 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMECPformer: Multi-estimations Complementary Patch with CNN-Transformers for Weakly Supervised Semantic Segmentation
Mar 19, 2023The initial seed based on the convolutional neural network (CNN) for weakly supervised semantic segmentation always highlights the most discriminative regions but fails to identify the global target information. Methods based on transformers have been proposed successively benefiting from the advantage of capturing long-range feature representations. However, we observe a flaw regardless of the gifts based on the transformer. Given a class, the initial seeds generated based on the transformer may invade regions belonging to other classes. Inspired by the mentioned issues, we devise a simple yet effective method with Multi-estimations Complementary Patch (MECP) strategy and Adaptive Conflict Module (ACM), dubbed MECPformer. Given an image, we manipulate it with the MECP strategy at different epochs, and the network mines and deeply fuses the semantic information at different levels. In addition, ACM adaptively removes conflicting pixels and exploits the network self-training capability to mine potential target information. Without bells and whistles, our MECPformer has reached new state-of-the-art 72.0% mIoU on the PASCAL VOC 2012 and 42.4% on MS COCO 2014 dataset. The code is available at https://github.com/ChunmengLiu1/MECPformer.
Heterogeneous Federated Knowledge Graph Embedding Learning and Unlearning
Feb 26, 2023



Federated Learning (FL) recently emerges as a paradigm to train a global machine learning model across distributed clients without sharing raw data. Knowledge Graph (KG) embedding represents KGs in a continuous vector space, serving as the backbone of many knowledge-driven applications. As a promising combination, federated KG embedding can fully take advantage of knowledge learned from different clients while preserving the privacy of local data. However, realistic problems such as data heterogeneity and knowledge forgetting still remain to be concerned. In this paper, we propose FedLU, a novel FL framework for heterogeneous KG embedding learning and unlearning. To cope with the drift between local optimization and global convergence caused by data heterogeneity, we propose mutual knowledge distillation to transfer local knowledge to global, and absorb global knowledge back. Moreover, we present an unlearning method based on cognitive neuroscience, which combines retroactive interference and passive decay to erase specific knowledge from local clients and propagate to the global model by reusing knowledge distillation. We construct new datasets for assessing realistic performance of the state-of-the-arts. Extensive experiments show that FedLU achieves superior results in both link prediction and knowledge forgetting.
EventEA: Benchmarking Entity Alignment for Event-centric Knowledge Graphs
Nov 05, 2022



Entity alignment is to find identical entities in different knowledge graphs (KGs) that refer to the same real-world object. Embedding-based entity alignment techniques have been drawing a lot of attention recently because they can help solve the issue of symbolic heterogeneity in different KGs. However, in this paper, we show that the progress made in the past was due to biased and unchallenging evaluation. We highlight two major flaws in existing datasets that favor embedding-based entity alignment techniques, i.e., the isomorphic graph structures in relation triples and the weak heterogeneity in attribute triples. Towards a critical evaluation of embedding-based entity alignment methods, we construct a new dataset with heterogeneous relations and attributes based on event-centric KGs. We conduct extensive experiments to evaluate existing popular methods, and find that they fail to achieve promising performance. As a new approach to this difficult problem, we propose a time-aware literal encoder for entity alignment. The dataset and source code are publicly available to foster future research. Our work calls for more effective and practical embedding-based solutions to entity alignment.
I Know What You Do Not Know: Knowledge Graph Embedding via Co-distillation Learning
Aug 28, 2022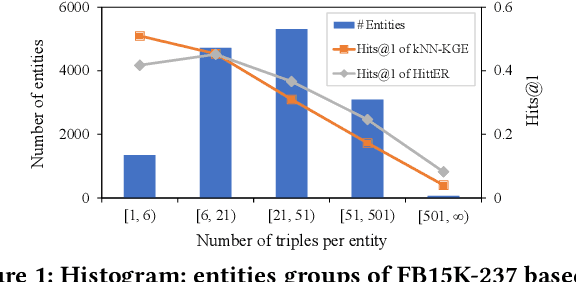

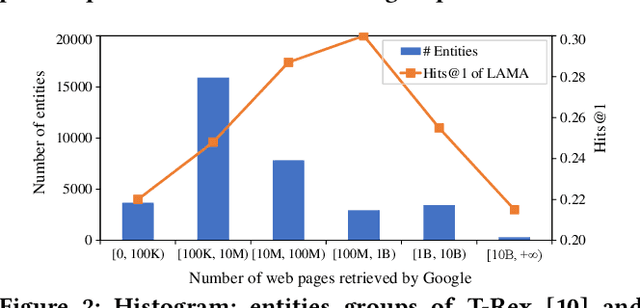

Knowledge graph (KG) embedding seeks to learn vector representations for entities and relations. Conventional models reason over graph structures, but they suffer from the issues of graph incompleteness and long-tail entities. Recent studies have used pre-trained language models to learn embeddings based on the textual information of entities and relations, but they cannot take advantage of graph structures. In the paper, we show empirically that these two kinds of features are complementary for KG embedding. To this end, we propose CoLE, a Co-distillation Learning method for KG Embedding that exploits the complementarity of graph structures and text information. Its graph embedding model employs Transformer to reconstruct the representation of an entity from its neighborhood subgraph. Its text embedding model uses a pre-trained language model to generate entity representations from the soft prompts of their names, descriptions, and relational neighbors. To let the two model promote each other, we propose co-distillation learning that allows them to distill selective knowledge from each other's prediction logits. In our co-distillation learning, each model serves as both a teacher and a student. Experiments on benchmark datasets demonstrate that the two models outperform their related baselines, and the ensemble method CoLE with co-distillation learning advances the state-of-the-art of KG embedding.
Learning to Answer Questions in Dynamic Audio-Visual Scenarios
Apr 05, 2022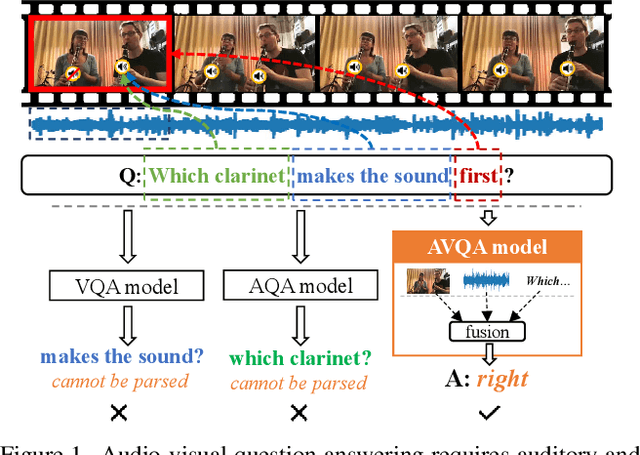

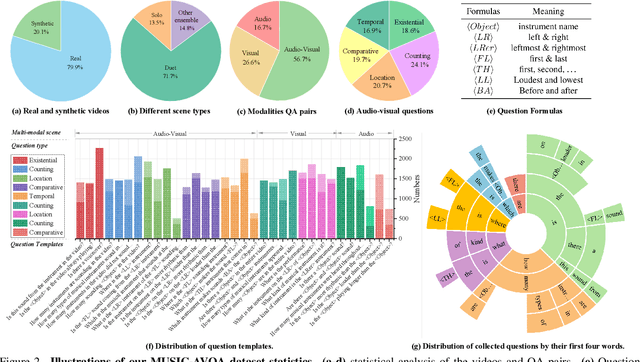
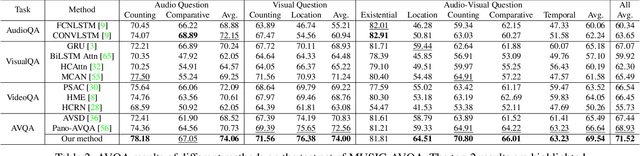
In this paper, we focus on the Audio-Visual Question Answering (AVQA) task, which aims to answer questions regarding different visual objects, sounds, and their associations in videos. The problem requires comprehensive multimodal understanding and spatio-temporal reasoning over audio-visual scenes. To benchmark this task and facilitate our study, we introduce a large-scale MUSIC-AVQA dataset, which contains more than 45K question-answer pairs covering 33 different question templates spanning over different modalities and question types. We develop several baselines and introduce a spatio-temporal grounded audio-visual network for the AVQA problem. Our results demonstrate that AVQA benefits from multisensory perception and our model outperforms recent A-, V-, and AVQA approaches. We believe that our built dataset has the potential to serve as testbed for evaluating and promoting progress in audio-visual scene understanding and spatio-temporal reasoning. Code and dataset: http://gewu-lab.github.io/MUSIC-AVQA/
WegFormer: Transformers for Weakly Supervised Semantic Segmentation
Mar 16, 2022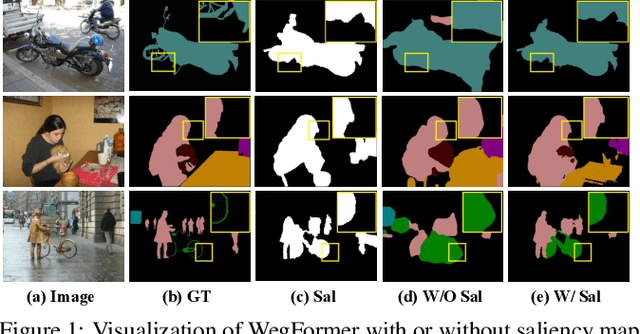
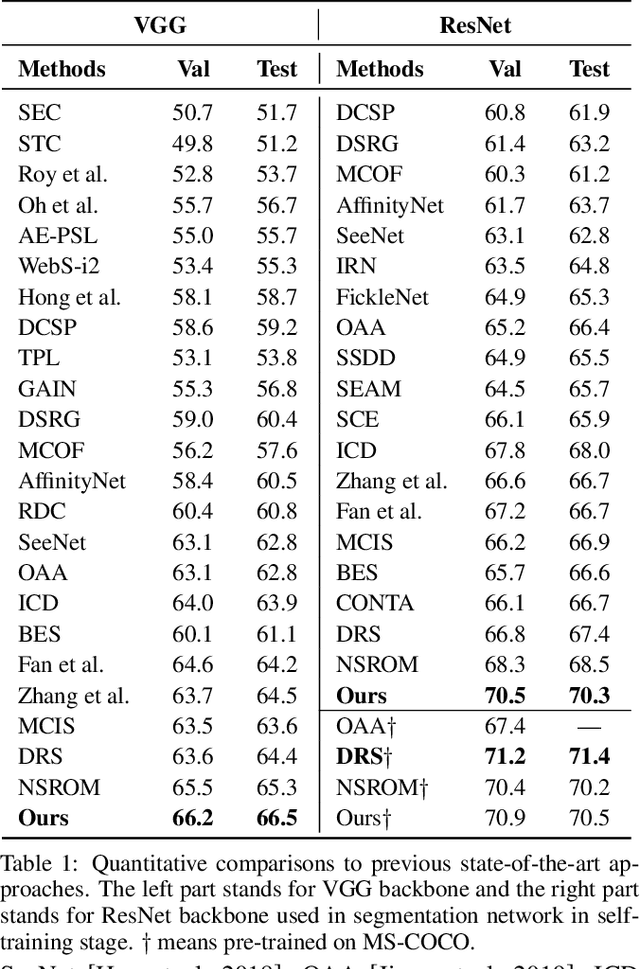
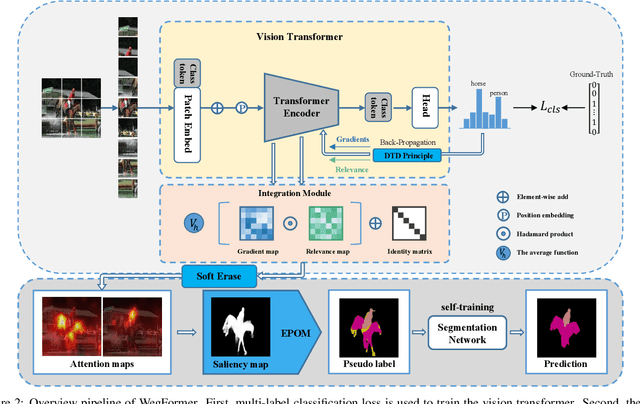

Although convolutional neural networks (CNNs) have achieved remarkable progress in weakly supervised semantic segmentation (WSSS), the effective receptive field of CNN is insufficient to capture global context information, leading to sub-optimal results. Inspired by the great success of Transformers in fundamental vision areas, this work for the first time introduces Transformer to build a simple and effective WSSS framework, termed WegFormer. Unlike existing CNN-based methods, WegFormer uses Vision Transformer (ViT) as a classifier to produce high-quality pseudo segmentation masks. To this end, we introduce three tailored components in our Transformer-based framework, which are (1) a Deep Taylor Decomposition (DTD) to generate attention maps, (2) a soft erasing module to smooth the attention maps, and (3) an efficient potential object mining (EPOM) to filter noisy activation in the background. Without any bells and whistles, WegFormer achieves state-of-the-art 70.5% mIoU on the PASCAL VOC dataset, significantly outperforming the previous best method. We hope WegFormer provides a new perspective to tap the potential of Transformer in weakly supervised semantic segmentation. Code will be released.
Self-supervised Audiovisual Representation Learning for Remote Sensing Data
Aug 02, 2021
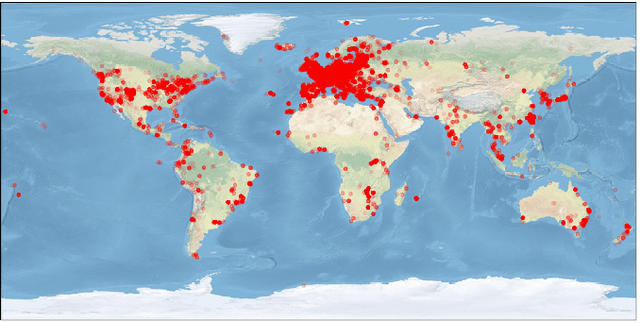
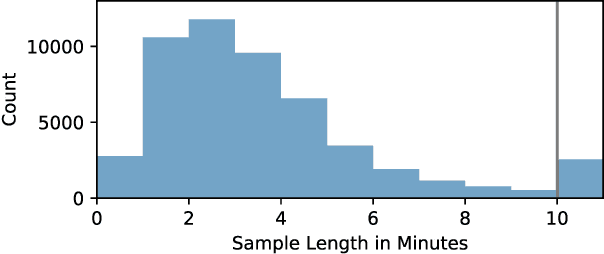
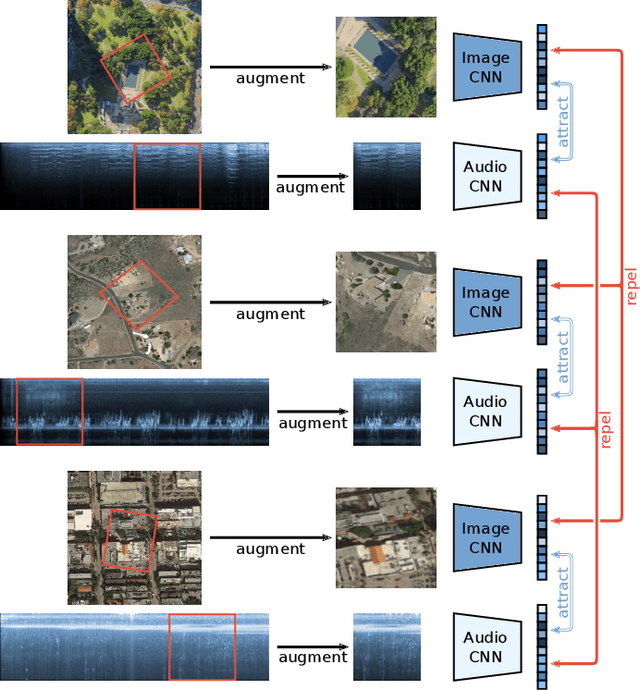
Many current deep learning approaches make extensive use of backbone networks pre-trained on large datasets like ImageNet, which are then fine-tuned to perform a certain task. In remote sensing, the lack of comparable large annotated datasets and the wide diversity of sensing platforms impedes similar developments. In order to contribute towards the availability of pre-trained backbone networks in remote sensing, we devise a self-supervised approach for pre-training deep neural networks. By exploiting the correspondence between geo-tagged audio recordings and remote sensing imagery, this is done in a completely label-free manner, eliminating the need for laborious manual annotation. For this purpose, we introduce the SoundingEarth dataset, which consists of co-located aerial imagery and audio samples all around the world. Using this dataset, we then pre-train ResNet models to map samples from both modalities into a common embedding space, which encourages the models to understand key properties of a scene that influence both visual and auditory appearance. To validate the usefulness of the proposed approach, we evaluate the transfer learning performance of pre-trained weights obtained against weights obtained through other means. By fine-tuning the models on a number of commonly used remote sensing datasets, we show that our approach outperforms existing pre-training strategies for remote sensing imagery. The dataset, code and pre-trained model weights will be available at https://github.com/khdlr/SoundingEarth.
Rule-Guided Graph Neural Networks for Recommender Systems
Sep 09, 2020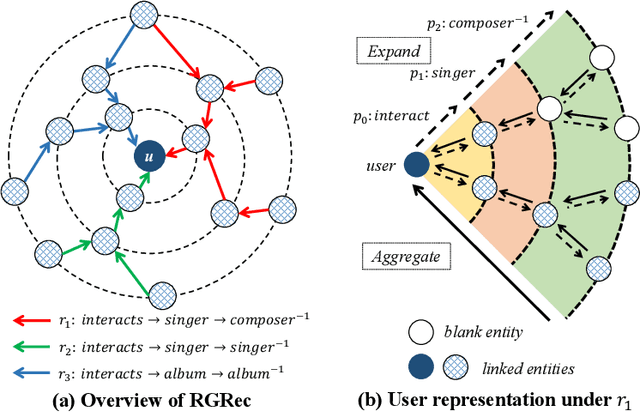
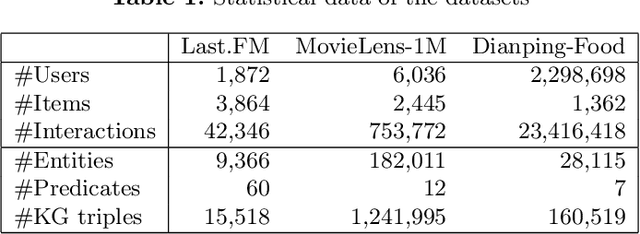
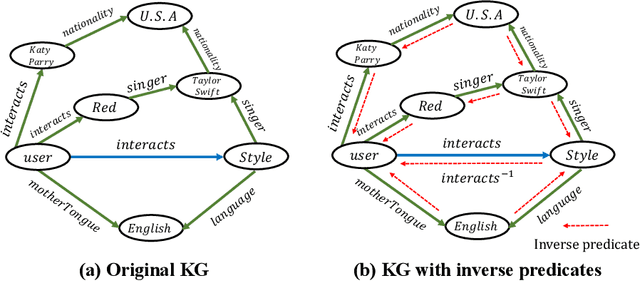
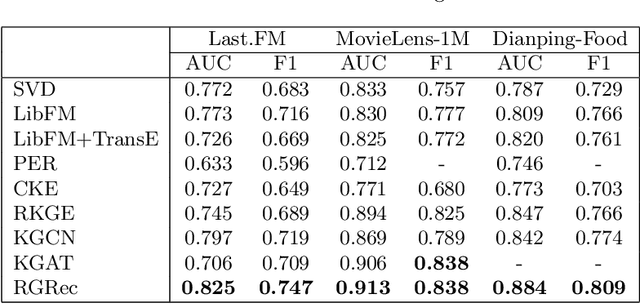
To alleviate the cold start problem caused by collaborative filtering in recommender systems, knowledge graphs (KGs) are increasingly employed by many methods as auxiliary resources. However, existing work incorporated with KGs cannot capture the explicit long-range semantics between users and items meanwhile consider various connectivity between items. In this paper, we propose RGRec, which combines rule learning and graph neural networks (GNNs) for recommendation. RGRec first maps items to corresponding entities in KGs and adds users as new entities. Then, it automatically learns rules to model the explicit long-range semantics, and captures the connectivity between entities by aggregation to better encode various information. We show the effectiveness of RGRec on three real-world datasets. Particularly, the combination of rule learning and GNNs achieves substantial improvement compared to methods only using either of them.
Deep Inception Generative Network for Cognitive Image Inpainting
Dec 01, 2018
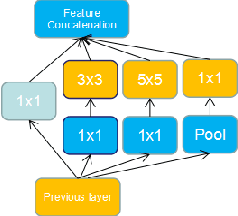
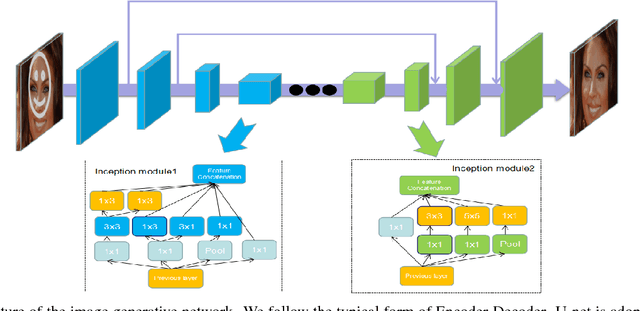

Recent advances in deep learning have shown exciting promise in filling large holes and lead to another orientation for image inpainting. However, existing learning-based methods often create artifacts and fallacious textures because of insufficient cognition understanding. Previous generative networks are limited with single receptive type and give up pooling in consideration of detail sharpness. Human cognition is constant regardless of the target attribute. As multiple receptive fields improve the ability of abstract image characterization and pooling can keep feature invariant, specifically, deep inception learning is adopted to promote high-level feature representation and enhance model learning capacity for local patches. Moreover, approaches for generating diverse mask images are introduced and a random mask dataset is created. We benchmark our methods on ImageNet, Places2 dataset, and CelebA-HQ. Experiments for regular, irregular, and custom regions completion are all performed and free-style image inpainting is also presented. Quantitative comparisons with previous state-of-the-art methods show that ours obtain much more natural image completions.
Scene Text Detection with Supervised Pyramid Context Network
Nov 21, 2018
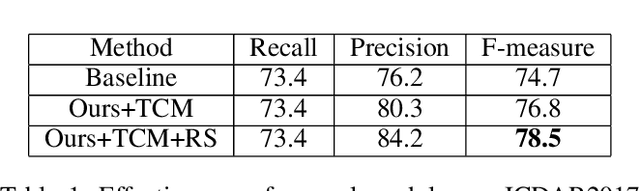
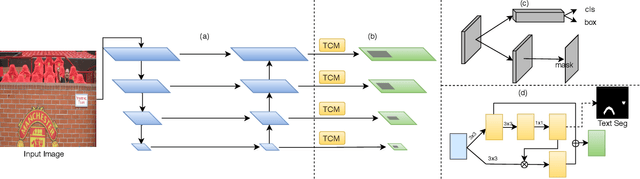
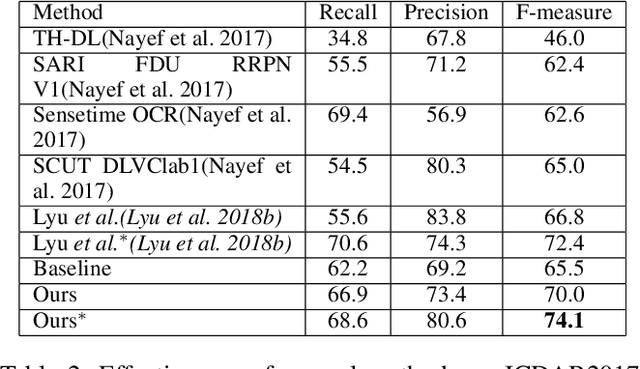
Scene text detection methods based on deep learning have achieved remarkable results over the past years. However, due to the high diversity and complexity of natural scenes, previous state-of-the-art text detection methods may still produce a considerable amount of false positives, when applied to images captured in real-world environments. To tackle this issue, mainly inspired by Mask R-CNN, we propose in this paper an effective model for scene text detection, which is based on Feature Pyramid Network (FPN) and instance segmentation. We propose a supervised pyramid context network (SPCNET) to precisely locate text regions while suppressing false positives. Benefited from the guidance of semantic information and sharing FPN, SPCNET obtains significantly enhanced performance while introducing marginal extra computation. Experiments on standard datasets demonstrate that our SPCNET clearly outperforms start-of-the-art methods. Specifically, it achieves an F-measure of 92.1% on ICDAR2013, 87.2% on ICDAR2015, 74.1% on ICDAR2017 MLT and 82.9% on Total-Text.