 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Camera-Controlled Video Generation of Static Scenes via Sparse Diffusion and 3D Rendering
Jan 14, 2026Modern video generative models based on diffusion models can produce very realistic clips, but they are computationally inefficient, often requiring minutes of GPU time for just a few seconds of video. This inefficiency poses a critical barrier to deploying generative video in applications that require real-time interactions, such as embodied AI and VR/AR. This paper explores a new strategy for camera-conditioned video generation of static scenes: using diffusion-based generative models to generate a sparse set of keyframes, and then synthesizing the full video through 3D reconstruction and rendering. By lifting keyframes into a 3D representation and rendering intermediate views, our approach amortizes the generation cost across hundreds of frames while enforcing geometric consistency. We further introduce a model that predicts the optimal number of keyframes for a given camera trajectory, allowing the system to adaptively allocate computation. Our final method, SRENDER, uses very sparse keyframes for simple trajectories and denser ones for complex camera motion. This results in video generation that is more than 40 times faster than the diffusion-based baseline in generating 20 seconds of video, while maintaining high visual fidelity and temporal stability, offering a practical path toward efficient and controllable video synthesis.
Uncovering Political Bias in Large Language Models using Parliamentary Voting Records
Jan 13, 2026As large language models (LLMs) become deeply embedded in digital platforms and decision-making systems, concerns about their political biases have grown. While substantial work has examined social biases such as gender and race, systematic studies of political bias remain limited, despite their direct societal impact. This paper introduces a general methodology for constructing political bias benchmarks by aligning model-generated voting predictions with verified parliamentary voting records. We instantiate this methodology in three national case studies: PoliBiasNL (2,701 Dutch parliamentary motions and votes from 15 political parties), PoliBiasNO (10,584 motions and votes from 9 Norwegian parties), and PoliBiasES (2,480 motions and votes from 10 Spanish parties). Across these benchmarks, we assess ideological tendencies and political entity bias in LLM behavior. As part of our evaluation framework, we also propose a method to visualize the ideology of LLMs and political parties in a shared two-dimensional CHES (Chapel Hill Expert Survey) space by linking their voting-based positions to the CHES dimensions, enabling direct and interpretable comparisons between models and real-world political actors. Our experiments reveal fine-grained ideological distinctions: state-of-the-art LLMs consistently display left-leaning or centrist tendencies, alongside clear negative biases toward right-conservative parties. These findings highlight the value of transparent, cross-national evaluation grounded in real parliamentary behavior for understanding and auditing political bias in modern LLMs.
Detecting Linguistic Bias in Government Documents Using Large language Models
Feb 19, 2025



This paper addresses the critical need for detecting bias in government documents, an underexplored area with significant implications for governance. Existing methodologies often overlook the unique context and far-reaching impacts of governmental documents, potentially obscuring embedded biases that shape public policy and citizen-government interactions. To bridge this gap, we introduce the Dutch Government Data for Bias Detection (DGDB), a dataset sourced from the Dutch House of Representatives and annotated for bias by experts. We fine-tune several BERT-based models on this dataset and compare their performance with that of generative language models. Additionally, we conduct a comprehensive error analysis that includes explanations of the models' predictions. Our findings demonstrate that fine-tuned models achieve strong performance and significantly outperform generative language models, indicating the effectiveness of DGDB for bias detection. This work underscores the importance of labeled datasets for bias detection in various languages and contributes to more equitable governance practices.
Towards Ontology Reshaping for KG Generation with User-in-the-Loop: Applied to Bosch Welding
Sep 22, 2022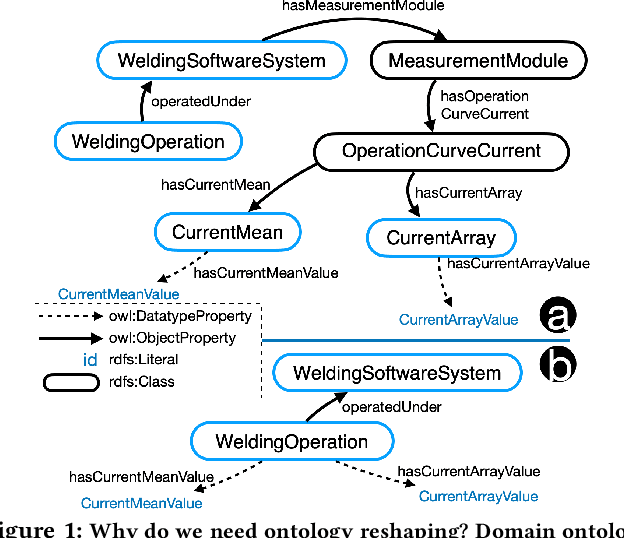
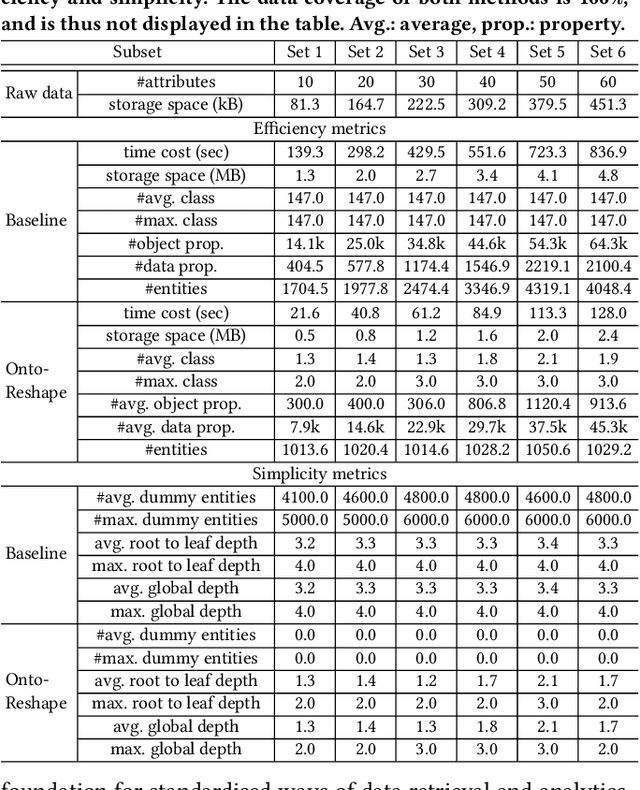
Knowledge graphs (KG) are used in a wide range of applications. The automation of KG generation is very desired due to the data volume and variety in industries. One important approach of KG generation is to map the raw data to a given KG schema, namely a domain ontology, and construct the entities and properties according to the ontology. However, the automatic generation of such ontology is demanding and existing solutions are often not satisfactory. An important challenge is a trade-off between two principles of ontology engineering: knowledge-orientation and data-orientation. The former one prescribes that an ontology should model the general knowledge of a domain, while the latter one emphasises on reflecting the data specificities to ensure good usability. We address this challenge by our method of ontology reshaping, which automates the process of converting a given domain ontology to a smaller ontology that serves as the KG schema. The domain ontology can be designed to be knowledge-oriented and the KG schema covers the data specificities. In addition, our approach allows the option of including user preferences in the loop. We demonstrate our on-going research on ontology reshaping and present an evaluation using real industrial data, with promising results.
Union and Intersection of all Justifications
Sep 23, 2021
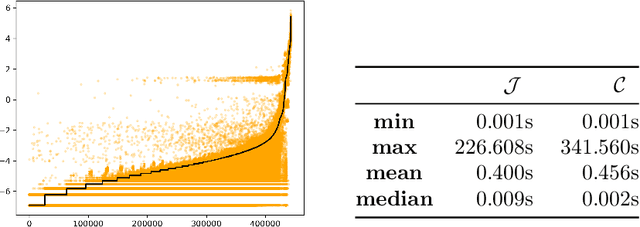
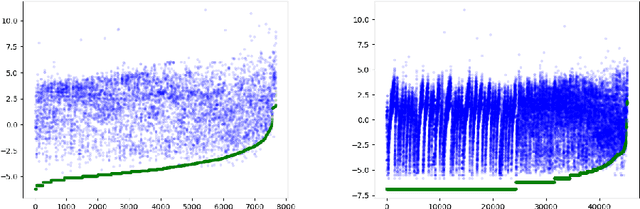
We present new algorithm for computing the union and intersection of all justifications for a given ontological consequence without first computing the set of all justifications. Through an empirical evaluation, we show that our approach works well in practice for expressive DLs. In particular, the union of all justifications can be computed much faster than with existing justification-enumeration approaches. We further discuss how to use these results to repair ontologies efficiently.