 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThreatening Patch Attacks on Object Detection in Optical Remote Sensing Images
Feb 13, 2023Advanced Patch Attacks (PAs) on object detection in natural images have pointed out the great safety vulnerability in methods based on deep neural networks. However, little attention has been paid to this topic in Optical Remote Sensing Images (O-RSIs). To this end, we focus on this research, i.e., PAs on object detection in O-RSIs, and propose a more Threatening PA without the scarification of the visual quality, dubbed TPA. Specifically, to address the problem of inconsistency between local and global landscapes in existing patch selection schemes, we propose leveraging the First-Order Difference (FOD) of the objective function before and after masking to select the sub-patches to be attacked. Further, considering the problem of gradient inundation when applying existing coordinate-based loss to PAs directly, we design an IoU-based objective function specific for PAs, dubbed Bounding box Drifting Loss (BDL), which pushes the detected bounding boxes far from the initial ones until there are no intersections between them. Finally, on two widely used benchmarks, i.e., DIOR and DOTA, comprehensive evaluations of our TPA with four typical detectors (Faster R-CNN, FCOS, RetinaNet, and YOLO-v4) witness its remarkable effectiveness. To the best of our knowledge, this is the first attempt to study the PAs on object detection in O-RSIs, and we hope this work can get our readers interested in studying this topic.
Fewer is More: Efficient Object Detection in Large Aerial Images
Dec 26, 2022Current mainstream object detection methods for large aerial images usually divide large images into patches and then exhaustively detect the objects of interest on all patches, no matter whether there exist objects or not. This paradigm, although effective, is inefficient because the detectors have to go through all patches, severely hindering the inference speed. This paper presents an Objectness Activation Network (OAN) to help detectors focus on fewer patches but achieve more efficient inference and more accurate results, enabling a simple and effective solution to object detection in large images. In brief, OAN is a light fully-convolutional network for judging whether each patch contains objects or not, which can be easily integrated into many object detectors and jointly trained with them end-to-end. We extensively evaluate our OAN with five advanced detectors. Using OAN, all five detectors acquire more than 30.0% speed-up on three large-scale aerial image datasets, meanwhile with consistent accuracy improvements. On extremely large Gaofen-2 images (29200$\times$27620 pixels), our OAN improves the detection speed by 70.5%. Moreover, we extend our OAN to driving-scene object detection and 4K video object detection, boosting the detection speed by 112.1% and 75.0%, respectively, without sacrificing the accuracy. Code is available at https://github.com/Ranchosky/OAN.
DyRRen: A Dynamic Retriever-Reranker-Generator Model for Numerical Reasoning over Tabular and Textual Data
Nov 23, 2022



Numerical reasoning over hybrid data containing tables and long texts has recently received research attention from the AI community. To generate an executable reasoning program consisting of math and table operations to answer a question, state-of-the-art methods use a retriever-generator pipeline. However, their retrieval results are static, while different generation steps may rely on different sentences. To attend to the retrieved information that is relevant to each generation step, in this paper, we propose DyRRen, an extended retriever-reranker-generator framework where each generation step is enhanced by a dynamic reranking of retrieved sentences. It outperforms existing baselines on the FinQA dataset.
Query-based Industrial Analytics over Knowledge Graphs with Ontology Reshaping
Sep 22, 2022Industrial analytics that includes among others equipment diagnosis and anomaly detection heavily relies on integration of heterogeneous production data. Knowledge Graphs (KGs) as the data format and ontologies as the unified data schemata are a prominent solution that offers high quality data integration and a convenient and standardised way to exchange data and to layer analytical applications over it. However, poor design of ontologies of high degree of mismatch between them and industrial data naturally lead to KGs of low quality that impede the adoption and scalability of industrial analytics. Indeed, such KGs substantially increase the training time of writing queries for users, consume high volume of storage for redundant information, and are hard to maintain and update. To address this problem we propose an ontology reshaping approach to transform ontologies into KG schemata that better reflect the underlying data and thus help to construct better KGs. In this poster we present a preliminary discussion of our on-going research, evaluate our approach with a rich set of SPARQL queries on real-world industry data at Bosch and discuss our findings.
Towards Ontology Reshaping for KG Generation with User-in-the-Loop: Applied to Bosch Welding
Sep 22, 2022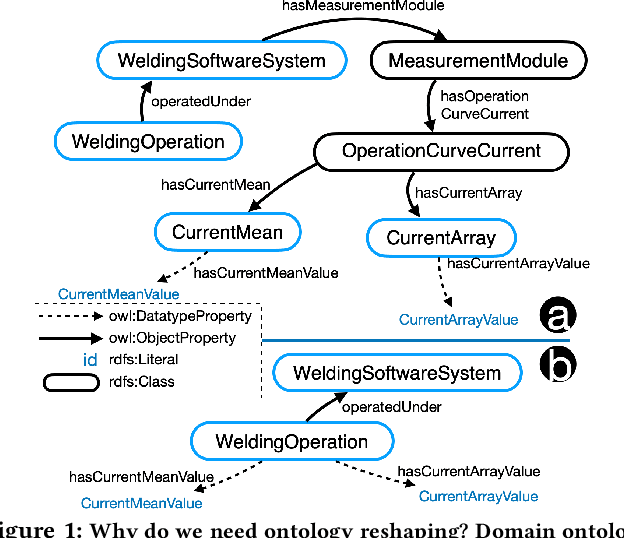
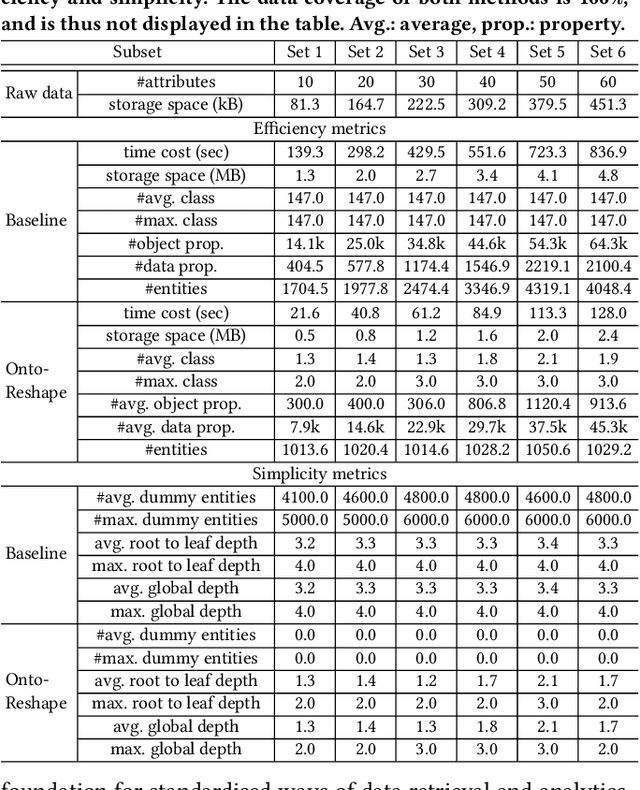
Knowledge graphs (KG) are used in a wide range of applications. The automation of KG generation is very desired due to the data volume and variety in industries. One important approach of KG generation is to map the raw data to a given KG schema, namely a domain ontology, and construct the entities and properties according to the ontology. However, the automatic generation of such ontology is demanding and existing solutions are often not satisfactory. An important challenge is a trade-off between two principles of ontology engineering: knowledge-orientation and data-orientation. The former one prescribes that an ontology should model the general knowledge of a domain, while the latter one emphasises on reflecting the data specificities to ensure good usability. We address this challenge by our method of ontology reshaping, which automates the process of converting a given domain ontology to a smaller ontology that serves as the KG schema. The domain ontology can be designed to be knowledge-oriented and the KG schema covers the data specificities. In addition, our approach allows the option of including user preferences in the loop. We demonstrate our on-going research on ontology reshaping and present an evaluation using real industrial data, with promising results.
Knowledge Base Question Answering: A Semantic Parsing Perspective
Sep 18, 2022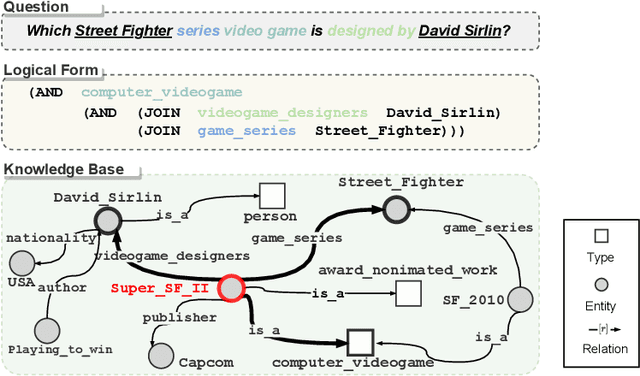
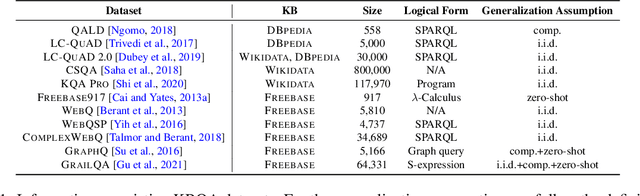
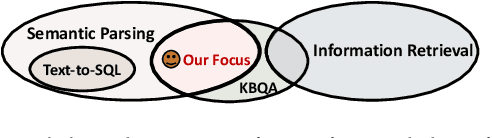

Recent advances in deep learning have greatly propelled the research on semantic parsing. Improvement has since been made in many downstream tasks, including natural language interface to web APIs, text-to-SQL generation, among others. However, despite the close connection shared with these tasks, research on question answering over knowledge bases (KBQA) has comparatively been progressing slowly. We identify and attribute this to two unique challenges of KBQA, schema-level complexity and fact-level complexity. In this survey, we situate KBQA in the broader literature of semantic parsing and give a comprehensive account of how existing KBQA approaches attempt to address the unique challenges. Regardless of the unique challenges, we argue that we can still take much inspiration from the literature of semantic parsing, which has been overlooked by existing research on KBQA. Based on our discussion, we can better understand the bottleneck of current KBQA research and shed light on promising directions for KBQA to keep up with the literature of semantic parsing, particularly in the era of pre-trained language models.
Towards Large-Scale Small Object Detection: Survey and Benchmarks
Jul 31, 2022
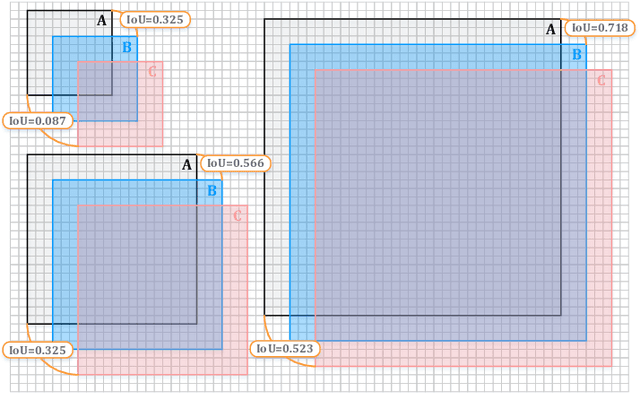
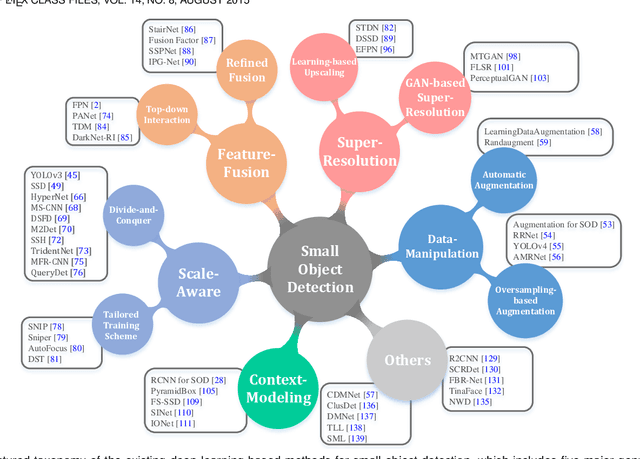
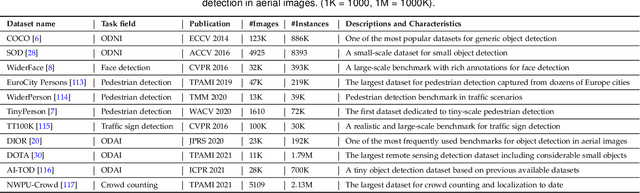
With the rise of deep convolutional neural networks, object detection has achieved prominent advances in past years. However, such prosperity could not camouflage the unsatisfactory situation of Small Object Detection (SOD), one of the notoriously challenging tasks in computer vision, owing to the poor visual appearance and noisy representation caused by the intrinsic structure of small targets. In addition, large-scale dataset for benchmarking small object detection methods remains a bottleneck. In this paper, we first conduct a thorough review of small object detection. Then, to catalyze the development of SOD, we construct two large-scale Small Object Detection dAtasets (SODA), SODA-D and SODA-A, which focus on the Driving and Aerial scenarios respectively. SODA-D includes 24704 high-quality traffic images and 277596 instances of 9 categories. For SODA-A, we harvest 2510 high-resolution aerial images and annotate 800203 instances over 9 classes. The proposed datasets, as we know, are the first-ever attempt to large-scale benchmarks with a vast collection of exhaustively annotated instances tailored for multi-category SOD. Finally, we evaluate the performance of mainstream methods on SODA. We expect the released benchmarks could facilitate the development of SOD and spawn more breakthroughs in this field. Datasets and codes will be available soon at: \url{https://shaunyuan22.github.io/SODA}.
Clues Before Answers: Generation-Enhanced Multiple-Choice QA
Apr 30, 2022
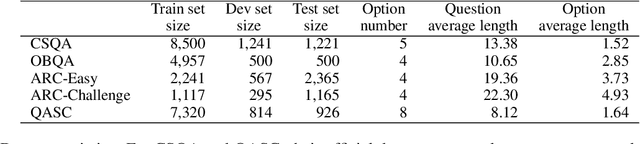
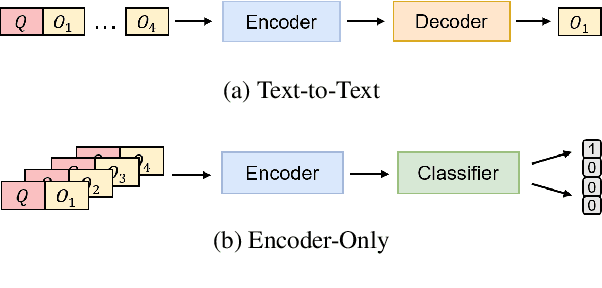
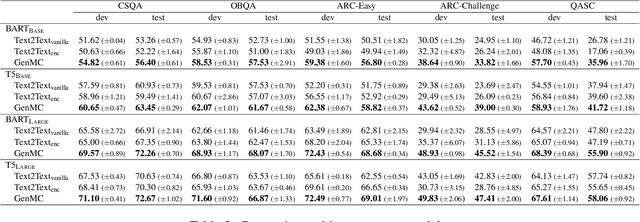
A trending paradigm for multiple-choice question answering (MCQA) is using a text-to-text framework. By unifying data in different tasks into a single text-to-text format, it trains a generative encoder-decoder model which is both powerful and universal. However, a side effect of twisting a generation target to fit the classification nature of MCQA is the under-utilization of the decoder and the knowledge that can be decoded. To exploit the generation capability and underlying knowledge of a pre-trained encoder-decoder model, in this paper, we propose a generation-enhanced MCQA model named GenMC. It generates a clue from the question and then leverages the clue to enhance a reader for MCQA. It outperforms text-to-text models on multiple MCQA datasets.
Beyond the Prototype: Divide-and-conquer Proxies for Few-shot Segmentation
Apr 21, 2022
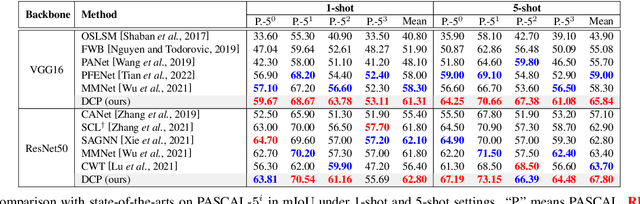
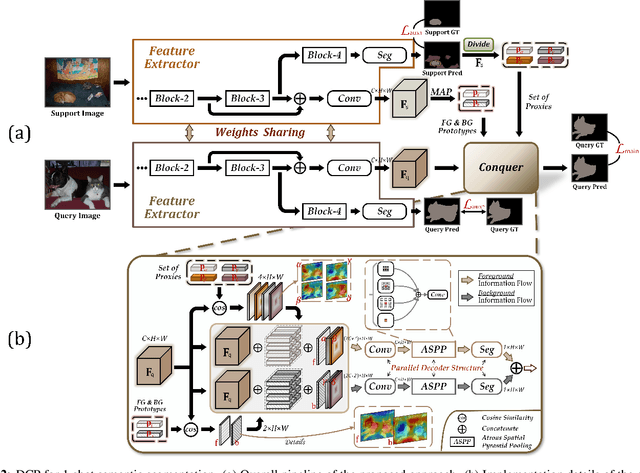

Few-shot segmentation, which aims to segment unseen-class objects given only a handful of densely labeled samples, has received widespread attention from the community. Existing approaches typically follow the prototype learning paradigm to perform meta-inference, which fails to fully exploit the underlying information from support image-mask pairs, resulting in various segmentation failures, e.g., incomplete objects, ambiguous boundaries, and distractor activation. To this end, we propose a simple yet versatile framework in the spirit of divide-and-conquer. Specifically, a novel self-reasoning scheme is first implemented on the annotated support image, and then the coarse segmentation mask is divided into multiple regions with different properties. Leveraging effective masked average pooling operations, a series of support-induced proxies are thus derived, each playing a specific role in conquering the above challenges. Moreover, we devise a unique parallel decoder structure that integrates proxies with similar attributes to boost the discrimination power. Our proposed approach, named divide-and-conquer proxies (DCP), allows for the development of appropriate and reliable information as a guide at the "episode" level, not just about the object cues themselves. Extensive experiments on PASCAL-5i and COCO-20i demonstrate the superiority of DCP over conventional prototype-based approaches (up to 5~10% on average), which also establishes a new state-of-the-art. Code is available at github.com/chunbolang/DCP.
Learning What Not to Segment: A New Perspective on Few-Shot Segmentation
Mar 29, 2022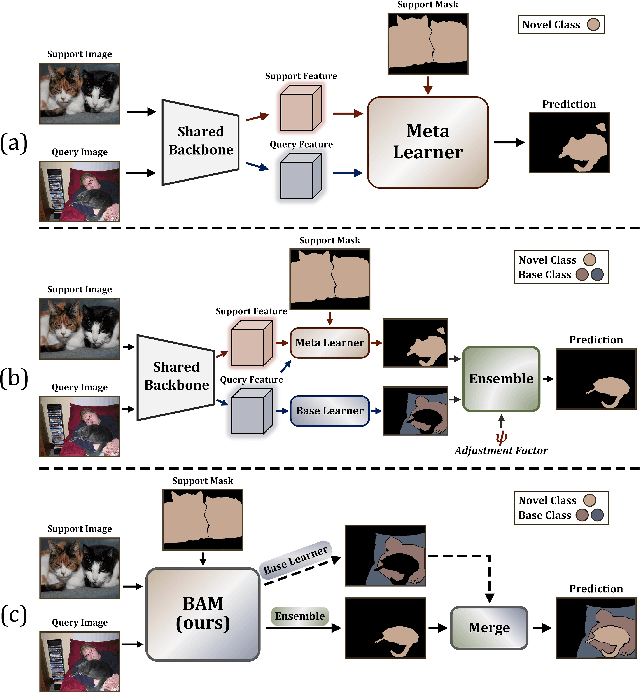
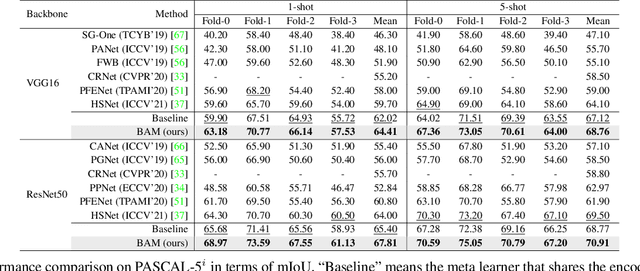
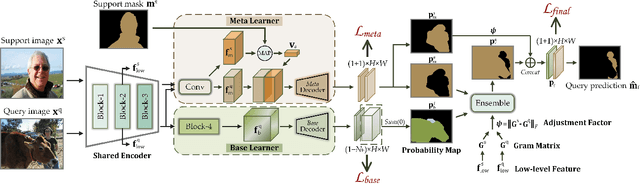
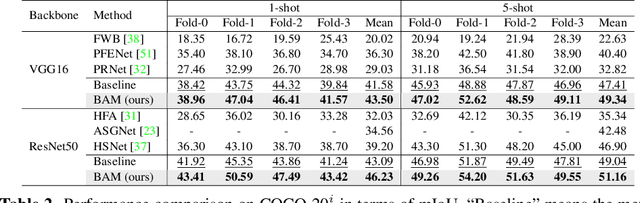
Recently few-shot segmentation (FSS) has been extensively developed. Most previous works strive to achieve generalization through the meta-learning framework derived from classification tasks; however, the trained models are biased towards the seen classes instead of being ideally class-agnostic, thus hindering the recognition of new concepts. This paper proposes a fresh and straightforward insight to alleviate the problem. Specifically, we apply an additional branch (base learner) to the conventional FSS model (meta learner) to explicitly identify the targets of base classes, i.e., the regions that do not need to be segmented. Then, the coarse results output by these two learners in parallel are adaptively integrated to yield precise segmentation prediction. Considering the sensitivity of meta learner, we further introduce an adjustment factor to estimate the scene differences between the input image pairs for facilitating the model ensemble forecasting. The substantial performance gains on PASCAL-5i and COCO-20i verify the effectiveness, and surprisingly, our versatile scheme sets a new state-of-the-art even with two plain learners. Moreover, in light of the unique nature of the proposed approach, we also extend it to a more realistic but challenging setting, i.e., generalized FSS, where the pixels of both base and novel classes are required to be determined. The source code is available at github.com/chunbolang/BAM.