 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS$^{3}$: Increasing GPU Utilization during Generative Inference for Higher Throughput
Jun 09, 2023



Generating texts with a large language model (LLM) consumes massive amounts of memory. Apart from the already-large model parameters, the key/value (KV) cache that holds information about previous tokens in a sequence can grow to be even larger than the model itself. This problem is exacerbated in one of the current LLM serving frameworks which reserves the maximum sequence length of memory for the KV cache to guarantee generating a complete sequence as they do not know the output sequence length. This restricts us to use a smaller batch size leading to lower GPU utilization and above all, lower throughput. We argue that designing a system with a priori knowledge of the output sequence can mitigate this problem. To this end, we propose S$^{3}$, which predicts the output sequence length, schedules generation queries based on the prediction to increase device resource utilization and throughput, and handle mispredictions. Our proposed method achieves 6.49$\times$ throughput over those systems that assume the worst case for the output sequence length.
CAMEL: Co-Designing AI Models and Embedded DRAMs for Efficient On-Device Learning
May 04, 2023



The emergence of the Internet of Things (IoT) has resulted in a remarkable amount of data generated on edge devices, which are often processed using AI algorithms. On-device learning enables edge platforms to continually adapt the AI models to user personal data and further allows for a better service quality. However, AI training on resource-limited devices is extremely difficult because of the intensive computing workload and the significant amount of on-chip memory consumption exacted by deep neural networks (DNNs). To mitigate this, we propose to use embedded dynamic random-access memory (eDRAM) as the main storage medium of training data. Compared with static random-access memory (SRAM), eDRAM introduces more than $2\times$ improvement on storage density, enabling reduced off-chip memory traffic. However, to keep the stored data intact, eDRAM is required to perform the power-hungry data refresh operations. eDRAM refresh can be eliminated if the data is stored for a period of time that is shorter than the eDRAM retention time. To achieve this, we design a novel reversible DNN architecture that enables a significantly reduced data lifetime during the training process and removes the need for eDRAM refresh. We further design an efficient on-device training engine, termed~\textit{CAMEL}, that uses eDRAM as the main on-chip memory. CAMEL enables the intermediate results during training to fit fully in on-chip eDRAM arrays and completely eliminates the off-chip DRAM traffic during the training process. We evaluate our CAMEL system on multiple DNNs with different datasets, demonstrating a more than $3\times$ saving on total DNN training energy consumption than the other baselines, while achieving a similar (even better) performance in validation accuracy.
MP-Rec: Hardware-Software Co-Design to Enable Multi-Path Recommendation
Feb 21, 2023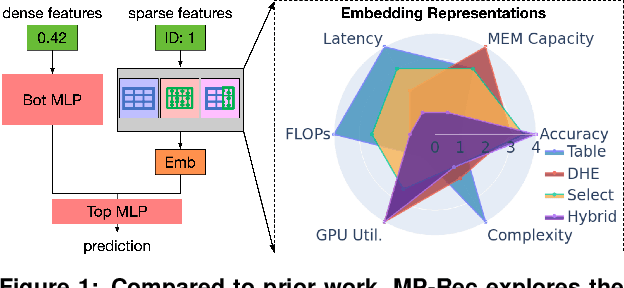

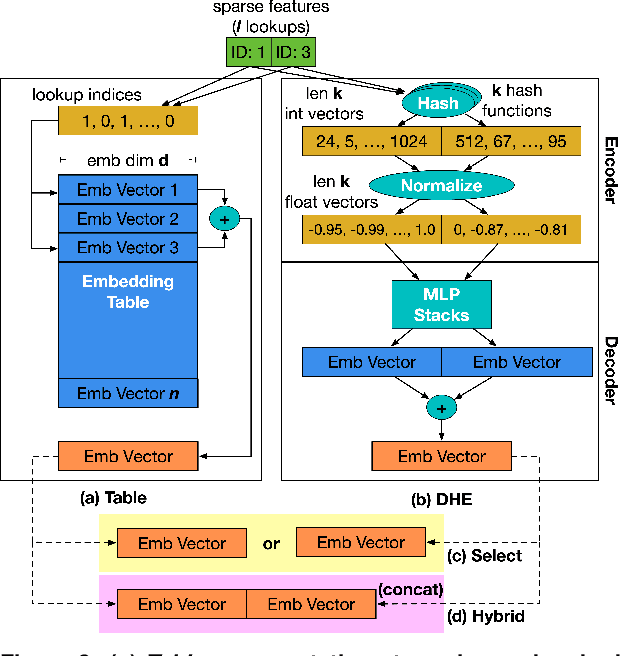
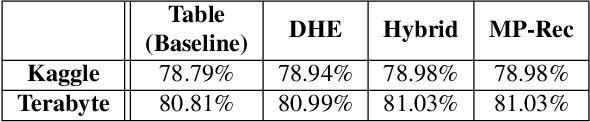
Deep learning recommendation systems serve personalized content under diverse tail-latency targets and input-query loads. In order to do so, state-of-the-art recommendation models rely on terabyte-scale embedding tables to learn user preferences over large bodies of contents. The reliance on a fixed embedding representation of embedding tables not only imposes significant memory capacity and bandwidth requirements but also limits the scope of compatible system solutions. This paper challenges the assumption of fixed embedding representations by showing how synergies between embedding representations and hardware platforms can lead to improvements in both algorithmic- and system performance. Based on our characterization of various embedding representations, we propose a hybrid embedding representation that achieves higher quality embeddings at the cost of increased memory and compute requirements. To address the system performance challenges of the hybrid representation, we propose MP-Rec -- a co-design technique that exploits heterogeneity and dynamic selection of embedding representations and underlying hardware platforms. On real system hardware, we demonstrate how matching custom accelerators, i.e., GPUs, TPUs, and IPUs, with compatible embedding representations can lead to 16.65x performance speedup. Additionally, in query-serving scenarios, MP-Rec achieves 2.49x and 3.76x higher correct prediction throughput and 0.19% and 0.22% better model quality on a CPU-GPU system for the Kaggle and Terabyte datasets, respectively.
GPU-based Private Information Retrieval for On-Device Machine Learning Inference
Jan 27, 2023



On-device machine learning (ML) inference can enable the use of private user data on user devices without remote servers. However, a pure on-device solution to private ML inference is impractical for many applications that rely on embedding tables that are too large to be stored on-device. To overcome this barrier, we propose the use of private information retrieval (PIR) to efficiently and privately retrieve embeddings from servers without sharing any private information during on-device ML inference. As off-the-shelf PIR algorithms are usually too computationally intensive to directly use for latency-sensitive inference tasks, we 1) develop a novel algorithm for accelerating PIR on GPUs, and 2) co-design PIR with the downstream ML application to obtain further speedup. Our GPU acceleration strategy improves system throughput by more than $20 \times$ over an optimized CPU PIR implementation, and our co-design techniques obtain over $5 \times$ additional throughput improvement at fixed model quality. Together, on various on-device ML applications such as recommendation and language modeling, our system on a single V100 GPU can serve up to $100,000$ queries per second -- a $>100 \times$ throughput improvement over a naively implemented system -- while maintaining model accuracy, and limiting inference communication and response latency to within $300$KB and $<100$ms respectively.
PerfSAGE: Generalized Inference Performance Predictor for Arbitrary Deep Learning Models on Edge Devices
Jan 26, 2023The ability to accurately predict deep neural network (DNN) inference performance metrics, such as latency, power, and memory footprint, for an arbitrary DNN on a target hardware platform is essential to the design of DNN based models. This ability is critical for the (manual or automatic) design, optimization, and deployment of practical DNNs for a specific hardware deployment platform. Unfortunately, these metrics are slow to evaluate using simulators (where available) and typically require measurement on the target hardware. This work describes PerfSAGE, a novel graph neural network (GNN) that predicts inference latency, energy, and memory footprint on an arbitrary DNN TFlite graph (TFL, 2017). In contrast, previously published performance predictors can only predict latency and are restricted to pre-defined construction rules or search spaces. This paper also describes the EdgeDLPerf dataset of 134,912 DNNs randomly sampled from four task search spaces and annotated with inference performance metrics from three edge hardware platforms. Using this dataset, we train PerfSAGE and provide experimental results that demonstrate state-of-the-art prediction accuracy with a Mean Absolute Percentage Error of <5% across all targets and model search spaces. These results: (1) Outperform previous state-of-art GNN-based predictors (Dudziak et al., 2020), (2) Accurately predict performance on accelerators (a shortfall of non-GNN-based predictors (Zhang et al., 2021)), and (3) Demonstrate predictions on arbitrary input graphs without modifications to the feature extractor.
Architectural Implications of Embedding Dimension during GCN on CPU and GPU
Dec 01, 2022Graph Neural Networks (GNNs) are a class of neural networks designed to extract information from the graphical structure of data. Graph Convolutional Networks (GCNs) are a widely used type of GNN for transductive graph learning problems which apply convolution to learn information from graphs. GCN is a challenging algorithm from an architecture perspective due to inherent sparsity, low data reuse, and massive memory capacity requirements. Traditional neural algorithms exploit the high compute capacity of GPUs to achieve high performance for both inference and training. The architectural decision to use a GPU for GCN inference is a question explored in this work. GCN on both CPU and GPU was characterized in order to better understand the implications of graph size, embedding dimension, and sampling on performance.
OMU: A Probabilistic 3D Occupancy Mapping Accelerator for Real-time OctoMap at the Edge
May 06, 2022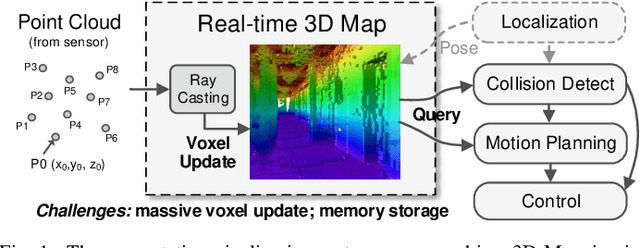
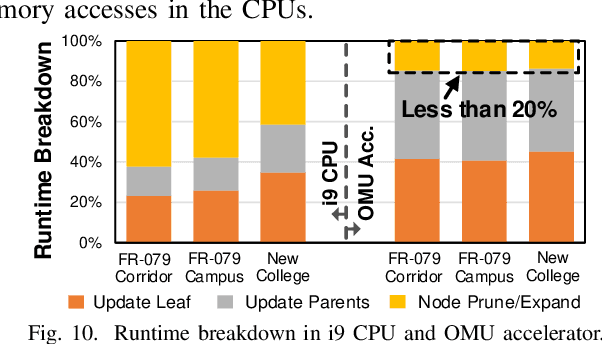
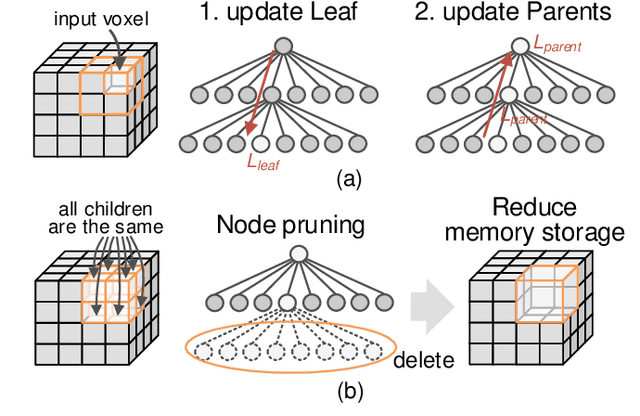
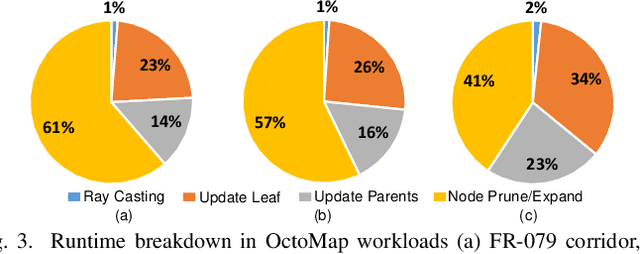
Autonomous machines (e.g., vehicles, mobile robots, drones) require sophisticated 3D mapping to perceive the dynamic environment. However, maintaining a real-time 3D map is expensive both in terms of compute and memory requirements, especially for resource-constrained edge machines. Probabilistic OctoMap is a reliable and memory-efficient 3D dense map model to represent the full environment, with dynamic voxel node pruning and expansion capacity. This paper presents the first efficient accelerator solution, i.e. OMU, to enable real-time probabilistic 3D mapping at the edge. To improve the performance, the input map voxels are updated via parallel PE units for data parallelism. Within each PE, the voxels are stored using a specially developed data structure in parallel memory banks. In addition, a pruning address manager is designed within each PE unit to reuse the pruned memory addresses. The proposed 3D mapping accelerator is implemented and evaluated using a commercial 12 nm technology. Compared to the ARM Cortex-A57 CPU in the Nvidia Jetson TX2 platform, the proposed accelerator achieves up to 62$\times$ performance and 708$\times$ energy efficiency improvement. Furthermore, the accelerator provides 63 FPS throughput, more than 2$\times$ higher than a real-time requirement, enabling real-time perception for 3D mapping.
Tabula: Efficiently Computing Nonlinear Activation Functions for Secure Neural Network Inference
Mar 05, 2022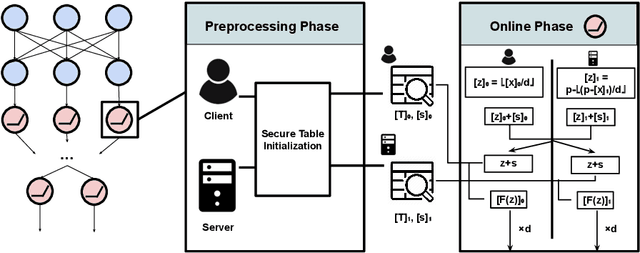

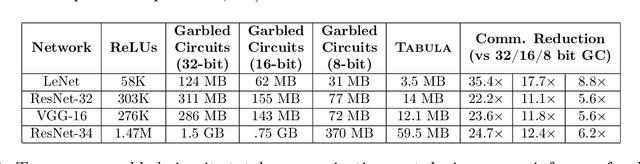
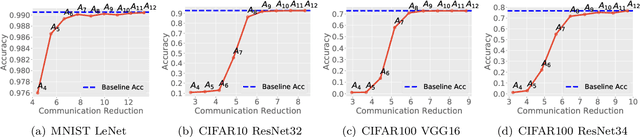
Multiparty computation approaches to secure neural network inference traditionally rely on garbled circuits for securely executing nonlinear activation functions. However, garbled circuits require excessive communication between server and client, impose significant storage overheads, and incur large runtime penalties. To eliminate these costs, we propose an alternative to garbled circuits: Tabula, an algorithm based on secure lookup tables. Tabula leverages neural networks' ability to be quantized and employs a secure lookup table approach to efficiently, securely, and accurately compute neural network nonlinear activation functions. Compared to garbled circuits with quantized inputs, when computing individual nonlinear functions, our experiments show Tabula uses between $35 \times$-$70 \times$ less communication, is over $100\times$ faster, and uses a comparable amount of storage. This leads to significant performance gains over garbled circuits with quantized inputs during secure inference on neural networks: Tabula reduces overall communication by up to $9 \times$ and achieves a speedup of up to $50 \times$, while imposing comparable storage costs.
Gradient Disaggregation: Breaking Privacy in Federated Learning by Reconstructing the User Participant Matrix
Jun 10, 2021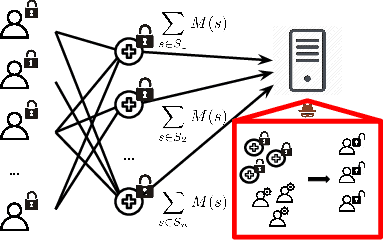
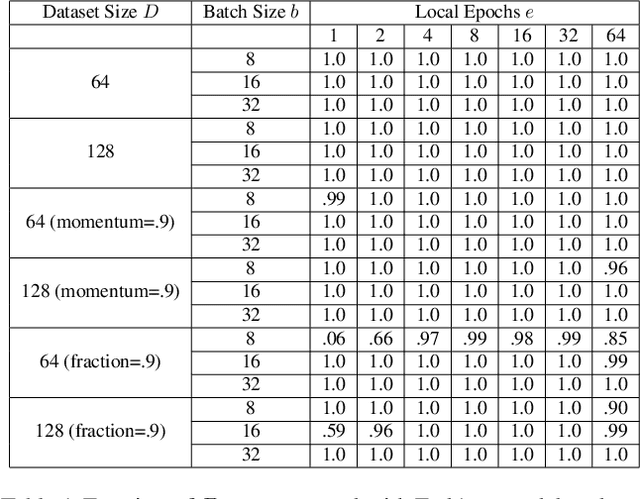
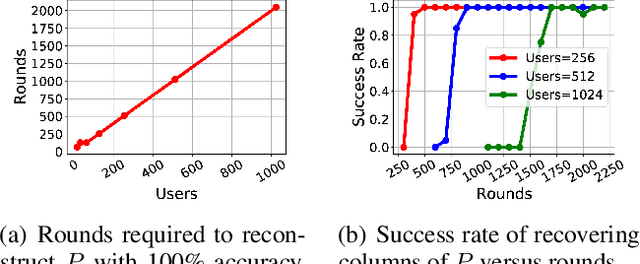

We show that aggregated model updates in federated learning may be insecure. An untrusted central server may disaggregate user updates from sums of updates across participants given repeated observations, enabling the server to recover privileged information about individual users' private training data via traditional gradient inference attacks. Our method revolves around reconstructing participant information (e.g: which rounds of training users participated in) from aggregated model updates by leveraging summary information from device analytics commonly used to monitor, debug, and manage federated learning systems. Our attack is parallelizable and we successfully disaggregate user updates on settings with up to thousands of participants. We quantitatively and qualitatively demonstrate significant improvements in the capability of various inference attacks on the disaggregated updates. Our attack enables the attribution of learned properties to individual users, violating anonymity, and shows that a determined central server may undermine the secure aggregation protocol to break individual users' data privacy in federated learning.
MAVFI: An End-to-End Fault Analysis Framework with Anomaly Detection and Recovery for Micro Aerial Vehicles
May 27, 2021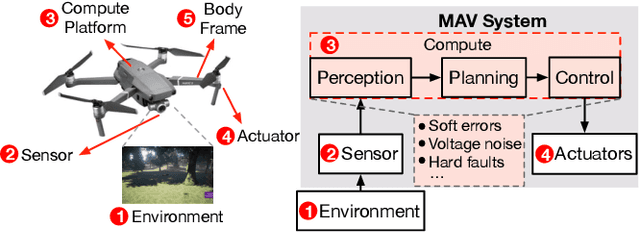

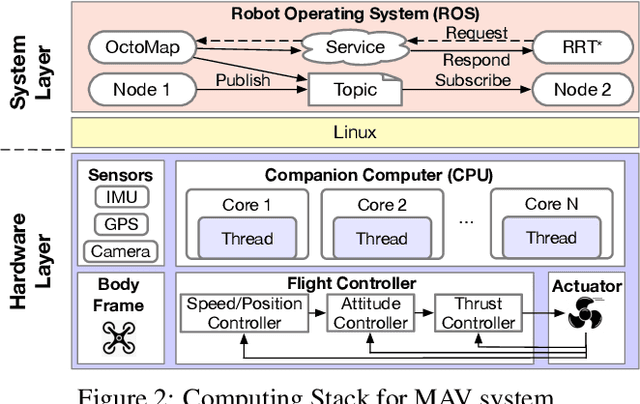
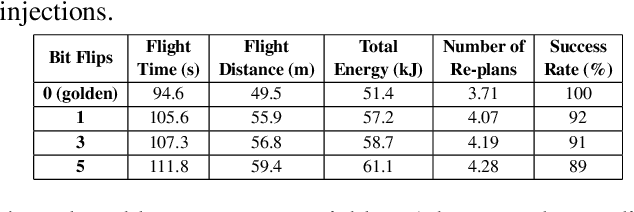
Reliability and safety are critical in autonomous machine services, such as autonomous vehicles and aerial drones. In this paper, we first present an open-source Micro Aerial Vehicles (MAVs) reliability analysis framework, MAVFI, to characterize transient fault's impacts on the end-to-end flight metrics, e.g., flight time, success rate. Based on our framework, it is observed that the end-to-end fault tolerance analysis is essential for characterizing system reliability. We demonstrate the planning and control stages are more vulnerable to transient faults than the visual perception stage in the common "Perception-Planning-Control (PPC)" compute pipeline. Furthermore, to improve the reliability of the MAV system, we propose two low overhead anomaly-based transient fault detection and recovery schemes based on Gaussian statistical models and autoencoder neural networks. We validate our anomaly fault protection schemes with a variety of simulated photo-realistic environments on both Intel i9 CPU and ARM Cortex-A57 on Nvidia TX2 platform. It is demonstrated that the autoencoder-based scheme can improve the system reliability by 100% recovering failure cases with less than 0.0062% computational overhead in best-case scenarios. In addition, MAVFI framework can be used for other ROS-based cyber-physical applications and is open-sourced at https://github.com/harvard-edge/MAVBench/tree/mavfi