 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemiNLL: A Framework of Noisy-Label Learning by Semi-Supervised Learning
Dec 02, 2020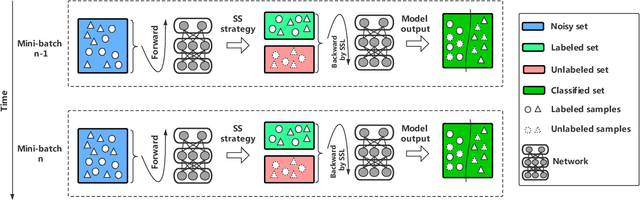
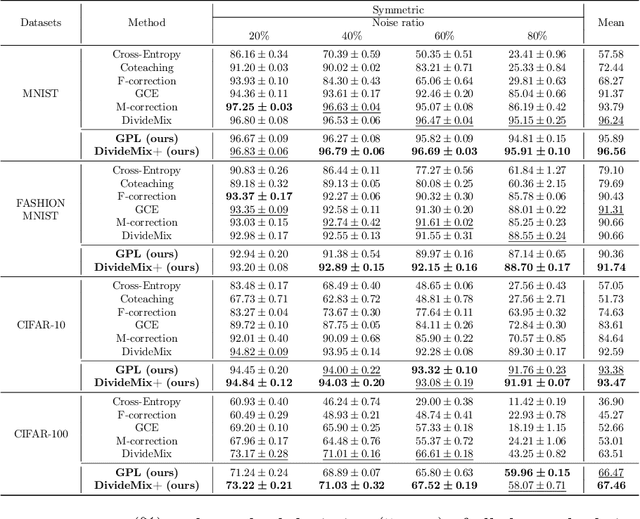
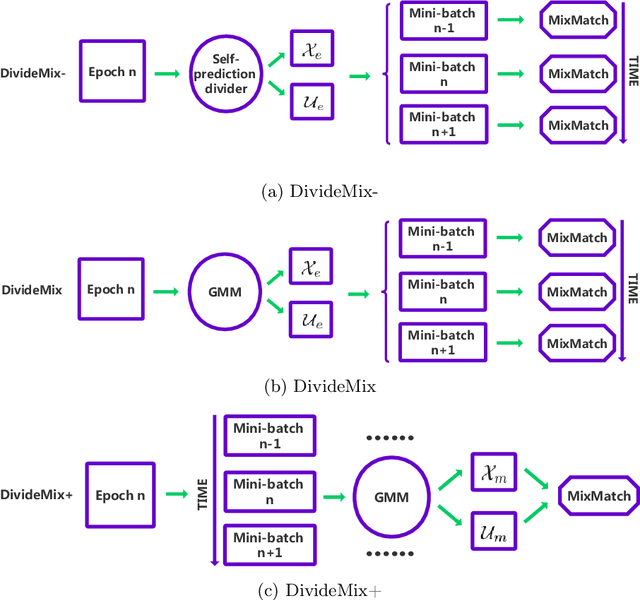
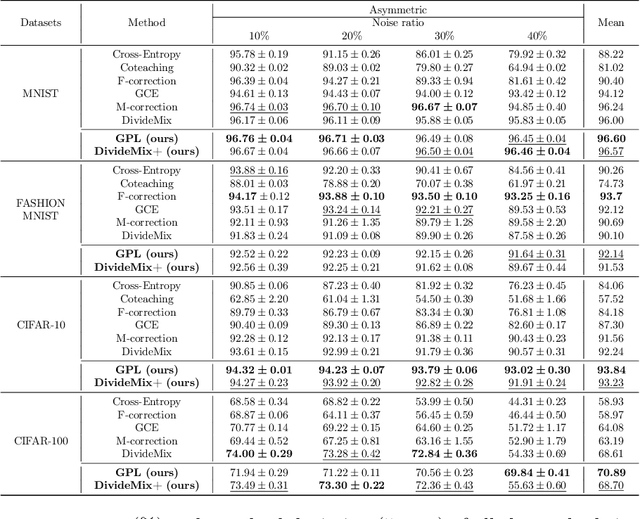
Deep learning with noisy labels is a challenging task. Recent prominent methods that build on a specific sample selection (SS) strategy and a specific semi-supervised learning (SSL) model achieved state-of-the-art performance. Intuitively, better performance could be achieved if stronger SS strategies and SSL models are employed. Following this intuition, one might easily derive various effective noisy-label learning methods using different combinations of SS strategies and SSL models, which is, however, reinventing the wheel in essence. To prevent this problem, we propose SemiNLL, a versatile framework that combines SS strategies and SSL models in an end-to-end manner. Our framework can absorb various SS strategies and SSL backbones, utilizing their power to achieve promising performance. We also instantiate our framework with different combinations, which set the new state of the art on benchmark-simulated and real-world datasets with noisy labels.
Confusable Learning for Large-class Few-Shot Classification
Nov 06, 2020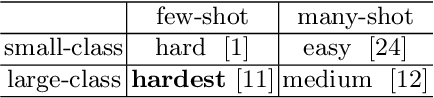
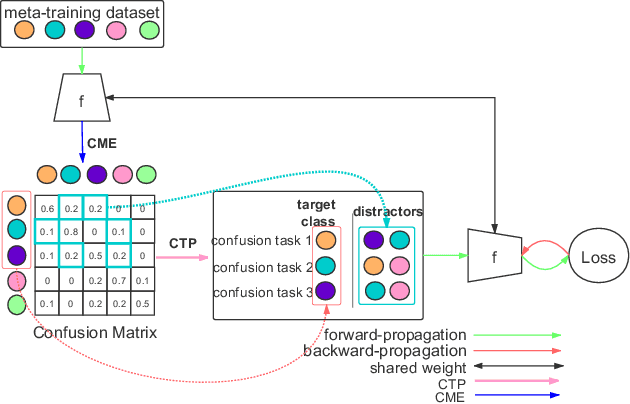
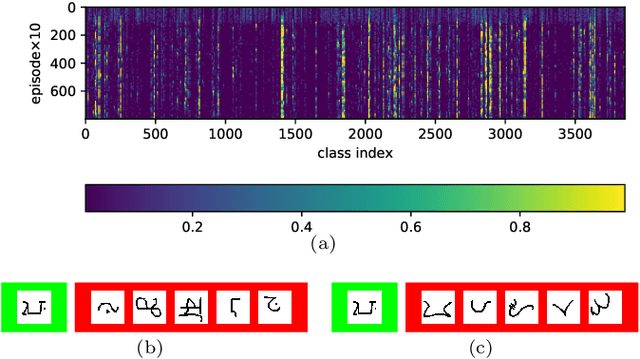
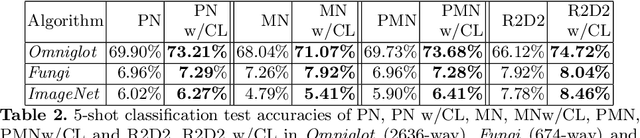
Few-shot image classification is challenging due to the lack of ample samples in each class. Such a challenge becomes even tougher when the number of classes is very large, i.e., the large-class few-shot scenario. In this novel scenario, existing approaches do not perform well because they ignore confusable classes, namely similar classes that are difficult to distinguish from each other. These classes carry more information. In this paper, we propose a biased learning paradigm called Confusable Learning, which focuses more on confusable classes. Our method can be applied to mainstream meta-learning algorithms. Specifically, our method maintains a dynamically updating confusion matrix, which analyzes confusable classes in the dataset. Such a confusion matrix helps meta learners to emphasize on confusable classes. Comprehensive experiments on Omniglot, Fungi, and ImageNet demonstrate the efficacy of our method over state-of-the-art baselines.
Cooperative Heterogeneous Deep Reinforcement Learning
Nov 02, 2020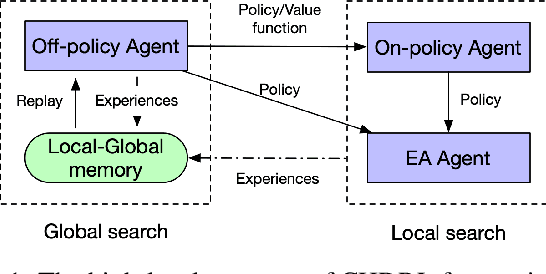
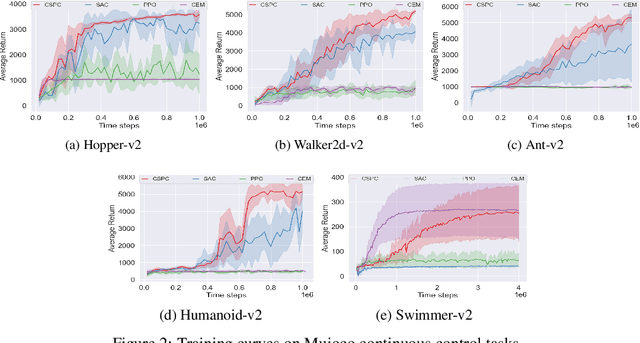

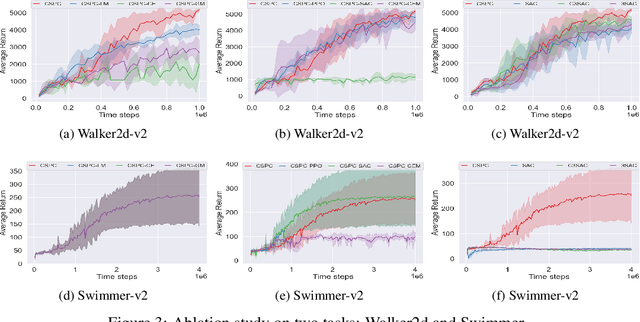
Numerous deep reinforcement learning agents have been proposed, and each of them has its strengths and flaws. In this work, we present a Cooperative Heterogeneous Deep Reinforcement Learning (CHDRL) framework that can learn a policy by integrating the advantages of heterogeneous agents. Specifically, we propose a cooperative learning framework that classifies heterogeneous agents into two classes: global agents and local agents. Global agents are off-policy agents that can utilize experiences from the other agents. Local agents are either on-policy agents or population-based evolutionary algorithms (EAs) agents that can explore the local area effectively. We employ global agents, which are sample-efficient, to guide the learning of local agents so that local agents can benefit from sample-efficient agents and simultaneously maintain their advantages, e.g., stability. Global agents also benefit from effective local searches. Experimental studies on a range of continuous control tasks from the Mujoco benchmark show that CHDRL achieves better performance compared with state-of-the-art baselines.
RatE: Relation-Adaptive Translating Embedding for Knowledge Graph Completion
Oct 10, 2020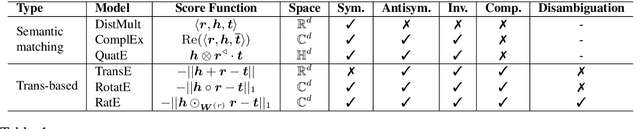
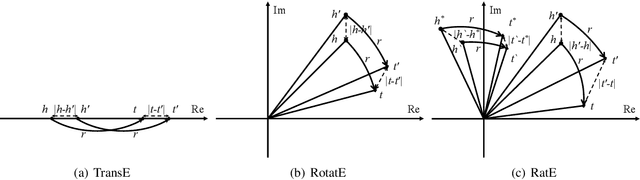
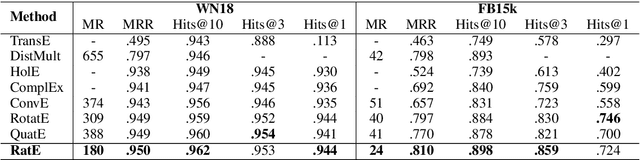
Many graph embedding approaches have been proposed for knowledge graph completion via link prediction. Among those, translating embedding approaches enjoy the advantages of light-weight structure, high efficiency and great interpretability. Especially when extended to complex vector space, they show the capability in handling various relation patterns including symmetry, antisymmetry, inversion and composition. However, previous translating embedding approaches defined in complex vector space suffer from two main issues: 1) representing and modeling capacities of the model are limited by the translation function with rigorous multiplication of two complex numbers; and 2) embedding ambiguity caused by one-to-many relations is not explicitly alleviated. In this paper, we propose a relation-adaptive translation function built upon a novel weighted product in complex space, where the weights are learnable, relation-specific and independent to embedding size. The translation function only requires eight more scalar parameters each relation, but improves expressive power and alleviates embedding ambiguity problem. Based on the function, we then present our Relation-adaptive translating Embedding (RatE) approach to score each graph triple. Moreover, a novel negative sampling method is proposed to utilize both prior knowledge and self-adversarial learning for effective optimization. Experiments verify RatE achieves state-of-the-art performance on four link prediction benchmarks.
Improving Long-Tail Relation Extraction with Collaborating Relation-Augmented Attention
Oct 08, 2020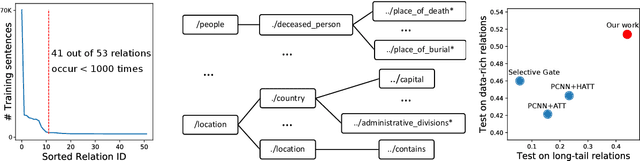
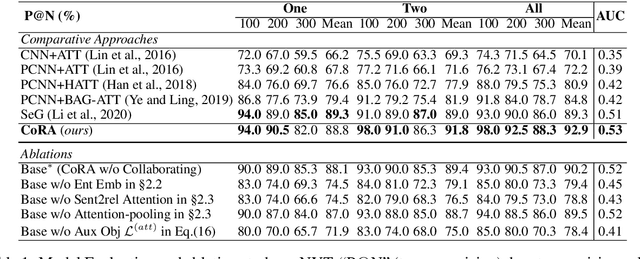
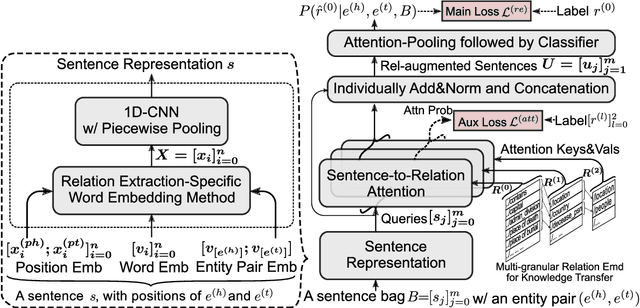
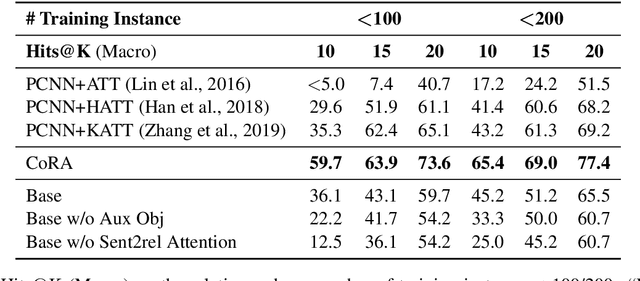
Wrong labeling problem and long-tail relations are two main challenges caused by distant supervision in relation extraction. Recent works alleviate the wrong labeling by selective attention via multi-instance learning, but cannot well handle long-tail relations even if hierarchies of the relations are introduced to share knowledge. In this work, we propose a novel neural network, Collaborating Relation-augmented Attention (CoRA), to handle both the wrong labeling and long-tail relations. Particularly, we first propose relation-augmented attention network as base model. It operates on sentence bag with a sentence-to-relation attention to minimize the effect of wrong labeling. Then, facilitated by the proposed base model, we introduce collaborating relation features shared among relations in the hierarchies to promote the relation-augmenting process and balance the training data for long-tail relations. Besides the main training objective to predict the relation of a sentence bag, an auxiliary objective is utilized to guide the relation-augmenting process for a more accurate bag-level representation. In the experiments on the popular benchmark dataset NYT, the proposed CoRA improves the prior state-of-the-art performance by a large margin in terms of Precision@N, AUC and Hits@K. Further analyses verify its superior capability in handling long-tail relations in contrast to the competitors.
Attribute Propagation Network for Graph Zero-shot Learning
Sep 24, 2020

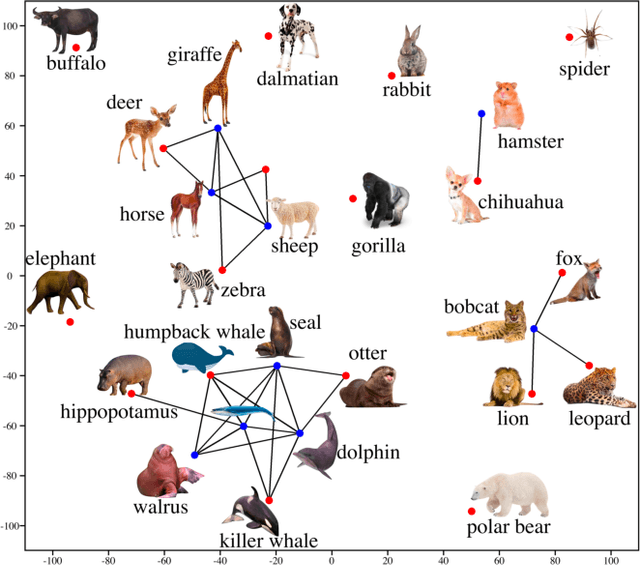
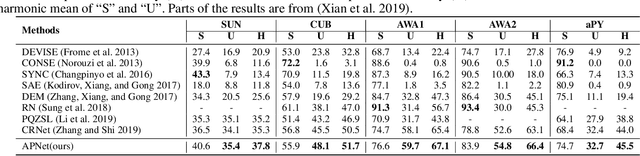
The goal of zero-shot learning (ZSL) is to train a model to classify samples of classes that were not seen during training. To address this challenging task, most ZSL methods relate unseen test classes to seen(training) classes via a pre-defined set of attributes that can describe all classes in the same semantic space, so the knowledge learned on the training classes can be adapted to unseen classes. In this paper, we aim to optimize the attribute space for ZSL by training a propagation mechanism to refine the semantic attributes of each class based on its neighbors and related classes on a graph of classes. We show that the propagated attributes can produce classifiers for zero-shot classes with significantly improved performance in different ZSL settings. The graph of classes is usually free or very cheap to acquire such as WordNet or ImageNet classes. When the graph is not provided, given pre-defined semantic embeddings of the classes, we can learn a mechanism to generate the graph in an end-to-end manner along with the propagation mechanism. However, this graph-aided technique has not been well-explored in the literature. In this paper, we introduce the attribute propagation network (APNet), which is composed of 1) a graph propagation model generating attribute vector for each class and 2) a parameterized nearest neighbor (NN) classifier categorizing an image to the class with the nearest attribute vector to the image's embedding. For better generalization over unseen classes, different from previous methods, we adopt a meta-learning strategy to train the propagation mechanism and the similarity metric for the NN classifier on multiple sub-graphs, each associated with a classification task over a subset of training classes. In experiments with two zero-shot learning settings and five benchmark datasets, APNet achieves either compelling performance or new state-of-the-art results.
BiteNet: Bidirectional Temporal Encoder Network to Predict Medical Outcomes
Sep 24, 2020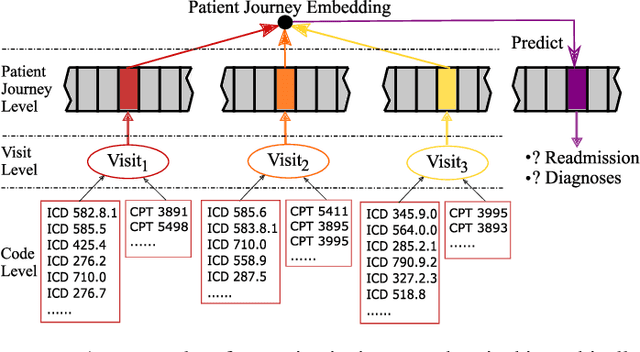
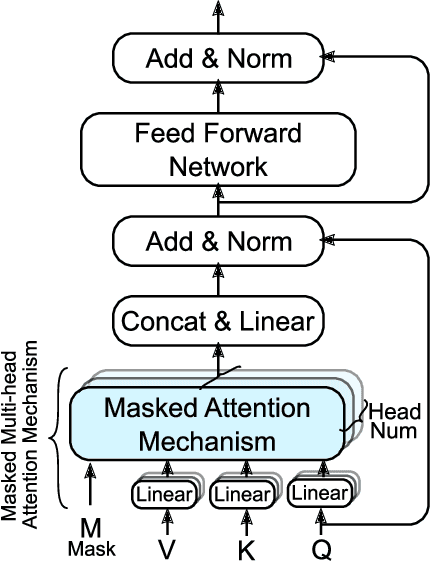
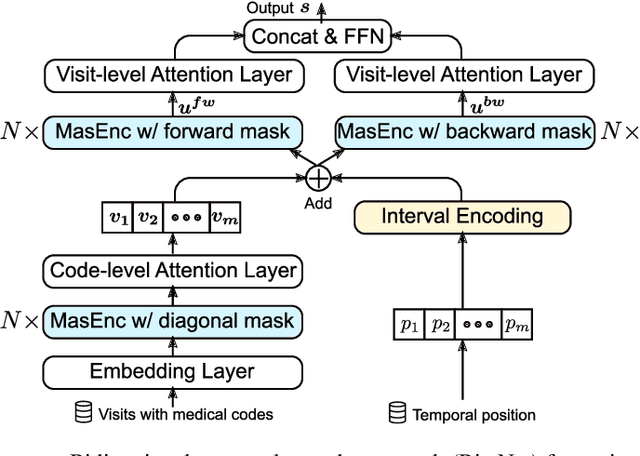
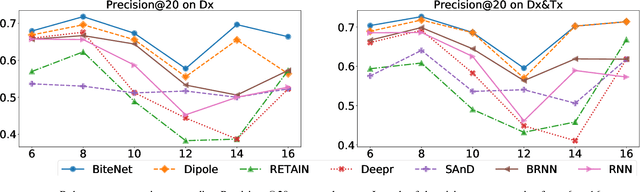
Electronic health records (EHRs) are longitudinal records of a patient's interactions with healthcare systems. A patient's EHR data is organized as a three-level hierarchy from top to bottom: patient journey - all the experiences of diagnoses and treatments over a period of time; individual visit - a set of medical codes in a particular visit; and medical code - a specific record in the form of medical codes. As EHRs begin to amass in millions, the potential benefits, which these data might hold for medical research and medical outcome prediction, are staggering - including, for example, predicting future admissions to hospitals, diagnosing illnesses or determining the efficacy of medical treatments. Each of these analytics tasks requires a domain knowledge extraction method to transform the hierarchical patient journey into a vector representation for further prediction procedure. The representations should embed a sequence of visits and a set of medical codes with a specific timestamp, which are crucial to any downstream prediction tasks. Hence, expressively powerful representations are appealing to boost learning performance. To this end, we propose a novel self-attention mechanism that captures the contextual dependency and temporal relationships within a patient's healthcare journey. An end-to-end bidirectional temporal encoder network (BiteNet) then learns representations of the patient's journeys, based solely on the proposed attention mechanism. We have evaluated the effectiveness of our methods on two supervised prediction and two unsupervised clustering tasks with a real-world EHR dataset. The empirical results demonstrate the proposed BiteNet model produces higher-quality representations than state-of-the-art baseline methods.
Many-Class Few-Shot Learning on Multi-Granularity Class Hierarchy
Jun 28, 2020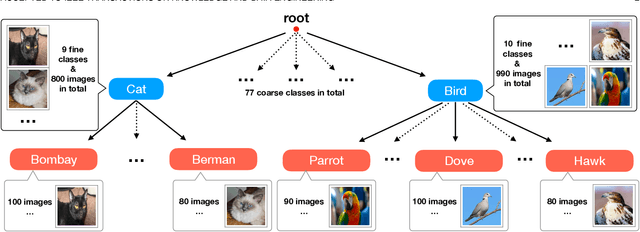
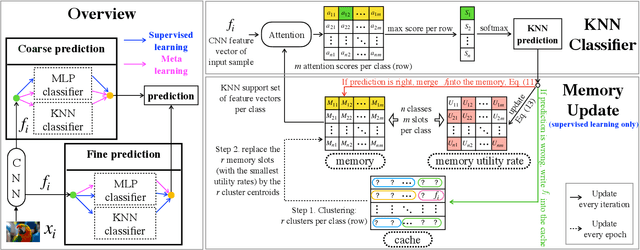

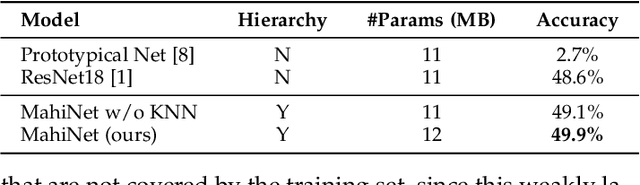
We study many-class few-shot (MCFS) problem in both supervised learning and meta-learning settings. Compared to the well-studied many-class many-shot and few-class few-shot problems, the MCFS problem commonly occurs in practical applications but has been rarely studied in previous literature. It brings new challenges of distinguishing between many classes given only a few training samples per class. In this paper, we leverage the class hierarchy as a prior knowledge to train a coarse-to-fine classifier that can produce accurate predictions for MCFS problem in both settings. The propose model, "memory-augmented hierarchical-classification network (MahiNet)", performs coarse-to-fine classification where each coarse class can cover multiple fine classes. Since it is challenging to directly distinguish a variety of fine classes given few-shot data per class, MahiNet starts from learning a classifier over coarse-classes with more training data whose labels are much cheaper to obtain. The coarse classifier reduces the searching range over the fine classes and thus alleviates the challenges from "many classes". On architecture, MahiNet firstly deploys a convolutional neural network (CNN) to extract features. It then integrates a memory-augmented attention module and a multi-layer perceptron (MLP) together to produce the probabilities over coarse and fine classes. While the MLP extends the linear classifier, the attention module extends the KNN classifier, both together targeting the "few-shot" problem. We design several training strategies of MahiNet for supervised learning and meta-learning. In addition, we propose two novel benchmark datasets "mcfsImageNet" and "mcfsOmniglot" specially designed for MCFS problem. In experiments, we show that MahiNet outperforms several state-of-the-art models on MCFS problems in both supervised learning and meta-learning.
A Universal Representation Transformer Layer for Few-Shot Image Classification
Jun 25, 2020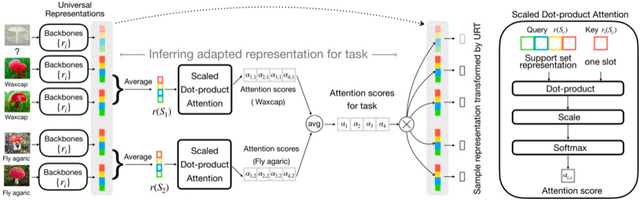
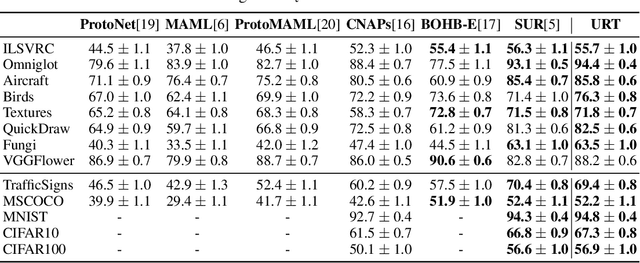
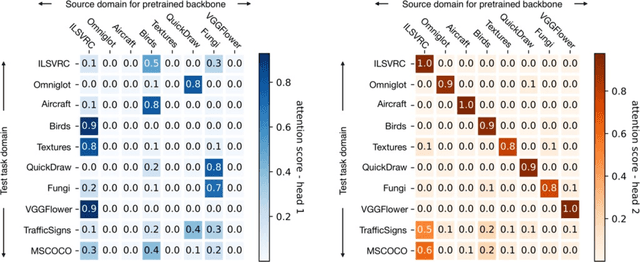
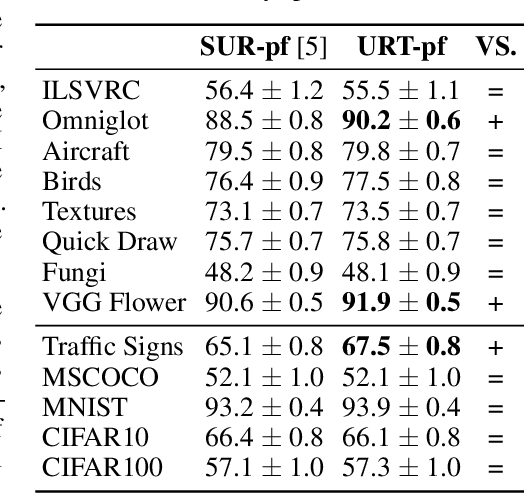
Few-shot classification aims to recognize unseen classes when presented with only a small number of samples. We consider the problem of multi-domain few-shot image classification, where unseen classes and examples come from diverse data sources. This problem has seen growing interest and has inspired the development of benchmarks such as Meta-Dataset. A key challenge in this multi-domain setting is to effectively integrate the feature representations from the diverse set of training domains. Here, we propose a Universal Representation Transformer (URT) layer, that meta-learns to leverage universal features for few-shot classification by dynamically re-weighting and composing the most appropriate domain-specific representations. In experiments, we show that URT sets a new state-of-the-art result on Meta-Dataset. Specifically, it outperforms the best previous model on three data sources or performs the same in others. We analyze variants of URT and present a visualization of the attention score heatmaps that sheds light on how the model performs cross-domain generalization. Our code is available at https://github.com/liulu112601/URT.
Self-Attention Enhanced Patient Journey Understanding in Healthcare System
Jun 19, 2020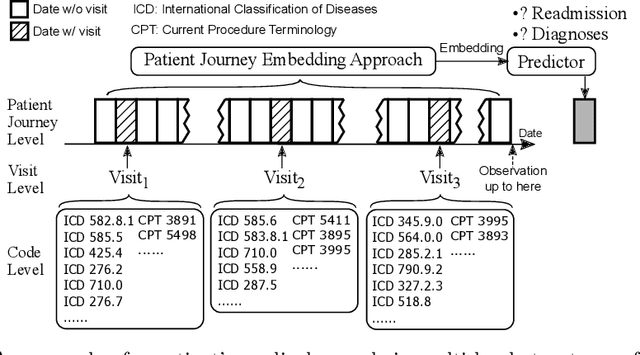

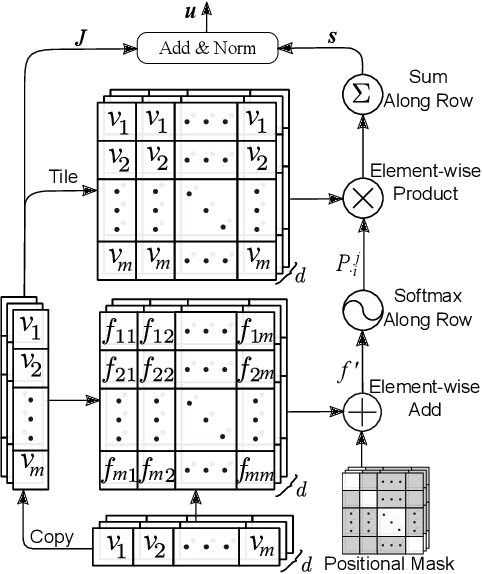
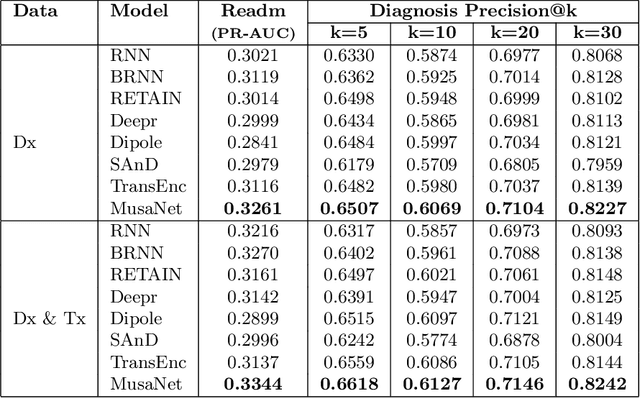
Understanding patients' journeys in healthcare system is a fundamental prepositive task for a broad range of AI-based healthcare applications. This task aims to learn an informative representation that can comprehensively encode hidden dependencies among medical events and its inner entities, and then the use of encoding outputs can greatly benefit the downstream application-driven tasks. A patient journey is a sequence of electronic health records (EHRs) over time that is organized at multiple levels: patient, visits and medical codes. The key challenge of patient journey understanding is to design an effective encoding mechanism which can properly tackle the aforementioned multi-level structured patient journey data with temporal sequential visits and a set of medical codes. This paper proposes a novel self-attention mechanism that can simultaneously capture the contextual and temporal relationships hidden in patient journeys. A multi-level self-attention network (MusaNet) is specifically designed to learn the representations of patient journeys that is used to be a long sequence of activities. The MusaNet is trained in end-to-end manner using the training data derived from EHRs. We evaluated the efficacy of our method on two medical application tasks with real-world benchmark datasets. The results have demonstrated the proposed MusaNet produces higher-quality representations than state-of-the-art baseline methods. The source code is available in https://github.com/xueping/MusaNet.