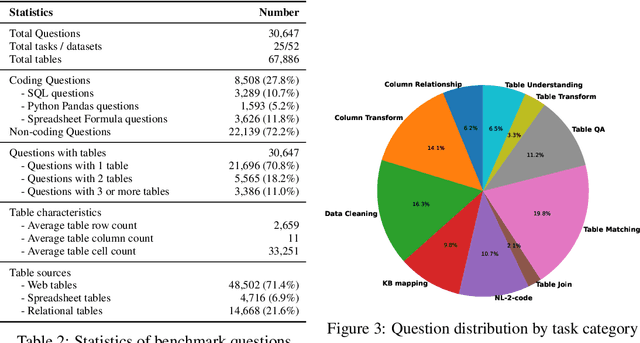
Tables and table-based use cases play a crucial role in many important real-world applications, such as spreadsheets, databases, and computational notebooks, which traditionally require expert-level users like data engineers, data analysts, and database administrators to operate. Although LLMs have shown remarkable progress in working with tables (e.g., in spreadsheet and database copilot scenarios), comprehensive benchmarking of such capabilities remains limited. In contrast to an extensive and growing list of NLP benchmarks, evaluations of table-related tasks are scarce, and narrowly focus on tasks like NL-to-SQL and Table-QA, overlooking the broader spectrum of real-world tasks that professional users face. This gap limits our understanding and model progress in this important area. In this work, we introduce MMTU, a large-scale benchmark with over 30K questions across 25 real-world table tasks, designed to comprehensively evaluate models ability to understand, reason, and manipulate real tables at the expert-level. These tasks are drawn from decades' worth of computer science research on tabular data, with a focus on complex table tasks faced by professional users. We show that MMTU require a combination of skills -- including table understanding, reasoning, and coding -- that remain challenging for today's frontier models, where even frontier reasoning models like OpenAI o4-mini and DeepSeek R1 score only around 60%, suggesting significant room for improvement. We highlight key findings in our evaluation using MMTU and hope that this benchmark drives further advances in understanding and developing foundation models for structured data processing and analysis. Our code and data are available at https://github.com/MMTU-Benchmark/MMTU and https://huggingface.co/datasets/MMTU-benchmark/MMTU.
VecAug: Unveiling Camouflaged Frauds with Cohort Augmentation for Enhanced Detection
Aug 01, 2024



Fraud detection presents a challenging task characterized by ever-evolving fraud patterns and scarce labeled data. Existing methods predominantly rely on graph-based or sequence-based approaches. While graph-based approaches connect users through shared entities to capture structural information, they remain vulnerable to fraudsters who can disrupt or manipulate these connections. In contrast, sequence-based approaches analyze users' behavioral patterns, offering robustness against tampering but overlooking the interactions between similar users. Inspired by cohort analysis in retention and healthcare, this paper introduces VecAug, a novel cohort-augmented learning framework that addresses these challenges by enhancing the representation learning of target users with personalized cohort information. To this end, we first propose a vector burn-in technique for automatic cohort identification, which retrieves a task-specific cohort for each target user. Then, to fully exploit the cohort information, we introduce an attentive cohort aggregation technique for augmenting target user representations. To improve the robustness of such cohort augmentation, we also propose a novel label-aware cohort neighbor separation mechanism to distance negative cohort neighbors and calibrate the aggregated cohort information. By integrating this cohort information with target user representations, VecAug enhances the modeling capacity and generalization capabilities of the model to be augmented. Our framework is flexible and can be seamlessly integrated with existing fraud detection models. We deploy our framework on e-commerce platforms and evaluate it on three fraud detection datasets, and results show that VecAug improves the detection performance of base models by up to 2.48\% in AUC and 22.5\% in R@P$_{0.9}$, outperforming state-of-the-art methods significantly.
CohortNet: Empowering Cohort Discovery for Interpretable Healthcare Analytics
Jun 20, 2024Cohort studies are of significant importance in the field of healthcare analysis. However, existing methods typically involve manual, labor-intensive, and expert-driven pattern definitions or rely on simplistic clustering techniques that lack medical relevance. Automating cohort studies with interpretable patterns has great potential to facilitate healthcare analysis but remains an unmet need in prior research efforts. In this paper, we propose a cohort auto-discovery model, CohortNet, for interpretable healthcare analysis, focusing on the effective identification, representation, and exploitation of cohorts characterized by medically meaningful patterns. CohortNet initially learns fine-grained patient representations by separately processing each feature, considering both individual feature trends and feature interactions at each time step. Subsequently, it classifies each feature into distinct states and employs a heuristic cohort exploration strategy to effectively discover substantial cohorts with concrete patterns. For each identified cohort, it learns comprehensive cohort representations with credible evidence through associated patient retrieval. Ultimately, given a new patient, CohortNet can leverage relevant cohorts with distinguished importance, which can provide a more holistic understanding of the patient's conditions. Extensive experiments on three real-world datasets demonstrate that it consistently outperforms state-of-the-art approaches and offers interpretable insights from diverse perspectives in a top-down fashion.
LITO: Learnable Intervention for Truthfulness Optimization
May 01, 2024



Large language models (LLMs) can generate long-form and coherent text, but they still frequently hallucinate facts, thus limiting their reliability. To address this issue, inference-time methods that elicit truthful responses have been proposed by shifting LLM representations towards learned "truthful directions". However, applying the truthful directions with the same intensity fails to generalize across different question contexts. We propose LITO, a Learnable Intervention method for Truthfulness Optimization that automatically identifies the optimal intervention intensity tailored to a specific context. LITO explores a sequence of model generations based on increasing levels of intervention intensities. It selects the most accurate response or refuses to answer when the predictions are highly uncertain. Experiments on multiple LLMs and question-answering datasets demonstrate that LITO improves truthfulness while preserving task accuracy. The adaptive nature of LITO counters issues with one-size-fits-all intervention-based solutions, maximizing model truthfulness by reflecting internal knowledge only when the model is confident.
Chameleon: Foundation Models for Fairness-aware Multi-modal Data Augmentation to Enhance Coverage of Minorities
Feb 02, 2024



The potential harms of the under-representation of minorities in training data, particularly in multi-modal settings, is a well-recognized concern. While there has been extensive effort in detecting such under-representation, resolution has remained a challenge. With recent advancements in generative AI, large language models and foundation models have emerged as versatile tools across various domains. In this paper, we propose Chameleon, a system that efficiently utilizes these tools to augment a data set with a minimal addition of synthetically generated tuples, in order to enhance the coverage of the under-represented groups. Our system follows a rejection sampling approach to ensure the generated tuples have a high quality and follow the underlying distribution. In order to minimize the rejection chance of the generated tuples, we propose multiple strategies for providing a guide for the foundation model. Our experiment results, in addition to confirming the efficiency of our proposed algorithms, illustrate the effectiveness of our approach, as the unfairness of the model in a downstream task significantly dropped after data repair using Chameleon.
Observatory: Characterizing Embeddings of Relational Tables
Oct 05, 2023



Language models and specialized table embedding models have recently demonstrated strong performance on many tasks over tabular data. Researchers and practitioners are keen to leverage these models in many new application contexts; but limited understanding of the strengths and weaknesses of these models, and the table representations they generate, makes the process of finding a suitable model for a given task reliant on trial and error. There is an urgent need to gain a comprehensive understanding of these models to minimize inefficiency and failures in downstream usage. To address this need, we propose Observatory, a formal framework to systematically analyze embedding representations of relational tables. Motivated both by invariants of the relational data model and by statistical considerations regarding data distributions, we define eight primitive properties, and corresponding measures to quantitatively characterize table embeddings for these properties. Based on these properties, we define an extensible framework to evaluate language and table embedding models. We collect and synthesize a suite of datasets and use Observatory to analyze seven such models. Our analysis provides insights into the strengths and weaknesses of learned representations over tables. We find, for example, that some models are sensitive to table structure such as column order, that functional dependencies are rarely reflected in embeddings, and that specialized table embedding models have relatively lower sample fidelity. Such insights help researchers and practitioners better anticipate model behaviors and select appropriate models for their downstream tasks, while guiding researchers in the development of new models.
Pylon: Semantic Table Union Search in Data Lakes
Jan 13, 2023The large size and fast growth of data repositories, such as data lakes, has spurred the need for data discovery to help analysts find related data. The problem has become challenging as (i) a user typically does not know what datasets exist in an enormous data repository; and (ii) there is usually a lack of a unified data model to capture the interrelationships between heterogeneous datasets from disparate sources. In this work, we address one important class of discovery needs: finding union-able tables. The task is to find tables in a data lake that can be unioned with a given query table. The challenge is to recognize union-able columns even if they are represented differently. In this paper, we propose a data-driven learning approach: specifically, an unsupervised representation learning and embedding retrieval task. Our key idea is to exploit self-supervised contrastive learning to learn an embedding model that takes into account the indexing/search data structure and produces embeddings close by for columns with semantically similar values while pushing apart columns with semantically dissimilar values. We then find union-able tables based on similarities between their constituent columns in embedding space. On a real-world data lake, we demonstrate that our best-performing model achieves significant improvements in precision ($16\% \uparrow$), recall ($17\% \uparrow $), and query response time (7x faster) compared to the state-of-the-art.
Detection of Groups with Biased Representation in Ranking
Dec 30, 2022



Real-life tools for decision-making in many critical domains are based on ranking results. With the increasing awareness of algorithmic fairness, recent works have presented measures for fairness in ranking. Many of those definitions consider the representation of different ``protected groups'', in the top-$k$ ranked items, for any reasonable $k$. Given the protected groups, confirming algorithmic fairness is a simple task. However, the groups' definitions may be unknown in advance. In this paper, we study the problem of detecting groups with biased representation in the top-$k$ ranked items, eliminating the need to pre-define protected groups. The number of such groups possible can be exponential, making the problem hard. We propose efficient search algorithms for two different fairness measures: global representation bounds, and proportional representation. Then we propose a method to explain the bias in the representations of groups utilizing the notion of Shapley values. We conclude with an experimental study, showing the scalability of our approach and demonstrating the usefulness of the proposed algorithms.
Reinforcement Learning Enhanced Weighted Sampling for Accurate Subgraph Counting on Fully Dynamic Graph Streams
Nov 13, 2022



As the popularity of graph data increases, there is a growing need to count the occurrences of subgraph patterns of interest, for a variety of applications. Many graphs are massive in scale and also fully dynamic (with insertions and deletions of edges), rendering exact computation of these counts to be infeasible. Common practice is, instead, to use a small set of edges as a sample to estimate the counts. Existing sampling algorithms for fully dynamic graphs sample the edges with uniform probability. In this paper, we show that we can do much better if we sample edges based on their individual properties. Specifically, we propose a weighted sampling algorithm called WSD for estimating the subgraph count in a fully dynamic graph stream, which samples the edges based on their weights that indicate their importance and reflect their properties. We determine the weights of edges in a data-driven fashion, using a novel method based on reinforcement learning. We conduct extensive experiments to verify that our technique can produce estimates with smaller errors while often running faster compared with existing algorithms.