 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Energy Cost of Reasoning: Analyzing Energy Usage in LLMs with Test-time Compute
May 20, 2025Scaling large language models (LLMs) has driven significant advancements, yet it faces diminishing returns and escalating energy demands. This work introduces test-time compute (TTC)-allocating additional computational resources during inference-as a compelling complement to conventional scaling strategies. Specifically, we investigate whether employing TTC can achieve superior accuracy-energy trade-offs compared to simply increasing model size. Our empirical analysis reveals that TTC surpasses traditional model scaling in accuracy/energy efficiency, with notable gains in tasks demanding complex reasoning rather than mere factual recall. Further, we identify a critical interaction between TTC performance and output sequence length, demonstrating that strategically adjusting compute resources at inference time according to query complexity can substantially enhance efficiency. Our findings advocate for TTC as a promising direction, enabling more sustainable, accurate, and adaptable deployment of future language models without incurring additional pretraining costs.
S$^{3}$: Increasing GPU Utilization during Generative Inference for Higher Throughput
Jun 09, 2023



Generating texts with a large language model (LLM) consumes massive amounts of memory. Apart from the already-large model parameters, the key/value (KV) cache that holds information about previous tokens in a sequence can grow to be even larger than the model itself. This problem is exacerbated in one of the current LLM serving frameworks which reserves the maximum sequence length of memory for the KV cache to guarantee generating a complete sequence as they do not know the output sequence length. This restricts us to use a smaller batch size leading to lower GPU utilization and above all, lower throughput. We argue that designing a system with a priori knowledge of the output sequence can mitigate this problem. To this end, we propose S$^{3}$, which predicts the output sequence length, schedules generation queries based on the prediction to increase device resource utilization and throughput, and handle mispredictions. Our proposed method achieves 6.49$\times$ throughput over those systems that assume the worst case for the output sequence length.
Bigger&Faster: Two-stage Neural Architecture Search for Quantized Transformer Models
Sep 25, 2022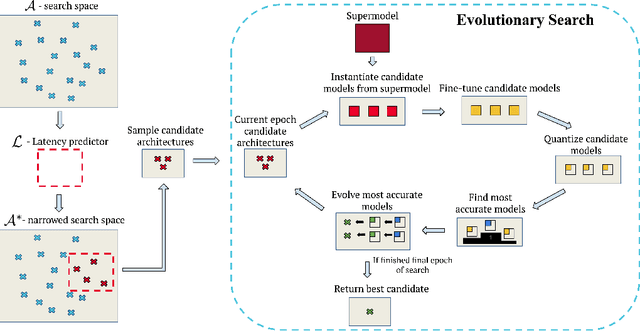

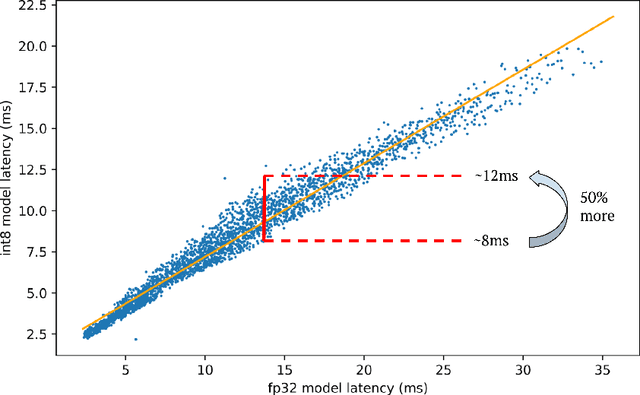
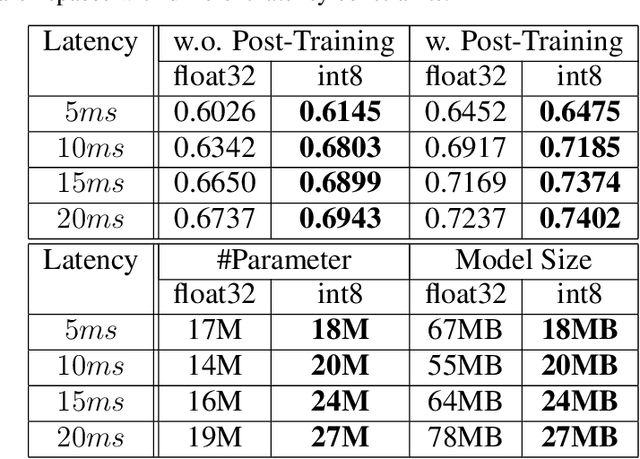
Neural architecture search (NAS) for transformers has been used to create state-of-the-art models that target certain latency constraints. In this work we present Bigger&Faster, a novel quantization-aware parameter sharing NAS that finds architectures for 8-bit integer (int8) quantized transformers. Our results show that our method is able to produce BERT models that outperform the current state-of-the-art technique, AutoTinyBERT, at all latency targets we tested, achieving up to a 2.68% accuracy gain. Additionally, although the models found by our technique have a larger number of parameters than their float32 counterparts, due to their parameters being int8, they have significantly smaller memory footprints.