 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Structured Inference Neural Networks with Label Relations
Oct 24, 2016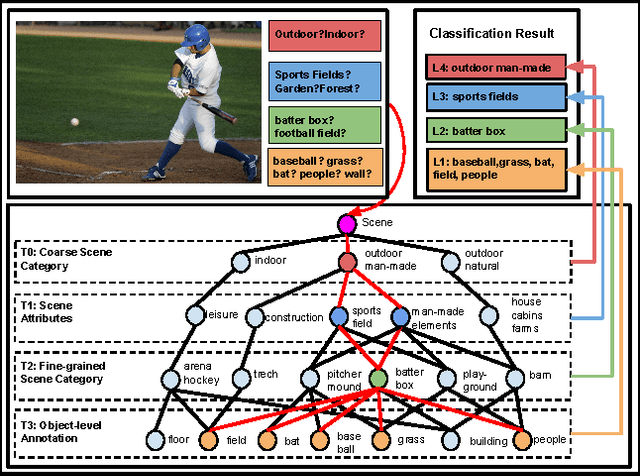
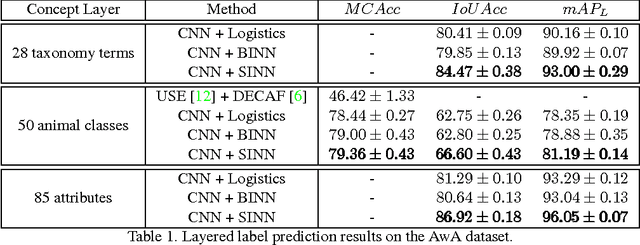
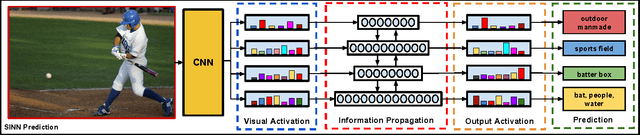
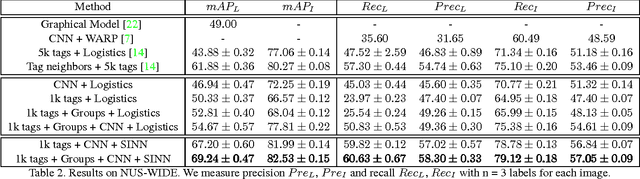
Images of scenes have various objects as well as abundant attributes, and diverse levels of visual categorization are possible. A natural image could be assigned with fine-grained labels that describe major components, coarse-grained labels that depict high level abstraction or a set of labels that reveal attributes. Such categorization at different concept layers can be modeled with label graphs encoding label information. In this paper, we exploit this rich information with a state-of-art deep learning framework, and propose a generic structured model that leverages diverse label relations to improve image classification performance. Our approach employs a novel stacked label prediction neural network, capturing both inter-level and intra-level label semantics. We evaluate our method on benchmark image datasets, and empirical results illustrate the efficacy of our model.
Hierarchical Deep Temporal Models for Group Activity Recognition
Jul 09, 2016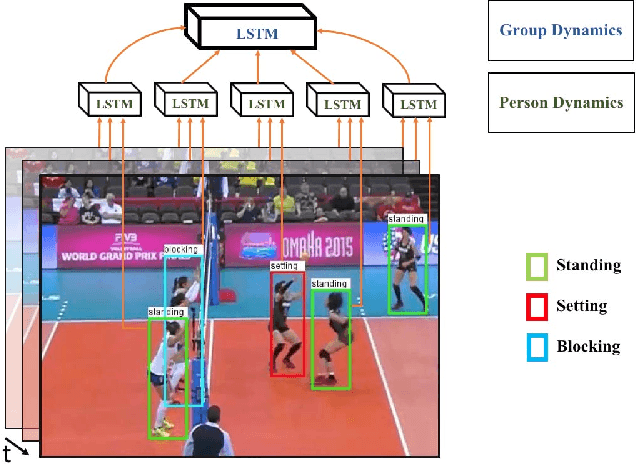

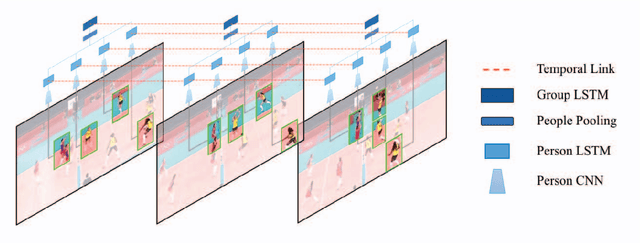
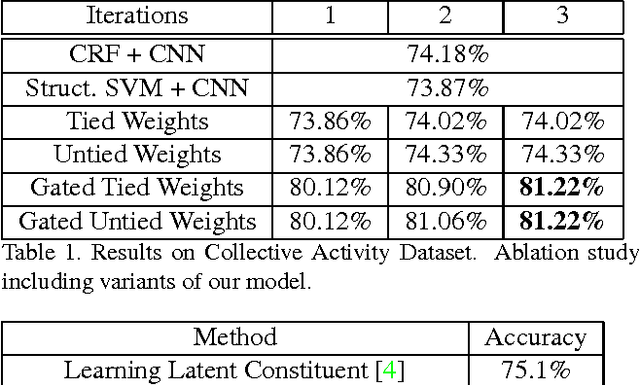
In this paper we present an approach for classifying the activity performed by a group of people in a video sequence. This problem of group activity recognition can be addressed by examining individual person actions and their relations. Temporal dynamics exist both at the level of individual person actions as well as at the level of group activity. Given a video sequence as input, methods can be developed to capture these dynamics at both person-level and group-level detail. We build a deep model to capture these dynamics based on LSTM (long short-term memory) models. In order to model both person-level and group-level dynamics, we present a 2-stage deep temporal model for the group activity recognition problem. In our approach, one LSTM model is designed to represent action dynamics of individual people in a video sequence and another LSTM model is designed to aggregate person-level information for group activity recognition. We collected a new dataset consisting of volleyball videos labeled with individual and group activities in order to evaluate our method. Experimental results on this new Volleyball Dataset and the standard benchmark Collective Activity Dataset demonstrate the efficacy of the proposed models.
Deep Learning of Appearance Models for Online Object Tracking
Jul 09, 2016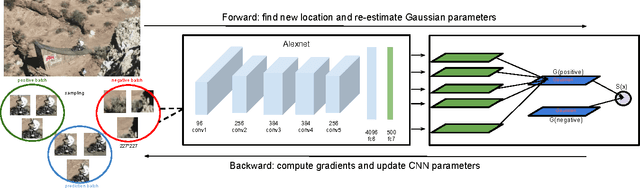
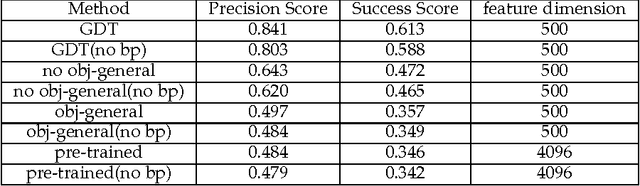

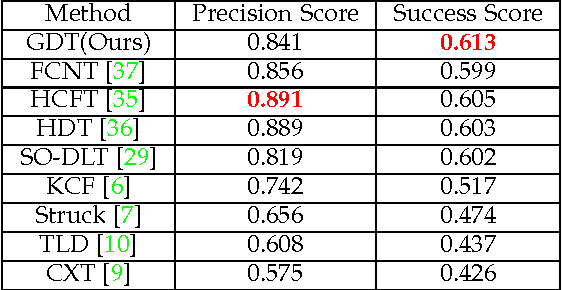
This paper introduces a novel deep learning based approach for vision based single target tracking. We address this problem by proposing a network architecture which takes the input video frames and directly computes the tracking score for any candidate target location by estimating the probability distributions of the positive and negative examples. This is achieved by combining a deep convolutional neural network with a Bayesian loss layer in a unified framework. In order to deal with the limited number of positive training examples, the network is pre-trained offline for a generic image feature representation and then is fine-tuned in multiple steps. An online fine-tuning step is carried out at every frame to learn the appearance of the target. We adopt a two-stage iterative algorithm to adaptively update the network parameters and maintain a probability density for target/non-target regions. The tracker has been tested on the standard tracking benchmark and the results indicate that the proposed solution achieves state-of-the-art tracking results.
Structure Inference Machines: Recurrent Neural Networks for Analyzing Relations in Group Activity Recognition
Apr 12, 2016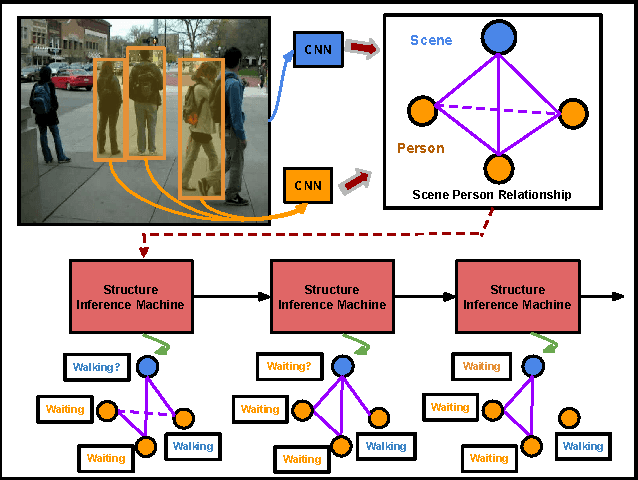
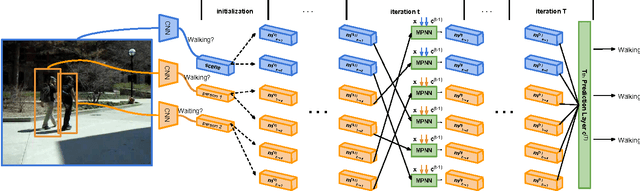
Rich semantic relations are important in a variety of visual recognition problems. As a concrete example, group activity recognition involves the interactions and relative spatial relations of a set of people in a scene. State of the art recognition methods center on deep learning approaches for training highly effective, complex classifiers for interpreting images. However, bridging the relatively low-level concepts output by these methods to interpret higher-level compositional scenes remains a challenge. Graphical models are a standard tool for this task. In this paper, we propose a method to integrate graphical models and deep neural networks into a joint framework. Instead of using a traditional inference method, we use a sequential inference modeled by a recurrent neural network. Beyond this, the appropriate structure for inference can be learned by imposing gates on edges between nodes. Empirical results on group activity recognition demonstrate the potential of this model to handle highly structured learning tasks.
A Hierarchical Deep Temporal Model for Group Activity Recognition
Apr 05, 2016In group activity recognition, the temporal dynamics of the whole activity can be inferred based on the dynamics of the individual people representing the activity. We build a deep model to capture these dynamics based on LSTM (long-short term memory) models. To make use of these ob- servations, we present a 2-stage deep temporal model for the group activity recognition problem. In our model, a LSTM model is designed to represent action dynamics of in- dividual people in a sequence and another LSTM model is designed to aggregate human-level information for whole activity understanding. We evaluate our model over two datasets: the collective activity dataset and a new volley- ball dataset. Experimental results demonstrate that our proposed model improves group activity recognition perfor- mance with compared to baseline methods.
Pose Embeddings: A Deep Architecture for Learning to Match Human Poses
Jul 01, 2015


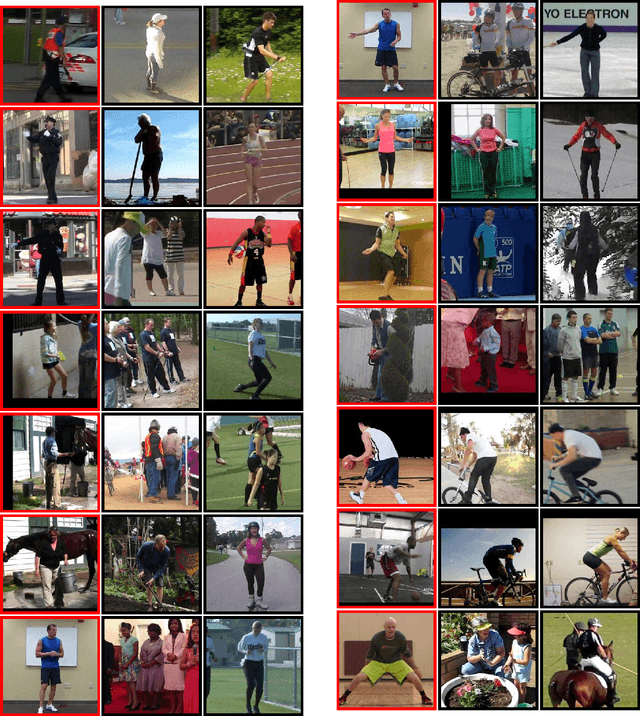
We present a method for learning an embedding that places images of humans in similar poses nearby. This embedding can be used as a direct method of comparing images based on human pose, avoiding potential challenges of estimating body joint positions. Pose embedding learning is formulated under a triplet-based distance criterion. A deep architecture is used to allow learning of a representation capable of making distinctions between different poses. Experiments on human pose matching and retrieval from video data demonstrate the potential of the method.
Deep Structured Models For Group Activity Recognition
Jun 12, 2015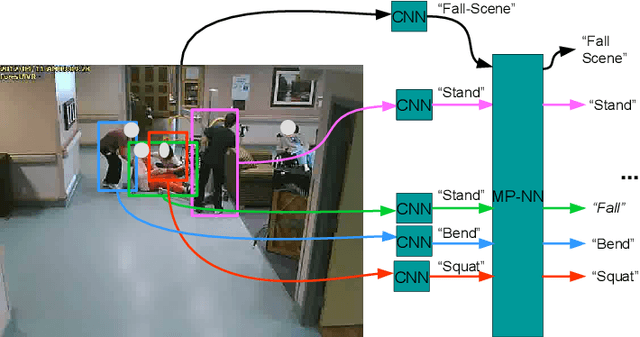

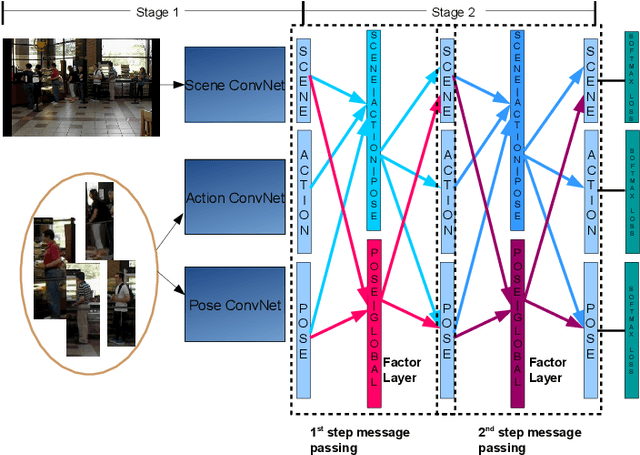

This paper presents a deep neural-network-based hierarchical graphical model for individual and group activity recognition in surveillance scenes. Deep networks are used to recognize the actions of individual people in a scene. Next, a neural-network-based hierarchical graphical model refines the predicted labels for each class by considering dependencies between the classes. This refinement step mimics a message-passing step similar to inference in a probabilistic graphical model. We show that this approach can be effective in group activity recognition, with the deep graphical model improving recognition rates over baseline methods.
Learning Temporal Embeddings for Complex Video Analysis
May 02, 2015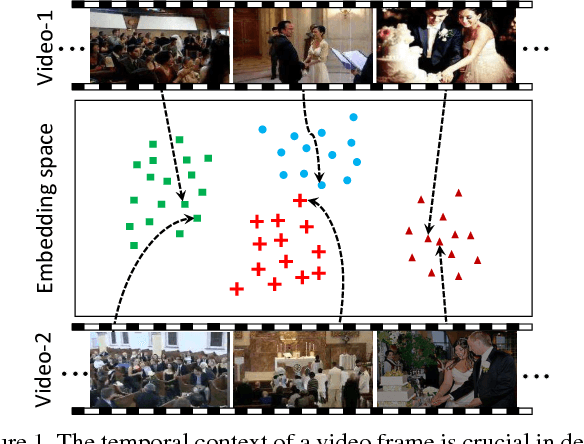
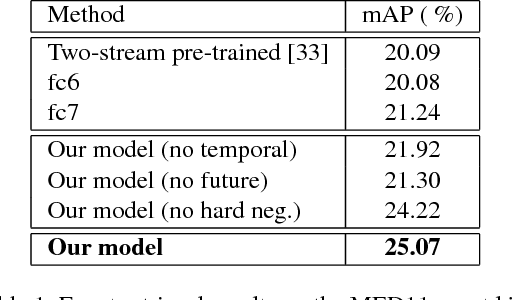
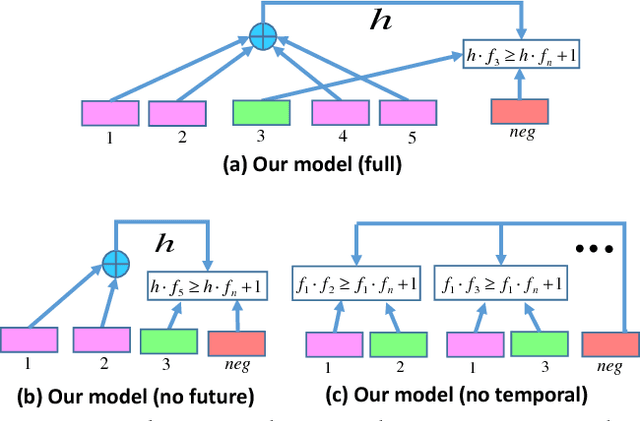

In this paper, we propose to learn temporal embeddings of video frames for complex video analysis. Large quantities of unlabeled video data can be easily obtained from the Internet. These videos possess the implicit weak label that they are sequences of temporally and semantically coherent images. We leverage this information to learn temporal embeddings for video frames by associating frames with the temporal context that they appear in. To do this, we propose a scheme for incorporating temporal context based on past and future frames in videos, and compare this to other contextual representations. In addition, we show how data augmentation using multi-resolution samples and hard negatives helps to significantly improve the quality of the learned embeddings. We evaluate various design decisions for learning temporal embeddings, and show that our embeddings can improve performance for multiple video tasks such as retrieval, classification, and temporal order recovery in unconstrained Internet video.
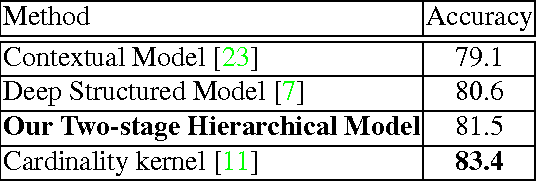
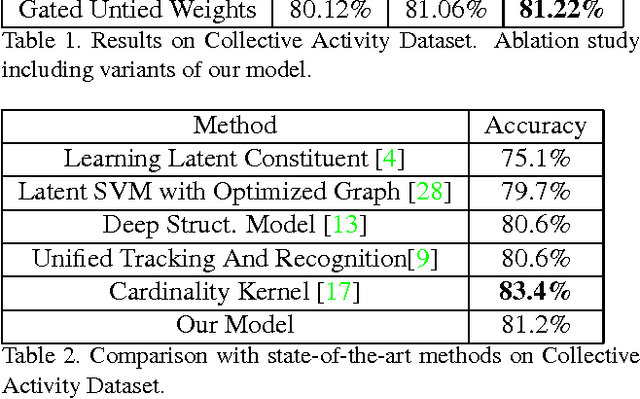
Visual Recognition by Counting Instances: A Multi-Instance Cardinality Potential Kernel
Apr 09, 2015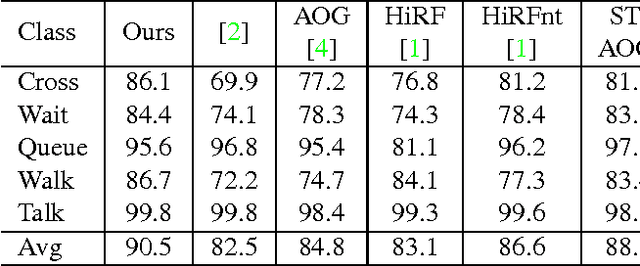
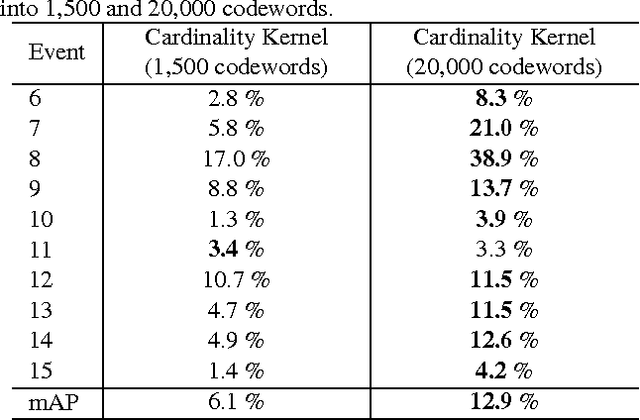
Many visual recognition problems can be approached by counting instances. To determine whether an event is present in a long internet video, one could count how many frames seem to contain the activity. Classifying the activity of a group of people can be done by counting the actions of individual people. Encoding these cardinality relationships can reduce sensitivity to clutter, in the form of irrelevant frames or individuals not involved in a group activity. Learned parameters can encode how many instances tend to occur in a class of interest. To this end, this paper develops a powerful and flexible framework to infer any cardinality relation between latent labels in a multi-instance model. Hard or soft cardinality relations can be encoded to tackle diverse levels of ambiguity. Experiments on tasks such as human activity recognition, video event detection, and video summarization demonstrate the effectiveness of using cardinality relations for improving recognition results.
Discovering Human Interactions in Videos with Limited Data Labeling
Feb 12, 2015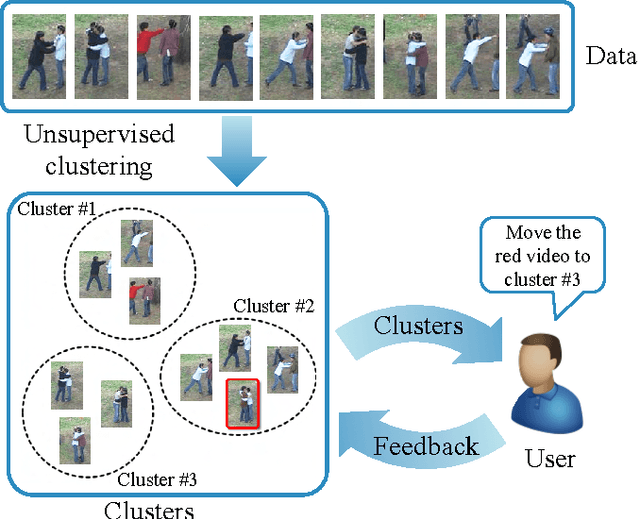
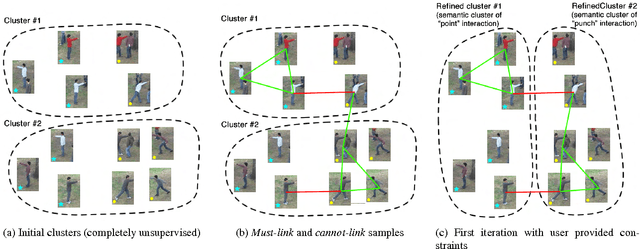
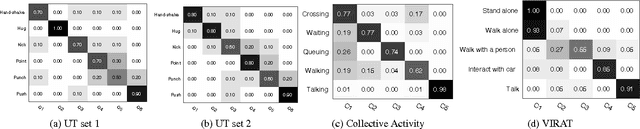
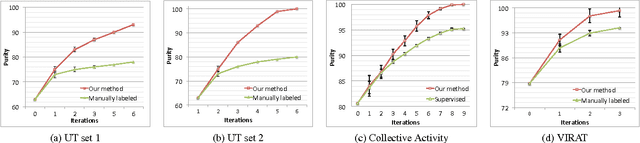
We present a novel approach for discovering human interactions in videos. Activity understanding techniques usually require a large number of labeled examples, which are not available in many practical cases. Here, we focus on recovering semantically meaningful clusters of human-human and human-object interaction in an unsupervised fashion. A new iterative solution is introduced based on Maximum Margin Clustering (MMC), which also accepts user feedback to refine clusters. This is achieved by formulating the whole process as a unified constrained latent max-margin clustering problem. Extensive experiments have been carried out over three challenging datasets, Collective Activity, VIRAT, and UT-interaction. Empirical results demonstrate that the proposed algorithm can efficiently discover perfect semantic clusters of human interactions with only a small amount of labeling effort.