 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColonoscopy Polyp Detection and Classification: Dataset Creation and Comparative Evaluations
Apr 22, 2021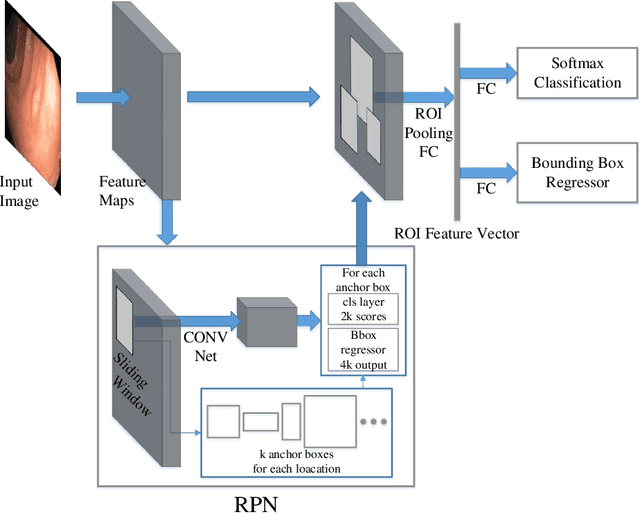
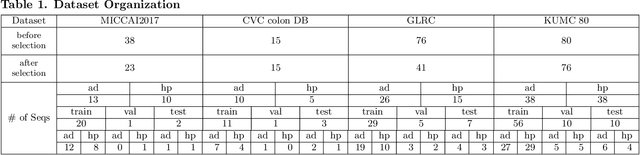
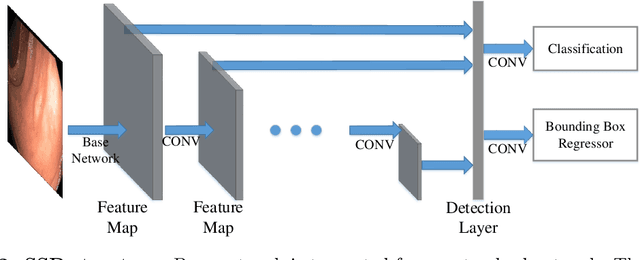
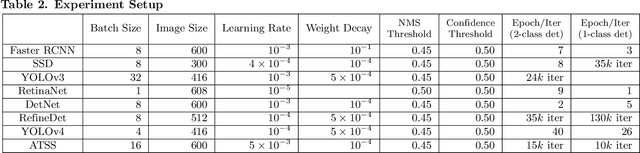
Colorectal cancer (CRC) is one of the most common types of cancer with a high mortality rate. Colonoscopy is the preferred procedure for CRC screening and has proven to be effective in reducing CRC mortality. Thus, a reliable computer-aided polyp detection and classification system can significantly increase the effectiveness of colonoscopy. In this paper, we create an endoscopic dataset collected from various sources and annotate the ground truth of polyp location and classification results with the help of experienced gastroenterologists. The dataset can serve as a benchmark platform to train and evaluate the machine learning models for polyp classification. We have also compared the performance of eight state-of-the-art deep learning-based object detection models. The results demonstrate that deep CNN models are promising in CRC screening. This work can serve as a baseline for future research in polyp detection and classification.
Branch-and-Pruning Optimization Towards Global Optimality in Deep Learning
Apr 05, 2021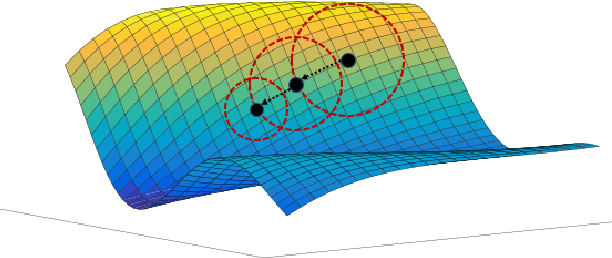
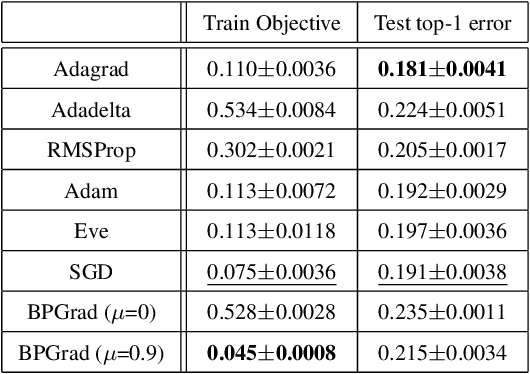
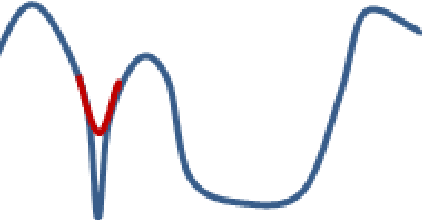
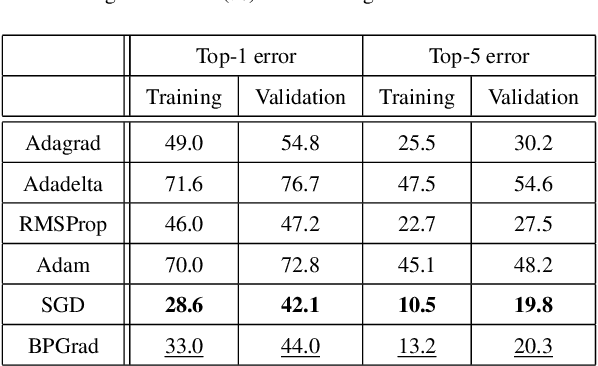
It has been attracting more and more attention to understand the global optimality in deep learning (DL) recently. However, conventional DL solvers, have not been developed intentionally to seek for such global optimality. In this paper, we propose a novel approximation algorithm, {\em BPGrad}, towards optimizing deep models globally via branch and pruning. The proposed BPGrad algorithm is based on the assumption of Lipschitz continuity in DL, and as a result, it can adaptively determine the step size for the current gradient given the history of previous updates, wherein theoretically no smaller steps can achieve the global optimality. We prove that, by repeating such a branch-and-pruning procedure, we can locate the global optimality within finite iterations. Empirically an efficient adaptive solver based on BPGrad for DL is proposed as well, and it outperforms conventional DL solvers such as Adagrad, Adadelta, RMSProp, and Adam in the tasks of object recognition, detection, and segmentation. The code is available at \url{https://github.com/RyanCV/BPGrad}.
Online Convex Optimization with Continuous Switching Constraint
Mar 21, 2021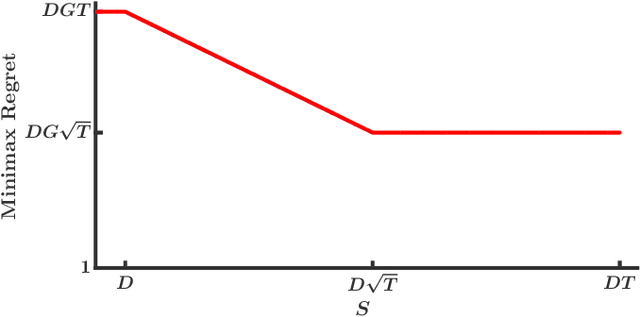
In many sequential decision making applications, the change of decision would bring an additional cost, such as the wear-and-tear cost associated with changing server status. To control the switching cost, we introduce the problem of online convex optimization with continuous switching constraint, where the goal is to achieve a small regret given a budget on the \emph{overall} switching cost. We first investigate the hardness of the problem, and provide a lower bound of order $\Omega(\sqrt{T})$ when the switching cost budget $S=\Omega(\sqrt{T})$, and $\Omega(\min\{\frac{T}{S},T\})$ when $S=O(\sqrt{T})$, where $T$ is the time horizon. The essential idea is to carefully design an adaptive adversary, who can adjust the loss function according to the cumulative switching cost of the player incurred so far based on the orthogonal technique. We then develop a simple gradient-based algorithm which enjoys the minimax optimal regret bound. Finally, we show that, for strongly convex functions, the regret bound can be improved to $O(\log T)$ for $S=\Omega(\log T)$, and $O(\min\{T/\exp(S)+S,T\})$ for $S=O(\log T)$.
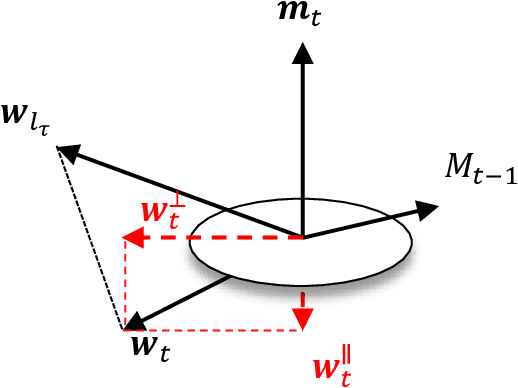
Projection-free Distributed Online Learning with Strongly Convex Losses
Mar 20, 2021
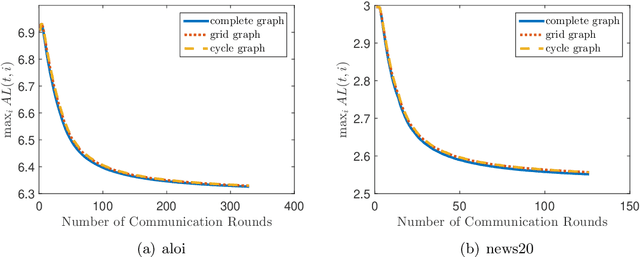
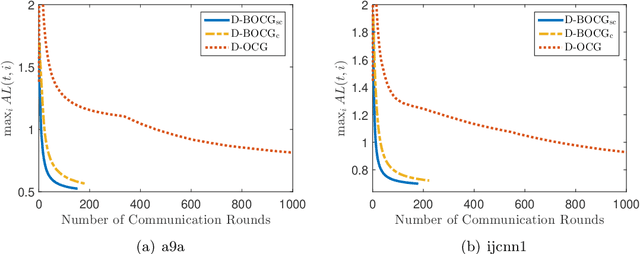
To efficiently solve distributed online learning problems with complicated constraints, previous studies have proposed several distributed projection-free algorithms. The state-of-the-art one achieves the $O({T}^{3/4})$ regret bound with $O(\sqrt{T})$ communication complexity. In this paper, we further exploit the strong convexity of loss functions to improve the regret bound and communication complexity. Specifically, we first propose a distributed projection-free algorithm for strongly convex loss functions, which enjoys a better regret bound of $O(T^{2/3}\log T)$ with smaller communication complexity of $O(T^{1/3})$. Furthermore, we demonstrate that the regret of distributed online algorithms with $C$ communication rounds has a lower bound of $\Omega(T/C)$, even when the loss functions are strongly convex. This lower bound implies that the $O(T^{1/3})$ communication complexity of our algorithm is nearly optimal for obtaining the $O(T^{2/3}\log T)$ regret bound up to polylogarithmic factors. Finally, we extend our algorithm into the bandit setting and obtain similar theoretical guarantees.
Classification of Long Noncoding RNA Elements Using Deep Convolutional Neural Networks and Siamese Networks
Feb 10, 2021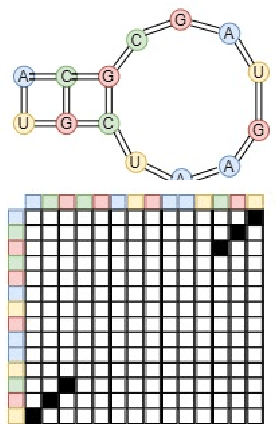
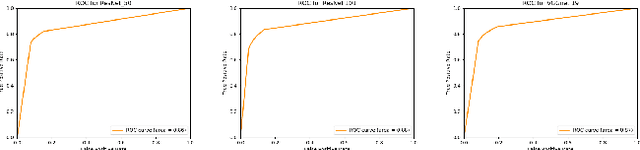
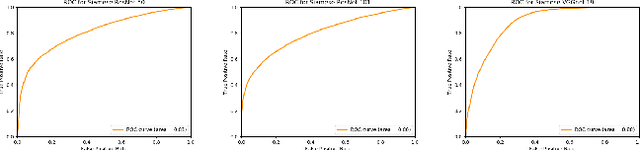

In the last decade, the discovery of noncoding RNA(ncRNA) has exploded. Classifying these ncRNA is critical todetermining their function. This thesis proposes a new methodemploying deep convolutional neural networks (CNNs) to classifyncRNA sequences. To this end, this paper first proposes anefficient approach to convert the RNA sequences into imagescharacterizing their base-pairing probability. As a result, clas-sifying RNA sequences is converted to an image classificationproblem that can be efficiently solved by available CNN-basedclassification models. This research also considers the foldingpotential of the ncRNAs in addition to their primary sequence.Based on the proposed approach, a benchmark image classifi-cation dataset is generated from the RFAM database of ncRNAsequences. In addition, three classical CNN models and threeSiamese network models have been implemented and comparedto demonstrate the superior performance and efficiency of theproposed approach. Extensive experimental results show thegreat potential of using deep learning approaches for RNAclassification.
SOSD-Net: Joint Semantic Object Segmentation and Depth Estimation from Monocular images
Jan 19, 2021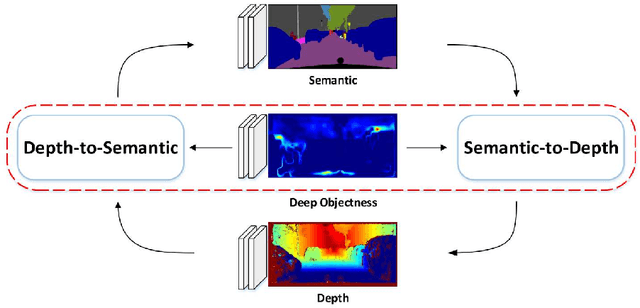
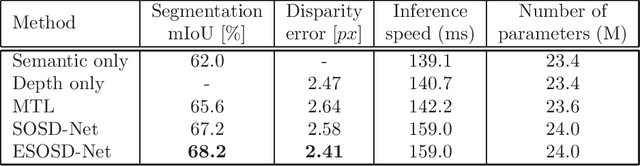
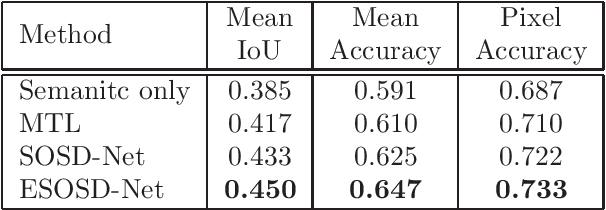
Depth estimation and semantic segmentation play essential roles in scene understanding. The state-of-the-art methods employ multi-task learning to simultaneously learn models for these two tasks at the pixel-wise level. They usually focus on sharing the common features or stitching feature maps from the corresponding branches. However, these methods lack in-depth consideration on the correlation of the geometric cues and the scene parsing. In this paper, we first introduce the concept of semantic objectness to exploit the geometric relationship of these two tasks through an analysis of the imaging process, then propose a Semantic Object Segmentation and Depth Estimation Network (SOSD-Net) based on the objectness assumption. To the best of our knowledge, SOSD-Net is the first network that exploits the geometry constraint for simultaneous monocular depth estimation and semantic segmentation. In addition, considering the mutual implicit relationship between these two tasks, we exploit the iterative idea from the expectation-maximization algorithm to train the proposed network more effectively. Extensive experimental results on the Cityscapes and NYU v2 dataset are presented to demonstrate the superior performance of the proposed approach.
Six-channel Image Representation for Cross-domain Object Detection
Jan 03, 2021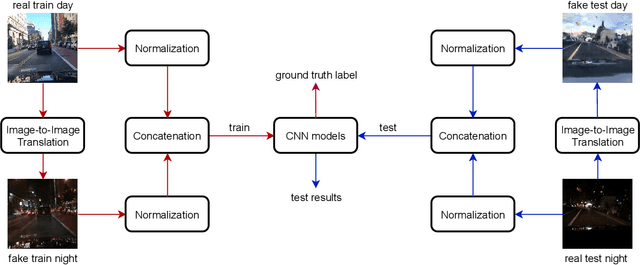



Most deep learning models are data-driven and the excellent performance is highly dependent on the abundant and diverse datasets. However, it is very hard to obtain and label the datasets of some specific scenes or applications. If we train the detector using the data from one domain, it cannot perform well on the data from another domain due to domain shift, which is one of the big challenges of most object detection models. To address this issue, some image-to-image translation techniques are employed to generate some fake data of some specific scenes to train the models. With the advent of Generative Adversarial Networks (GANs), we could realize unsupervised image-to-image translation in both directions from a source to a target domain and from the target to the source domain. In this study, we report a new approach to making use of the generated images. We propose to concatenate the original 3-channel images and their corresponding GAN-generated fake images to form 6-channel representations of the dataset, hoping to address the domain shift problem while exploiting the success of available detection models. The idea of augmented data representation may inspire further study on object detection and other applications.
Efficient Golf Ball Detection and Tracking Based on Convolutional Neural Networks and Kalman Filter
Dec 17, 2020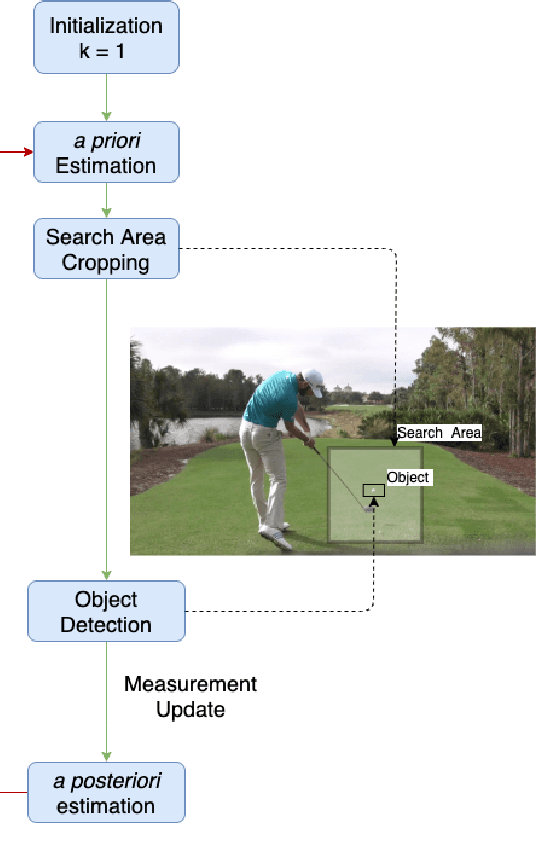

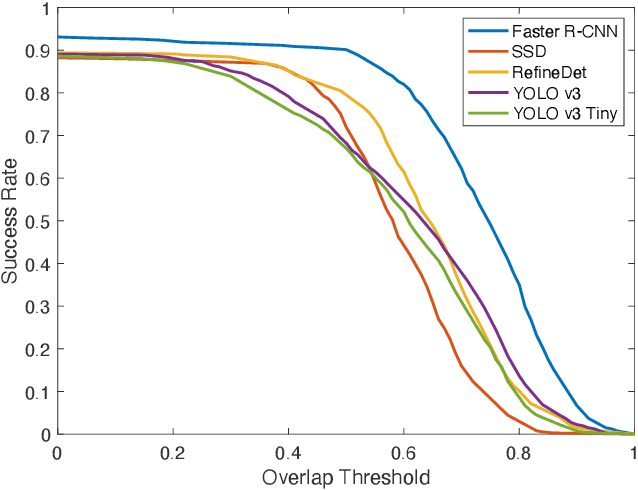
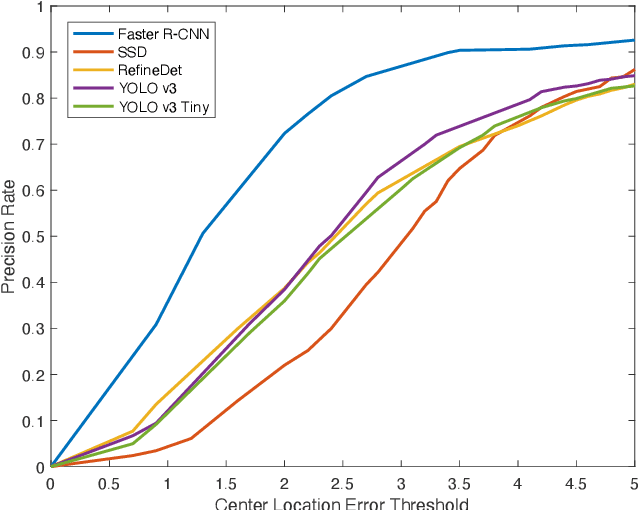
This paper focuses on the problem of online golf ball detection and tracking from image sequences. An efficient real-time approach is proposed by exploiting convolutional neural networks (CNN) based object detection and a Kalman filter based prediction. Five classical deep learning-based object detection networks are implemented and evaluated for ball detection, including YOLO v3 and its tiny version, YOLO v4, Faster R-CNN, SSD, and RefineDet. The detection is performed on small image patches instead of the entire image to increase the performance of small ball detection. At the tracking stage, a discrete Kalman filter is employed to predict the location of the ball and a small image patch is cropped based on the prediction. Then, the object detector is utilized to refine the location of the ball and update the parameters of Kalman filter. In order to train the detection models and test the tracking algorithm, a collection of golf ball dataset is created and annotated. Extensive comparative experiments are performed to demonstrate the effectiveness and superior tracking performance of the proposed scheme.
Stereo Frustums: A Siamese Pipeline for 3D Object Detection
Nov 08, 2020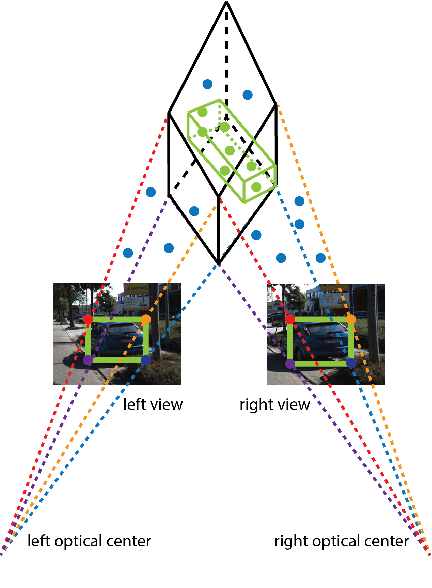
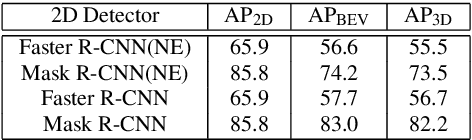
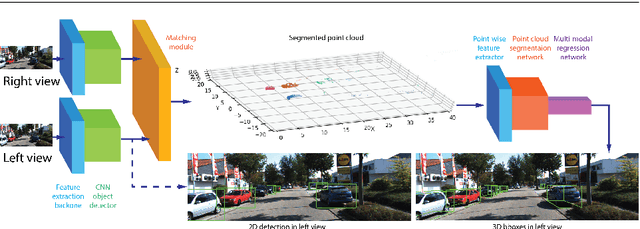
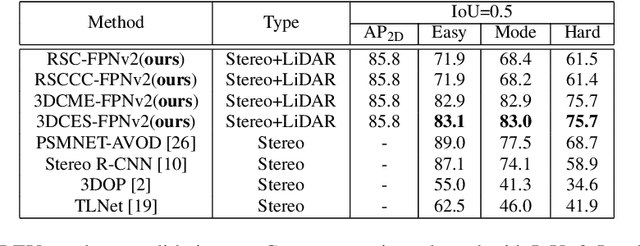
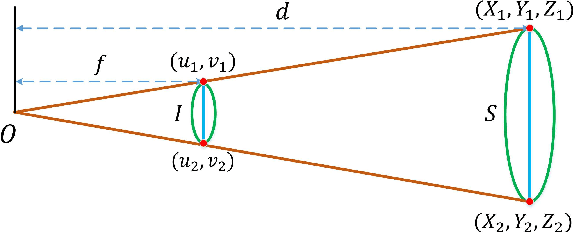
The paper proposes a light-weighted stereo frustums matching module for 3D objection detection. The proposed framework takes advantage of a high-performance 2D detector and a point cloud segmentation network to regress 3D bounding boxes for autonomous driving vehicles. Instead of performing traditional stereo matching to compute disparities, the module directly takes the 2D proposals from both the left and the right views as input. Based on the epipolar constraints recovered from the well-calibrated stereo cameras, we propose four matching algorithms to search for the best match for each proposal between the stereo image pairs. Each matching pair proposes a segmentation of the scene which is then fed into a 3D bounding box regression network. Results of extensive experiments on KITTI dataset demonstrate that the proposed Siamese pipeline outperforms the state-of-the-art stereo-based 3D bounding box regression methods.
Deep Feature Augmentation for Occluded Image Classification
Nov 02, 2020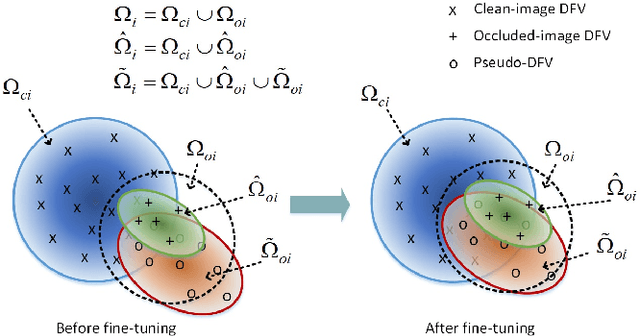
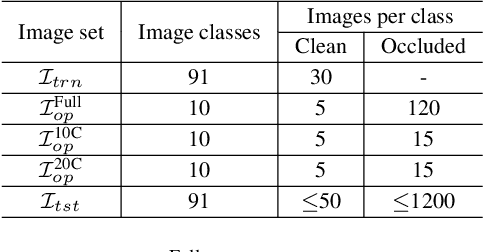
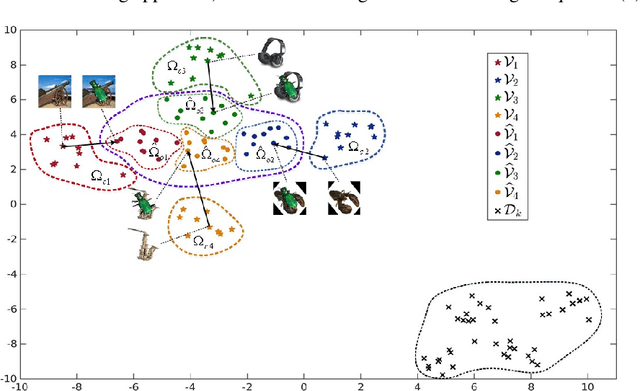
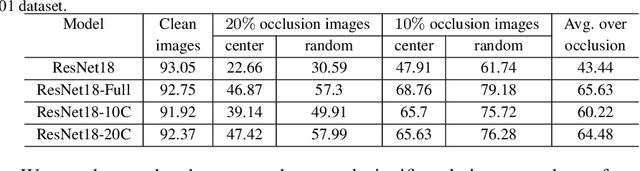
Due to the difficulty in acquiring massive task-specific occluded images, the classification of occluded images with deep convolutional neural networks (CNNs) remains highly challenging. To alleviate the dependency on large-scale occluded image datasets, we propose a novel approach to improve the classification accuracy of occluded images by fine-tuning the pre-trained models with a set of augmented deep feature vectors (DFVs). The set of augmented DFVs is composed of original DFVs and pseudo-DFVs. The pseudo-DFVs are generated by randomly adding difference vectors (DVs), extracted from a small set of clean and occluded image pairs, to the real DFVs. In the fine-tuning, the back-propagation is conducted on the DFV data flow to update the network parameters. The experiments on various datasets and network structures show that the deep feature augmentation significantly improves the classification accuracy of occluded images without a noticeable influence on the performance of clean images. Specifically, on the ILSVRC2012 dataset with synthetic occluded images, the proposed approach achieves 11.21% and 9.14% average increases in classification accuracy for the ResNet50 networks fine-tuned on the occlusion-exclusive and occlusion-inclusive training sets, respectively.