 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOAA: Flattened Outer Arithmetic Attention For Multimodal Tumor Classification
Mar 10, 2024



Fusion of multimodal healthcare data holds great promise to provide a holistic view of a patient's health, taking advantage of the complementarity of different modalities while leveraging their correlation. This paper proposes a simple and effective approach, inspired by attention, to fuse discriminative features from different modalities. We propose a novel attention mechanism, called Flattened Outer Arithmetic Attention (FOAA), which relies on outer arithmetic operators (addition, subtraction, product, and division) to compute attention scores from keys, queries and values derived from flattened embeddings of each modality. We demonstrate how FOAA can be implemented for self-attention and cross-attention, providing a reusable component in neural network architectures. We evaluate FOAA on two datasets for multimodal tumor classification and achieve state-of-the-art results, and we demonstrate that features enriched by FOAA are superior to those derived from other fusion approaches. The code is publicly available at \href{https://github.com/omniaalwazzan/FOAA}{https://github.com/omniaalwazzan/FOAA}
Crop and Couple: cardiac image segmentation using interlinked specialist networks
Feb 14, 2024Diagnosis of cardiovascular disease using automated methods often relies on the critical task of cardiac image segmentation. We propose a novel strategy that performs segmentation using specialist networks that focus on a single anatomy (left ventricle, right ventricle, or myocardium). Given an input long-axis cardiac MR image, our method performs a ternary segmentation in the first stage to identify these anatomical regions, followed by cropping the original image to focus subsequent processing on the anatomical regions. The specialist networks are coupled through an attention mechanism that performs cross-attention to interlink features from different anatomies, serving as a soft relative shape prior. Central to our approach is an additive attention block (E-2A block), which is used throughout our architecture thanks to its efficiency.
Multi-Stain Self-Attention Graph Multiple Instance Learning Pipeline for Histopathology Whole Slide Images
Sep 19, 2023



Whole Slide Images (WSIs) present a challenging computer vision task due to their gigapixel size and presence of numerous artefacts. Yet they are a valuable resource for patient diagnosis and stratification, often representing the gold standard for diagnostic tasks. Real-world clinical datasets tend to come as sets of heterogeneous WSIs with labels present at the patient-level, with poor to no annotations. Weakly supervised attention-based multiple instance learning approaches have been developed in recent years to address these challenges, but can fail to resolve both long and short-range dependencies. Here we propose an end-to-end multi-stain self-attention graph (MUSTANG) multiple instance learning pipeline, which is designed to solve a weakly-supervised gigapixel multi-image classification task, where the label is assigned at the patient-level, but no slide-level labels or region annotations are available. The pipeline uses a self-attention based approach by restricting the operations to a highly sparse k-Nearest Neighbour Graph of embedded WSI patches based on the Euclidean distance. We show this approach achieves a state-of-the-art F1-score/AUC of 0.89/0.92, outperforming the widely used CLAM model. Our approach is highly modular and can easily be modified to suit different clinical datasets, as it only requires a patient-level label without annotations and accepts WSI sets of different sizes, as the graphs can be of varying sizes and structures. The source code can be found at https://github.com/AmayaGS/MUSTANG.
Automated segmentation of rheumatoid arthritis immunohistochemistry stained synovial tissue
Sep 13, 2023Rheumatoid Arthritis (RA) is a chronic, autoimmune disease which primarily affects the joint's synovial tissue. It is a highly heterogeneous disease, with wide cellular and molecular variability observed in synovial tissues. Over the last two decades, the methods available for their study have advanced considerably. In particular, Immunohistochemistry stains are well suited to highlighting the functional organisation of samples. Yet, analysis of IHC-stained synovial tissue samples is still overwhelmingly done manually and semi-quantitatively by expert pathologists. This is because in addition to the fragmented nature of IHC stained synovial tissue, there exist wide variations in intensity and colour, strong clinical centre batch effect, as well as the presence of many undesirable artefacts present in gigapixel Whole Slide Images (WSIs), such as water droplets, pen annotation, folded tissue, blurriness, etc. There is therefore a strong need for a robust, repeatable automated tissue segmentation algorithm which can cope with this variability and provide support to imaging pipelines. We train a UNET on a hand-curated, heterogeneous real-world multi-centre clinical dataset R4RA, which contains multiple types of IHC staining. The model obtains a DICE score of 0.865 and successfully segments different types of IHC staining, as well as dealing with variance in colours, intensity and common WSIs artefacts from the different clinical centres. It can be used as the first step in an automated image analysis pipeline for synovial tissue samples stained with IHC, increasing speed, reproducibility and robustness.
Graph Neural Networks in Vision-Language Image Understanding: A Survey
Mar 07, 20232D image understanding is a complex problem within Computer Vision, but it holds the key to providing human level scene comprehension. It goes further than identifying the objects in an image, and instead it attempts to understand the scene. Solutions to this problem form the underpinning of a range of tasks, including image captioning, Visual Question Answering (VQA), and image retrieval. Graphs provide a natural way to represent the relational arrangement between objects in an image, and thus in recent years Graph Neural Networks (GNNs) have become a standard component of many 2D image understanding pipelines, becoming a core architectural component especially in the VQA group of tasks. In this survey, we review this rapidly evolving field and we provide a taxonomy of graph types used in 2D image understanding approaches, a comprehensive list of the GNN models used in this domain, and a roadmap of future potential developments. To the best of our knowledge, this is the first comprehensive survey that covers image captioning, visual question answering, and image retrieval techniques that focus on using GNNs as the main part of their architecture.
Vector Quantized Semantic Communication System
Sep 23, 2022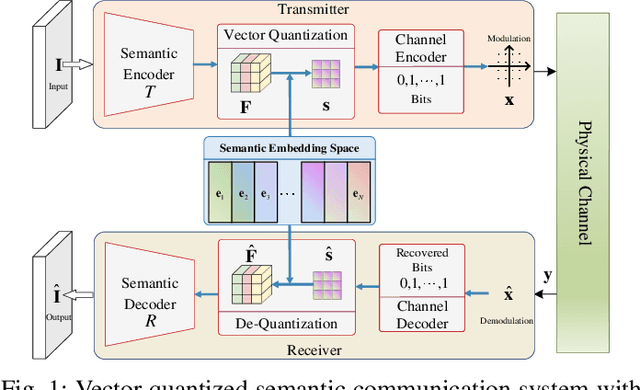
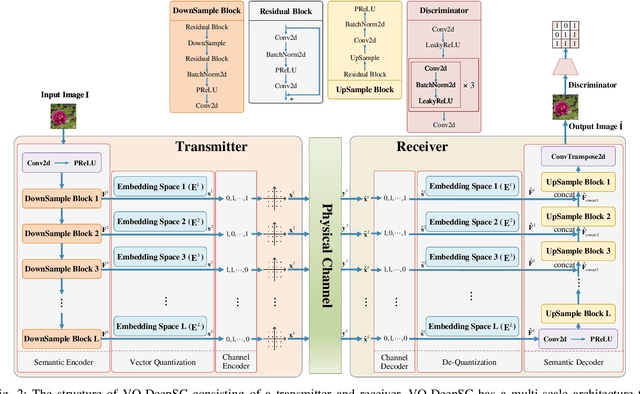
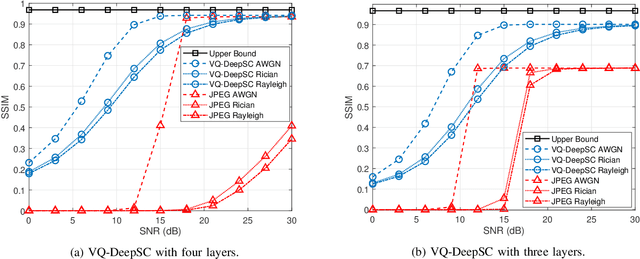
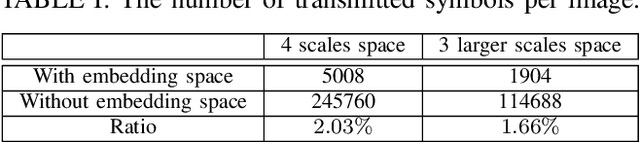
Although analog semantic communication systems have received considerable attention in the literature, there is less work on digital semantic communication systems. In this paper, we develop a deep learning (DL)-enabled vector quantized (VQ) semantic communication system for image transmission, named VQ-DeepSC. Specifically, we propose a convolutional neural network (CNN)-based transceiver to extract multi-scale semantic features of images and introduce multi-scale semantic embedding spaces to perform semantic feature quantization, rendering the data compatible with digital communication systems. Furthermore, we employ adversarial training to improve the quality of received images by introducing a PatchGAN discriminator. Experimental results demonstrate that the proposed VQ-DeepSC outperforms traditional image transmission methods in terms of SSIM.
FlexHDR: Modelling Alignment and Exposure Uncertainties for Flexible HDR Imaging
Jan 07, 2022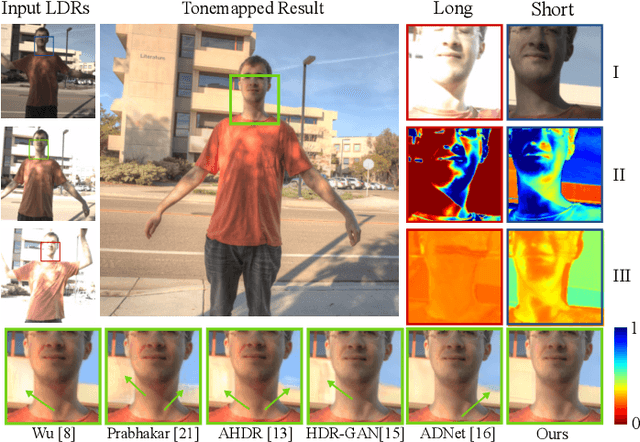


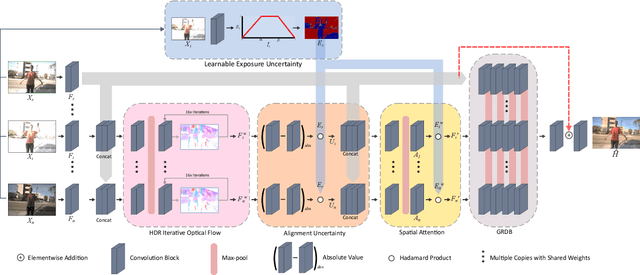
High dynamic range (HDR) imaging is of fundamental importance in modern digital photography pipelines and used to produce a high-quality photograph with well exposed regions despite varying illumination across the image. This is typically achieved by merging multiple low dynamic range (LDR) images taken at different exposures. However, over-exposed regions and misalignment errors due to poorly compensated motion result in artefacts such as ghosting. In this paper, we present a new HDR imaging technique that specifically models alignment and exposure uncertainties to produce high quality HDR results. We introduce a strategy that learns to jointly align and assess the alignment and exposure reliability using an HDR-aware, uncertainty-driven attention map that robustly merges the frames into a single high quality HDR image. Further, we introduce a progressive, multi-stage image fusion approach that can flexibly merge any number of LDR images in a permutation-invariant manner. Experimental results show our method can produce better quality HDR images with up to 0.8dB PSNR improvement to the state-of-the-art, and subjective improvements in terms of better detail, colours, and fewer artefacts.
Learning to Sample the Most Useful Training Patches from Images
Nov 24, 2020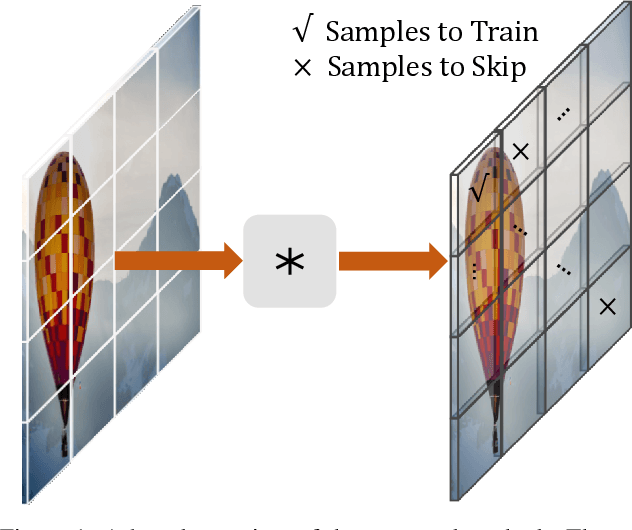


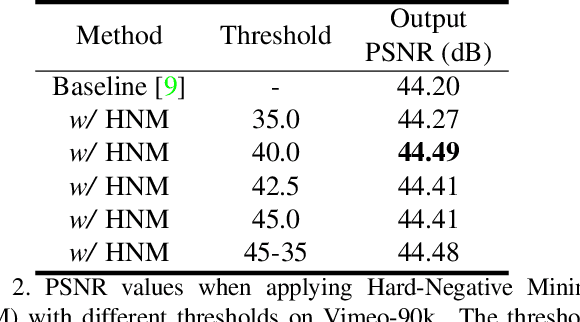
Some image restoration tasks like demosaicing require difficult training samples to learn effective models. Existing methods attempt to address this data training problem by manually collecting a new training dataset that contains adequate hard samples, however, there are still hard and simple areas even within one single image. In this paper, we present a data-driven approach called PatchNet that learns to select the most useful patches from an image to construct a new training set instead of manual or random selection. We show that our simple idea automatically selects informative samples out from a large-scale dataset, leading to a surprising 2.35dB generalisation gain in terms of PSNR. In addition to its remarkable effectiveness, PatchNet is also resource-friendly as it is applied only during training and therefore does not require any additional computational cost during inference.
Self-Adaptively Learning to Demoire from Focused and Defocused Image Pairs
Nov 05, 2020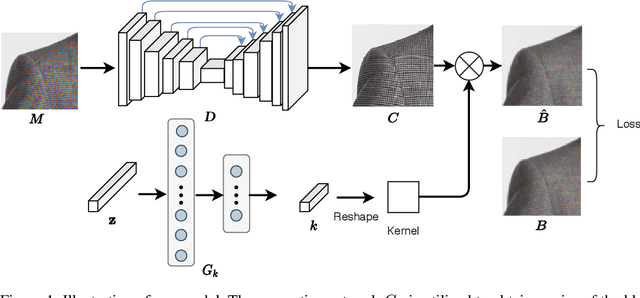



Moire artifacts are common in digital photography, resulting from the interference between high-frequency scene content and the color filter array of the camera. Existing deep learning-based demoireing methods trained on large scale datasets are limited in handling various complex moire patterns, and mainly focus on demoireing of photos taken of digital displays. Moreover, obtaining moire-free ground-truth in natural scenes is difficult but needed for training. In this paper, we propose a self-adaptive learning method for demoireing a high-frequency image, with the help of an additional defocused moire-free blur image. Given an image degraded with moire artifacts and a moire-free blur image, our network predicts a moire-free clean image and a blur kernel with a self-adaptive strategy that does not require an explicit training stage, instead performing test-time adaptation. Our model has two sub-networks and works iteratively. During each iteration, one sub-network takes the moire image as input, removing moire patterns and restoring image details, and the other sub-network estimates the blur kernel from the blur image. The two sub-networks are jointly optimized. Extensive experiments demonstrate that our method outperforms state-of-the-art methods and can produce high-quality demoired results. It can generalize well to the task of removing moire artifacts caused by display screens. In addition, we build a new moire dataset, including images with screen and texture moire artifacts. As far as we know, this is the first dataset with real texture moire patterns.
Diagnosing and Preventing Instabilities in Recurrent Video Processing
Oct 17, 2020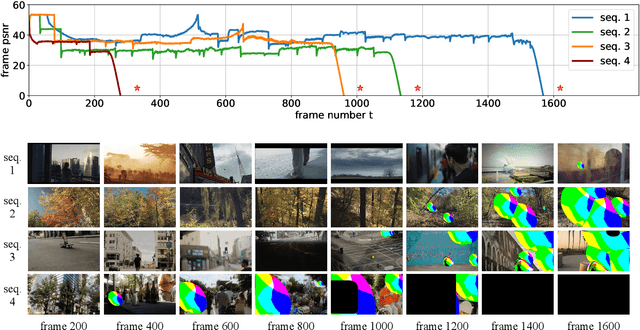
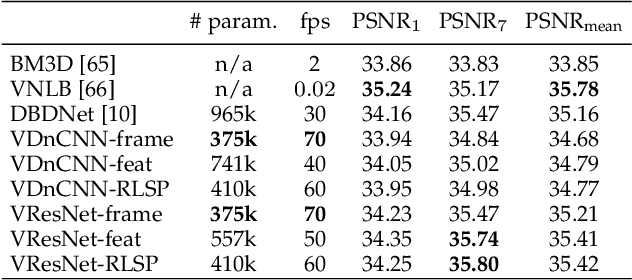
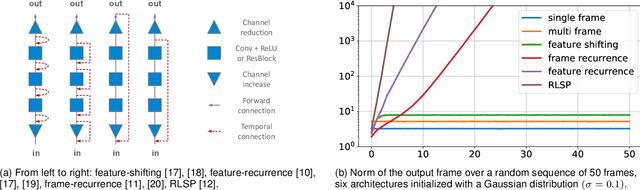
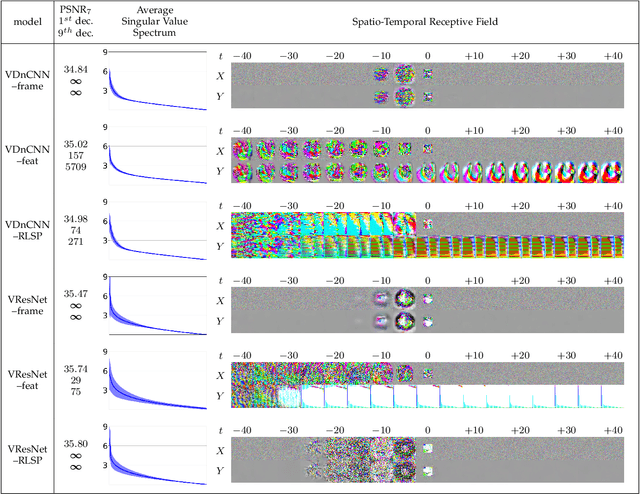
Recurrent models are becoming a popular choice for video enhancement tasks such as video denoising. In this work, we focus on their stability as dynamical systems and show that they tend to fail catastrophically at inference time on long video sequences. To address this issue, we (1) introduce a diagnostic tool which produces adversarial input sequences optimized to trigger instabilities and that can be interpreted as visualizations of spatio-temporal receptive fields, and (2) propose two approaches to enforce the stability of a model: constraining the spectral norm or constraining the stable rank of its convolutional layers. We then introduce Stable Rank Normalization of the Layers (SRNL), a new algorithm that enforces these constraints, and verify experimentally that it successfully results in stable recurrent video processing.