 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking AI Forget You: Data Deletion in Machine Learning
Jul 11, 2019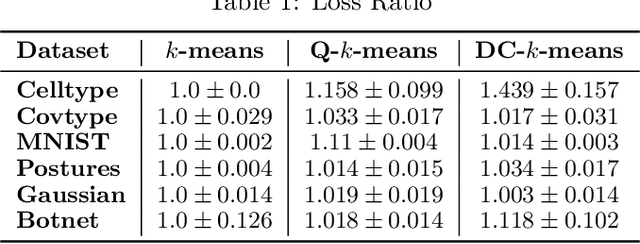
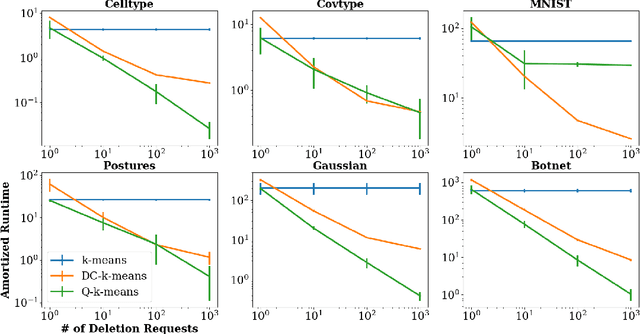
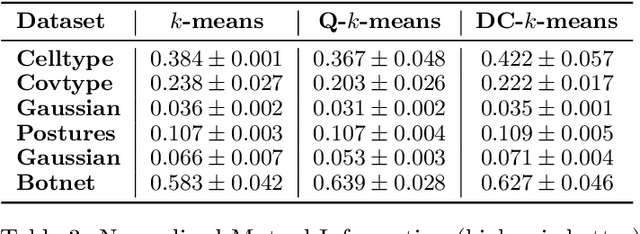
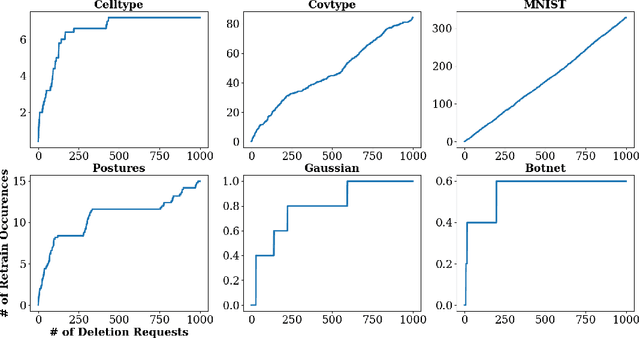
Intense recent discussions have focused on how to provide individuals with control over when their data can and cannot be used -- the EU's Right To Be Forgotten regulation is an example of this effort. In this paper we initiate a framework studying what to do when it is no longer permissible to deploy models derivative from specific user data. In particular, we formulate the problem of how to efficiently delete individual data points from trained machine learning models. For many standard ML models, the only way to completely remove an individual's data is to retrain the whole model from scratch on the remaining data, which is often not computationally practical. We investigate algorithmic principles that enable efficient data deletion in ML. For the specific setting of k-means clustering, we propose two provably deletion efficient algorithms which achieve an average of over 100X improvement in deletion efficiency across 6 datasets, while producing clusters of comparable statistical quality to a canonical k-means++ baseline.
A Surprising Density of Illusionable Natural Speech
Jun 05, 2019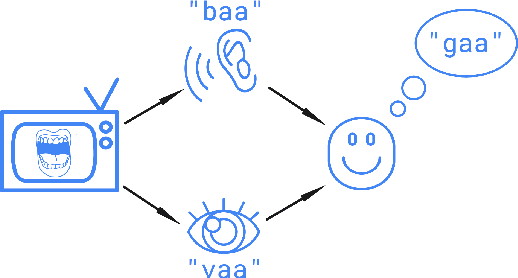

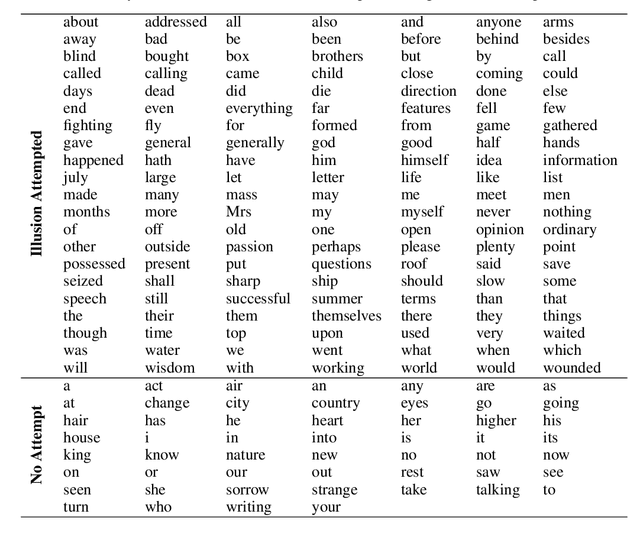
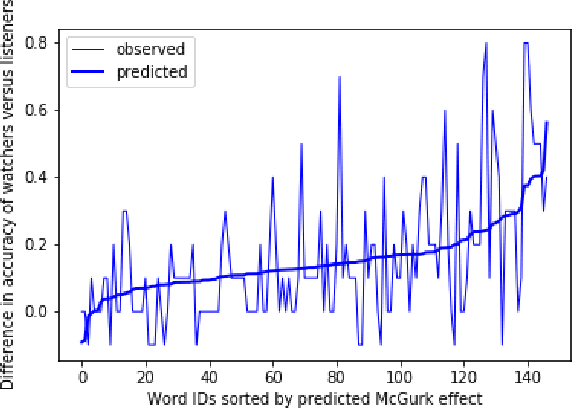
Recent work on adversarial examples has demonstrated that most natural inputs can be perturbed to fool even state-of-the-art machine learning systems. But does this happen for humans as well? In this work, we investigate: what fraction of natural instances of speech can be turned into "illusions" which either alter humans' perception or result in different people having significantly different perceptions? We first consider the McGurk effect, the phenomenon by which adding a carefully chosen video clip to the audio channel affects the viewer's perception of what is said (McGurk and MacDonald, 1976). We obtain empirical estimates that a significant fraction of both words and sentences occurring in natural speech have some susceptibility to this effect. We also learn models for predicting McGurk illusionability. Finally we demonstrate that the Yanny or Laurel auditory illusion (Pressnitzer et al., 2018) is not an isolated occurrence by generating several very different new instances. We believe that the surprising density of illusionable natural speech warrants further investigation, from the perspectives of both security and cognitive science. Supplementary videos are available at: https://www.youtube.com/playlist?list=PLaX7t1K-e_fF2iaenoKznCatm0RC37B_k.
Sample Amplification: Increasing Dataset Size even when Learning is Impossible
Apr 26, 2019
Given data drawn from an unknown distribution, $D$, to what extent is it possible to ``amplify'' this dataset and output an even larger set of samples that appear to have been drawn from $D$? We formalize this question as follows: an $(n,m)$ $\text{amplification procedure}$ takes as input $n$ independent draws from an unknown distribution $D$, and outputs a set of $m > n$ ``samples''. An amplification procedure is valid if no algorithm can distinguish the set of $m$ samples produced by the amplifier from a set of $m$ independent draws from $D$, with probability greater than $2/3$. Perhaps surprisingly, in many settings, a valid amplification procedure exists, even when the size of the input dataset, $n$, is significantly less than what would be necessary to learn $D$ to non-trivial accuracy. Specifically we consider two fundamental settings: the case where $D$ is an arbitrary discrete distribution supported on $\le k$ elements, and the case where $D$ is a $d$-dimensional Gaussian with unknown mean, and fixed covariance. In the first case, we show that an $\left(n, n + \Theta(\frac{n}{\sqrt{k}})\right)$ amplifier exists. In particular, given $n=O(\sqrt{k})$ samples from $D$, one can output a set of $m=n+1$ datapoints, whose total variation distance from the distribution of $m$ i.i.d. draws from $D$ is a small constant, despite the fact that one would need quadratically more data, $n=\Theta(k)$, to learn $D$ up to small constant total variation distance. In the Gaussian case, we show that an $\left(n,n+\Theta(\frac{n}{\sqrt{d}} )\right)$ amplifier exists, even though learning the distribution to small constant total variation distance requires $\Theta(d)$ samples. In both the discrete and Gaussian settings, we show that these results are tight, to constant factors. Beyond these results, we formalize a number of curious directions for future research along this vein.
Implicit regularization for deep neural networks driven by an Ornstein-Uhlenbeck like process
Apr 19, 2019
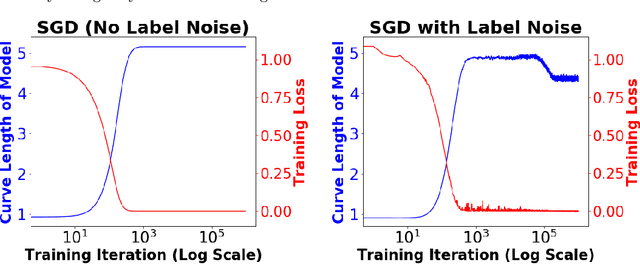
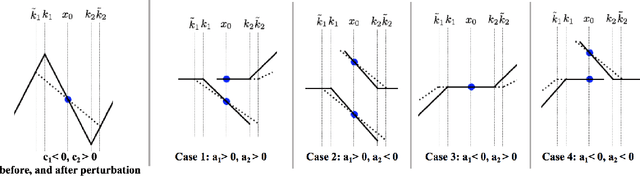
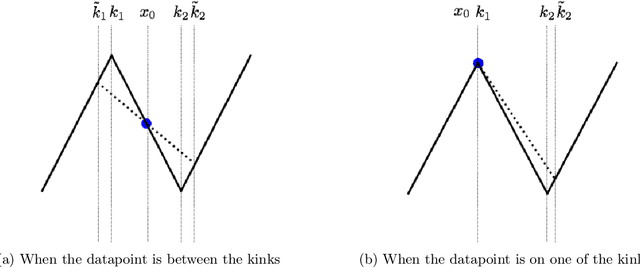
We consider deep networks, trained via stochastic gradient descent to minimize L2 loss, with the training labels perturbed by independent noise at each iteration. We characterize the behavior of the training dynamics near any parameter vector that achieves zero training error, in terms of an implicit regularization term corresponding to the sum over the data points, of the squared L2 norm of the gradient of the model with respect to the parameter vector, evaluated at each data point. We then leverage this general characterization, which holds for networks of any connectivity, width, depth, and choice of activation function, to show that for 2-layer ReLU networks of arbitrary width and L2 loss, when trained on one-dimensional labeled data $(x_1,y_1),\ldots,(x_n,y_n),$ the only stable solutions with zero training error correspond to functions that: 1) are linear over any set of three or more co-linear training points (i.e. the function has no extra "kinks"); and 2) change convexity the minimum number of times that is necessary to fit the training data. Additionally, for 2-layer networks of arbitrary width, with tanh or logistic activations, we show that when trained on a single $d$-dimensional point $(x,y)$ the only stable solutions correspond to networks where the activations of all hidden units at the datapoint, and all weights from the hidden units to the output, take at most two distinct values, or are zero. In this sense, we show that when trained on "simple" data, models corresponding to stable parameters are also "simple"; in short, despite fitting in an over-parameterized regime where the vast majority of expressible functions are complicated and badly behaved, stable parameters reached by training with noise express nearly the "simplest possible" hypothesis consistent with the data. These results shed light on the mystery of why deep networks generalize so well in practice.
Memory-Sample Tradeoffs for Linear Regression with Small Error
Apr 18, 2019We consider the problem of performing linear regression over a stream of $d$-dimensional examples, and show that any algorithm that uses a subquadratic amount of memory exhibits a slower rate of convergence than can be achieved without memory constraints. Specifically, consider a sequence of labeled examples $(a_1,b_1), (a_2,b_2)\ldots,$ with $a_i$ drawn independently from a $d$-dimensional isotropic Gaussian, and where $b_i = \langle a_i, x\rangle + \eta_i,$ for a fixed $x \in \mathbb{R}^d$ with $\|x\|_2 = 1$ and with independent noise $\eta_i$ drawn uniformly from the interval $[-2^{-d/5},2^{-d/5}].$ We show that any algorithm with at most $d^2/4$ bits of memory requires at least $\Omega(d \log \log \frac{1}{\epsilon})$ samples to approximate $x$ to $\ell_2$ error $\epsilon$ with probability of success at least $2/3$, for $\epsilon$ sufficiently small as a function of $d$. In contrast, for such $\epsilon$, $x$ can be recovered to error $\epsilon$ with probability $1-o(1)$ with memory $O\left(d^2 \log(1/\epsilon)\right)$ using $d$ examples. This represents the first nontrivial lower bounds for regression with super-linear memory, and may open the door for strong memory/sample tradeoffs for continuous optimization.
A Theory of Selective Prediction
Feb 27, 2019
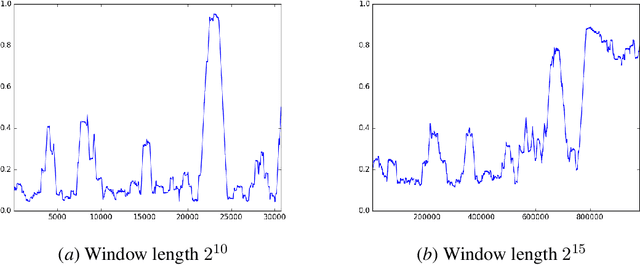
We consider a model of selective prediction, where the prediction algorithm is given a data sequence in an online fashion and asked to predict a pre-specified statistic of the upcoming data points. The algorithm is allowed to choose when to make the prediction as well as the length of the prediction window, possibly depending on the observations so far. We prove that, even without any distributional assumption on the input data stream, a large family of statistics can be estimated to non-trivial accuracy. To give one concrete example, suppose that we are given access to an arbitrary binary sequence $x_1, \ldots, x_n$ of length $n$. Our goal is to accurately predict the average observation, and we are allowed to choose the window over which the prediction is made: for some $t < n$ and $m \le n - t$, after seeing $t$ observations we predict the average of $x_{t+1}, \ldots, x_{t+m}$. This particular problem was first studied in [Dru13] and referred to as the "density prediction game". We show that the expected squared error of our prediction can be bounded by $O(\frac{1}{\log n})$ and prove a matching lower bound, which resolves an open question raised in [Dru13]. This result holds for any sequence (that is not adaptive to when the prediction is made, or the predicted value), and the expectation of the error is with respect to the randomness of the prediction algorithm. Our results apply to more general statistics of a sequence of observations, and we highlight several open directions for future work.
Maximum Likelihood Estimation for Learning Populations of Parameters
Feb 12, 2019
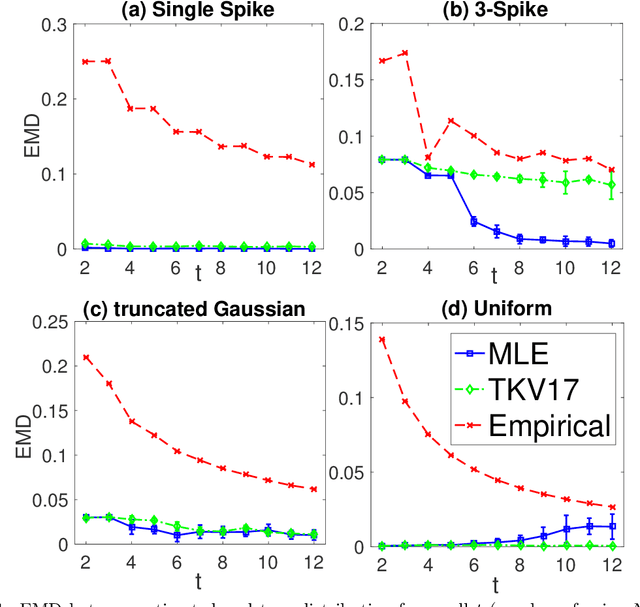
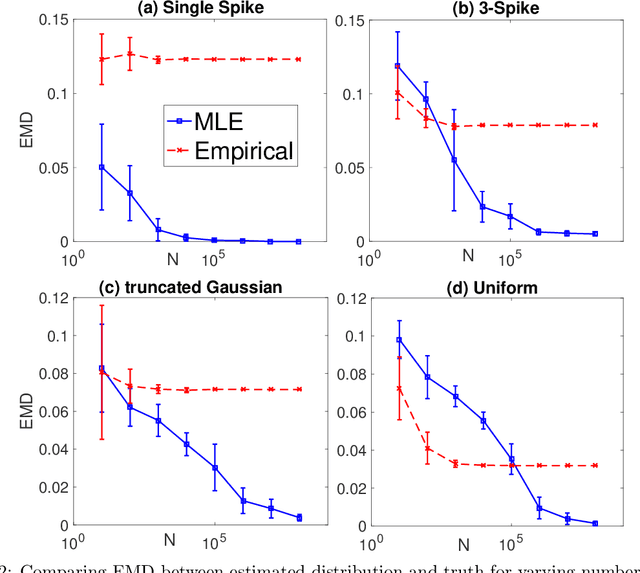
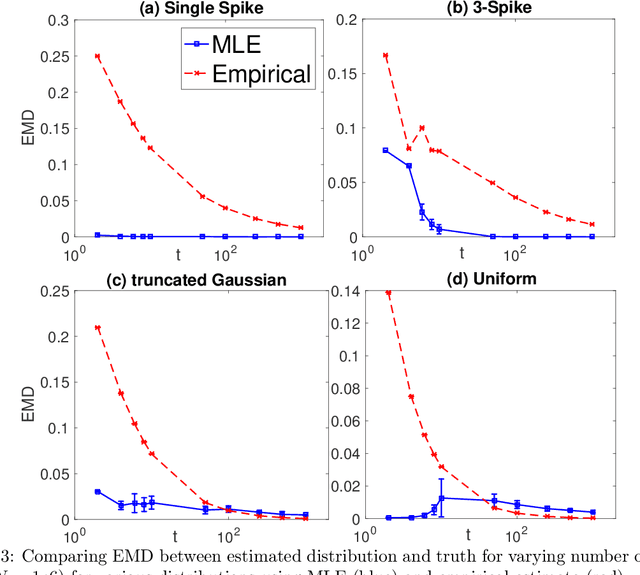
Consider a setting with $N$ independent individuals, each with an unknown parameter, $p_i \in [0, 1]$ drawn from some unknown distribution $P^\star$. After observing the outcomes of $t$ independent Bernoulli trials, i.e., $X_i \sim \text{Binomial}(t, p_i)$ per individual, our objective is to accurately estimate $P^\star$. This problem arises in numerous domains, including the social sciences, psychology, health-care, and biology, where the size of the population under study is usually large while the number of observations per individual is often limited. Our main result shows that, in the regime where $t \ll N$, the maximum likelihood estimator (MLE) is both statistically minimax optimal and efficiently computable. Precisely, for sufficiently large $N$, the MLE achieves the information theoretic optimal error bound of $\mathcal{O}(\frac{1}{t})$ for $t < c\log{N}$, with regards to the earth mover's distance (between the estimated and true distributions). More generally, in an exponentially large interval of $t$ beyond $c \log{N}$, the MLE achieves the minimax error bound of $\mathcal{O}(\frac{1}{\sqrt{t\log N}})$. In contrast, regardless of how large $N$ is, the naive "plug-in" estimator for this problem only achieves the sub-optimal error of $\Theta(\frac{1}{\sqrt{t}})$.
Equivariant Transformer Networks
Jan 25, 2019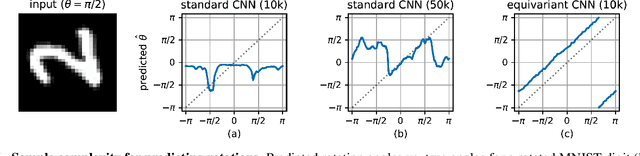
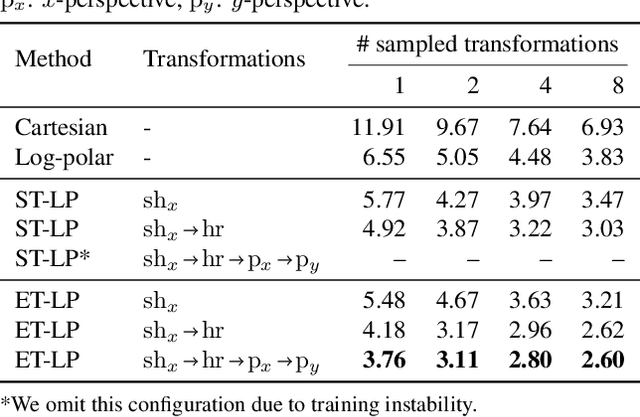
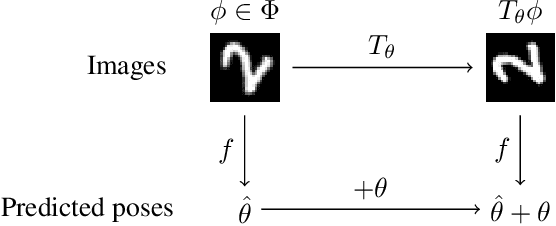
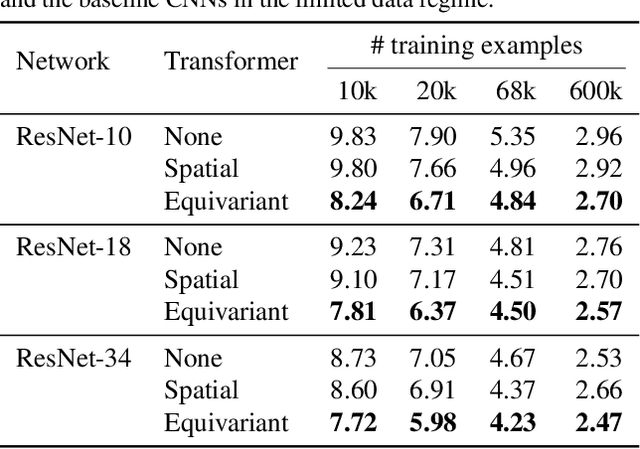
How can prior knowledge on the transformation invariances of a domain be incorporated into the architecture of a neural network? We propose Equivariant Transformers (ETs), a family of differentiable image-to-image mappings that improve the robustness of models towards pre-defined continuous transformation groups. Through the use of specially-derived canonical coordinate systems, ETs incorporate functions that are equivariant by construction with respect to these transformations. We show empirically that ETs can be flexibly composed to improve model robustness towards more complicated transformation groups in several parameters. On a real-world image classification task, ETs improve the sample efficiency of ResNet classifiers, achieving relative improvements in error rate of up to 15% in the limited data regime while increasing model parameter count by less than 1%.
A Spectral View of Adversarially Robust Features
Nov 15, 2018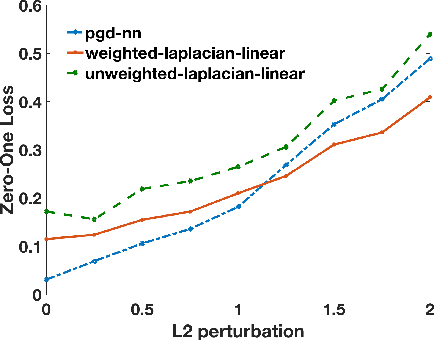
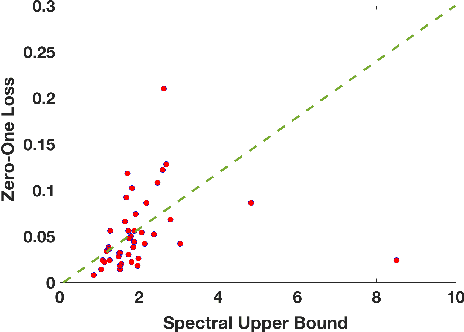
Given the apparent difficulty of learning models that are robust to adversarial perturbations, we propose tackling the simpler problem of developing adversarially robust features. Specifically, given a dataset and metric of interest, the goal is to return a function (or multiple functions) that 1) is robust to adversarial perturbations, and 2) has significant variation across the datapoints. We establish strong connections between adversarially robust features and a natural spectral property of the geometry of the dataset and metric of interest. This connection can be leveraged to provide both robust features, and a lower bound on the robustness of any function that has significant variance across the dataset. Finally, we provide empirical evidence that the adversarially robust features given by this spectral approach can be fruitfully leveraged to learn a robust (and accurate) model.
Prediction with a Short Memory
Jun 28, 2018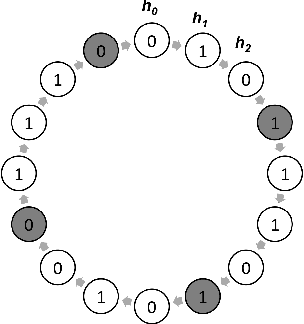
We consider the problem of predicting the next observation given a sequence of past observations, and consider the extent to which accurate prediction requires complex algorithms that explicitly leverage long-range dependencies. Perhaps surprisingly, our positive results show that for a broad class of sequences, there is an algorithm that predicts well on average, and bases its predictions only on the most recent few observation together with a set of simple summary statistics of the past observations. Specifically, we show that for any distribution over observations, if the mutual information between past observations and future observations is upper bounded by $I$, then a simple Markov model over the most recent $I/\epsilon$ observations obtains expected KL error $\epsilon$---and hence $\ell_1$ error $\sqrt{\epsilon}$---with respect to the optimal predictor that has access to the entire past and knows the data generating distribution. For a Hidden Markov Model with $n$ hidden states, $I$ is bounded by $\log n$, a quantity that does not depend on the mixing time, and we show that the trivial prediction algorithm based on the empirical frequencies of length $O(\log n/\epsilon)$ windows of observations achieves this error, provided the length of the sequence is $d^{\Omega(\log n/\epsilon)}$, where $d$ is the size of the observation alphabet. We also establish that this result cannot be improved upon, even for the class of HMMs, in the following two senses: First, for HMMs with $n$ hidden states, a window length of $\log n/\epsilon$ is information-theoretically necessary to achieve expected $\ell_1$ error $\sqrt{\epsilon}$. Second, the $d^{\Theta(\log n/\epsilon)}$ samples required to estimate the Markov model for an observation alphabet of size $d$ is necessary for any computationally tractable learning algorithm, assuming the hardness of strongly refuting a certain class of CSPs.